4강 AutoGrad & Optimizer
GOAL
- Pytorch의 Module, Parameter 와 Backward 과정 - Optimizer 에 대한 학습
- nn.Module 을 통해 기본적으로 Pytorch 에 구현되어 있는 네트워크 텐서 모듈들을 살펴보자.
- nn.Parameter 가 Module 내부에서 어떤 역할을 하는지 학습
- Backward 함수가 작동하는 방식을 확인해 직접 구현해보는 시간
# Further Question
1. epoch에서 이뤄지는 모델 학습 과정을 정리해보자. 성능을 올리기 위해서 어떤 부분을 먼저 고려하면 좋을지 팀원들과 생각해보자.
- gradient 초기화
- input 에 대한 model output 과 label 값의 차이 ( loss 구하기 )
- backward 로 parmeters 에 관한 미분 값 구하기
- optimizer 로 parameter value 업데이트 하기
- 연관 내용 : #### Backward 기본 과정
2. optimizer.zero_grad()를 안하면 어떤 일이 일어날지 생각해보자. 그리고 매 batch step마다 항상 필요한지 팀원들과 논의해보자.
- 이전에 사용하던 gradient 값이 남아있어 부정확한 gradient 계산이 된다. 이전에 업데이트된 gradient 에 영향을 받지 않기 위해 항상 필요하다.AutoGradient 를 구성하는 Optimizer 의 구성과 process 에 대해 알아보자.
torch.nn.Module
- 딥러닝을 구성하는 Layer 의 base class
- 네 가지 정의가 필요하다.
- Input data
- Output data
- Forward 동작
- Backward 동작 :
AutoGrad자동 미분- 학습의 대상이되는 weight 값을 미분해준다.
- Tensor 객체를 상속 받은
parameter class 로 정의
- Tensor 객체를 상속 받은
- 학습의 대상이되는 weight 값을 미분해준다.
nn.Parameter
- Tensor 객체의 상속 객체
- nn.Module 내에서 attribute 로 사용될 때는
required_grad = True로 지정되어 학습의 대상이 되는 Tensor - 일반적으로 PyTorch 내에 구현된 layer를 사용하기 때문에, weights 값들이 지정되어 있다.
- 직접 지정할 일은 잘 없다.
weight 를 nn.parameter 대신 Tensor class 로 선언하면 미분 대상에 속하지 않기 때문에
module.parameters로 확인할 수 없다.
xw+b 모듈을 작성해보자.
class MyLiner(nn.Module):
def __init__(self, in_features, out_features, bias = True):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weights = nn.Parameter( torch.randn(in_features, out_features))
self.bias = nn.Parameter(torch.randn(out_features))
def forward(self, x : Tensor):
return x @ self.weights + self.biasdata와 feature
- data 2개 , feature 3개
>>> x = torch.randn(2, 3)
tensor([[ 0.8110, 1.2075, 0.3604],
[ 1.3843, -0.1228, -0.7199]])Backward
- Layer 에 있는 Parameter 들의 미분을 수행한다.
- Forward 의 결과값( model 의 output = 예측치 )과 실제 값 간의 차이 ( loss 값 ) 에 대해 미분을 수행한다.
- 미분 값으로 Parameter 를 업데이트
loss.backward()에서 loss 값을 각 weight 로 미분한 값을 계산한다.
- 실제 backward 는 Moule 단계에서 직접 지정이 가능하다.
- Module 에서 backward 와 optimizer 를 오버라이딩하여 직접 지정할 수 있다.
- 사용자가 직접 미분 수식을 써야하는 부담
- 쓸 일은 없지만 순서 이해는 필요
- AutoGrad 가 해주므로 직접 할 일은 잘 없다.
- Module 에서 backward 와 optimizer 를 오버라이딩하여 직접 지정할 수 있다.
