3강. Basics of Recurrent Neural Network
GOAL
- 자연어 처리 분야에서 Recurrent Neural Network(RNN)를 활용하는 다양한 방법
- RNN 을 이용한 Language Model 학습
- Language Model : 이전에 등장한 단어를 condition으로 다음에 등장할 단어를 예측하는 모델
- 이전에 등장한 단어는 이전에 학습했던 다양한 neural network 알고리즘을 이용해 표현될 수 있음
RNN을 이용한 character-level의 language model에 대해서 알아봅니다.Further More
- RNN을 이용한 Language Model 에서는 초반 time step 의 정보를 전달하기 어려운 문제가 있는데, 어떻게 보완 했을까?
- gradient vanishing/exploding을 해결하기 위한 방법에는 어떤 것들이 있을까?
01. 기본 구조
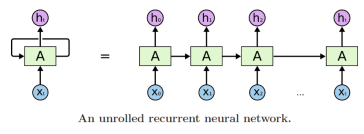
🐬 서로 다른 time step에 들어오는 입력 데이터를 처리할 때 동일한 parameter를 가지는 Recurrent Neural Net Module을 매 time step 에서 동일하게 사용하는 구조
참고은 hidden state vector 를, 는 현재 word 정보를 나타낸다.
- 특정 time step에서 원하는 task에 맞는 출력값 y를 계산해주어야 한다.
02. 계산
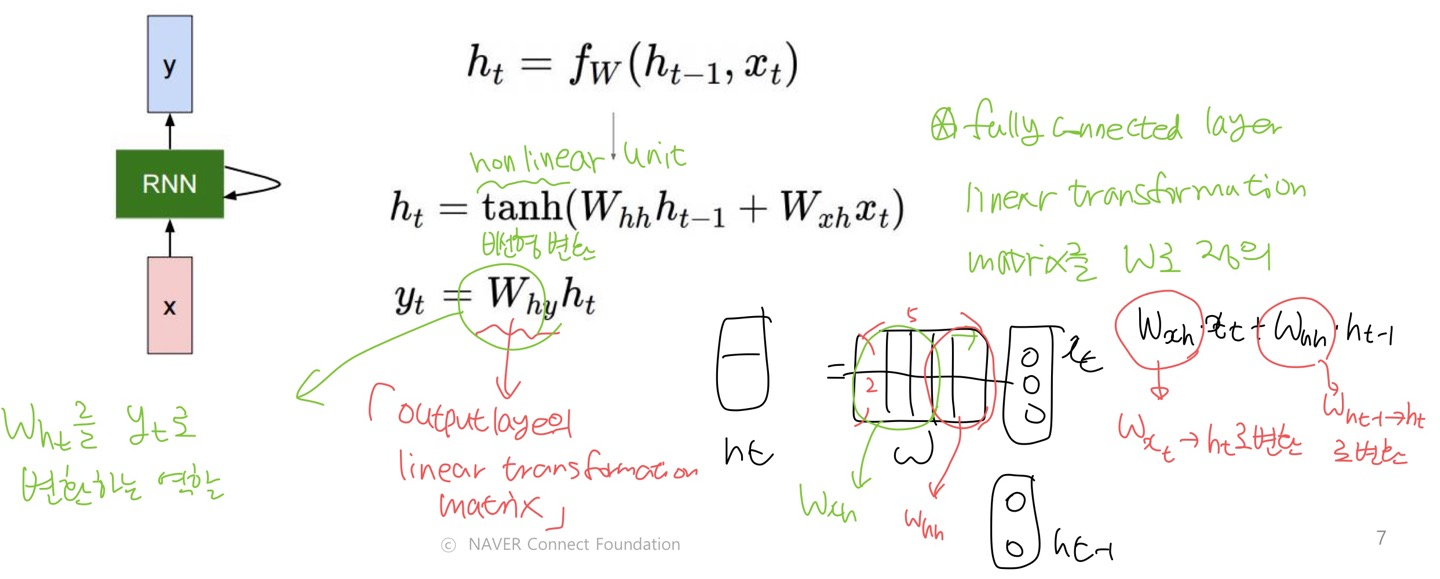
1 ) 식
- : 이전 hidden state vector
- : 특정 time step에서의 input vector
- : 새로운 hidden state vector
- : parameters W 를 가지는 RNN 함수
- linear transformation matrix (선형 변환 행렬) 를 나타내는 parameter
- : time step t에서 output vector
- output vector를 계산하는 타이밍은 task 마다 다름
- 품사 예측 같이 매 time step 마다 예측해야 하는 task
- 긍정 또는 부정 예측 같이 마지막 time step 에서만 예측하는 task
- output vector를 계산하는 타이밍은 task 마다 다름
✨ Recurrent Neural Net (RNN) module을 정의하는 parameter W는 모든 time step에서 동일한 값을 공유한다.
