python 을 이용한 데이터 분석 과정을 시작했다.
어떤 tweet의 글을 분석하는 과정인데,
preprocess_text(text)
문자열 text를 가공하여 반환합니다.
- 모든 알파벳 대문자를 알파벳 소문자로 변경합니다.
2. (@와 #을 제외한) 특수문자를 삭제합니다.
- 가공된 텍스트를 공백을 기준으로 나누어 리스트 형태로 반환합니다.
여기서 2번이 큰 문제로 다가왔다.
특수문자를 일일이 제거해줘야하는건가?
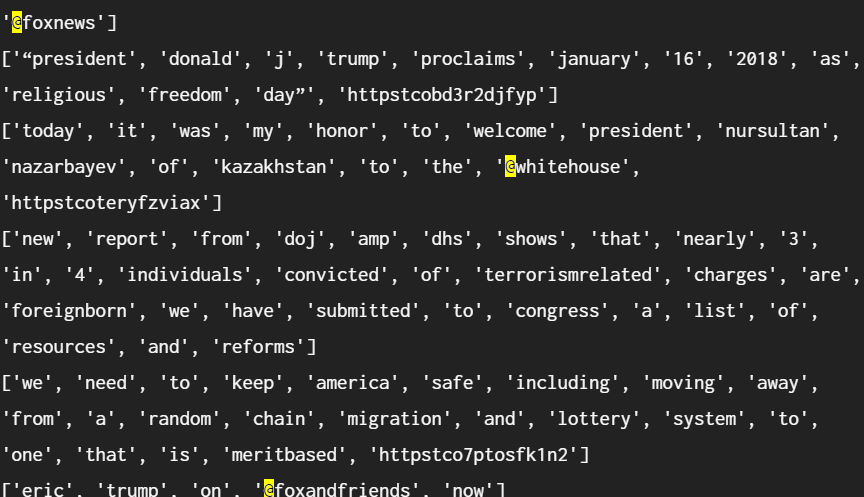
기본으로 제공 받은 text 문자열을 print(text) 해보자
“90% of trump 2017 news coverage was negative” -and much of it contrived!@foxandfriends
unemployment for black americans is the lowest ever recorded. trump approval ratings with black americans has doubled. thank you and it will get even (much) better! @foxnews
“president donald j. trump proclaims january 16 2018 as religious freedom day” https://t.co/bd3r2djfyp
today it was my honor to welcome president nursultan nazarbayev of kazakhstan to the @whitehouse! https://t.co/teryfzviax
new report from doj & dhs shows that nearly 3 in 4 individuals convicted of terrorism-related charges are foreign-born. we have submitted to congress a list of resources and reforms....각종 특수 문자가 있는 것을 볼 수 있다.
여기서 기본적으로 코드를 주어줬다.
# @와 #을 제외한 특수문자로 이루어진 문자열 symbols를 만듭니다.
symbols = punctuation.replace('@', '').replace('#', '')
# symbols는 @과 #을 제외한 모든 특수문자이게 뭔지 몰라서 punctualtion자리에 text를 넣고 출력했더니 @와 #만 제거 되어서 저장되었다 ^^;;;
아니!!! 반대로 해야된다고 !를 써야되나 이상한 생각이 들었다.
질문을 넣었더니 답변을 받았다. (처음으로 3분만에!!!)
punctialtion은 특수문자 모음이라고 했다.
그래서 symbols의 값에는 특수 문자 모음에서 @와 #을 제거한 값만 남아있는 것이다.
for symbol in symbols:
text = text.replace(symbol, "")
#symbols는 문자열이므로 문자를 하나씩 순회할 수 있다.이제 @와 #을 제외한 특수문자를 만들려면 해당 값을 순회해서 제거해주면 된다.
위for문을 해석 하자면,
symbols안 안에서 symbol을 하나씩 가져올 건데, text라는 문자열에서 symbol에 들어있는 !"$%&'()*+,-./:;<=>?[\]^_{|}~ 얘네 값을 지워줘!
그렇게 만든 데이터를 text = text.split() 해주면
text는 요로코롬 아름답게 리스트로 출력되는 것을 볼 수 있다.

트렌디 풀스택 개발자