
코세라 파이썬
COURSERA
Python Data Structures
- 8.4 Open the file romeo.txt and read it line by line. For each line, split the line into a list of words using the split() method. The program should build a list of words. For each word on each line check to see if the word is already in the list and if not append it to the list. When the program completes, sort and print the resulting words in alphabetical order.
You can download the sample data at http://www.py4e.com/code3/romeo.txt
fname= input('Enter a file name: ') #인풋을 만들어
fh = open(fname) #어떤 파일을 열어
lst = list() #lst라는 리스트를 만들고
for line in fh: #fh만큼 라인을 반복해
word= line.split() #라인을 공백단위로 쪼개서 word 리스트 넣어
for element in word: #word를 반복하는데
if element not in lst: #lst안에 요소가 없으면
lst.append(element) #그 요소를 lst에다가 다 넣어버려
# 그러면 txt에 있던 문장들이 공백단위로 쪼개져서 리스트에 들어가게 되잖아
print(sorted(lst)) # 그럼 오름차순으로 정렬해줘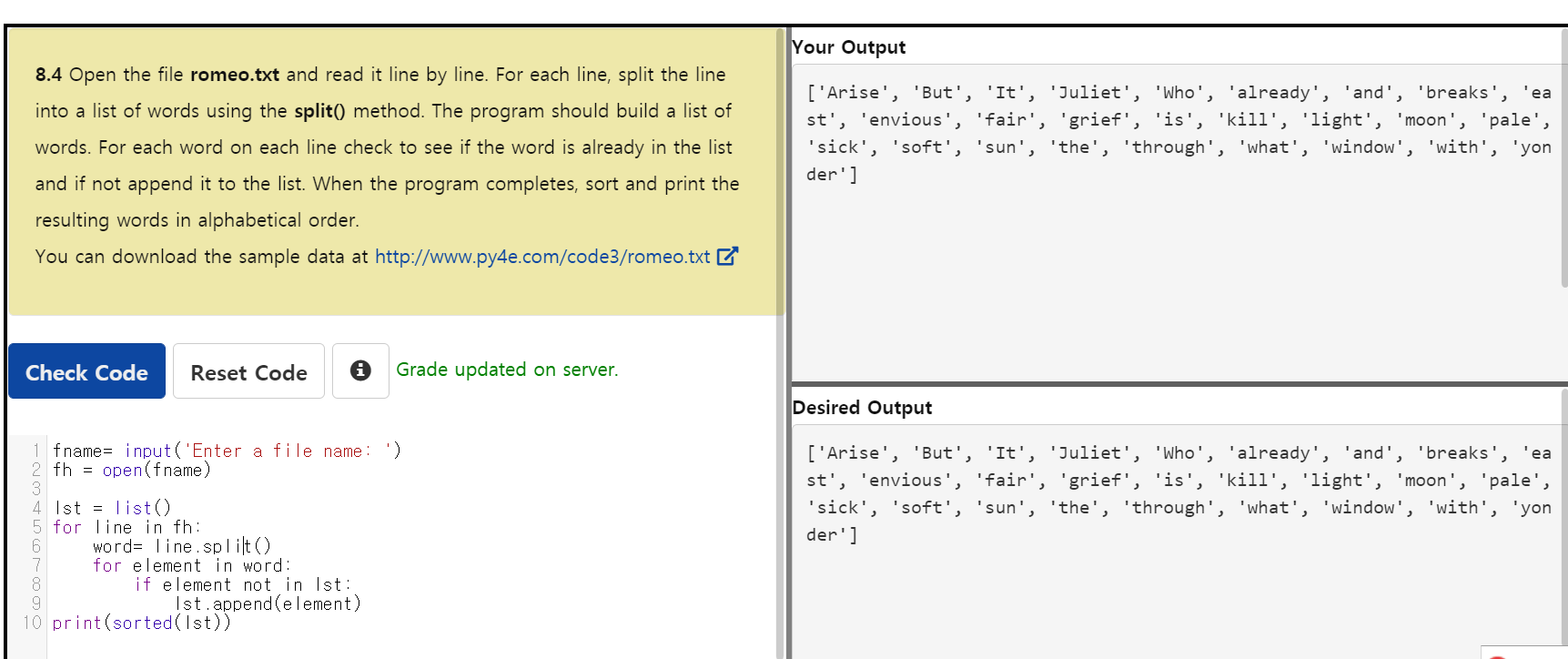
8.5 Open the file mbox-short.txt and read it line by line. When you find a line that starts with 'From ' like the following line:
From stephen.marquard@uct.ac.za Sat Jan 5 09:14:16 2008
You will parse the From line using split() and print out the second word in the line (i.e. the entire address of the person who sent the message). Then print out a count at the end.
Hint: make sure not to include the lines that start with 'From:'. Also look at the last line of the sample output to see how to print the count.
You can download the sample data at http://www.py4e.com/code3/mbox-short.txt
fname = input("Enter file name: ")
if len(fname) < 1:
fname = "mbox-short.txt"
fh = open(fname)
count = 0
for line in fh:
if line.startswith('From:'): #From 으로 시작하는 놈을 찾으면
li=line.split() #공백으로 리스트를 만들어버려
print(li[1]) #그리고 그 리스트의 1번째를 인덱싱해서 보여줘
count=count+1 #돌때마다 카운트 +1 해줘
else: continue #아니면 계속해줘
print("There were", count, "lines in the file with From as the first word")
근데.... 왜 내가 처음에 짠 코드는 2번씩 돌까?
fname = input("Enter file name: ")
if len(fname) < 1:
fname = "mbox-short.txt"
fh = open(fname)
count = 0
for line in fh:
if line.startswith("From"):
print(line.rstrip().split()[1])
count += 1
print("There were", count, "lines in the file with From as the first word")
이건 왜 두번씩 실행되는지 아시는분?

트렌디 풀스택 개발자