
2025.03.01
Chapter 5. Basic of Pytorch
36. Pytorch Mnist - 이론 137. Pytorch Mnist - 이론 238. Pytorch Mnist - 이론 3
Pytorch Mnist _ 이론(1~3)
Pytorch 기본 패키지
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from matplotlib import pyplot as plt- 딥러닝 진행 시 기본적으로 필요한 구성들이
nn이라는 모듈에 있음. - 딥러닝에서 자주 사용되는 수학적 함수는
nn.functional에 저장되어 있음. - 최적화 알고리즘
optim torchvision: 여러 데이터셋을 가지고 있는 모듈
Cuda가 가능하면Cuda사용
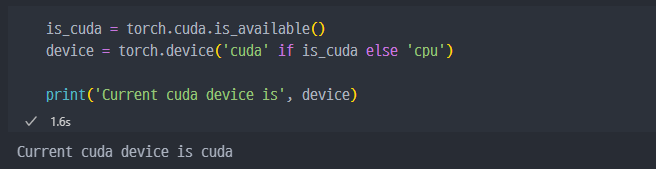
- GPU 사용 가능한지 확인 및 GPU 사용 설정
파라미터 설정
batch_size = 50
learning_rate = 0.001
epoch_num = 15
- batch_size는 데이터 묶음 수.
Mnist data set의 경우 약 60k 데이터가 있으니, 50으로 하면 1.2k 데이터Epoch(에폭): 전체 데이터셋을 한 번 학습하는 횟수Batch Size(배치 크기): 한 번의 훈련(iteration)에서 사용할 데이터 개수Step(스텝, 반복 횟수): 한 epoch 동안 배치 단위로 훈련을 진행하는 횟수
