
본 프로젝트는 Spring Boot와 MySQL을 활용한 기록 프로젝트 입니다.
해당 글은 BulkInsert를 적용하면서 발생한 문제를 해결하기 위해 진행한 기술적 접근 방식을 설명합니다.
[요약]
BulkDelete를 통해 삭제 쿼리 수는 줄였으나, 부모 엔티티가 자식 엔티티의 생성 생명주기를 담당함에 따라 데이터 행 수 만큼 Insert 쿼리가 발생하는 문제가 있었습니다. 이를 해결하고자 JdbcTemplate을 활용한 BulkInsert를 도입하였으며, 추가 Repository 구현으로 인한 Service 로직 변경 전파 문제를 새로운 인터페이스 상속 방식을 통해 개선하며, 불필요한 기능 사용을 제한하였습니다.
이를 통해 의도치 않은 사용으로 인한 잠재적 문제를 효과적으로 방지할 수 있었습니다.
[문제 상황]
BulkDelete를 적용하면서 부모 엔티티가 자식 엔티티의 삭제 생명주기를 더이상 관리하지 않게 되었습니다.
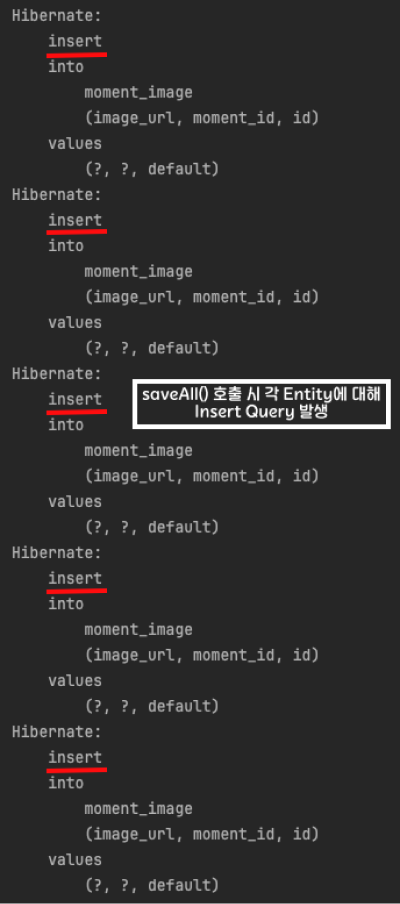
하지만, 여전히 부모 엔티티가 자식 엔티티의 생성 생명주기를 담당하고 있었기에 아래와 같이 저장되는 Data Row 갯수 만큼 Insert Query가 나가는 문제가 존재했습니다.
[문제 상황 분석]
이를 해결하고자, 여러 Entity를 저장할 때 saveAll() 메서드를 사용하였습니다.
SimpleJpaRepository.saveAll()
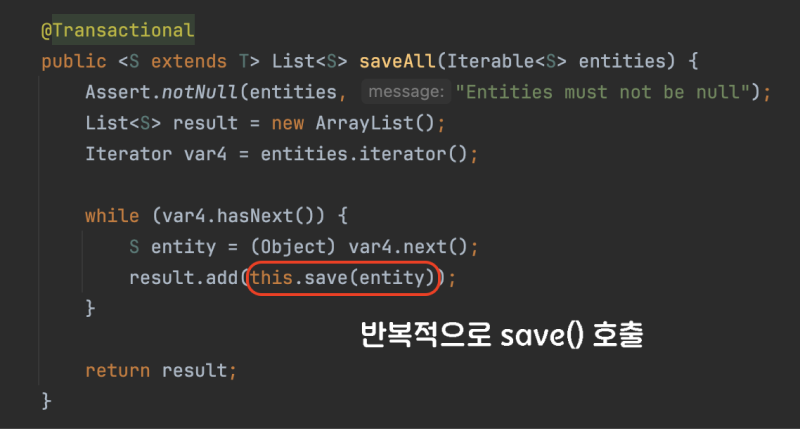
saveAll은 내부적으로 각 엔티티마다 save 메서드를 호출하여 개별적으로 처리합니다.
메서드 레벨에 트랜잭션이 설정되어 있기 때문에, saveAll을 실행하는 동안 동일한 트랜잭션 내에서 모든 작업이 수행됩니다. 이로 인해 save 메서드를 반복적으로 호출하는 것보다 효율적일 수 있었습니다.
하지만, 대용량 데이터를 처리할 때는 여전히 각 엔티티마다 개별적인 Query가 실행되기 때문에 매번 네트워크를 타고 데이터베이스 I/O가 증가하기 때문에 성능 저하가 발생할 수 있습니다.
