7강. Transformer 1
GOAL
- Transformer(Self-Attention)에 대한 이해
- Self-Attention이 RNN 기반 번역 모델의 단점을 어떻게 해결했는지 이해
- RNN과 Attention을 함께 사용했을 때 보다, Attention 연산만 사용할 경우, 입력 문장/단어의 representation을 학습하며 좀 더 parallel한 연산이 가능하고 학습 속도가 빠르다는 장점
Further Reading
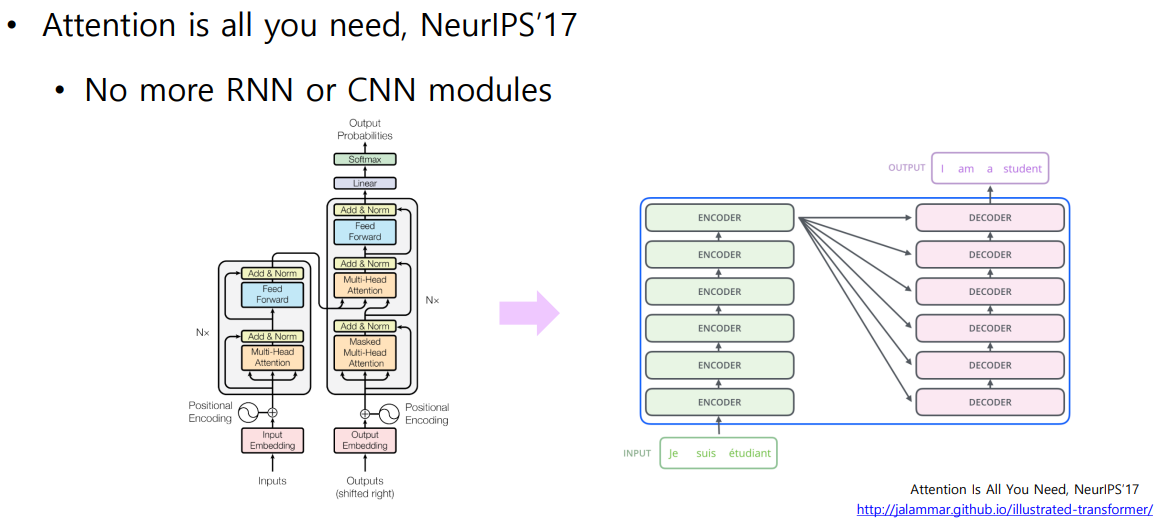
01. Transformer: High-Level View
🐬 입력 시퀀스를 인코딩하고 디코더를 통해 출력 시퀀스로 반환하는 형태
02. Transformer: Long-Term Dependency
🐬 Attention 모듈을 사용하면 주어진 sequence에서 각 단어 별로 문맥을 잘 반영한 encoding vector를 만들어 낼 수 있다 ! Attention 모듈이 어떤 역할을 하는지 알아보자.
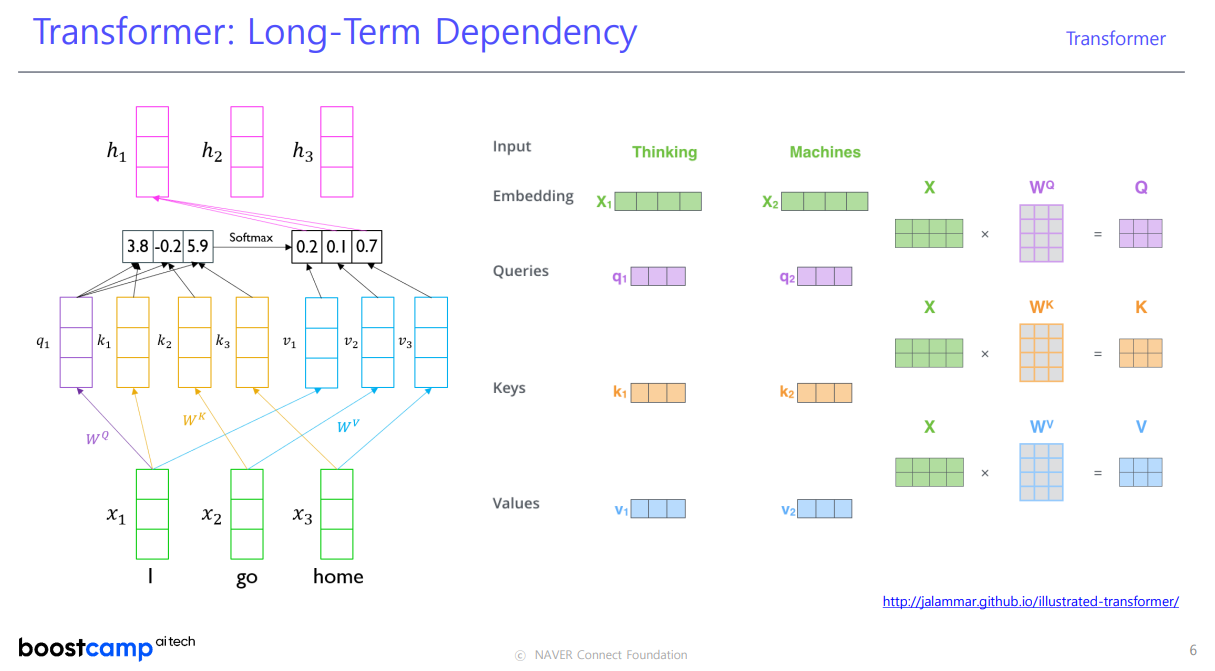
I go home 이라는 문장에서 각 단어를 선형 변환 행렬 를 통해 Query, Key, Value로 나타낸다.
STEP1특정 단어의 Query 벡터와 문장 내 단어들의 Key 벡터들과의 내적으로 유사도를 계산
- Query 벡터는 주어진 여러 개의 Key 벡터 중 어느 것과 높은 유사도를 가지는지 (어느 것을 가져올지) 결정하는 역할을 한다.
