2강. Word Embedding
Word2Vec 과 Glove 는 하나의 차원에 단어의 모든 의미를 표현하는 one-hot-encoding 과 달리 단어의 distributed representation을 학습하고자 고안된 모델
GOAL
- Word2Vec 과 GlobVe 가 단어를 학습하는 원리를 중심으로 이해
Further Questions
- Word2Vec 과 Glove 알고리즘이 가지고 있는 단점은 ?
- Word2Vec 의 단점은 vocabulary 의 크기가 클 때 모델이 softmax 함수를 사용하여 학습하기 어려운 것이다.
- GloVe 의 단점은 단어의 co-occurence 행렬이 꽤 많은 양의 메모리를 요구하고, co-occurence 행렬과 관련된 hyper parameter 를 변경할 경우 행렬을 다시 계산해야해서 시간이 소요된다.
- 두 알고리즘 모두 vocabulary 외의 단어를 표현하지 못하고, 반의어 쌍을 분리하기 어려운 문제점이 있다.
Further Reading
Word Emebedding이란, 단어들을 특정 차원으로 이루어진 공간 상의 한 점으로 표현하는 것
Word Emebedding이란, 단어들을 점의 좌표로 나타내는 벡터로 변환해주는 기법
비슷한 의미를 가지는 단어가 좌표공간 상에 비슷한 위치의 점으로 맵핑
- 단어 간 의미 유사도를 잘 반영한 벡터 표현을 제공한다.
01. Word2Vec
🐬 맥락 속 단어에서 단어의 벡터 표현에 대한 알고리즘
- 같은 문장에서 나타난 인접한 단어들의 의미적 연관성이 높다는 점을 이용
- 비슷한 맥락에서 사용되는 단어들은 의미적 유사도가 높을 것이라는 가정
KEY SENTENCE
입력 단어와 출력 단어의 벡터 내적 값이 최대한 커지도록 학습하는 것
1 ) 방법
a ) 문장 내의 unique 한 단어들로 사전을 구축한다.
- 사전의 각 단어는 voca size 만큼의 dimension 을 가지는 one-hot-vector 형태
b ) Sliding Window 방식으로 기준 단어 앞뒤로 나타난 단어 각각과 입출력 단어 쌍을 구성한다.
- 주어진 학습 데이터에 대해 각 문장 별로 sliding window 를 적용한다.
- 중심, 주변 단어 각각을 단어 쌍으로 구성하여 word2vec 의 학습 데이터를 구성한다.
예를 들어 I study math. ( window size = 3 )
- ( I, study )
- ( study, I )
- ( study, math )
softmax 함수를 통해 3차원 벡터가 확률 값을 가지도록한다.
- softmax 함수의 입력인 logit 으로 전달되는 값이 양의 무한대에 가까울수록 해당 class 로 분류 확률이 높아진다.
- 추론된 확률 분포 벡터와 실제 값의 거리가 최대한 가깝도록 softmaxloss 를 줄이는 방향으로 학습된다.
입력 단어의 상에서의 벡터와 출력 단어의 상에서의 벡터의 내적 값이 최대한 커지도록 한다.
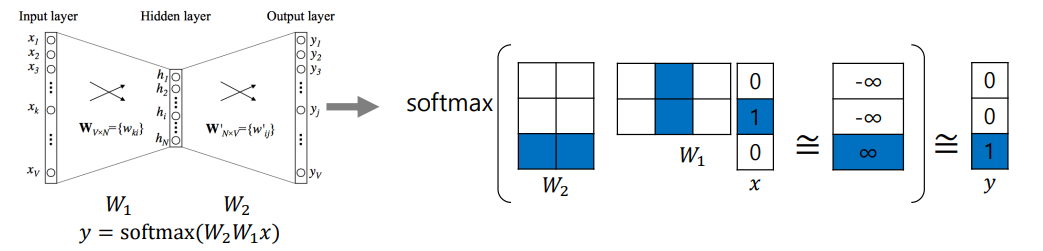
- : Linear Transformation Matrix
- one-hot-vector 자리에 해당하는 column vector 를 뽑아오는 과정
- hidden layer (hyper parameter) : word embedding 을 구성하는 좌표 공간의 차원 수와 동일
2 ) 특징
a ) word들 간의 의미론적 관계가 vector embedding의 결과에 잘 반영됨
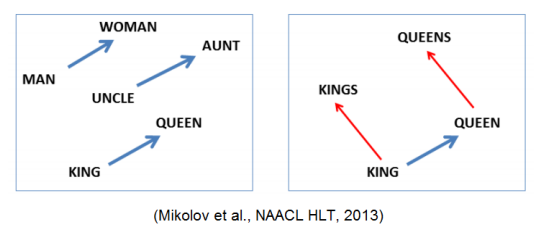
b ) 여러 단어가 주어졌을 때 나머지와 의미가 가장 상이한 것을 탐색하는 과제도 잘함
- 단어들 간의 euclidean distance들의 평균 값을 계산하여 평균 거리가 가장 큰 단어를 찾아낸다.
- 예시 : word intrusion detection
Word2Vec 은 아래 역할로 사용되며, 기계 번역, 품사와 고유 명사 태깅, 감성 분석 등에 활용할 수 있다.
- 단어 자체의 의미를 파악
- 단어 단위의 vector 를 task 의 입력으로 제공
02. GloVe: Global Vectors for Word Representation
Word2Vec 과 차이점 : 각 입력 및 출력 단어 쌍에 대해 학습 데이터에서 두 단어가 한 window에서 동시에 총 몇 번 등장하는지 미리 계산해두는 점
입력 단어와 출력 단어 쌍이 한 window에서 동시에 몇 번 등장하는지 미리 계산하여 로그 값으로 표현한다.
이 값과 예측된 값의 내적 값이 가까워질 수 있도록하는 새로운 형태의 loss function 을 사용한다.
1 ) 장점
- 중복 계산이 적다.
- 학습 속도가 빠르다.
- 적은 데이터에서도 잘 동작한다.
- Word2Vec 은 특정 단어 쌍이 자주 등장할 경우 여러 번 학습되어 내적 값이 커진다.
- Glove 는 단어 쌍이 동시에 등장하는 횟수를 미리 계산하여 로그 값을 취한 것이다.
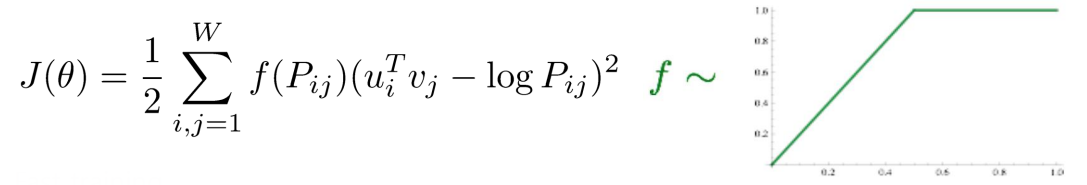
2 ) 참고
- 이미 학습된 말뭉치를 사용할 수 있다.
- 400만 개의 unique 한 단어들을 word embedding vector로 나타난 것
이 글은 네이버 커넥트재단 부스트캠프 AI Tech 교육자료를 참고했습니다.