즉, saveAll()을 통해서는 문제를 해결할 수 없었습니다.
✅ [해결 방안 - BulkInsert 도입]
BulkDelete와 같이 JPQL 쿼리를 통해 문제를 풀어나가려고 했지만, 기본키 생성 전략 중 IDENTITY 전략의 경우 Hibernate는 insert batching을 지원하지 않는 상태였습니다.
Hibernate 공식문서
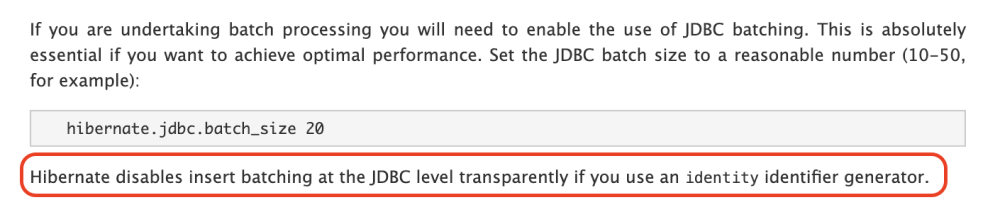
영속성 컨텍스트 내부에서는 엔티티를 식별할때 엔티티 타입과 PK값으로 식별하지만, IDENTITY전략의 경우 DB에 Insert 한 후 PK 확인이 가능하기 때문에 batch insert를 비활성화 한 것으로 확인되었습니다.
(Hibernate가 채택한 transactional write-behind (쓰기 지연) 전략을 방해하기 때문입니다.)
[기본 키 생성전략을 교체?]
BulkInsert를 위해 기본 키 생성전략을 SEQUENCE 혹은 TABLE 로의 변경 또한 고려해보았습니다.
하지만 운영환경 DB는 MySQL로 SEQUENCE 테이블 전략을 지원하지 않았으며, TABLE 전략은 테이블 마다 키를 관리하는 테이블을 만든다는 것이 더 큰 비용을 야기한다고 판단하였습니다.
[jdbc or Native SQL]
따라서 기본키 생성 전략을 IDENTITY로 가져가면서 BulkInsert를 하기 위해서는 jdbc 혹은 Native SQL을 이용해야 하는 상황이였고, jdbc를 활용하기로 결정하였습니다.
(Native SQL은 애플리케이션이 특정 데이터베이스에 종속적으로 작성되면, 다른 데이터베이스로의 이식성이 떨어진다는 단점으로 jdbc를 활용하게 되었습니다.)
[문제 해결]
MomentImageBulkInsertRepository.bulkInsert()
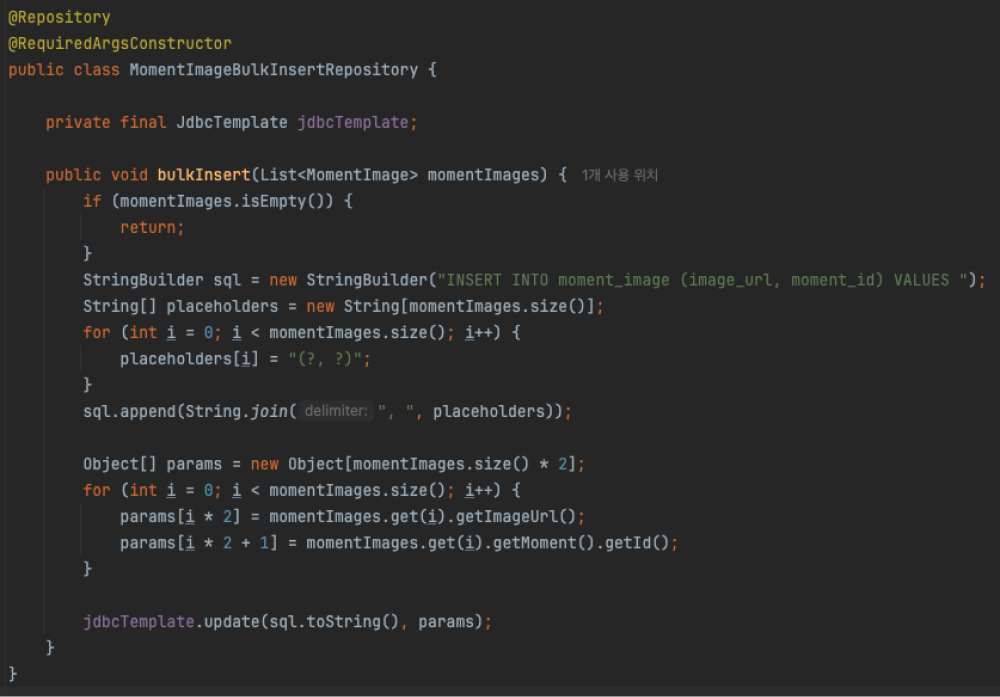
위와 같이 JdbcTemplate을 통해 BulkInsert를 구성하였고, 아래와 같이 하나의 Insert Query문을 통해 데이터가 BulkInsert 되었습니다.
