00. Hadoop 설치
설치 : Cloudera HDP Data Platform 2.6.5
- 사용하는 플랫폼에 맞게 다운로드
다양한 기술 간의 차이점, 어떤 것을 사용할지 결정하는 것, 어떻게 조합하여 문제를 해결할 것인지 결정하는 능력

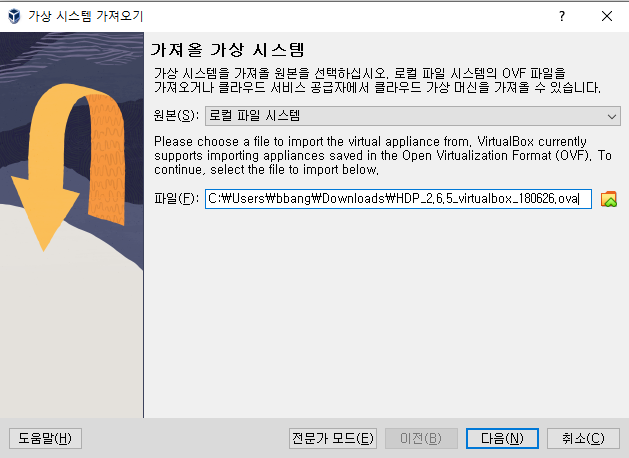
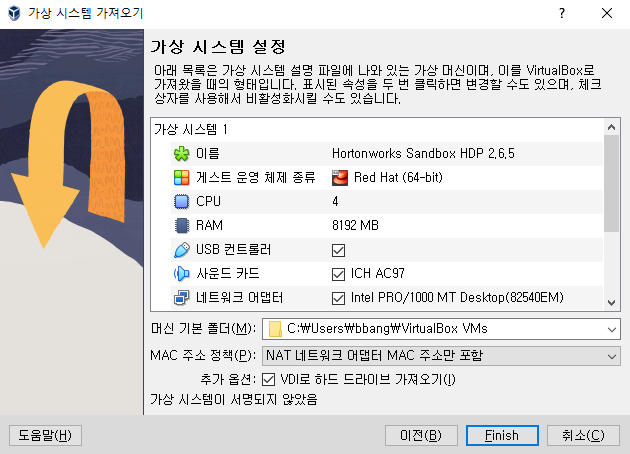
10분에서 20분 정도 소요
id : maria_dev pw : maria_dev
- 접근에 문제가 있다면 8080 port를 사용하는 다른 프로그램이 없는지 확인해보기

01. Hadoop 생태계
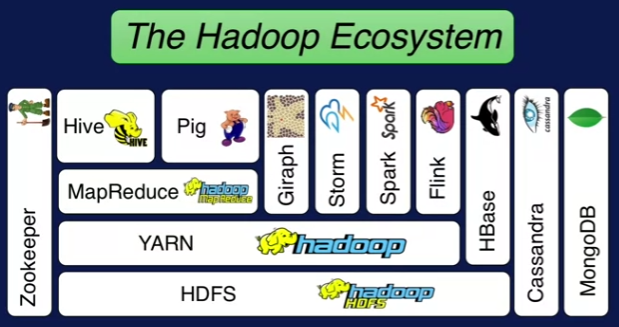
HDFS: 클러스터의 하드 드라이브들을 하나의 거대한 파일 시스템으로 사용- 데이터의 복사본을 두어 안정성을 높임
YARN:컴퓨터 클리스터의 리소스 관리- 작업 실행, 추가 작업 가능한 노드 관리 등
MapRduce: 데이터를 클러스터 전체에 걸쳐 처리하도록 하는 프로그래밍 모델- 분산된 데이터를 효율적으로 다룰 수 있음
Pig: 고수준 API로 SQL문을 MapReduce 문으로 변환하여 데이터 추출Hive: SQL 쿼리를 받아 파일 시스템에 저장된 데이터를 SQL DB처럼 취급- ODBC로 DB 접근
- 관계형 DB 처럼 사용 가능
Ambari: 클러스터 전체의 리소스 관리, 시각화, Pig, Hive 등으로 쿼리 실행- 우리가 쓸 Hortonworks도 Ambari를 사용
Mesos: YARN과 같은 리소스 관리자Spark: MapReduce와 동일 선상, YARN 이나 Mesos에 기반하여 쿼리를 실행할 수 있음- Python, Java, Scala로 스크립트 작성
TEZ: 방향성 비사이클 그래프를 사용하여 MapReduce 연산에 유리- 쿼리 실행에 효율적인 계획 수립