2 ) RNN의 hidden state 계산
- 는 을 로 변환하고, 는 를 로 변환한다.
- linear transformation matrix 를 와 로 나누어 생각할 수 있다.
03. Types of RNNs
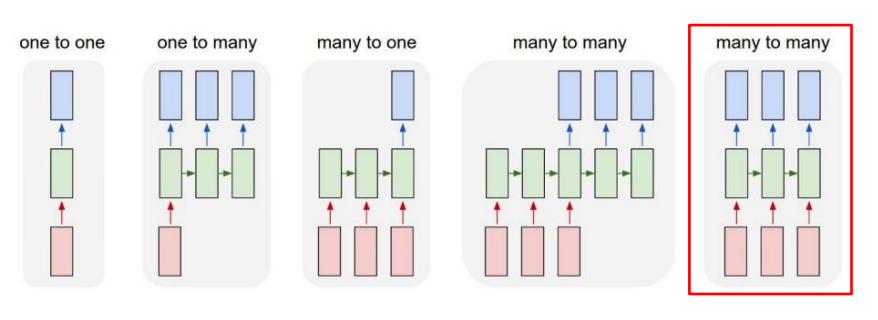
- 입력 또는 출력이 sequence data 인 경우
- 입력과 출력 모두 sequence data 인 경우
One-to-One
전형적인 Neural Networks
One-to-many
하나의 Input에서 time step 마다 output 이 존재하는 task
한 번의 Input 이후 각 time step 의 입력은 값이 모두 0인 동일한 사이즈의 벡터/행렬/텐서 이다.
- Image Captioning 등에 사용됨
Sequence-to-sequence:Machine Translation
Sequence-to-sequence:Video classification on frame level
입력이 주어질 때마다 예측하는 것으로 딜레이를 허용하지 않는다.
- Tagging task 또는 video 분류 프레임 (프레임 별 예측) 에 사용된다.
04. Character-level Language Model
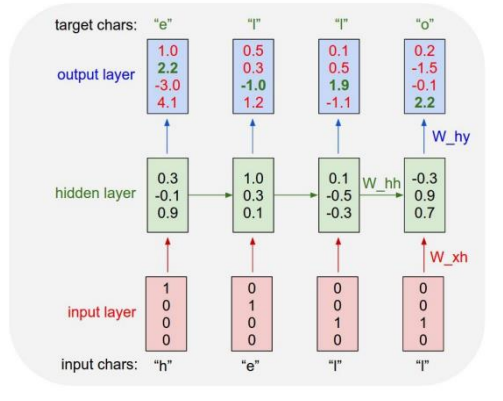
- Logit =
- : output layer 에서 정의된 선형 변환 행렬 (linear transformation matrix)의 parameter
첫 번째 character 만 입력으로 주고, 예측 값은 다음 time step의 입력으로 사용한다.
