[Coursera] C3W4 Neural Language Processing in TensorFlow - Sequence models and literature
DeepLearning.AI TensorFlow Developer

GOAL
- 주어진 단어 다음에 올 단어를 추측하는 단어를 거쳐 전통 아이리쉬 음악으로 훈련된 모델을 이용하여 아름다운 노래를 만들어보자.
C3_W4_Lab_1.ipynb 코드 바로가기
text generation 을 위한 데이터 준비와 모델 구성을 해보자. Week3 에서 했던 것과 아주 유사하지만 약간의 변형이 필요함
Building the Word Vocabulary
dataset: Lanigan's Ball의 가사
Preprocessing the Dataset
가사의 각 라인을 받아들여 input 과 labels 를 생성해보자.
example: I am using Tensorflow
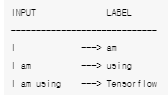
padded sequences 형식인 input 과 one-hot encoded array 인 labels 를 구해보자.
# Initialize the sequences list
input_sequences = []
# Loop over every line
for line in corpus :
#Tokenize the current line
token_list = tokenizer.texts_to_sequences([line])[0]
# Loop over the line several times to generate the subphrases
for i in range( 1 , len(token_list)):
# Generate the subphrase
n_gram_sequence = token_list[:i+1]
# Append the subphrase to the sequences list
input_sequences.append(n_gram_sequence)
# Get the length of the longest line
max_sequence_len = max([len(x) for x in input_sequences])
# Pad all sequences
input_sequences = np.array(pad_sequences(input_sequences , maxlen = max_sequence_len , padding = 'pre'))
# Create inputs and label by splitting the last token in the subphrases
xs , labels = input_sequences[:,:-1],input_sequences[:,-1]
# Convert the label into one-hot arrays
ys = tf.keras.utils.to_categorical(labels , num_classes = total_words)What is [:,:-1] in python? [duplicate]
[ : , : ]:[all rows , all columns ][ : , -1 ]: 모든 행의 마지막 열만을 포함[ : , : -1 ]: 모든 행과 마지막 열을 제외한 모든 열 포함
노래 가사의 첫 줄을 살펴 보자. 특정 줄과 기대되는 token sequence 가 표시된다.
# Get sample sentence
sentence = corpus[0].split()
print(f'sample sentence : {sentence}')
# Initialize token list
token_list = []
# Look up the indices of each word and append to the list
for word in sentence :
token_list.append(tokenizer.word_index[word])
# Print the token list
print(token_list)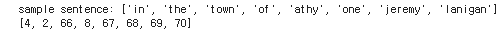
8개의 토큰이 있기 때문에 , 앞서 생성한 xs 의 첫 7개의 요소 안에서 특정한 line 을 찾길 기대한다. 만약 우리가 가장 긴 subphrase 를 가지고 있다면 , xs[6] 에서 확인 될 것이다. 아래에서 padded token 을 보자.
# Pick element
elem_number = 6
# Print token list and phrase
print(f'token list: {xs[elem_number]}')
print(f'decoded to text: {tokenizer.sequences_to_texts([xs[elem_number]])}')
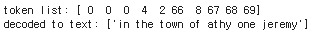
label 값을 출력해보면 70 번째에 마킹되어 있다. np.argmax() 를 이용하면 hot label 을 찾을 수 있다.
# Print label
print(f'one-hot label: {ys[elem_number]}')
print(f'index of label: {np.argmax(ys[elem_number])}')
Build the Model
이전과 같은 모델을 구성할 수 있다. 주요 차이점은 Dense layer 에 activation function 으로 softmax 함수를 쓸 수 있다는 점이다. Output layer 는 vocabulary 의 각 단어당 한 개의 neuron 을 가진다. 따라서 input token list 가 주어지면 , 마지막 layer 에서 output array 는 각 단어의 가능성이 될 것이다.
# Build the model
model = Sequential([
Embedding(total_words , 64 , input_length = max_sentence_len-1),
Bidirectional(LSTM(20)),
Dense(total_words, activation = 'softmax')
])
# Use categorical crossentropy because this is a multi-class problem
model.compile(loss='categorical_crossentropy',optimizer='adam' , metrics=['accuracy'])
# Print the model summary
model.summary()
Train the model
- 상대적으로 적은 input size 로 , 500 에포크 훈련에 단 몇 분 밖에 걸리지 않음
history = model.fit(xs ,ys , epochs = 500 )

