
본 프로젝트는 Spring Boot와 MySQL을 활용한 기록 프로젝트 입니다.
해당 글은 현재 운영 중인 서버가 트래픽 급증 시에도 안전하게 서비스를 제공할 수 있도록 인스턴스 단위의 성능 튜닝 및 최적화 과정에서 선택한 기술적 접근 방식을 설명합니다.
[요약]
현재 운영 중인 서버는 Scale-Out과 Scale-Up 방식에 한계가 존재합니다.
트래픽이 급증하는 상황에 대비하여 애플리케이션의 성능을 튜닝하여 안전성있는 서비스를 제공하는 것이 필수적이라고 판단했습니다. 따라서, 인스턴스 한 대 기준으로 핵심기능이 안정적으로 서비스 될 수 있게 설정하는 과정을 거치게 되었습니다.
[Tomcat과 HikariCP의 설정값만을 바꾸면서 테스트를 진행한 이유]
성능 개선에서 무분별한 변경은 원인 분석을 어렵게 만든다고 생각했습니다.
저희는 우선, 애플리케이션의 응답 지연이 DB 커넥션 풀과 서버 쓰레드 처리량에 기인할 수 있다는 가설을 세웠고, 이에 따라 Tomcat의 최대 스레드 수, HikariCP의 최소/최대 커넥션 수와 같은 I/O 병목 지점에 직접적인 영향을 주는 설정값부터 조정해 테스트를 진행했습니다.
정해진 일정에 차질이 가지 않도록 하나의 요인을 기준으로 우선 테스트를 진행하였고, 추가적인 성능 테스트를 위해 APM, 캐시 도입 등 추가적인 영역으로 테스트 범위를 확장하려는 계획을 갖고 있습니다.
[과정]
[테스트 시나리오 선정 및 Ngrinder Setting]
Ngrinder Setting -> Vuser 1000 (process 1, thread 1000)
test 기간: 3m
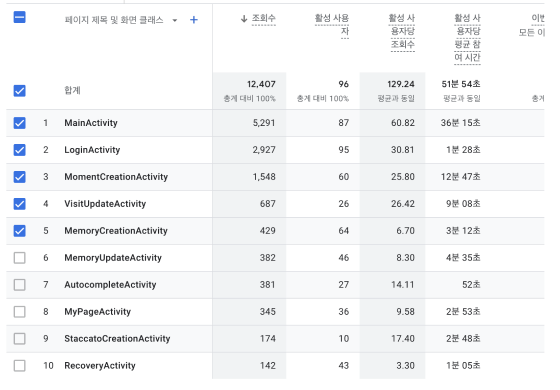
Firebase Analytics 을 확인해 보았을 때 조회 API를 호출하는 화면의 비중이 높았습니다.
그로인해 로그인, 추억 조회, 기록 조회 API 를 Think Time이 적용된 하나의 테스트 시나리오로 묶어 스크립트를 작성, 각 테스트 데이터는 100만건을 삽입한 후 Ngrinder를 통해 부하 테스트를 진행하였습니다.
또한 활성 사용자수와 현재 서비스 크기를 고려했을때, 약 1000명의 사용자가 요청을 보내는 상황으로 가정하였습니다.
Firebase Analytics
[초기 값(Default Value)으로 성능 측정]
 Default Value Default Value |  Default Value 성능 측정 결과 Default Value 성능 측정 결과 |
|---|
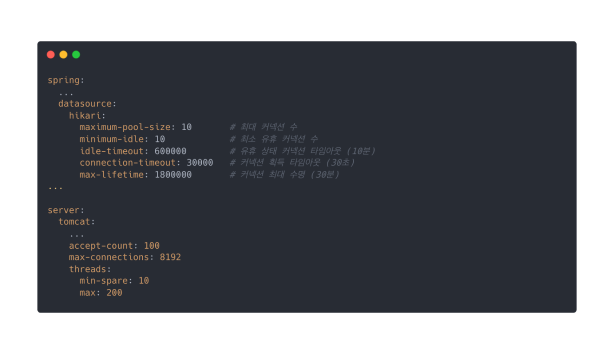
팀 프로젝트에서 Spring Boot(3.3.1)를 사용하였기에 위와 같은 Default 값들이 설정되어있었습니다.