- 무한한 길이의 character sequence 생성
응용: 특정 회사의 과거 주식 데이터를 학습하여 특정 시점의 주식 값을 입력으로 주고 먼 미래의 주식 값을 예측하는 task
05. RNN의 한계점
- Gradient Vanishing / Explosion 문제
- 매 time step 마다 동일한 matrix 가 계속 곱해져 gradient 가 폭발하거나 소실되는 문제
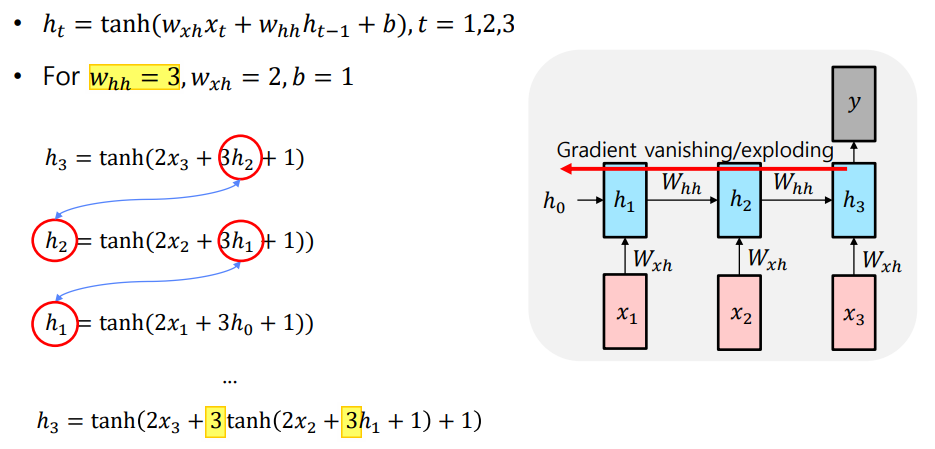
- 매 time step 마다 동일한 matrix 가 계속 곱해져 gradient 가 폭발하거나 소실되는 문제
- Long Term Dependency 문제
4강. LSTM, GRU
GOAL
- LSTM과 GRU에 대한 이해
- LSTM과 GRU가 gradient flow를 개선할 수 있는 이유 이해
01. Long Short-Term Memory (LSTM)
🐬 Original RNN의 문제점인 Long Term Dependency 문제를 개선
- Original RNN :
- 는 linear transformation matrix 를 가지는 RNN 모델
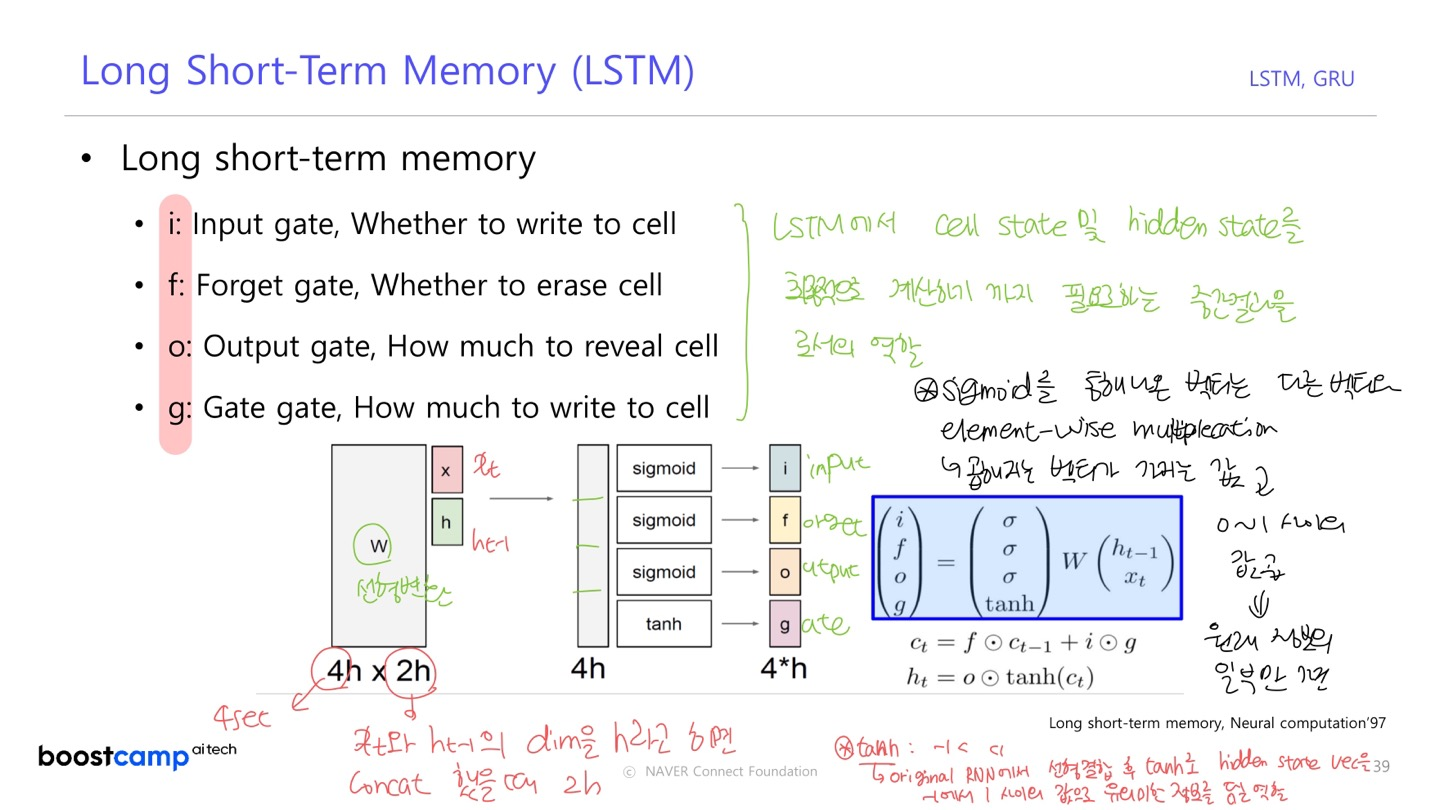
- LSTM :
- : cell state
- : cell state 를 한 번 더 가공한 값으로 해당 time step 에서 노출할 filtering 된 정보를 담은 vector
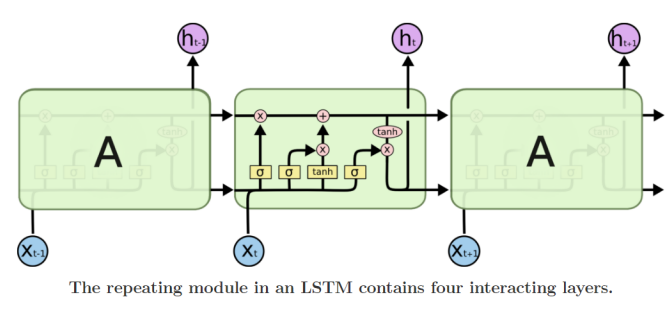
1 ) Long short-term memory
LSTM에서 cell state 및 hidden state 를 최종적으로 계산하기까지 필요로 하는 중간 결과물로의 역할