MNIST 데이터 불러오기

skicit-learn에서 데이터를 불러오는 방식과 조금 상이하다.
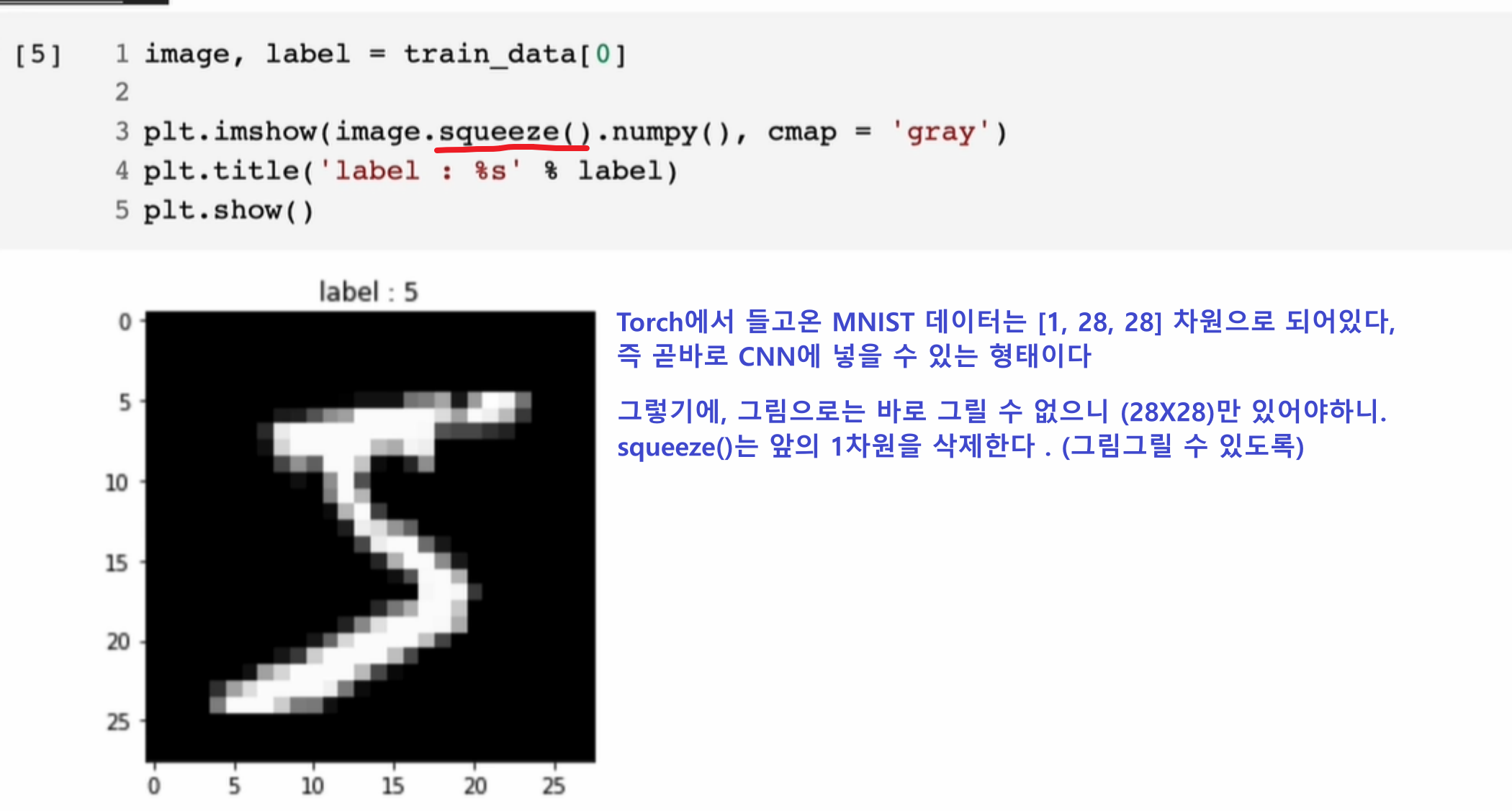
- 항상 데이터를 분석하기 앞서,
shape을 확인하고 시작하는 습관이 중요해 보인다.
미니 배치 구성
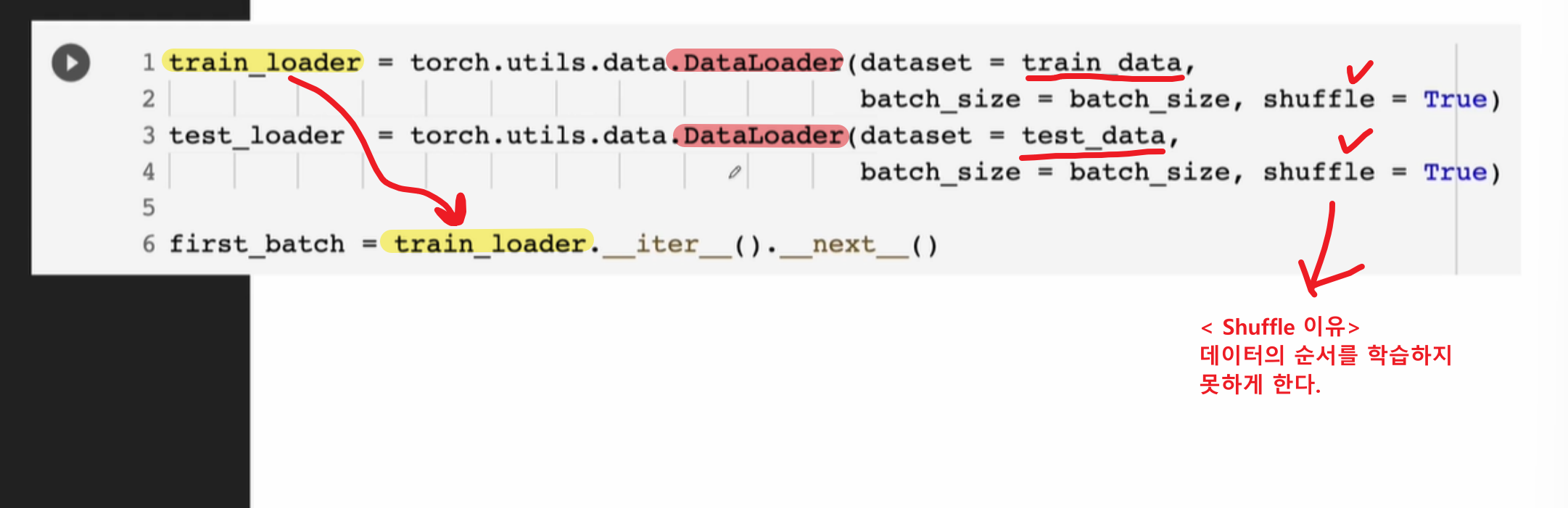
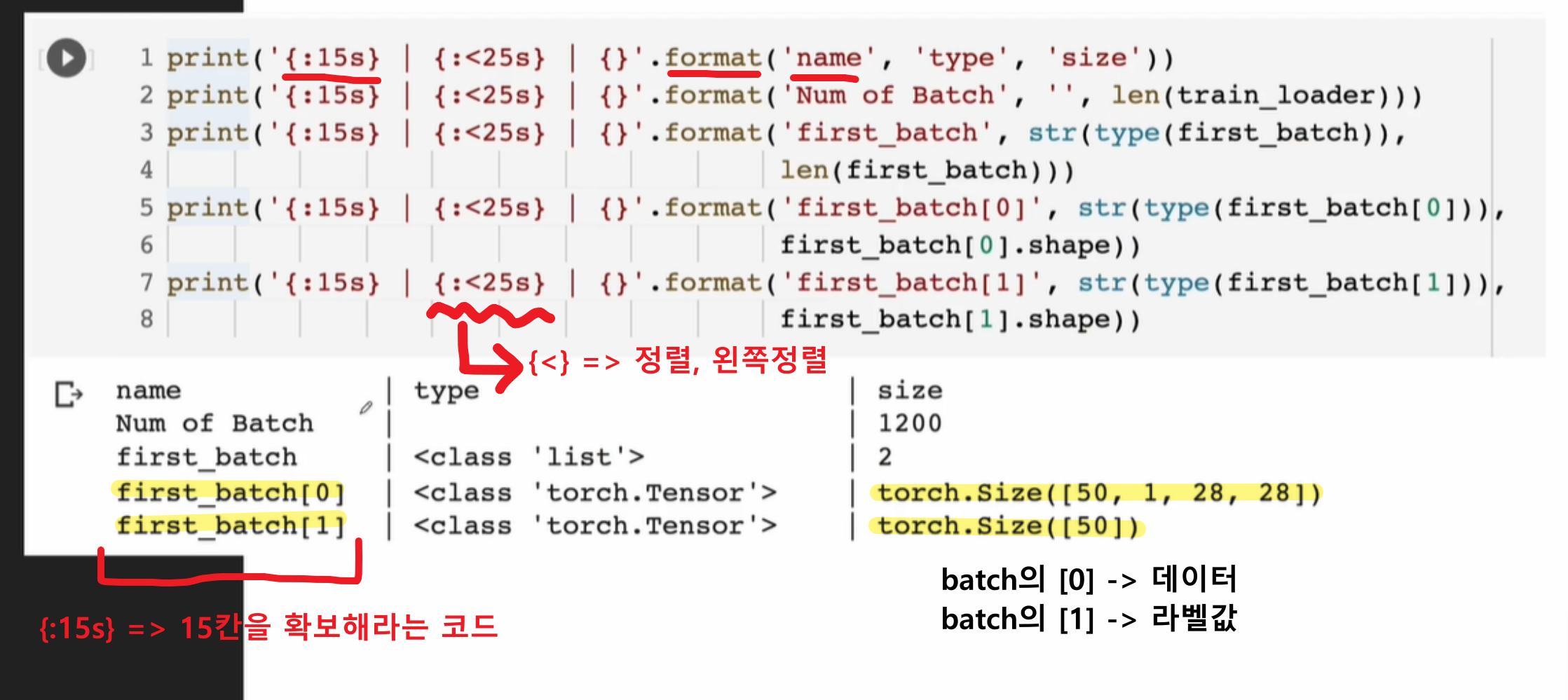
- 각각의 batch에 어떤 데이터가 어떤 형태로 들어가있는지 학습
Class - CNN
특히나
Pytorch유저들은class를 생성해서 학습하는 것을 보편적으로 생각한다.
