EC2 단일 서버에서 Blue-Green 무중단 배포 구현하기 — 1편: 설계
MOA 운영 서비스에 적용하기 전, POC 프로젝트로 먼저 검증해본 기록
IOS_MOA 설치
안드로이드 MOA 설치
배포할 때마다 서버가 죽는다
현재 MOA 서비스의 배포 방식은 이렇다.
docker stop moa-server # ← 여기서부터 서비스 중단
docker rm moa-server
docker pull new-image
docker run moa-server # ← Spring Boot 기동까지 10~20초docker stop을 하는 순간부터 새 컨테이너의 Spring Boot가 완전히 뜰 때까지 약 10~30초 동안 서비스가 죽어있다. 이 시간 동안 사용자가 앱을 열면 502 Bad Gateway가 뜬다.
주 1회 배포면 월간 다운타임이 약 2분인데, 솔직히 수치만 보면 대단한 건 아니다. 근데 문제는 "배포 = 서비스 중단"이라는 구조 자체다. 배포할 때마다 긴장하게 되고, 사용자가 적은 새벽에만 배포하게 되고, 그러다 보면 배포 주기가 점점 길어진다.
무중단 배포는 이 구조적 문제를 없애는 거다. 배포해도 사용자한테 영향이 없으니까 언제든 편하게 배포할 수 있다.
왜 Blue-Green인가
무중단 배포 전략은 여러 가지가 있는데, 비교해보면 이렇다.
| 전략 | 핵심 원리 | 장점 | 단점 |
|---|---|---|---|
| Blue-Green | 동일 환경 2개, 트래픽을 한번에 전환 | 즉시 롤백, 구현 단순 | 순간 리소스 2배 |
| Rolling Update | N개 인스턴스를 하나씩 교체 | 리소스 효율적 | 최소 2대 이상 필요 |
| Canary | 새 버전에 트래픽 일부만 보내고 점진 확대 | 위험 최소화 | 구현 복잡 |
| In-Place | 그냥 멈추고 교체 | 가장 단순 | 다운타임 발생 |
MOA에서 Blue-Green을 선택한 이유는 명확했다.
- EC2 서버가 1대 → Rolling Update는 서버가 여러 대 있어야 가능하니까 불가
- Nginx가 이미 깔려있음 → 추가 인프라 없이 upstream 설정만 바꾸면 됨
- DAU 80명 → Canary의 "일부 트래픽 검증"이 통계적으로 무의미
- 즉시 롤백 → Nginx reload 한 번이면 1초 안에 이전 버전으로 복원
쿠버네티스 쓰면 더 깔끔하겠지만, 120명 규모 서비스에 K8s는 과하다. 컨트롤 플레인만 해도 메모리 2GB 이상 잡아먹는데, 그 리소스와 학습 비용을 감당할 이유가 없었다. (이후 학습후 롤링 배포를 도전해보자!!)
전체 아키텍처
Before — 단일 컨테이너
Client → Nginx(:80) → moa-server(:8080)
배포 시 stop → start = 다운타임After — Blue-Green
Client → Nginx(:80) → upstream(전환 가능)
├─ Blue (:8080) ← 현재 활성
└─ Green (:8081) ← 대기/신규 배포핵심은 Nginx의 upstream 설정을 바꾸고 reload하는 것이다. 새 컨테이너가 완전히 준비된 후에 트래픽을 전환하니까, 클라이언트 입장에서는 끊김이 없다.
nginx -s reload가 무중단인 이유도 재밌는데, Nginx는 Master-Worker 모델이라 reload 시 기존 Worker는 현재 처리 중인 커넥션만 마무리하고, 새 Worker가 새 설정으로 요청을 받는다. 그래서 어떤 커넥션도 끊기지 않는다.
배포 플로우 전체 그림
GitHub에 push
→ GitHub Actions (build job)
→ 테스트 실행
→ Docker 이미지 빌드 + Docker Hub push
→ GitHub Actions (deploy job) — 서버의 self-hosted runner가 실행
→ deploy.sh 실행
→ Step 1: 현재 활성 컬러 확인 (blue/green)
→ Step 2: 새 이미지 pull
→ Step 3: 새 컨테이너 시작 (대기 포트에)
→ Step 4: Health check (최대 60초)
→ Step 5: Nginx upstream 전환 + reload
→ Step 6: Smoke test (nginx 경유 확인)
→ Step 7: 이전 컨테이너 graceful shutdown
→ Step 8: 상태 파일 + 배포 이력 업데이트
→ Step 9: Docker 이미지 정리전체 과정에서 클라이언트 요청이 실패하는 구간은 없다. Step 4까지는 기존 컨테이너가 트래픽을 처리하고, Step 5에서 전환한 후에는 새 컨테이너가 처리한다.
구현 코드 상세
버전 확인 API — DeployInfoController
배포 후 "진짜 새 버전이 뜬 건가?"를 확인할 수 있는 API가 필요했다. /api/deploy-info를 호출하면 현재 버전, 컬러, 기동 시간을 반환한다.