STEP2STEP1 의 결과를 Value 벡터와 연산한 값을 softmax 함수를 통해 확률 값으로 변환한다.
문장 내 각 단어들을 Input 벡터로 표현하고, 각각을 Query, Key, Value 에 해당하는 Value 벡터로 변환한다. 각 Value 벡터에 대한 가중 평균으로 Encoding 벡터가 계산된다.
입력 벡터에 대한 선형 결합 또는 가중 평균을 주어진 단어에 대한 인코딩 벡터로 생각할 수 있음
🍀 Time Step의 거리가 멀더라도 동일한 Key, Value 벡터로 변환되기 때문에 Query 벡터와의 내적 유사도만 높다면 멀리 떨어진 정보도 반영할 수 있다.
Sequence Encoding 기법으로 RNN에서 멀리 떨어진 Time Step 의 정보들이 반복 연산되며 발생하는 정보의 손실과 변질에 대한 한계점을 근본적으로 개선
03. Transformer : Scaled Dot-Product Attention
Input : Query 벡터 , key-value 쌍인
Output : Query, Key, Value 로 부터 계산된 값
- Output은 값들의 가중 합
- 각 값의 가중치는 Query 벡터와 Key 벡터들의 내적
- Query 와 Key 는 동일한 dimension 를 갖고, value는 를 갖는다.
Attension 연산은 전체 Query, Key 내적 값 합에서 특정 내적 값의 상대적 비율을 구한다.
유사도가 가장 큰 값을 구함
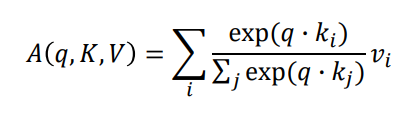
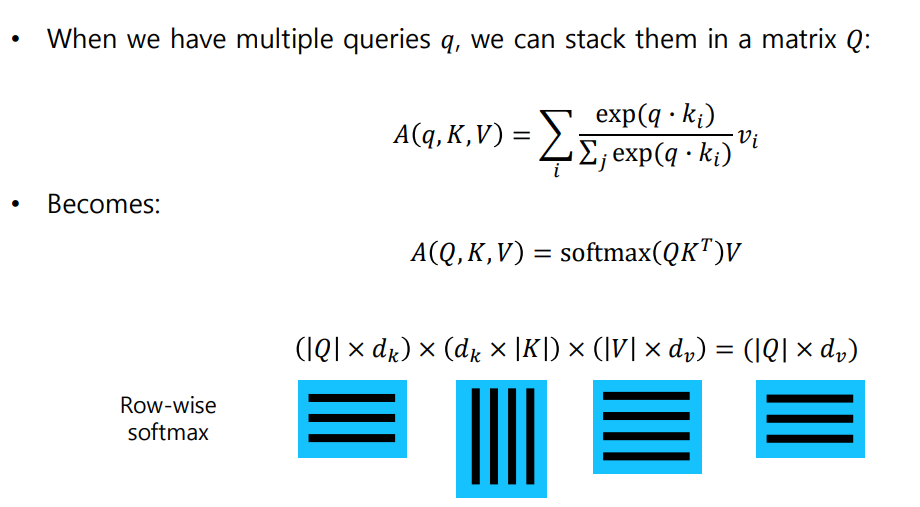
🐬 여러 Query 벡터들의 계산을 행렬 연산으로 진행하여 병렬 처리가 가능
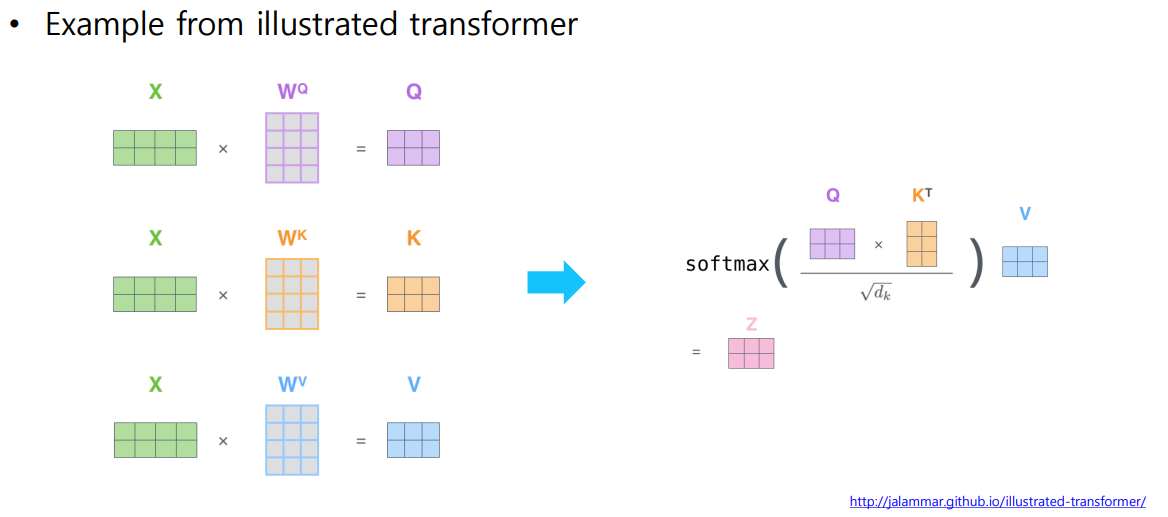
1 ) Sacaled가 필요한 이유 ( : 로 나누어주는 과정이 포함된 이유 )
🐬 Scaling 이 필요한 이유는 Query, Key 벡터의 차원이 다양하게 정의되는 데에 있다.
가정 Query와 Key 벡터의 각 원소 값이 특정 평균과 분산을 가지는 확률 변수라고 가정해보자.
가정 이 때, 는 통계적으로 독립이라고 가정한다.