Generating Text
훈련된 모델로 노래를 만들어보자.
- process를 초기화할 seed text 전달
- Model 이 가장 가능성 높은 다음 단어 유추
- reverse word index dictionary 에서 index 찾아보기
- seed text 에 다음 단어 추가하기
- 반복
# Define seed text
seed_text = "Laurence went to Dublin"
# Define total words to predict
next_words = 100
# Loop until desired length is reached
for _ in range (next_words ) :
# Convert the seed text to ta token sequence
token_list = tokenizer.texts_to_sequences([seed_text])[0]
# Pad the sequence
token_list = pad_sequences([token_list], maxlen = max_sequence_len - 1 , padding = 'pre')
# Feed to the model and get the probabilites for each index
probabilities = model.predict(token_list)
# Get the index with the highest probability
predicted = np.argmax(probabilities , axis = -1 )[0]
# Igmore if index is 0 because that is just the padding.
if predicted != 0 :
# Look up the word associated with the index.
output_word = tokenizer.index_word[predicted]
# Combine with the seed text
seed_text += " " + output_word
# Print the result
print(seed_text)
Laurence went to Dublin the ructions of lanigans ball ball up weeks in might ask glisten glisten glisten round relations entangled girls away chanters as as red as a rose call call glisten harp ladies ladies red round bees a rose glisten glisten glisten mavrone nelly nelly saw mavrone nelly all the catchers daughter daughter dolans dolans dolans eyes glisten glisten glisten glisten round girls round they saw weeks brooks as academy groups we rose rose rose glisten father mavrone girls away away away and her brothers all a free invitation stretched suppose suppose harp arrived glisten row dolans ill hullabaloo dolans dolans dolans동일한 단어가 많이 반복된다.
최대 확률을 가진 3개의 인덱스를 골라 무작위로 한 개를 선택할 수도 있다.
Sort 가 항상 발생하므로 시간 효율적인 방법은 아니다. 다음 단어를 고르는 방법을 생각해보자 !
# Feed to the model and get the probabilities for each index
probabilities = model.predict(token_list)
# Pick a random number from [1,2,3]
choice = np.random.choice([1,2,3])
# Sort the probabilities in ascending order
# and get the random choice from the end of the array
predicted = np.argsort(probabilities)[0][-choice][Ungraded Lab: Generating Text from Irish Lyrics
Week 4: Predicting the next word
Shakespeare's sonnets 단어 뭉치를 이용하여 학습해보자.
Tokenizing the text
tokenizer = Tokenizer()
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1 한 번에 한 줄씩 처리해야한다. 데이터를 전달하는 방식이 결과에 영향을 준다. 아래 예제에서 확인해보자.

이것을 `texts_to_sequences 로 전달하면 아래와 같은 결과를 가진다.