BulkInsert Log

[새로운 문제의 발견]
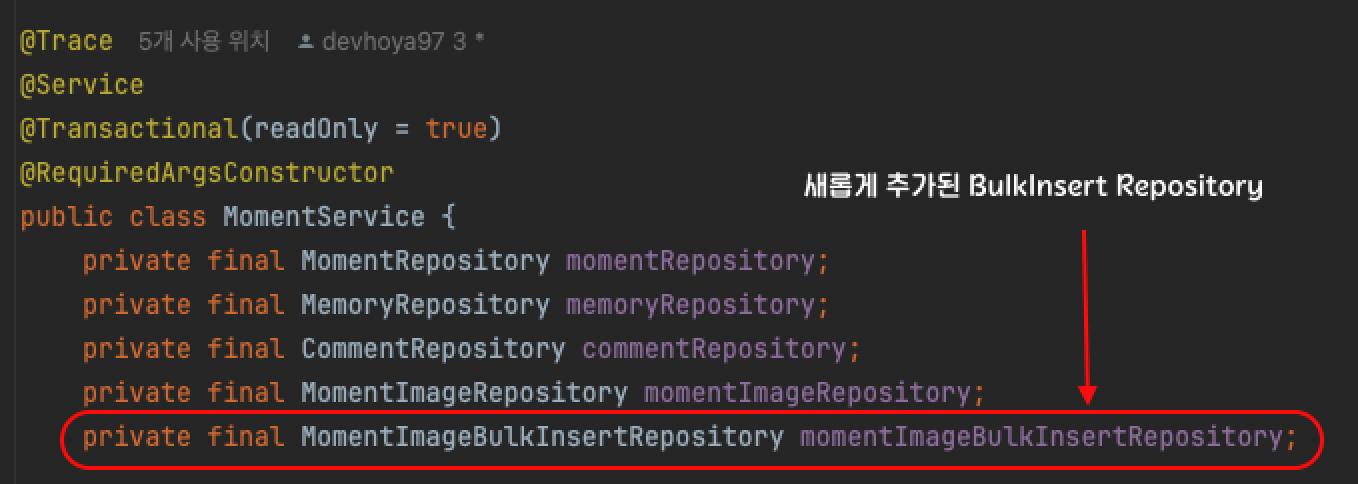
하지만 새로운 Bulk Method를 담당하는 클래스를 구현함으로 인해 Service에서 의존해야 할 빈의 수가 증가하였습니다.
즉, Repository가 추가될수록 Service 로직에 변화가 전파되는 문제점이 발생하였습니다.
이는 변경 관리가 어렵게 만들고, 개발자가 직접 관리해야 할 요소가 늘어나면서 실수 발생 가능성을 높이는 원인이 될 수 있다고 판단하였습니다.
✅ [새로운 문제의 해결 방안]
아래와 같이 새로운 인터페이스를 상속받는 방식으로 문제를 해결했으며, 이를 통해 두 가지 주요 장점을 얻을 수 있었습니다.
개선된 MomentService
Diagram
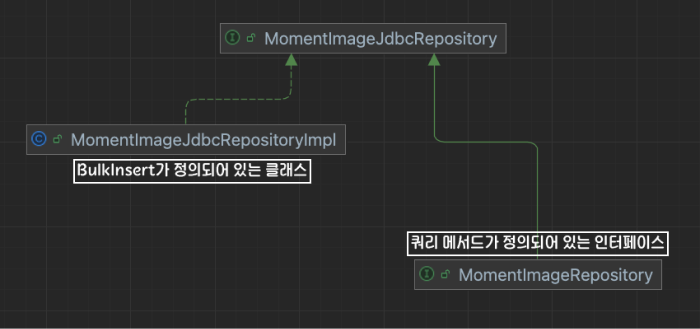
[첫번째 장점 - 변경의 전파를 방지]
새로운 JdbcTemplate 기반 메서드 혹은 클래스가 추가되더라도 변경 사항이 전파되지 않습니다.