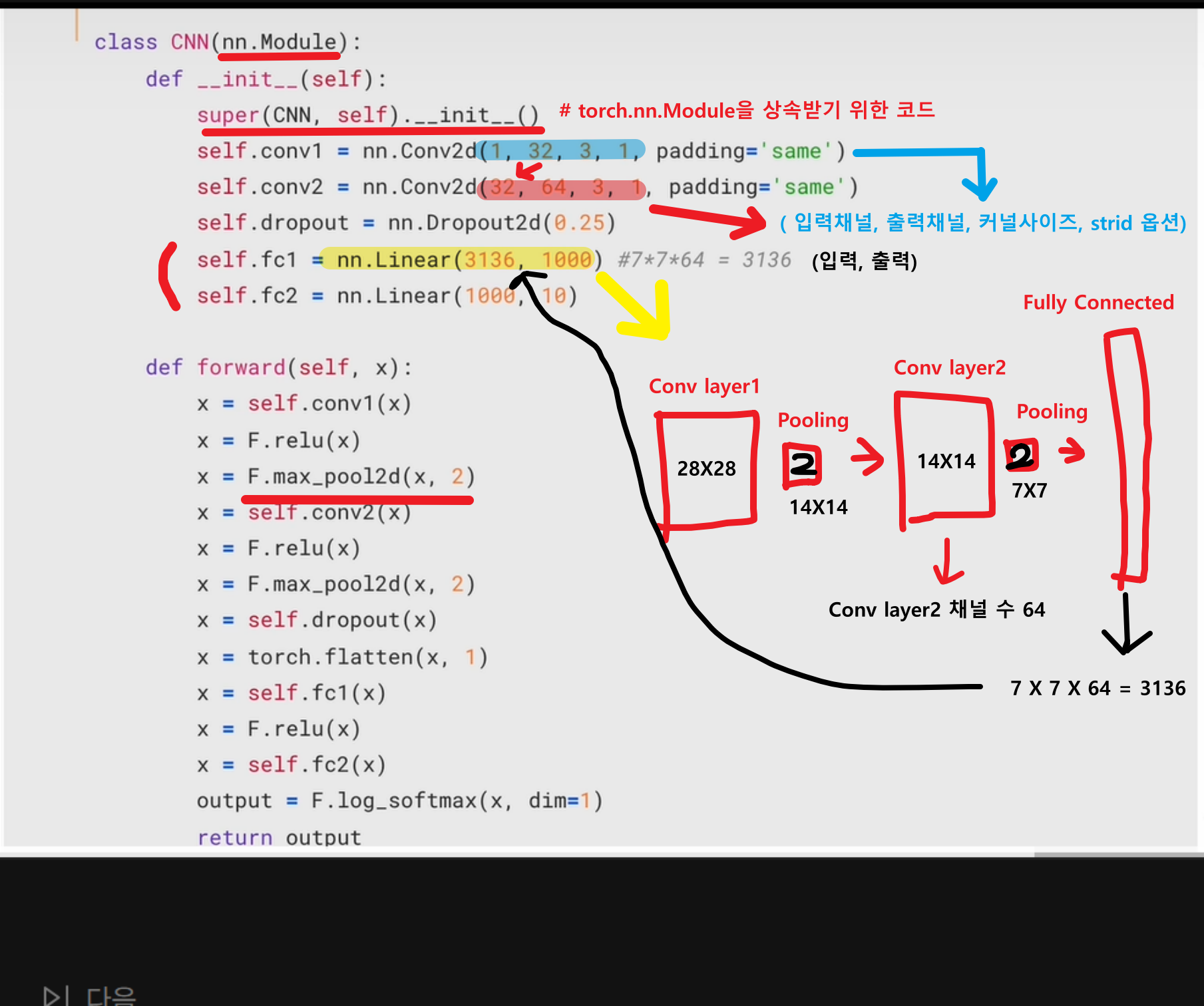
코드분석
class CNN(nn.Module):
# PyTorch의 nn.Module을 상속해서 모델을 정의하는 부분.
# CNN이라는 이름의 **합성곱 신경망(Convolutional Neural Network, CNN)**을 설계하는 중.
def __init__(self):
super(CNN, self).__init__()
# 부모 클래스(nn.Module)의 생성자를 호출하여 PyTorch의 기능을 사용할 수 있게 함.
self.conv1 = nn.Conv2d(1, 32, 3, 1, padding='same')
# nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, stride=1, padding='same')
# in_channels=1: 입력 채널 수 (MNIST는 **흑백 이미지(1채널)**이므로 1)
# out_channels=32: 출력 채널 수 (32개의 필터를 사용)
# 필터 개수가 많을수록 더 복잡한 특징을 잡을 수 있음.
# kernel_size=3: 3×3 크기의 필터 사용
# 작은 커널(3×3)은 국소적인 특징을 잘 잡아냄.
# stride=1: 필터가 이동하는 간격 (한 번에 1픽셀씩 이동)
# padding='same': 입력과 출력 크기가 같도록 패딩 적용
# 입력이 28×28이면 출력도 28×28이 유지됨.
# 📏 크기 변화
# 입력 크기: (1, 28, 28) → (32, 28, 28)
# 이유: padding='same'이므로 크기가 유지됨.
self.conv2 = nn.Conv2d(32, 64, 3, 1, padding='same')
# 입력 채널 32, 출력 채널 64 → 더 많은 특징을 학습할 수 있음.
# 입력 크기: (32, 28, 28) → (64, 28, 28)
# 여전히 padding='same'이므로 크기 유지됨.
self.dropout = nn.Dropout2d(0.25)
# 과적합을 방지하기 위해 25%의 뉴런을 랜덤하게 제거(dropout).
self.fc1 = nn.Linear(3136, 1000)
self.fc2 = nn.Linear(1000, 10)
# fc1: 3136개의 입력 → 1000개 출력
# fc2: 1000개 → 10개 (숫자 0~9 예측)
------------------------------------------------------------
def forward(self, x):
# 모델이 입력 데이터를 받아서 어떻게 계산하는지를 정의하는 함수.
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
# conv1(x): (1, 28, 28) → (32, 28, 28)
# ReLU: 음수를 0으로 바꾸는 활성화 함수 적용
# MaxPooling(2): (32, 28, 28) → (32, 14, 14)
# 풀링 크기 2를 사용하여 크기 절반으로 축소.
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
# conv2(x): (32, 14, 14) → (64, 14, 14)
# ReLU 적용
# MaxPooling(2): (64, 14, 14) → (64, 7, 7)
x = self.dropout(x)
x = torch.flatten(x, 1)
# dropout 적용 (일부 뉴런 제거)
# flatten(x, 1): CNN의 2D 출력을 1D 벡터로 변환
# (64, 7, 7) → (64×7×7) = (3136,)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
# fc1: (3136,) → (1000,)
# ReLU
# fc2: (1000,) → (10,) (출력 10개, 숫자 0~9 예측)
output = F.log_softmax(x, dim=1)