- Query = (a,b), Key = (x,y)
- Query, Key 벡터의 내적 값의 분산은 각 벡터의 차원에 정비례
참고 분산 / 표준편차가 클수록 Softmax의 확률 분포가 큰 값에 몰리는 패턴을 가진다.
Scaling 을 하지 않고 softmax 연산을 할 경우, 분산에 따라 특정 key에만 몰리는 패턴이나 전반적으로 모든 key가 고른 값을 가지는 패턴이 나타날 수 있다.
- Softmax 값이 한 쪽으로 몰리는 경우, Gradient Vanising 문제 발생 확률이 높아짐
✨ Query, Key 벡터의 Dimension이 의도치 않게 Softmax 연산의 결과에 영향을 준다.
- 따라서, 내적 값의 1 ) 분산을 일정하게 유지하고 2 ) 학습을 안정화하기 위해 Scaling 을 해준다.

✨
Attention Module: 각각의 Query 벡터에 대해 Key, Value 벡터에 대한 Attention으로 Value 벡터의 가중합을 구함으로써 각 Query 벡터에서 Encoding된 Vector Output을 획득한다.
- 문제점 : 다른 단어와의 상호 작용이 단방향으로만 가능
8강. Transformer 2
✨
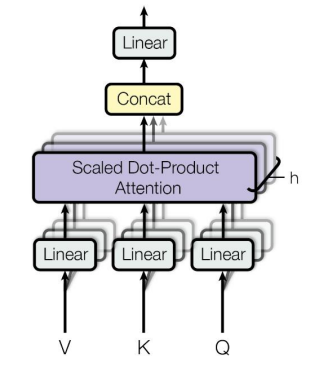
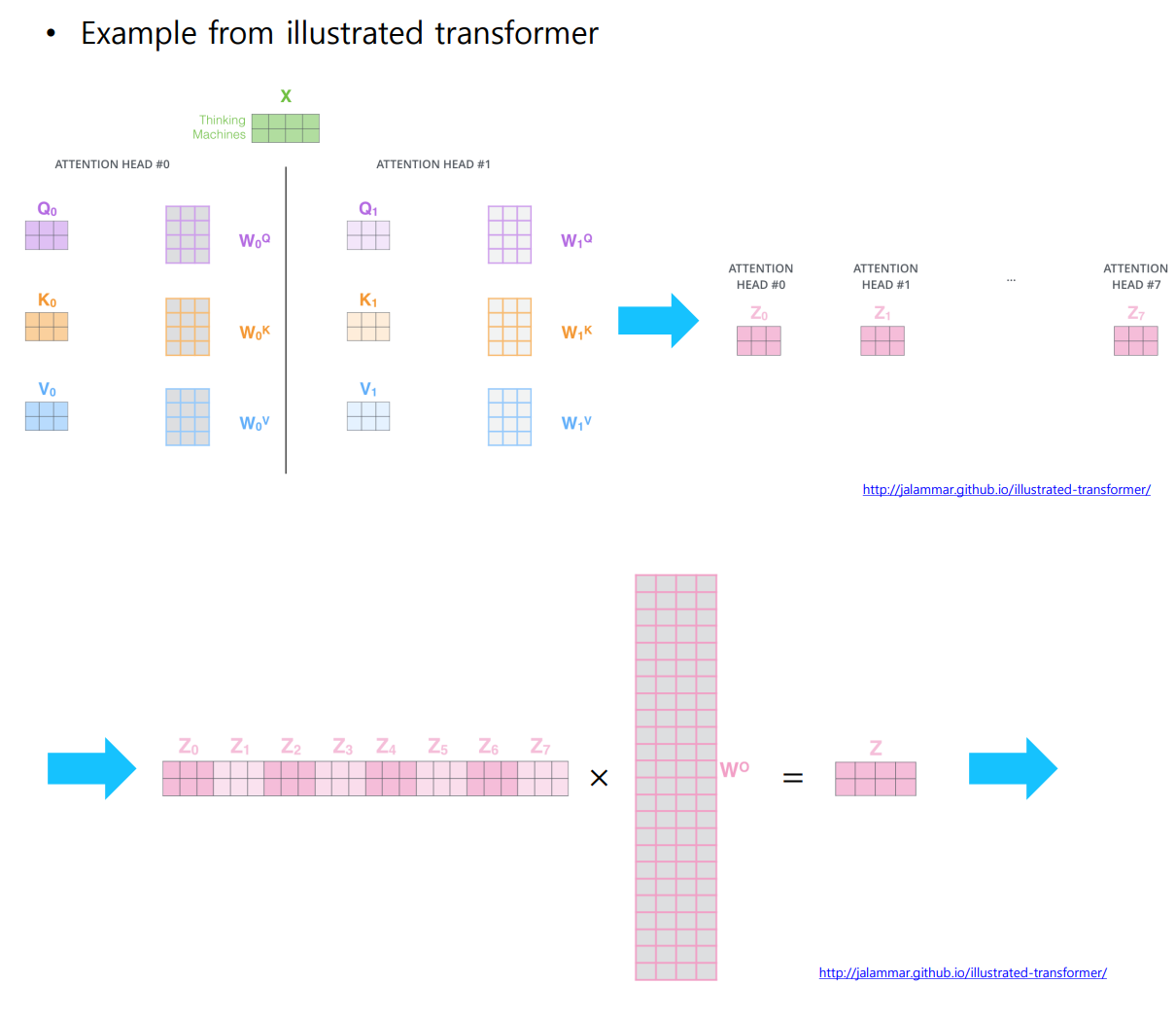
Multi-Head Attention: 동일한 Query, Key, Value 벡터에 대해 여러 개의 선형 변환 행렬을 적용하여 병렬적으로 Attention을 수행하여 각각의 head (선형 변환으로 얻어낸 Encoding 벡터) 가 상호보완적인 정보를 추출하는 역할을 한다.동일한 Sequence에서도 특정 Query Word에 대해 서로 다른 기준으로 여러 측면에서 정보를 추출
- 서로 다른 측면의 정보를 병렬적으로 추출하여 concat 을 이용해 모두 합치는 형태
01. Transformer:Multi-Head Attention
Single Attention 을 사용할 경우, 맥락을 모두 반영하지 못한다는 문제점이 있다.