@RestController
@RequestMapping("/api")
public class DeployInfoController {
private final String version;
private final String color;
private final Instant startedAt;
public DeployInfoController(
@Value("${app.version:dev}") String version,
@Value("${app.deploy-color:local}") String color) {
this.version = version;
this.color = color;
this.startedAt = Instant.now();
}
@GetMapping("/deploy-info")
public DeployInfoResponse deployInfo() {
return DeployInfoResponse.of(version, color, startedAt);
}
}APP_VERSION과 DEPLOY_COLOR는 Docker 컨테이너 실행 시 환경변수로 주입된다. 로컬에서 ./gradlew bootRun으로 실행하면 환경변수가 없으니까 기본값인 "dev", "local"이 들어간다.
실제 배포 후 이 API를 호출하면 이런 응답이 온다:

처음에 이 부분이 좀 헷갈렸는데, 결국 이런 흐름이다:
deploy.sh에서 현재 상태 파일 읽음 → "blue"
→ 다음 컬러는 "green"
→ docker run -e DEPLOY_COLOR=green -e APP_VERSION=abc123 ...
→ Spring Boot가 환경변수 읽음 → ${DEPLOY_COLOR:local} → "green"Graceful Shutdown 설정 — application-prod.yaml
server:
shutdown: graceful
spring:
lifecycle:
timeout-per-shutdown-phase: 30s
management:
endpoints:
web:
exposure:
include: health
endpoint:
health:
show-details: neverserver.shutdown: graceful 이 없으면 SIGTERM 받았을 때 진행 중인 요청을 바로 끊어버린다. 이 설정을 넣으면 새 요청은 거부하되, 처리 중인 요청은 완료할 때까지 기다려준다. 최대 30초.
show-details: never로 한 이유는 보안 때문이다. health endpoint는 인증 없이 접근 가능한데, 상세 정보에 DB 호스트나 디스크 경로 같은 인프라 정보가 포함될 수 있다.
Dockerfile — Multi-stage 빌드
# Stage 1: Build
FROM eclipse-temurin:21-jdk AS builder
WORKDIR /build
COPY gradle/ gradle/
COPY gradlew settings.gradle build.gradle ./
RUN chmod +x gradlew && ./gradlew dependencies --no-daemon || true
COPY src/ src/
RUN ./gradlew bootJar --no-daemon -x test
# Stage 2: Runtime
FROM eclipse-temurin:21-jre
WORKDIR /app
COPY --from=builder /build/build/libs/*.jar app.jar
RUN mkdir -p /app/logs
EXPOSE 8080
ENTRYPOINT ["java", "-jar", "app.jar"]2단계로 나눈 이유는 이미지 크기 때문이다. JDK(~450MB) 대신 JRE(~200MB)를 런타임에 쓰면 이미지가 절반 이하로 줄어든다. 배포마다 이미지가 쌓이니까 이 차이가 디스크 관리에서 꽤 중요하다.
Gradle 의존성을 먼저 다운받는 레이어를 분리한 것도 포인트인데, 소스 코드만 바뀌면 의존성 레이어는 Docker 캐시에서 가져오니까 빌드 시간이 확 줄어든다.
배포 스크립트 — deploy.sh
이게 Blue-Green 배포의 핵심이다. 전체 코드는 길어서 주요 부분만 짚어보면:
동시 배포 방지 (flock)
exec 200>"${LOCK_FILE}"
if ! flock -n 200; then
echo "[ERROR] Another deployment is already running. Exiting."
exit 1
fi누군가 SSH로 직접 deploy.sh를 실행하는 경우를 대비한 OS 수준의 파일 락이다. GitHub Actions의 concurrency 설정과 이중으로 방어한다.
해당 부분에 대해서 claudeCode에게 리뷰를 받았고 지적 받았다.
혼자서는 생각해볼 수 없는 부분인데 참고할 수 있어서 너무 좋은듯
Health Check
for i in $(seq 1 ${HEALTH_CHECK_MAX_RETRY}); do
HEALTH=$(curl -sf "http://localhost:${NEXT_PORT}/actuator/health" 2>/dev/null || true)
if echo "${HEALTH}" | grep -q '"status":"UP"'; then
echo "[Step 4] Health check PASSED"
break
fi
if [ "${i}" -eq "${HEALTH_CHECK_MAX_RETRY}" ]; then
# 실패 → 새 컨테이너 정지, 기존 유지
sudo docker stop "${NEXT_CONTAINER}" || true
sudo docker rm "${NEXT_CONTAINER}" || true
exit 1
fi
sleep ${HEALTH_CHECK_INTERVAL}
done최대 30번 × 2초 = 60초 동안 health check를 시도한다. 실패하면 새 컨테이너를 정리하고 스크립트를 종료한다. 기존 컨테이너는 건드리지 않으니까 사용자 영향 없이 자동 롤백되는 셈이다.