- 보통 Hive와 함께 사용되어 성능 가속
HBASE: NoSQL 데이터베이스- 클러스터에 저장된 데이터를 노출시킴
STORM: 스트리밍 데이터를 처리하는 방식- 센서, 웹 로그로부터 데이터 스트리밍
OOZIE: 클러스터의 작업을 스케줄링- 여러 단계나 시스템이 필요한 작업을 해야하는 경우, 일정에 따라 작업을 순차적으로 실행할 수 있도록 해줌
예를 들어데이터를 Hive에 불러와서 Pig를 통해 통합하고 Spark로 쿼리하여 결과를 HBASE로 변환하는 경우, OOZIE를 이용하여 관리할 수 있음
- 여러 단계나 시스템이 필요한 작업을 해야하는 경우, 일정에 따라 작업을 순차적으로 실행할 수 있도록 해줌
Zookeeper: 클러스터의 모든 것을 조직화- 노드가 살아있는지 추적, 여러 애플리케이션이 사용하는 클러스터의 공유 상태를 안정적으로 관리
- 특정 노드가 다운되더라도 일관성있고 안정적인 성능을 클러스터에 걸쳐 유지할 수 있음
Sqoop: Hadoop의 DB를 관계형 데이터베이스로 엮음- ODBC나 JDBC로 접근 가능한 데이터는 Sqoop을 통해 HDFS의 파일로 변형 가능
여러 쿼리 엔진들DRILLZeppelin- 클러스터와의 상호작용과 사용자 인터페이스를 노트북 유형으로 접근
HUEPHOENIX- ACID 보장, OLTP 제공 관계형 데이터베이스와 유사해짐
presto
02. HDFS
- Hadoop Distributed File System
- 빅데이터를 전체 클러스터에 분산하여 안정적으로 저장, 애플리케이션이 데이터에 접근하여 분석할 수 있음
데이터를 블록 형태로 나누어 저장
Read: Name Node와 Data Node가 있고, 요청이 오면 Name Node가 어느 Data Node의 Block에 접근할지 알려줌Write: Name Node에 요청하여 저장할 Data Node 위치를 획득하고, Data Node는 다른 Data Node에게 복사본 전달, 잘 저장되었다면 Name Node에게 저장 위치를 회신