Multi-Head Attention 은 병렬적으로 Attention을 수행하며 상호 보완적인 정보를 추출하기 때문에 문제점을 보완할 수 있다.
예를 들어,I wnto the school. I studied hard. 라는 문장에서 Multi-Head Attention 에서는 I studied hard. 가 school 이라는 장소에서 진행된 것임을 알 수 있다 .
=
where
참고이 때, Query, Key, Value 벡터를 생성하기 위한 projection matrix 는 각 head 별로 다른 weight matrix를 사용한다.
02. Transformer: Multi-Head Attention
- : 입력 seqeunece 에 따른 가변 값
- : dimension (hyper parameter)
- : convolutions의 kernel size
- : restricted self-attention 에서 이웃의 크기 (주변 단어의 크기)
Self-Attention :
- 는 의 내적 값이 만큼 있으므로 layer 의 복잡도는
Self-Attention의 행렬 연산은 GPU의 core 수에 따라 얼마든지 병렬 처리가 가능하다는 장점이 있지만, 행렬 연산을 위해 모두 메모리에 올려야 하므로 RNN 보다 많은 메모리를 요구한다.
- 반면, RNN은 이전의 결과 값을 사용하므로 순차적으로 학습이 진행된다.

02. Transformer: Block-Based Model
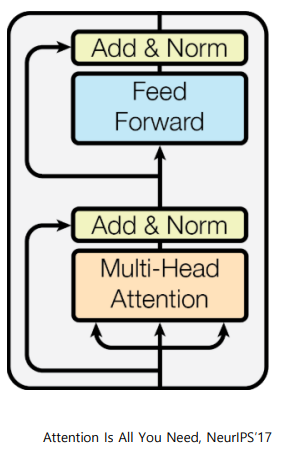
-
Residual Connection : 깊은 layer 의 network 를 만들 때, Gradient Vansishing 문제를 해결하여 학습을 안정화 시키고, layer 를 깊게 쌓아 높은 성능을 보일 수 있게 함