Smoke Test
SMOKE_RESULT=$(curl -sf "http://localhost/api/deploy-info" 2>/dev/null || true)
if echo "${SMOKE_RESULT}" | grep -q "\"version\":\"${DOCKER_TAG}\""; then
echo "[Step 6] Smoke test PASSED"
else
# Nginx를 이전 컬러로 되돌림
...
fiHealth check와 Smoke test의 차이가 중요한데:
- Health check: 컨테이너에 직접 요청 (port 8081)
- Smoke test: Nginx를 경유해서 요청 (port 80)
Nginx upstream 설정이 잘못되면 health check는 통과해도 사용자는 502를 볼 수 있다. Smoke test는 실제 사용자 경로를 그대로 테스트하는 거다.
GitHub Actions — deploy.yml
name: Blue-Green Deploy
on:
push:
branches: [ main ]
concurrency:
group: deploy-production
cancel-in-progress: false # 진행 중인 배포는 절대 취소하지 않음cancel-in-progress: false가 핵심이다. true로 하면 빠른 연속 push 시 진행 중인 배포가 취소되는데, deploy.sh가 nginx 전환 중간에 죽으면 nginx가 존재하지 않는 컨테이너를 가리키게 될 수 있다. false로 하면 첫 번째 배포가 끝날 때까지 두 번째가 큐에서 대기한다.
deploy job은 self-hosted runner에서 실행되는데, 리포에서 scripts/ 폴더만 sparse-checkout으로 가져와서 deploy.sh를 실행한다. 실제로 GitHub Actions에서 deploy가 돌아가면 이런 로그가 나온다:
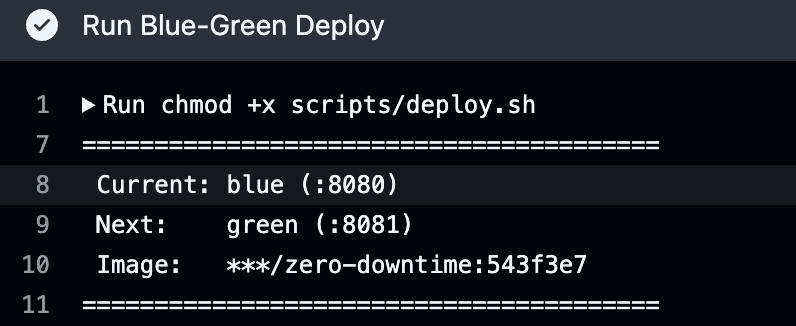
Current가 blue(:8080)이고 Next가 green(:8081)인 걸 볼 수 있다. 다음 배포 때는 반대로 green→blue가 된다.
deploy:
needs: build
runs-on:
- self-hosted
steps:
- name: Checkout deploy scripts
uses: actions/checkout@v4
with:
sparse-checkout: |
scripts
- name: Run Blue-Green Deploy
env:
DOCKER_IMAGE: ${{ secrets.DOCKER_USERNAME }}/zero-downtime
run: |
chmod +x scripts/deploy.sh
sudo -E bash scripts/deploy.sh "${{ needs.build.outputs.docker_tag }}"롤백 전략
자동 롤백: Health check 실패하면 새 컨테이너 정리하고 끝. 기존 컨테이너가 계속 돌고 있으니까 다운타임 없음.
수동 롤백: GitHub Actions UI에서 rollback.yml을 트리거하면 된다. 이전 태그를 입력하거나, 비워두면 deploy-history 파일에서 직전 성공 태그를 자동으로 찾아서 재배포한다.
# .github/workflows/rollback.yml
on:
workflow_dispatch:
inputs:
docker_tag:
description: 'Rollback할 Docker 태그. 비우면 직전 버전으로 롤백'
required: false롤백도 결국 deploy.sh를 재실행하는 거라서, health check, smoke test 등 동일한 안전장치가 적용된다.
놓치기 쉬운 것들
구현하면서 처음에 생각 못 했다가 나중에 추가한 부분들이 있다.
1. Docker 이미지가 쌓인다
배포마다 ~200MB 이미지가 pull된다. EC2 t2.micro 기본 디스크가 8GB인데, 25번 정도 배포하면 꽉 찬다. 디스크 풀 나면 docker pull이 실패하면서 배포가 막힌다. deploy.sh 마지막에 docker image prune -f를 넣어서 해결했다.
2. 로그에서 blue/green 구분이 안 된다
두 컨테이너가 같은 볼륨에 로그를 쓰는데, 태깅이 없으면 에러 로그가 이전 버전에서 난 건지 새 버전에서 난 건지 알 수가 없다. 로그 패턴에 [${DEPLOY_COLOR}]을 넣어서 해결했다.
3. 배포 이력이 없으면 롤백이 느리다
장애 나서 롤백하려는데 "이전 버전 태그가 뭐였지?" → GitHub Actions 로그 뒤져야 한다. deploy-history 파일에 매 배포마다 timestamp|color|tag|status를 기록해두니까 rollback.sh가 직전 태그를 바로 찾을 수 있다.
4. 첫 배포에서 스크립트가 죽을 수 있다
최초 배포 시 "이전 컨테이너"가 없는데, docker stop을 하면 에러가 난다. set -e 때문에 스크립트가 바로 죽는다. 모든 docker stop/rm 앞에 docker inspect로 존재 확인 + || true로 방어했다.
다음 글에서는 실제 서버에 세팅하면서 겪은 트러블슈팅과 무중단 검증 결과를 정리해보겠다.