Backward 기본 과정
for epoch in range( epochs ) :
# 이전 epoch 에서 업데이트된 gradient 값에 영향을 받지 않기 위해 초기화
optimizer.zero_grad()
# get output from the model, given the inputs
outputs = model(inputs)
# get loss for the predicted output
loss = criterion(outputs, labels)
print(loss)
# get gradients w.r.t to parameters
loss.backward()
# update parameters
optimizer.step()AutoGrad for Linear Regression
"""
data 선언
"""
import numpy as np
# training 을 위한 dummy data 생성
x_values = [i for i in range(11)]
x_train = np.array(x_values, dtype=np.float32)
x_train = x_train.reshape(-1,1)
y_values = [2*i + 1 for i in x_values]
x_train = np.array(y_values , dtype = np.float32)
y_train = y_train.reshape(-1,1)
"""
auto grad
"""
import torch
from torch.autograd import Variable
class LinearRegression(torch.nn.Modue(:
def __init__(self, inputSize, outputSize):
super(LinearRegression, self).__init__()
self.linear = torch.nn.Linear(inputSize, outputSize)
def forward(self,x):
out = self.linear(x)
return out
"""
Prepare for training
"""
inputDim = 1
outputDim = 1
learningRate = 0.01
epochs = 100
model = LinearRegression(inputDim, outputDim)
#### For GPU ####
if torch.cuda.is_available():
model.cuda()
"""
Define loss and optimizer
"""
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learningRate)
"""
Start training
"""
for epoch in range(epochs):
# Converting inputs and labels to Variable
# GPU 사용 가능하면 GPU 에 variable 을 올린다.
if torch.cuda.is_available():
inputs = Variable(torch.from_numpy(x_train).cuda())
labels = Variable(torch.from_numpy(y_train).cuda())
else:
inputs = Variable(torch.from_numpy(x_train))
labels = Variable(torch.form_numpy(y_train))
# gradient 초기화
optimizer.zero_grad()
# 주어진 input에 대한 output value 계산
outputs = model(inputs)
# loss 계산
loss = criterion(outputs, labels)
print(loss)
# parameters에 관한 gradients 획득
loss.backward()
# update parameters
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))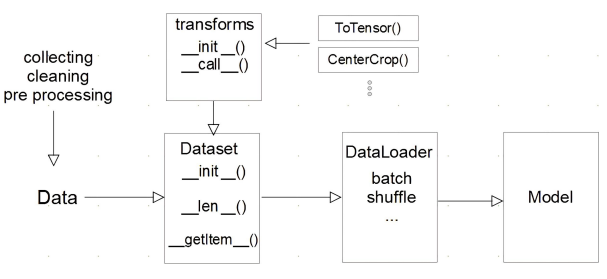
"""
예측 데이터 확인
"""
# 예측 모델에서는 gradient 를 사용하지 않아도 된다.
with torch.no_grad():
if torch.cuda.is_available():
predicted = model(Variable(torch.from_numpy(x_train).cuda())).cpu().data.numpy()
else:
predicted = model(Variable(torch.from_numpy(x_train))).data.numpy()
print(predicted)
"""
[[ 1.006162 ]
[ 3.0052748]
[ 5.0043874]
[ 7.0035 ]
[ 9.002612 ]
[11.001725 ]
[13.000837 ]
[14.999949 ]
[16.999063 ]
[18.998177 ]
[20.99729 ]]
"""예시 : Logistic Regression 에서의 계산 과정을 살펴보자.
class LR( nn.Module):
def __init__(self, dim, lr=torch.scalar_tensor(0.001)):
super(LR,self).__init__()
# parameters 초기화
self.w = torch.zeros(dim, 1, dtype= torch.float).to(device)
self.b = torch.scalar_tensor(0).to(device)
self.grads = {"dw":torch.zeros(dim, 1, dtype=torch.float).to(device),
"db":torch.scalar_tensor(0).to(device)}
self.lr = lr.to(device):
def forward(self, x):
## compute forward
z = torch.mm(self.w.T,x)
z = self.sigmoid(z)
return adef sigmoid(self,z):
return 1/(1 + torch.exp(-z))-
cost function 을 w 에 관해 미분한 결과 값
-
cost function 을 b 에 관해 미분한 결과 값
def backward(self, x, yhat, y):
## compute backward
self.grads["dw"] = ( 1/x.shape[1] ) * torch.mm( x, (yhat - y).T )
self.grads["db"] = ( 1/x.shape[1] ) * torch.sum( yhat-y ) # 기존 theta ( w ) 값에
# 미분 값 * learning rate 만큼을 업데이트 해줌
def optimizer(self):
## optimization step
self.W = self.W - self.lr * self.grads["dw"]
self.b = self.b - self.lr * self.grads["db"]참고TODO4강 실습 파일에 Logistic Regression 에 대한 구현이 있음 따라 쳐보기 []
5강 PyTorch datasets & dataloaders
GOAL
- PyTorch Dataset, Dataloader 를 사용하는 방법
- 데이터 입력 형태를 정의하는 Dataset 클래스를 이해하여 Image, Video, Text 등에 따른 Custom Data를 PyTorch 에 사용할 수 있도록 학습
- DataLoader 를 통해 네트워크에 Batch 단위로 데이터를 로등하는 방법에 대해 학습
# Further Question
1. DataLoader에서 사용할 수 있는 각 sampler들을 언제 사용하면 좋을지 논의해보기
2. 데이터의 크기가 너무 커서 메모리에 한번에 올릴 수가 없을 때 Dataset에서 어떻게 데이터를 불러오는게 좋을지 생각해보기
-
KEYWORDData Centric AI
- 어떻게 하면 대용량 데이터를 잘 넣어서 학습 시킬지
- PyTorch 에서는 대량의 데이터를 잘 다루기 위한
dataset API를 제공
Dataset API 가 무엇인지, 파일 형태 부터 모델 feeding 을 위한 데이터 셋까지 만들어보자 !