각 설정들을 하나씩 독립 변인으로 설정한 후, 다른 설정들은 통제 변인으로 설정, 그로 인해 도출되는 결과 TPS와 성공 응답 비율을 종속 변인으로 설정하여 테스트를 진행하였습니다.
[Tomcat-Max-Connections]
1000명 기준 평균 TPS가 30인 것에 비해 Max Connections이 과도하게 크다고 생각되었습니다.
따라서 연결할 수 있는 개수를 줄여 리소스 낭비를 줄이는 방식을 선택하였습니다. 대신, Connection을 얻지 못해서 테스트 실패율이 증가하였습니다.
테스트 실패율과 TPS를 두고 저울질 한다면, 테스트 실패율이 더 낮은 것이 중요하다고 생각해서 Connection의 개수를 2048개로 선택하게 되었습니다.
 [Max-Connection = 8192] [Max-Connection = 8192] |  [Max-Connection = 2048] [Max-Connection = 2048] |
|---|
[성능 테스트 진행 중 Nginx Worker Connection Error]
부하 테스트를 진행하던 중 Nginx 로그를 확인해보니 아래와 같은 에러 로그가 기록되고 있었습니다.
에러 로그
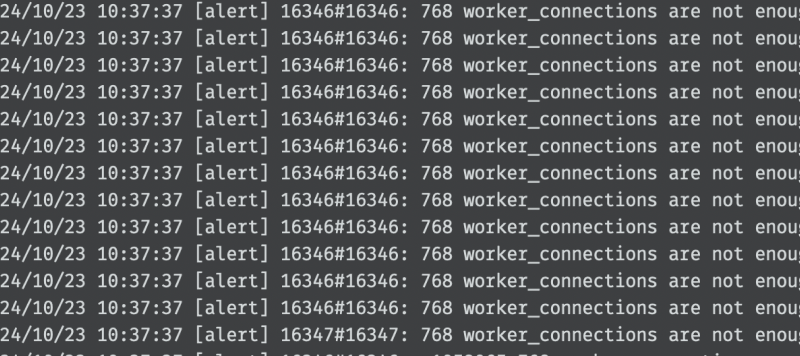
1000개의 사용자 요청이 일어났을 때 발생하는 이 에러 메시지는 Nginx에서 동시에 처리할 수 있는 연결 수(worker_connections)가 부족하다는 경고이며, 구체적으로 Nginx의 현재 설정으로는 768개의 연결을 처리할 수 있도록 되어 있는데, 더 많은 연결이 들어와서 이 한계를 초과하였기에 발생한 에러로 판단하였습니다.
따라서 기존에 768개의 사용자 요청을 처리할 수 있게 설정된 값을 2048로 변경하였습니다.
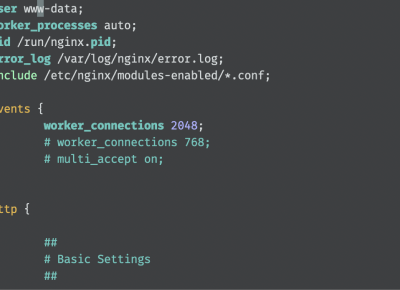 worker_connections 설정 변경 worker_connections 설정 변경 | 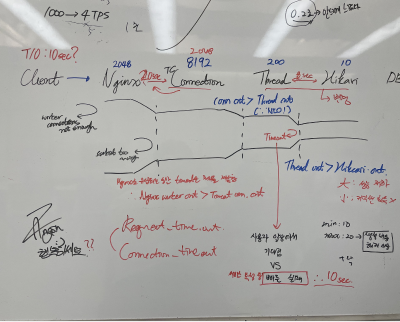 병목 현상 발생 지점 병목 현상 발생 지점 |
|---|
위의 그림과 같이 병목 현상을 최대한 줄이는 방식으로 구성하기 위해 WorkerConnection ≥ Max-Connection로 설정을 하는 것이 합리적이라고 생각했습니다. 따라서 Max-Connection의 수와 같이 2048개의 동시 처리 커넥션 수를 가져가기로 결정하였습니다.
[Tomcat-Accept-Count]
Max-Connections 이상의 연결 시도가 있을 시 요청 대기열 큐에 저장되는데, 요청 대기열 큐의 사이즈인 Accept-Count 보다도 연결 시도가 많아지면 연결을 거부하게 됩니다.