Service는 단순히 MomentImageRepository만을 의존하면 되므로 구조가 더욱 간결해집니다.
MomentImageRepository
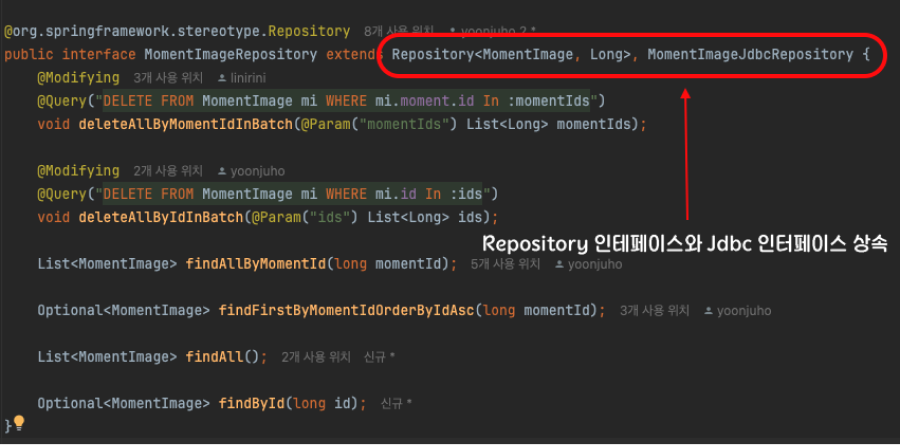
[두번째 장점 - JpaRepository의 단점을 보완]
MomentImageRepository를 살펴보면 JpaRepository가 아닌 Repository를 상속받은 것을 확인할 수 있습니다.
JpaRepository를 그대로 상속받을 경우, 필요하지 않은 기능들도 함께 포함되어 불필요한 메서드들이 자동으로 사용 가능해지는 문제가 발생합니다.
배치 처리를 지원하는 메서드나 페이징 처리를 위한 메서드, 영속성 컨텍스트 초기화를 수행하는 메서드, 프록시 객체를 조회하는 메서드 등 기본적으로 제공되지만, 이러한 기능들이 실제로 필요하지 않을 수 있습니다.
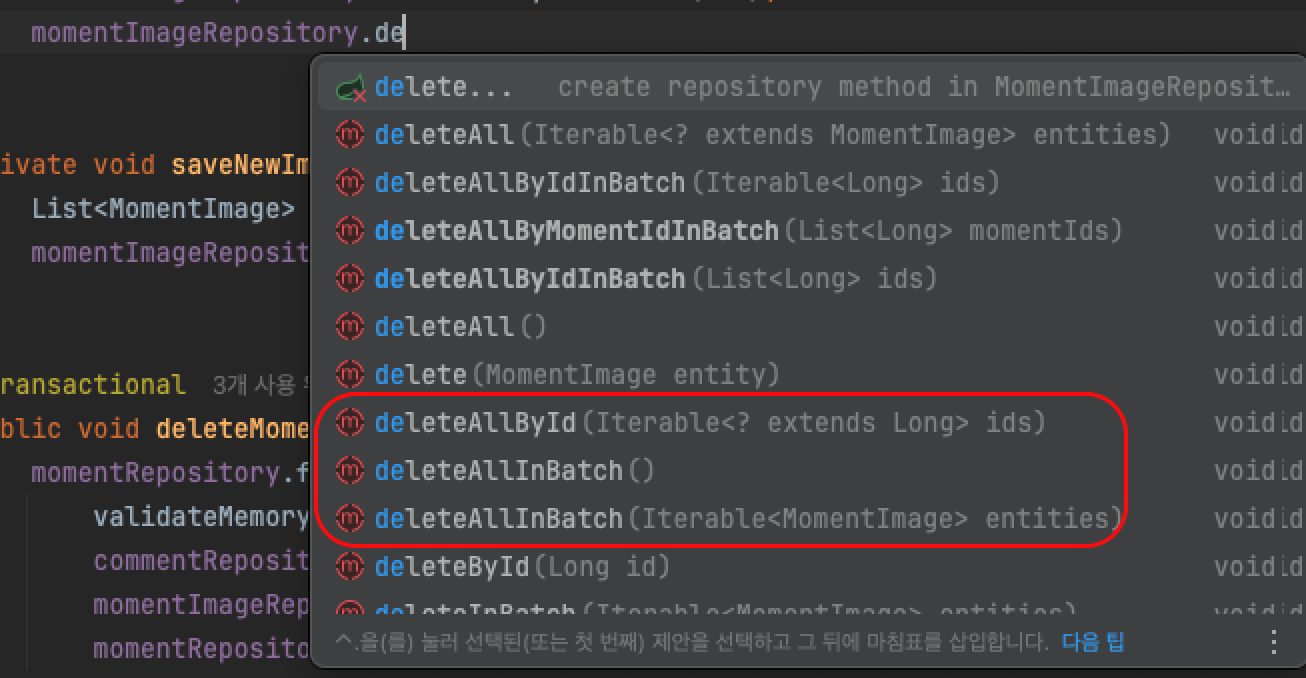
[그러면 CRUD는 어떻게 수행할까?]