예를 들어I studied math. 라는 문장에서 'I' 의 Input 벡터가 (1,-4) 이고 Multi-Head Attentiond을 거친 Output 벡터가 (2, 3) 일 때, Residual Connection 을 통해 'I'의 Encoding 벡터를 (3, -1) 로 얻을 수 있다.- Multi-Head Attention은 target 값인 (3, -1)과 Ijput 값인 (1, -4)의 차이에 해당하는 값을 만들어주어야 한다.
- 이를 통해 Gradient Vanihsing 문제를 해결하고 학습을 안정화할 수 있다.
주의입력 벡터와 출력 벡터의 dimension 이 동일하게 유지되어야 한다.!- 각 dimension 별로 값을 더해 다음 값을 낼 수 있다.
-
Layer Normalization : 값들의 평균과 분산을 각각 0과 1로 정규화한 뒤, 평균과 분산을 주입하도록 선형 변환으로 구성
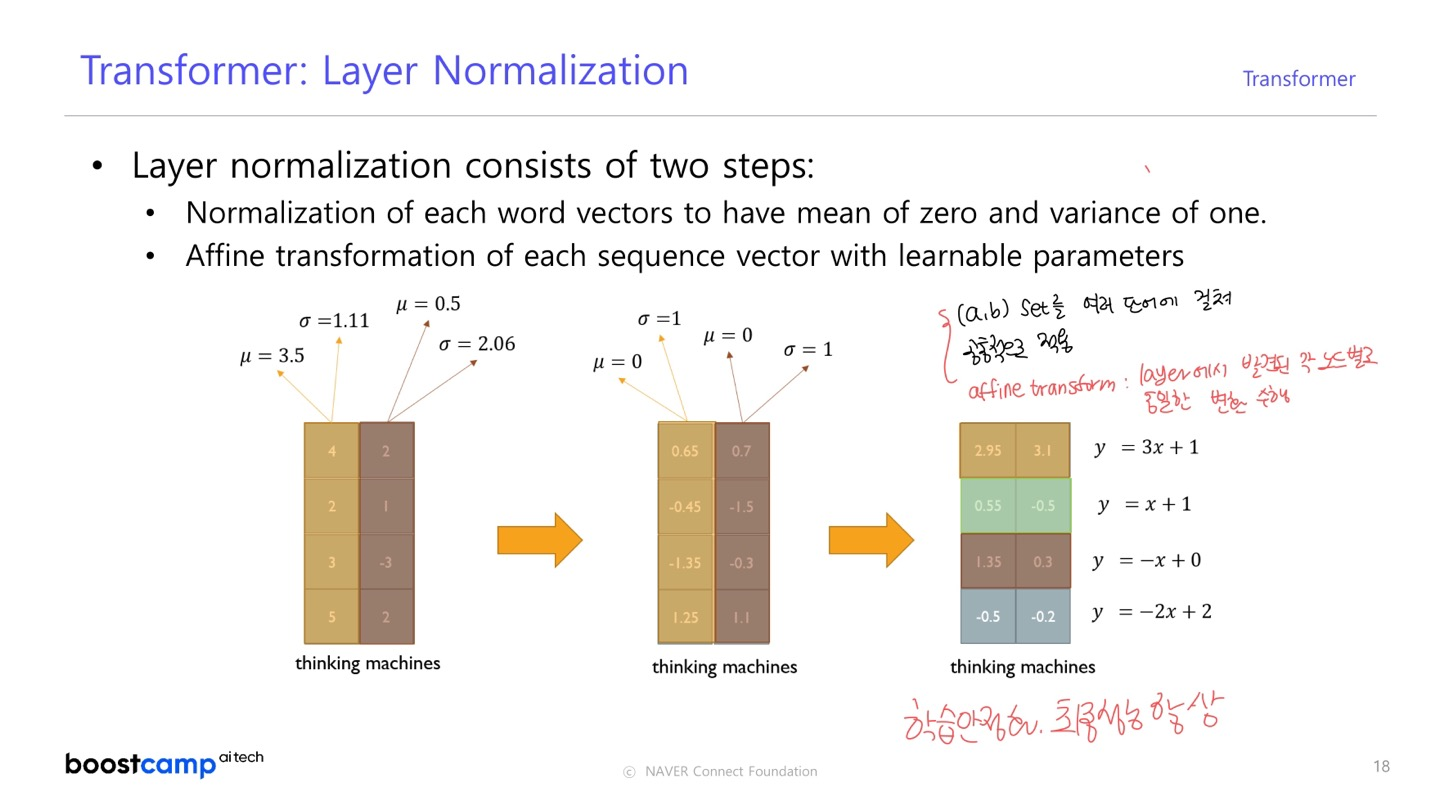
03. Transformer: Layer Normalization
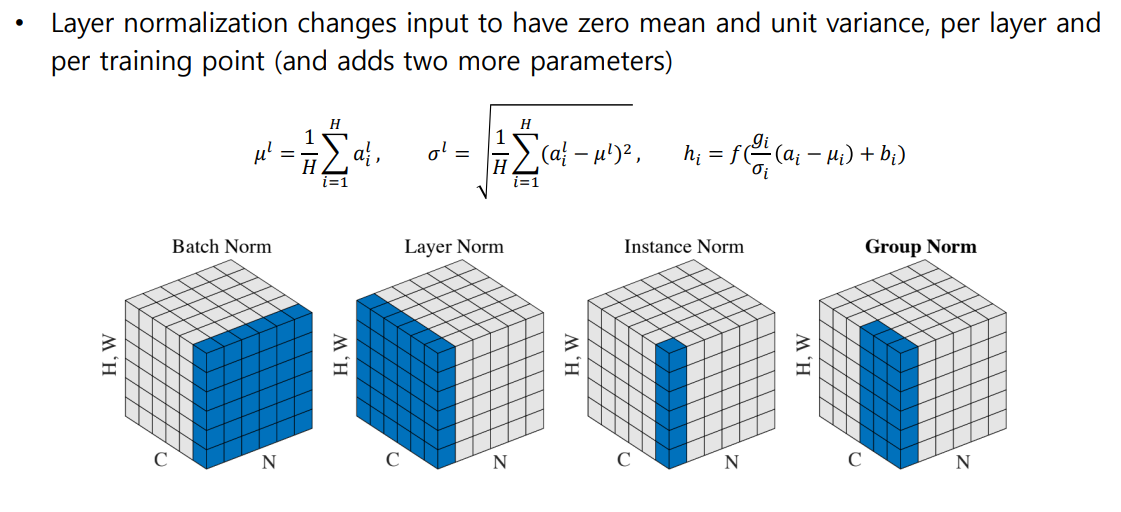
- 원래 값들이 가지던 평균과 분산 값을 표준화된 평균과 분산 0과 1로 만들어주는 과정을 거쳐, Affine Transform 연산으로 평균과 분산을 주입한다.
03. Transformer: Positional Encoding
I GO HOME , I HOME GO 에서 각 Word 의 Encoding 벡터 Output이 동일한 문제
- 각 Key 별로 주어진 Query 와의 Attention 유사도를 구하고 해당 Value 벡터의 가중치를 구해 가중합을 구함으로써 Encoding 벡터를 얻는다.
- 가중 평균을 낼 때, Value 벡터들에 교환 법칙이 적용되기 때문에 위치가 다르더라도 동일한 Encoding 벡터를 획득한다.
각 순서를 특정할 수 있도록 상수 벡터를 더해주는 과정
- sin과 cos으로 이루어진 주기 함수를 이용하여 서로 다른 주기에서 특정 값에서의 함수 값을 모아서 사용한다.