Max-Connections도 충분히 작은 값으로 설정했기 때문에 수정하지 않기로(100개) 결정했습니다.
[Tomcat-Max-Thread]
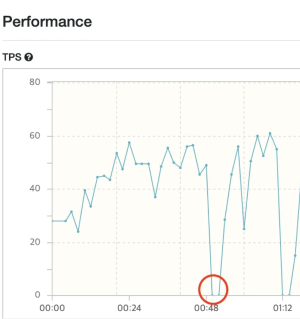
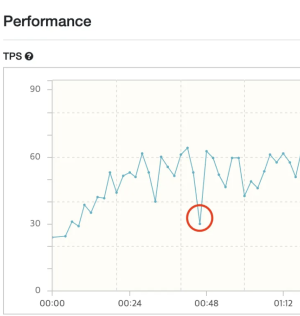
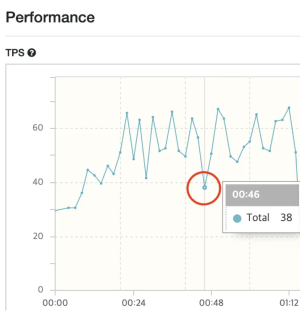
Max-Thread의 크기가 크면 Context Switching 비용이 많이 발생하므로,
값을 줄이는 방향으로 테스트를 수행하였을 때 30일 때의 TPS가 가장 높게 측정되었습니다.
Max-Thread의 수가 감소함에 따라 동일한 테스트 구간에서 TPS가 상승한 모습을 볼 수 있습니다.
 |  |  |
|---|
[Tomcat-Min-Spare]
항상 있는 최소한의 스레드 수로 너무 낮게 설정하면, 커넥션이 즉시 사용 가능한 상태가 아니어서 추가 요청 시 지연이 발생할 수 있고, 너무 높게 설정하면 불필요한 커넥션 유지로 자원 낭비가 발생할 수 있다고 판단되었습니다.
쓰레드 개수 10개 혹은 20개가 메모리 부하에 큰 영향을 미칠지, 성능에 큰 영향을 줄지 고민되어 값을 변경하면서 테스트를 해보았지만 큰 영향을 끼치지 않는다고 판단하여 수정하지 않기로(10개) 결정했습니다.
[HikariCP.maximum-pool-size] & [HikariCP.minimum-idle]
maximum-pool-size 와 minimum-idle을 동일하게가져가는 것이 권장사항이며, minimum-idle을 pool size보다 작게 가져갈 시 Connection을 생성하고 삭제하는 비용이 발생하므로, 동일하게 가져가는 방식을 선택하였습니다.
maximum-pool-size을 기존 10보다 더 적게(5개) 혹은 더 많게(15개) 구성하였을 때, TPS와 성공응답 비율의 차이가 크지 않았다고 판단하여 Default 값 10으로 유지하였습니다.
[HikariCP.connection-timeout]
HikariCP의 connection-timeout이 클라이언트 측으로부터의 요청 timeout보다 짧아야 하기에 8초로 설정하였습니다.
사용자가 10초 이상 기다리는 행동을 취하는 것 보다, 10초 내에 Connection이 맺어지지 않으면 빠른 실패를 한 후 재시도하게끔 구성하는 것이 사용자 경험 측면에서 이점이 있다고 생각되었습니다.
따라서 클라이언트 측 timeout은 10초로 설정하게 되었고, 만약 HikariCP의 connection-timeout이 클라이언트 측보다 길게 된다면 서버에서 디비로 조회를 완료한 후 반환하려 할 때, 응답을 돌려주지 못하는 문제가 발생할 수 있기에 HikariCP의 connection-timeout은 클라이언트 측보다 짧게 가져간 8초로 설정하였습니다.
[TPS 개선 결과]
TPS
30.6→44.3으로 약 44%개선

이 과정은 시스템 리소스를 효율적으로 활용하고 병목 지점을 최소화하여 애플리케이션의 처리 성능과 응답 속도를 크게 향상시킬 수 있는 중요한 작업이라고 생각됩니다. 서비스의 특성, 성격에 맞춰 애플리케이션을 튜닝하며 최적의 값을 찾아가는 과정은 서비스에 대한 깊은 이해를 쌓는 것에 큰 도움이 되었습니다.