Repository JavaDoc
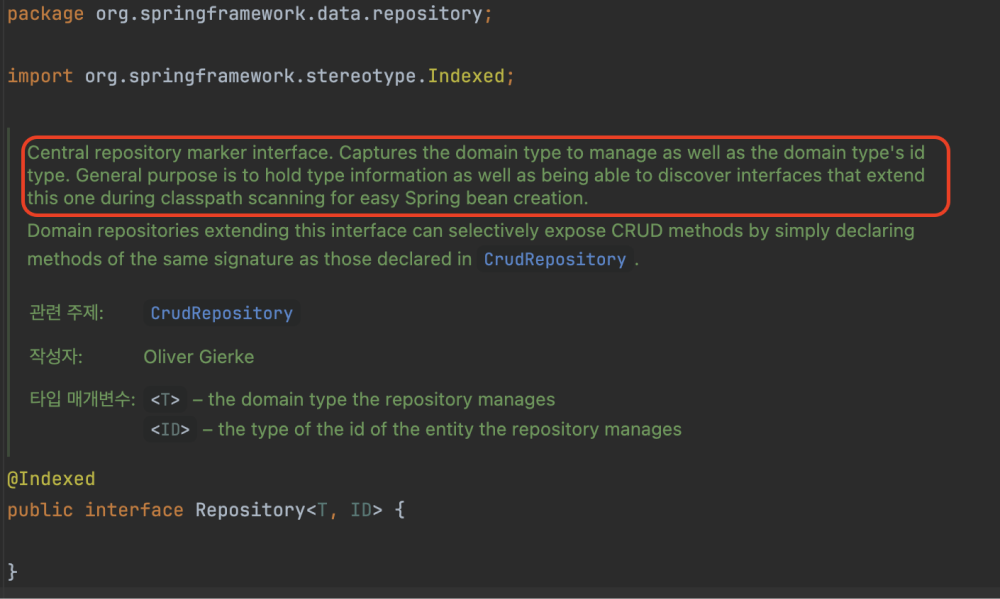
해당 JavaDoc은 "Spring이 클래스패스 스캐닝을 통해 특정 인터페이스를 확장한 다른 인터페이스들을 발견하고, 이를 기반으로 빈을 자동으로 생성하는 과정을 간소화할 수 있다"는 것을 의미합니다.
개발자가 직접 구현체를 만들 필요 없이, 인터페이스 설계만으로 Spring이 이를 처리해 준다는 장점을 설명하는 내용입니다.
따라서 쿼리 메서드 규칙대로 메서드 시그니처를 정의하기만 한다면, 구현체의 구현은 Spring Data JPA가 수행합니다.
[항상 제약을 두자!]
좋은 코드를 작성하기 위해서는 꼭 필요한 기능만을 명시적으로 정의하고, 제약을 두고 사용하는 것이 중요하다고 생각합니다.
위와 같이 필요하지 않은 기능들이 포함되면, 불필요한 메서드를 잘못 사용하는 실수를 할 가능성이 더 높아지기 때문입니다.
특히, 제가 정의한 BulkDelete와 같은 메서드는 다른 개발자가 사용할 때 JpaRepository에서 제공하는 Batch 메서드와 혼동하지 않도록 적절한 제한이 필요합니다.
(JpaRepository를 통해 제공되어지는 Batch 메서드는 의도한 바와 다르게 작동할 수 있고, 의도하지 않은 데이터까지 삭제될 위험이 있습니다.)
[결론]
BulkDelete와 BulkInsert를 수행하는 과정에서 발생할 수 있는 다양한 문제를 분석하고, 이를 개선하는 과정을 거쳤습니다. 이 과정에서 메서드가 오용되지 않도록 제약을 둔 설계를 적용했으며, 이를 통해 의도치 않은 사용으로 인한 잠재적 문제를 효과적으로 방지할 수 있었습니다.