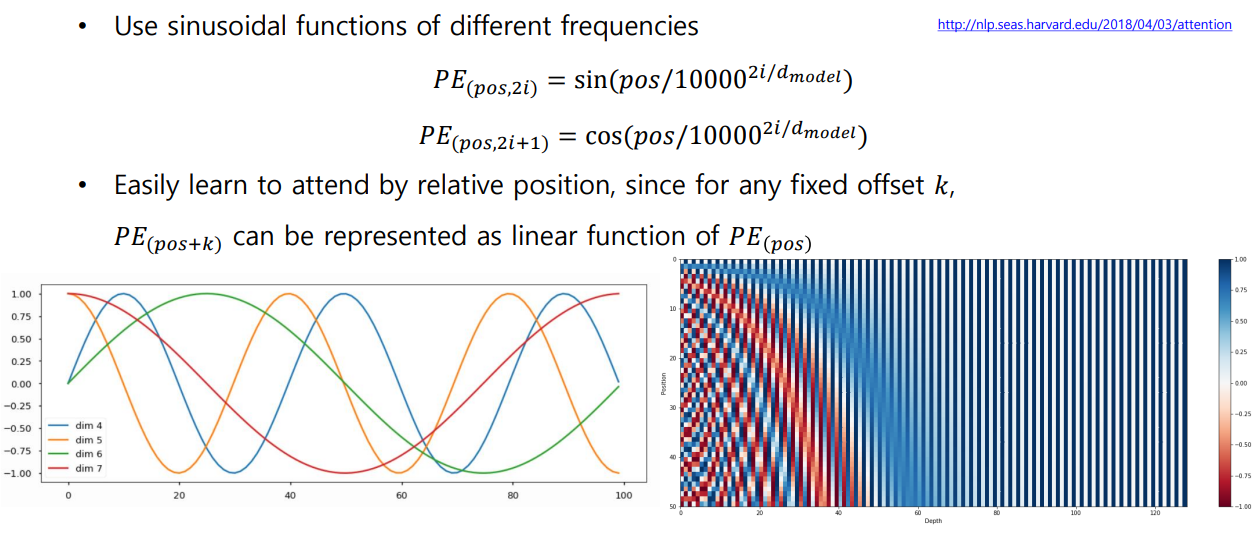
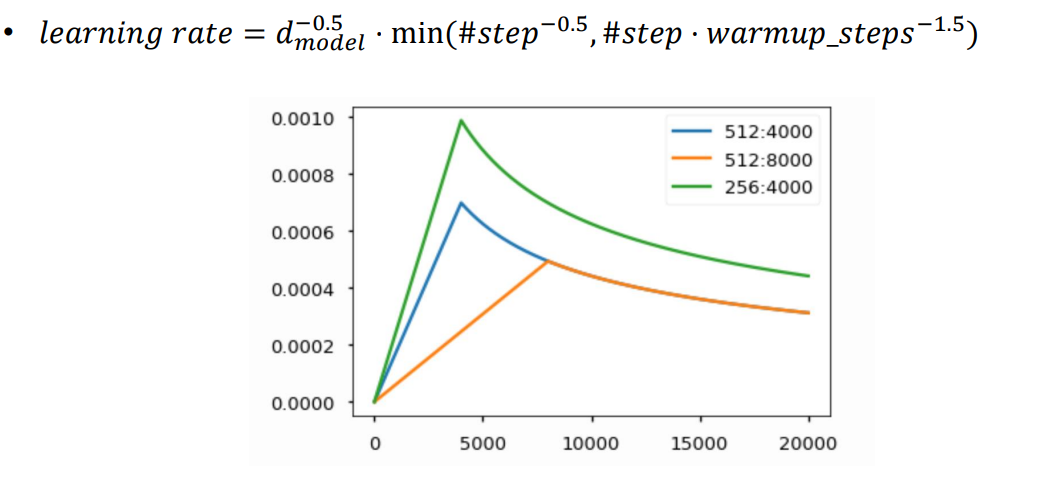
04. Transformer: Warm-up Learning Rate Scheduler
학습이 진행되면서 Optimal Value 에 잘 도달할 수 있도록 Iteration 에 따라 learning rate을 조절해주는 역할
05. Transformer: Decoder
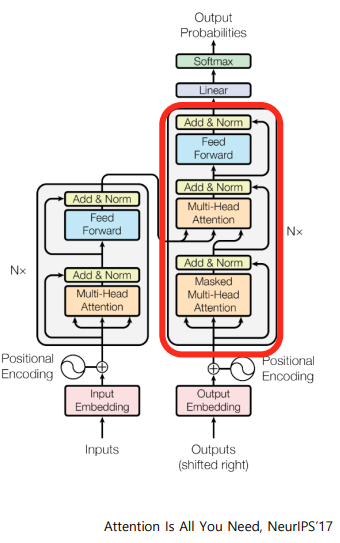
1 ) I go home 이라는 문장을 Encoding 하여 나온 Output을 오른쪽으로 한 칸 shifting
2 ) <SOS> 나는 집에 라는 문장을 다시 Encoding 한다.
- Seq2Seq모델의 Decoder에서 hidden state 벡터를 뽑는 과정과 같다.
3 ) Encoding 단의 Output 벡터가 Key 와 Value 로 사용되고, 2 ) 에서 Encoding 된 값이 Query로 사용되어 Attention이 수행된다.
Encoder 의 hidden state 벡터 중 어느 벡터에 가중치를 걸어 해당 정보를 서로 다른 Decoder의 time step 에서 가져올지 결정
4 ) Residual connection, Layer Normalization, Feed Forward 등을 추가로 거쳐 <SOS> 나는 집에 에 해당하는 각각의 벡터가 최종 값으로 나온다.
5 ) 각각의 벡터에 linear transformation 을 적용하여 target language 에 해당하는 벡터를 생성한다.
- 예를 들어, 10 만 개의 단어가 있으면, 10만 차원으로 linear transformation
6 ) Softmax 함수를 적용하여 각 확률 값을 도출한다.
7 ) 다음 단어 나는 집에 간다 라는 예측을 수행한다.
8 ) Ground truth 와 softmax loss 를 통해 back propagation 이 진행된다.
06. Transformer: Masked Self-Attention
✨ Batch Processing 을 위해 뒷 단어를 동시에 입력으로 주지만, Attention Module 을 수행할 때는 접근 가능한 Key, Value 쌍에서 뒷 단어를 제외해 주어야 한다.