input, forget, output, gate gate는 이전 time step에서 나온 을 적절하게 변환하는 데에 사용된다.
- Input Gate
- Forget Gate
- Output Gate
- Gate Gate
a ) Forget Gate
이전 단계에서 넘어온 값 중 일부만 반영한다.
예를 들어,[3, 5, -2] 를 [0.7, 0.4, 0.8] 과 내적한 값 [2.1, 2, -1.6]
b ) Input Gate
한 번의 선형 결합만으로 에 더해줄 (반영해줄) 정보를 만들기 어려운 경우,
더해주고자 하는 값보다 좀 더 큰 값으로 구성된 값을 로 만들어 준 후,
각각의 dimension에 해당하는 특정 비율만큼의 정보를 반영
c ) output gate
- 는 -1과 1 사이의 값, 는 sigmoid 함수의 결과 값으로 0과 1 사이의 값
- cell state 값에 적정 비율만큼 작게 만들어 구성
: 기억해야하는 모든 정보를 담고 있는 벡터
: 현재 time step 에서 예측 값을 내는 output layer의 입력으로 사용되는 벡터
- 현재 time step의 예측 값 중 필요한 정보만을 담음
02. Gated Recurrent Unit (GRU)
🐬 LSTM 과의 차이점
- 적은 메모리 사용량
- cell state vector 와 hidden state vector 를 일원화하여 와 만 사용
- 빠른 계산
- 과 의 가중 평균
- 은 LSTM의 cell state 와 비슷한 역할
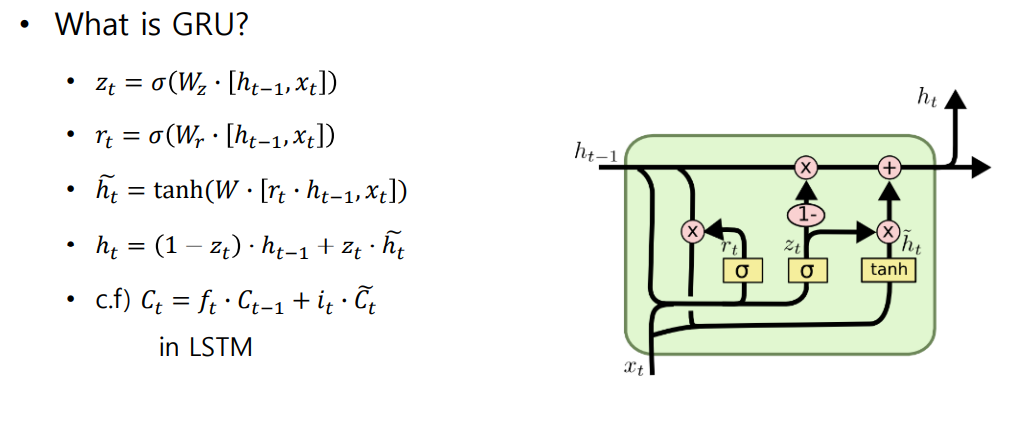
input gate 만 사용하고, output gate 는 로 대체