texts_to_sequences 가 list를 기대하고 우리가 전달한 것은 string type 이기 때문에 위와 같은 문제가 생긴다. 하지만 string 역시 Python 에서는 iterable 타입이기 때문에 , string의 모든 character 에 대해 word index 를 얻을 수 있다.
따라서 , 입력 값을 전달하기 전에는 list 에 담아야 한다.
tokenizer.texts_to_sequences([corpus[0])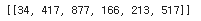
output 역시 list 로 감싸져 나오므로 , 전달한 string 에 대한 output sequences 를 얻기 위해서는 index 로 접근하여야 한다.
tokenizer.texts_to_sequences([corpus[0]])[0]
Generating n-grams : n_gram_seqs
fitted tokenizer 와 string list 인 corpus 를 입력으로 받아 corpus 의 각 line 에 대한 n_gram sequences 를 포함하는 list를 반환한다.
def n_gram_seqs( corpus , tokenizer ) :
"""
Generates a list of n-gram sequences
Args:
corpus (list of string): lines of texts to generate n-grams for
tokenizer (object): an instance of the Tokenizer class containing the word-index dictionary
Returns:
input_sequences (list of int): the n-gram sequences for each line in the corpus
"""
input_sequences = []
### START CODE HERE
for content in corpus :
token_list = tokenizer.texts_to_sequences([content])[0]
print(token_list)
num_of_tokens = len(token_list)
for idx in range( 1 , num_of_tokens ):
n_gram_sequences = token_list[:idx+1]
input_sequences.append( n_gram_sequences )
### END CODE HERE
return input_sequences 
n_gram_seqs transformation 을 전체 corpus 에 적용해보고 추후 사용하기 위해 maximum sequence length 값을 저장해두자.
# Apply the n_gram_seqs transformation to the whole corpus
input_sequences = n_gram_seqs(corpus, tokenizer)
# Save max length
max_sequence_len = max([len(x) for x in input_sequences])
print(f"n_grams of input_sequences have length: {len(input_sequences)}")
print(f"maximum length of sequences is: {max_sequence_len}")
Add padding to the sequences : pad_seqs
주어진 sequences 에 padding 을 추가하여 maximum length 와 같게 만들어보자. 이 함수는 sequences 의 list 를 입력으로 받고 padded sequences 가 있는 numpy array 를 반환해야한다.
def pad_seqs(input_sequences, maxlen):
"""
Pads tokenized sequences to the same length
Args:
input_sequences (list of int): tokenized sequences to pad
maxlen (int): maximum length of the token sequences
Returns:
padded_sequences (array of int): tokenized sequences padded to the same length
"""
### START CODE HERE
padded_sequences = pad_sequences( sequences = input_sequences , maxlen = maxlen )
return padded_sequences
### END CODE HERE
Split the data into features and labels
neural network 에 데이터를 전달하기 전에 feature 와 label 로 나누어야 한다. 이번 케이스에서는 마지막 단어가 labels 가 되고 , 마지막 단어가 제거된 n_gram_sequences 가 feature 가 된다.
feature_and_labels function 을 완성해보자. 이 함수는 padded n_gram sequences 를 입력으로 기대하고 features 와 one hot encoded labels 를 포함하는 tuple 을 반환한다.
이 함수는 또한 corpus 에 있는 words 전체를 받는다. 이 parameter 는 labels 를 one hot encoding 할 때 주요한 요소가 된다. to_categorical function 이 어떻게 작용하는지는 이 문서를 보자. (https://www.tensorflow.org/api_docs/python/tf/keras/utils/to_categorical)

Create the model
80% 의 정확도를 가진 모델을 구성해보자.
- 첫 번째 레이어 ( Embedding layer ) 의 적절한
output_dim은 100 이고 , 이미 주어져 있다. - Bidirectional LSTM 은 이 문제에 도움이 된다.
- 마지막 layer 는 corpus 내의 단어의 전체 개수와 동일한 유닛 개수를 가져야한다. 그리고 activation function 은 softmax 이다.
- 이 문제는 Embedding 을 제외하고 두 개의 layer 만으로도 해결할 수 있으니 작은 모델부터 시도해보자.
Test1
model = Sequential()
### START CODE HERE
model.add(Embedding(total_words , 100, input_length=max_sequence_len -1))
model.add( Bidirectional(LSTM(32)))
model.add(Dense( units =total_words, activation = 'softmax'))
# Compile the model
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
### END CODE HERE
Test2
### START CODE HERE
model.add(Embedding(total_words , 100, input_length=max_sequence_len -1))
model.add(Bidirectional(LSTM(64)))
model.add(Dropout(0.2))
model.add(Dense(units = total_words / 2 , activation = 'relu'))
model.add(Dense( units =total_words, activation = 'softmax'))
# Compile the model
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
### END CODE HERE
Quiz
-
When predicting words to generate poetry, the more words predicted the more likely it will end up gibberish. Why?
poetry 생성을 위해 단어를 예측할 때 , 더 많은 단어를 예측할수록 더 많이 횡설수설하는 이유는 ?- Because the probability that each word matches an existing phrase goes down the more words you create
-
What is a major drawback of word-based training for text generation instead of character-based generation?
Because there are far more words in a typical corpus than characters, it is much more memory intensive