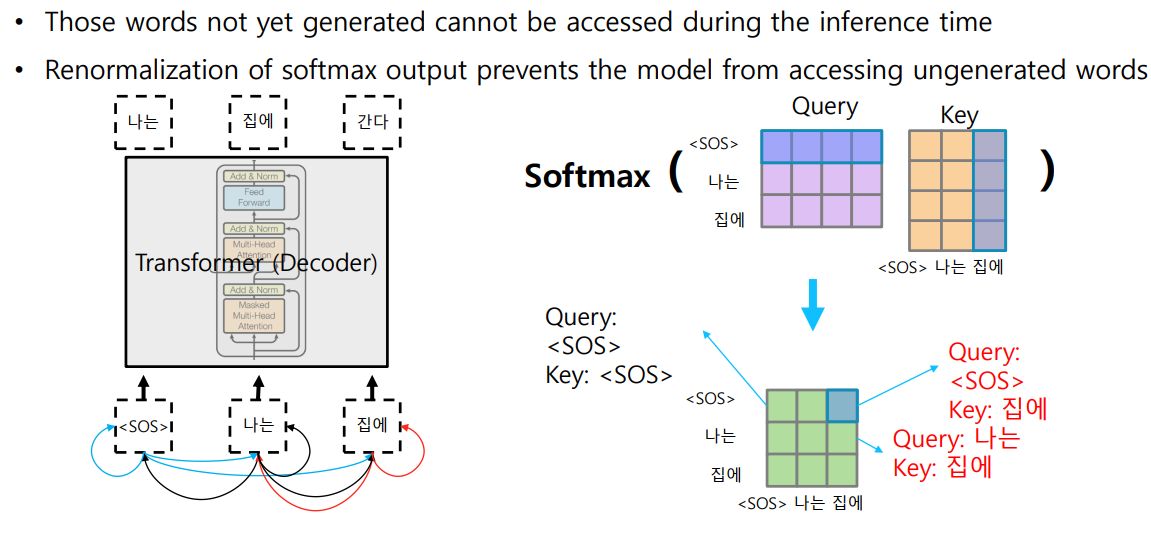
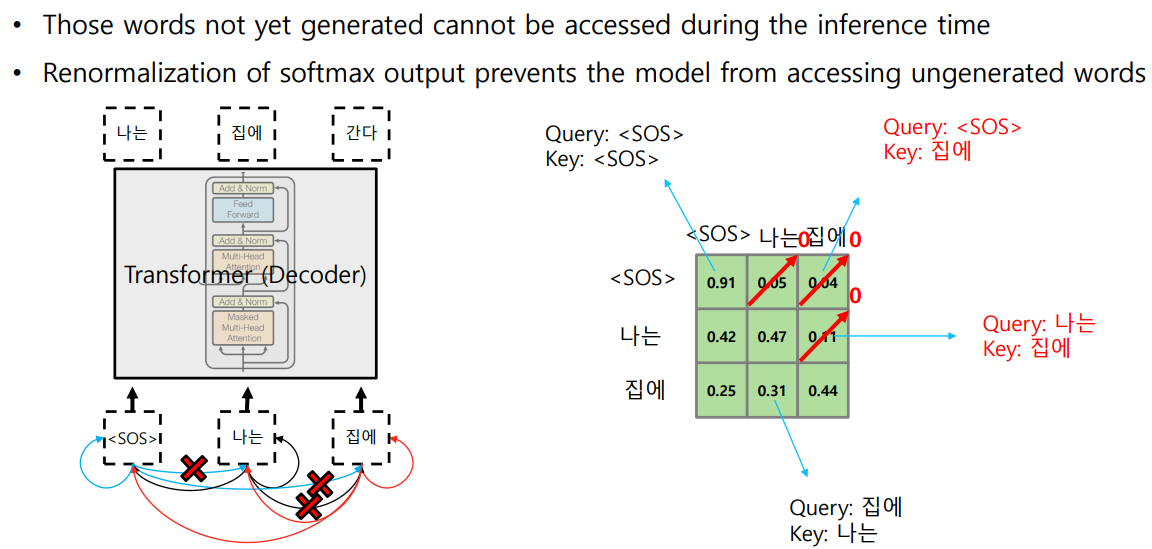
STEP1Softmax 이후에 뒷 단어들의 확률 값을 모두 0으로 후처리 해준다.STEP2Row 별 합이 1이 되도록 한다.
- 주어진 value vector 에 대한 가중 평균 (가중 합)이 1이 되도록 함
- [[0.91,0,0],[0.42,0.47,0],[0.25,0.31,0.44]] 일 때, 각각 0.91, 0.89, 1.0 으로 나누어줌
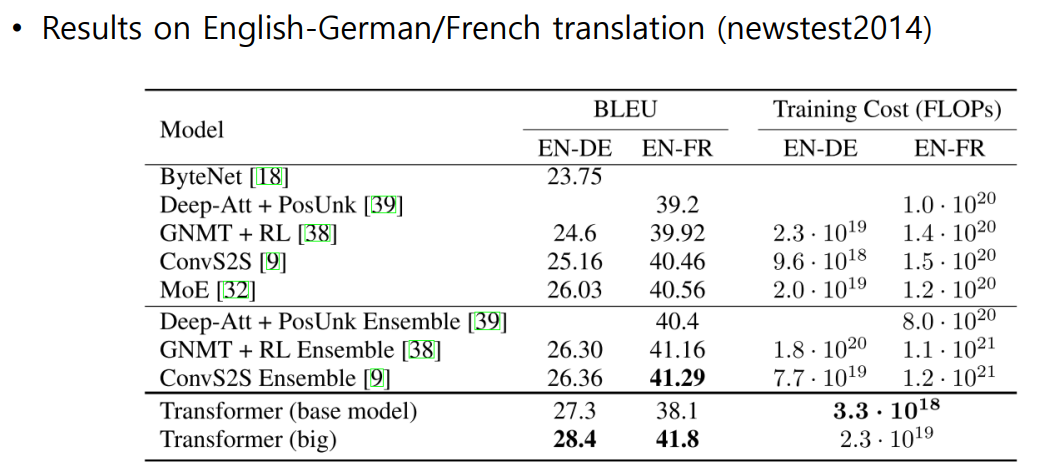
07. Transformer: Experimental Results
- 예시 :
나는 수학을 열심히 공부한다.나는 열심히 수학을 공부한다.