# 출력값을 확률 형태로 변환 (log softmax 사용)
# 크기: (batch_size, 10)
학습진행

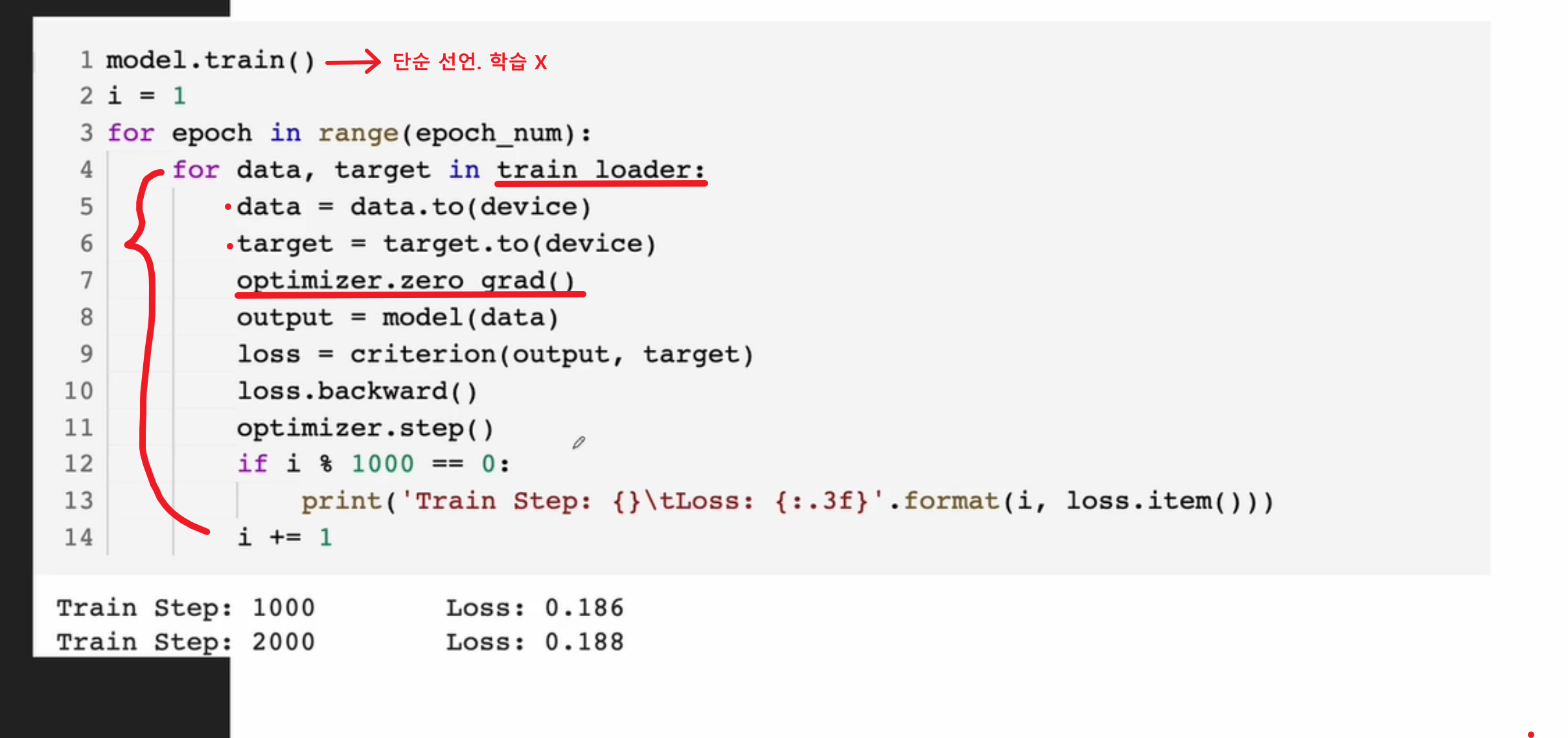
model = CNN().to(device)
- CNN()은 앞서 정의한 모델을 불러오고, .to(device)는 모델을 GPU나 CPU로 이동시키는 코드야.
- 여기서 device는 GPU가 있으면 GPU로, 없으면 CPU로 설정되도록 해야 해.
- 예시: device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
- Adam 옵티마이저를 설정하는 코드야. Adam은 Adaptive Moment Estimation의 약자로, 경사하강법의 일종인데 학습률을 자동으로 조정하는 기능이 있어.
- model.parameters()는 모델의 모든 가중치를 의미하고, lr=learning_rate는 학습률을 설정하는 부분이야.
criterion = nn.CrossEntropyLoss()
- 손실 함수로 교차 엔트로피 손실(Cross Entropy Loss)를 사용하겠다는 설정이야.
- 교차 엔트로피 손실은 분류 문제에서 자주 사용되며, 실제 클래스와 예측 클래스 간의 차이를 계산하여 그 차이를 줄여나가게 해.
- 출력값과 타겟값(정답 레이블)을 비교해서 모델이 얼마나 잘 예측하는지 평가해.
data = data.to(device)
- 데이터를 device로 이동시키는 코드야. (GPU나 CPU에 맞게 데이터가 이동한다)
- 이렇게 해야 학습 시 데이터와 모델이 같은 디바이스에서 처리되므로 연산을 잘 할 수 있어.
target = target.to(device)
- target도 같은 방식으로 정답 레이블을 device로 이동시켜야 해.
- 데이터와 정답 레이블이 모두 GPU나 CPU에서 처리되도록 해야 해.
optimizer.zero_grad()
- Gradients 초기화: PyTorch는 기울기(gradient)를 계속 누적해서 계산해. 즉, loss.backward()가 호출될 때마다 기존의 기울기 값에 더해주거든.
- 그런데 한 번의 학습 후 기울기 값을 초기화하지 않으면, 이전 배치에서 계산된 기울기가 다음 배치의 기울기 값에 영향을 미치게 돼.
- optimizer.zero_grad()는 이렇게 기울기를 0으로 초기화해줘서, 새로운 배치에 대해서만 기울기를 계산하도록 만들어주는 거야.
output = model(data)
- 입력 data를 모델에 넣어서 예측 결과(output)를 받는 코드야.
- 이 값은 모델이 예측한 각 클래스의 확률이 될 거야.
loss = criterion(output, target)
- 예측한 output과 실제 정답 target을 비교해서 손실(loss)을 계산하는 코드야.
- 교차 엔트로피 손실은 두 확률 분포(모델의 예측과 실제 클래스)를 비교하여 모델이 얼마나 틀렸는지를 측정해.
loss.backward()
- 역전파(Backpropagation): loss를 통해 기울기(gradient)를 계산하는 코드야.
- 역전파는 모델의 파라미터(가중치)들이 손실을 최소화할 수 있도록 기울기 방향으로 가중치를 업데이트하는 과정이야.
optimizer.step()
- 기울기를 사용해 모델 파라미터 업데이트를 하는 코드야.