✨ Cell state vector 가 업데이트 되는 과정이 덧셈이므로 back propagation 과정에서 gradient가 복사된다.
- Gradient vanishing / explosion 발생할 확률이 줄어든다.
- 먼 time step까지 gradient를 큰 변화없이 전달할 수 있다. (Long Term Dependency 문제가 줄어듦)
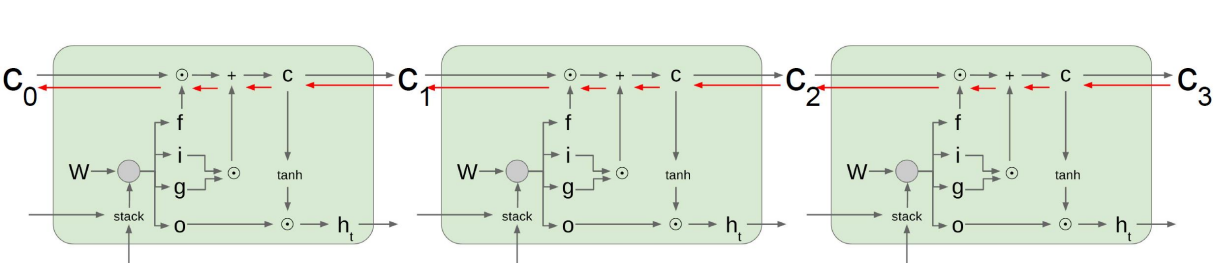
03. Summary on RNN/LSTM/GRU
- 다양한 길이를 가질 수 있는 sequence data에 특화된 유연한 형태의 구조
- Vanilla RNN 에 비해 간단하지만 좋은 성능
- Cell state vector 와 hidden state vector 를 각 time step에서 업데이트 하는 과정이 기본적으로 덧셈에 기반하여 Gradient Vanising/Explosion 문제와 Long Term Dependency 문제를 개선
04 Quize
1 ) 다음 LSTM 모델의 총 파라미터의 수는 ?
LSTM 모델 구조
- 은닉층 1개
- 입력 ()의 차원 25
- 은닉 상태 (h_{t-1})의 차원은 100
- LSTM 의 각 게이트는 bias 를 가진다.
LSTM의 입력 차원을 m, hidden state 의 차원을 n 이라고 할 때, 각 게이트 (input, output, forget, gate) 연산에 사용되는 그리고 bias 로 구성되고 각각 개의 파라미터를 가진다.
따라서, 4개의 게이트 연산에서 사용되는 파라미터의 수는 개 이고, 문제에서 주어진 차원 () 을 대입하여 계산하면 총 50400개의 파라미터를 가진다.
이 글은 네이버 커넥트재단 부스트캠프 AI Tech 교육자료를 참고했습니다.