7강-실습. Multi head Attention
- Multi-head attention 및 self-attention 구현
- 각 과정에서 일어나는 연산과 input/output 형태 이해
01. 패키지 Import
from torch import nn
from torch.nn import functional as F
from tqdm import tqdm
import torch
import math02. 데이터 전처리
pad_id = 0
vocab_size = 100
data = [
[62, 13, 47, 39, 78, 33, 56, 13, 39, 29, 44, 86, 71, 36, 18, 75],
[60, 96, 51, 32, 90],
[35, 45, 48, 65, 91, 99, 92, 10, 3, 21, 54],
[75, 51],
[66, 88, 98, 47],
[21, 39, 10, 64, 21],
[98],
[77, 65, 51, 77, 19, 15, 35, 19, 23, 97, 50, 46, 53, 42, 45, 91, 66, 3, 43, 10],
[70, 64, 98, 25, 99, 53, 4, 13, 69, 62, 66, 76, 15, 75, 45, 34],
[20, 64, 81, 35, 76, 85, 1, 62, 8, 45, 99, 77, 19, 43]
]
# sequence 길이를 max_sequence 와 동일하게 맞추어준다.
def padding(data):
max_len = len(max(data, key=len))
print(f"Maximum sequence length: {max_len}")
for i, seq in enumerate(tqdm(data)):
if len(seq) < max_len:
data[i] = seq + [pad_id] * (max_len - len(seq))
return data, max_len03. Hyperparameter 세팅 및 embedding
d_model = 512 # model 의 hidden size
num_heads = 8 # head 의 개수
embedding = nn.Embedding(vocab_size, d_model)
# B: batch size, L: maximum sequence length
batch = torch.LongTensor(data) # (B, L)
batch_emb = embedding(batch) # (B, L, d_model)
print(batch_emb)
print(batch_emb.shape) # torch.Size([10,20,512])04. Linear transformation & 여러 head로 나누기
Muti-head attention 에서 사용되는 linear transformation matrix 정의
- query, key, value를 서로 다른 linear transformation matrix 를 사용하여 linear projection
]> - 동일한 representations (batch_emb)로부터 서로 다른 query, key, value 생성
w_q = nn.Linear(d_model, d_model)
w_k = nn.Linear(d_model, d_model)
w_v = nn.Linear(d_model, d_model)
w_O = nn.Linear(d_model, d_model)
q = w_q(batch_emb) # (B, L, d_model) [10, 20, 512]
k = w_k(batch_emb) # (B, L, d_model) [10, 20, 512]
v = w_v(batch_emb) # (B, L, d_model) [10, 20, 512]q, k, v를 num_head 개의 차원으로 분할된 여러 vector로 만들자.
batch_size = q.shape[0]
d_k = d_model // num_heads
q = q.view(batch_size, -1 , num_heads, d_k ) # (B, L, num_heads, d_k) [10, 20, 8, 64]
k = k.view(batch_size, -1 , num_heads, d_k ) # (B, L, num_heads, d_k) [10, 20, 8, 64]
v = v.view(batch_size, -1 , num_heads, d_k ) # (B, L, num_heads, d_k) [10, 20, 8, 64]
q = q.transpose(1,2) # (B, num_heads, L, d_k) # [10, 8, 20, 64]
k = k.transpose(1,2) # (B, num_heads, L, d_k) # [10, 8, 20, 64]
v = v.transpose(1,2) # (B, num_heads, L, d_k) # [10, 8, 20, 64]05. Scaled dot-product self-attention 구현
각 head에서 실행되는 self-attention 과정
attn_scores = torch.matmul(q, k.transpose(-2,-1)) / math.sqrt(d_k) # (B, num_heads, L, L)
attn_dists = F.softmax(attn_scores, dim = -1) # (B, num_heads, L, L)
attn_values = torch.matmul(attn_dists, v) # (B, num_heads, L, d_k) [10, 8, 20, 64]06. 각 head의 결과물 병합
outputs = w_0(attn_values) # [10, 20, 512]07. 전체 코드
class MultiheadAttention(nn.Module):
def __init__(self):
super(MultiheadAttention, self).__init__()
# Q, K, V learnable matrices
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
# Linear transformation for concatenated outputs
self.w_0 = nn.Linear(d_model, d_model)
def forward(self, q, k, v):
batch_size = q.shape[0]
q = self.w_q(q) # (B, L, d_model)
k = self.w_k(k) # (B, L, d_model)
v = self.w_v(v) # (B, L, d_model)
q = q.view(batch_size, -1, num_heads, d_k) # (B, L, num_heads, d_k)
k = k.view(batch_size, -1, num_heads, d_k) # (B, L, num_heads, d_k)
v = v.view(batch_size, -1, num_heads, d_k) # (B, L, num_heads, d_k)
q = q.transpose(1, 2) # (B, num_heads, L, d_k)
k = k.transpose(1, 2) # (B, num_heads, L, d_k)
v = v.transpose(1, 2) # (B, num_heads, L, d_k)
attn_values = self.self_attention(q, k, v) # (B, num_heads, L, d_k)
attn_values = attn_values.transpose(1, 2).contiguous().view(batch_size, -1, d_model) # (B, L, num_heads, d_k) => (B, L, d_model)
return self.w_0(attn_values)
def self_attention(self, q, k, v):
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k) # (B, num_heads, L, L)
attn_dists = F.softmax(attn_scores, dim=-1) # (B, num_heads, L, L)
attn_values = torch.matmul(attn_dists, v) # (B, num_heads, L, d_k)
return attn_values08. 실행
multihead_attn = MultiheadAttention()
outputs = multihead_attn(batch_emb, batch_emb, batch_emb) # (B, L, d_model)8강-실습. Masked Multi-head Attention
- Masked Multi-head Attention 구현
- Encoder-Decoder Attention 구현
01. Mask 구축
from torch import nn
from torch.nn import functional as F
from tqdm import tqdm
import torch
import math02. 데이터 전처리
pad_id = 0
vocab_size = 100
data = [
[62, 13, 47, 39, 78, 33, 56, 13],
[60, 96, 51, 32, 90],
[35, 45, 48, 65, 91, 99, 92, 10, 3, 21],
[66, 88, 98, 47],
[77, 65, 51, 77, 19, 15, 35, 19, 23]
]이 글은 네이버 커넥트재단 부스트캠프 AI Tech 교육자료를 참고했습니다.