- optimizer.step()은 Adam 옵티마이저가 기울기 정보를 바탕으로 가중치를 업데이트하는 단계야.
- 이 코드가 실행되면 모델의 가중치가 현재 배치에서 계산된 기울기를 기준으로 업데이트된다.
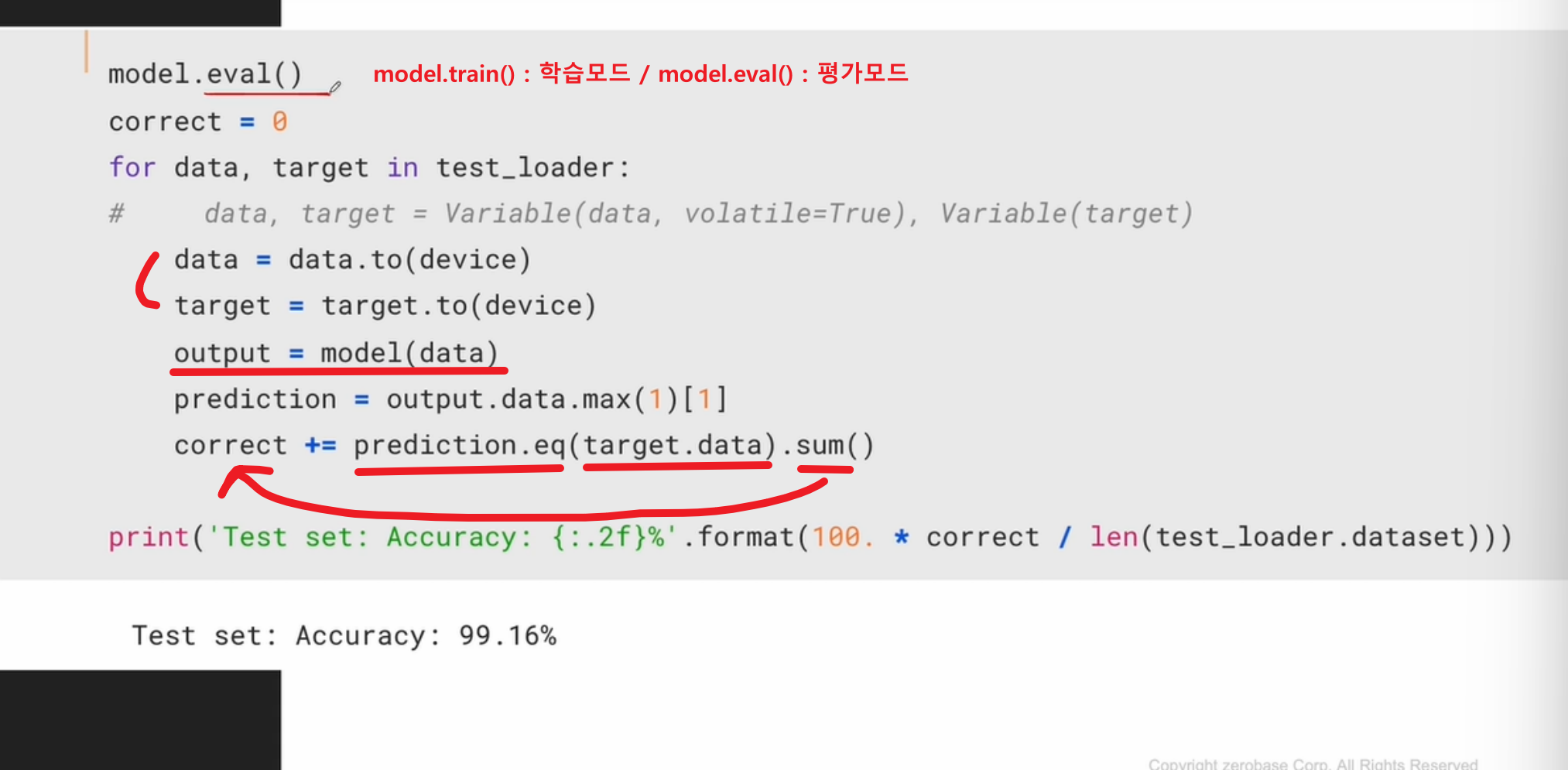
평가

(hellow. world)