1 ) Name Node는 한 개만 있다!
Name Node가 있는 저장소가 고장난다면 어떻게 해야할까?
a ) 메타데이터 계속 백업하기
- Name Noe의 데이터를 local disk 나 NFS(Network File System)에 백업
b ) Secondary Name Node
- Primary Name Node의 복사본을 유지
c ) HDFS Federation
- 각 볼륨마다 namespace를 두어 여러 개의 name node 사용
d ) HDFS High Availability
- Hot Backup Name Node를 운영하여 Name Node가 다운되면 교체
- 사용하지 않는 Name Node의 전원을 물리적으로 차단하여 클라이언트와 통신하지 못하도록 함
데이터를 블록으로 나누어 저장하여 회복성이 좋음
03. HDFS 실습 - ambari
1 ) Web UI
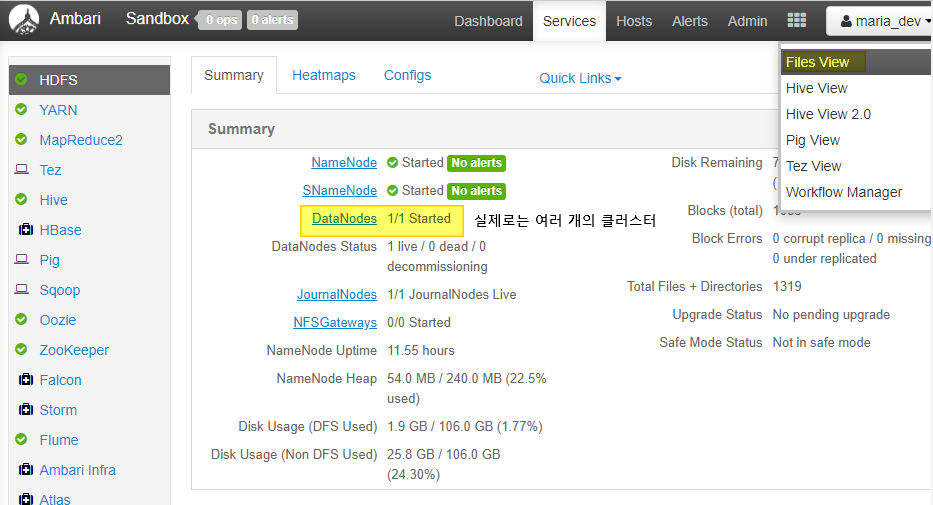
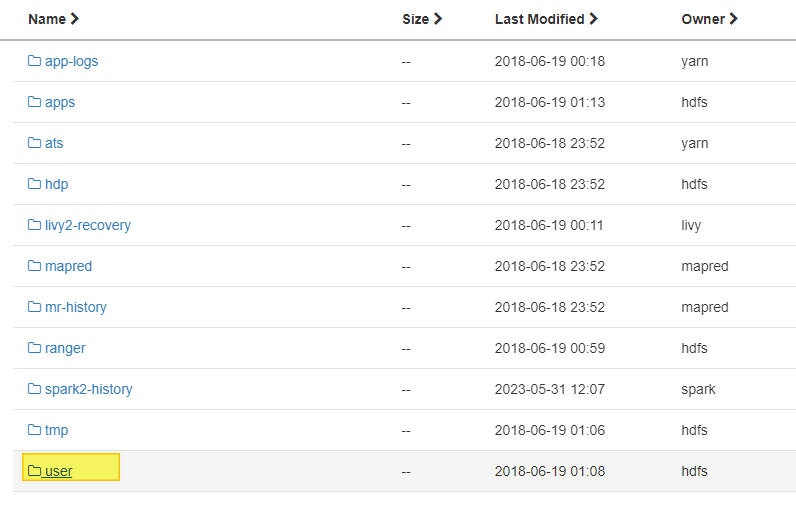
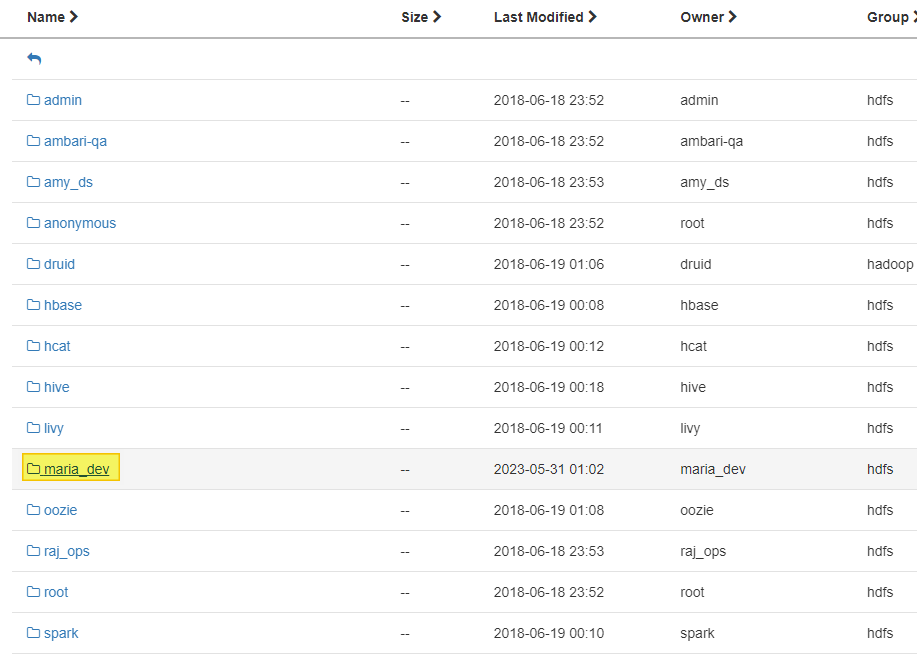

2 ) CLI
ssh maria_dev@127.0.0.1 -p 2222
Are you sure you want to continue connecting (yes/no/[fingerprint])? yeswget http://media.sundog-soft.com/hadoop/ml-100k/u.data
hadoop fs -ls
hadoop fs -mkdir ml-100k
hadoop fs -copyFromLocal u.data ml-100k/u.data
hadoop fs -rm ml-100k/u.data
hadoop fs -rmdir ml-100k