-
데이터 셋을 전처리하는 부분과 데이터 셋을 Tensor 형태로 변환해주는 부분을 구분해야 한다.
- Tensor로 변환하는 것은
Transformer에서 함
- Tensor로 변환하는 것은
-
DataLoader에서는 batch 단위로 데이터를 나누어 주거나 shuffle 해주는 등의 역할을 한다.
Dataset 클래스
- 데이터 입력 형태를 정의하는 클래스
- 데이터를 입력하는 방식의 표준화
- Image, Text, Audio 등에 따른 다른 입력 정의
basic custom dataset
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
# 초기 데이터를 어떻게 불러올지 지정
# 예를 들어 이미지의 경우, 데이터가 있는 폴더 경로 등을 지정해줌
def __init__(self, text, labels):
self.labels = labels
self.data = text
# 데이터의 전체 길이
def __len__(self):
return len(self.labels)
# index 값을 주었을 때 반환되는 데이터의 형태 (X,y)
# 꼭 dict type 으로 반환해줄 필요는 없다.
# 일반적으로 classification 문제에서는 dict type 으로 많이 반환함
# 만약 detection 문제라면 방식이 달라질 수 있음
def __getitem__(self,idx):
label = self.labels[idx]
text = self.data[idx]
sample = {"Text": text, "Class": label}
return sampleDataset 클래스 생성시 유의할 점
- 데이터 형태에 따라 각 함수를 다르게 정의한다.
- 데이터마다 가진 특징이 다르기 때문이다.
- ★ 모든 것을 데이터 생성 시점에 처리할 필요는 없다.
- 예를 들어, image 데이터에서 Tensor 변환은 학습에 필요한 시점에 하면 된다.
- 데이터 셋에 대한 표준화된 처리 방법 제공 필요
- 후속 연구자 또는 동료에게 큰 도움
- 최근에는 HuggingFace 등 표준화된 라이브러리를 사용한다.
DataLoader 클래스
- sampler
- dataset 에서 sample 을 추출하는 전략을 정의
__len__이 구현된 어떤Iterable이든 가능- sampler 가 전달되면
shuffle은 특정될 수 없음SequentialSampler: element 들을 연속적으로 sampling, 항상 동일한 순서를 가진다.RandomSampler: element 들을 random 으로 sampling, repacement=False 이면 shuffled dataset 에서 샘플링된다. True 이면,num_samples를 지정할 수 있다.SubsetRandomSampler: 주어진 list of indices 에서 랜덤으로 샘플링된다.WeightedRandomSampler: 주어진 가능성( weights ) 를 고려해 샘플링된다.BatchSampler: mini-batch of dindices 를 yield 하는 다른 sampler 를 감싼다.
DistributedSampler: 데이터 로드를 데이터 셋의 하위 집합으로 제한
- batch_sampler
- sampler 와 같은 역할
- 한 번에 batch of indices 를 반환하는 것에서 차이가 있음
- batch_size, shuffle, sampler 그리고 drop_last 와 상호 배타적인 관계 ( 일괄 처리됨 )
- collate_fn
- 언제 사용하는지 알아두면 유용 !
- variable parameter 를 다룰 때 사용된다.
- sequence data 에서 padding 이 필요할 때
- [data label] 형태로 주어진 데이터를 [data][label] 로 분리할 때
merges a list of samples to form a mini-batch of Tensor(s). Used when using batched loading from a map-style dataset.
torch.utils.data.DataLoader
( dataset, batch_size=1, shuffle=None,
sampler=None, batch_sampler=None,
num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False,
timeout=0, worker_init_fn=None,
multiprocessing_context=None,
generator=None, *, prefetch_factor=2,
persistent_workers=False,
pin_memory_device='')- Data 의 Batch를 생성해주는 클래스
- Dataset 은 하나의 데이터를 어떻게 가져올 것인가
- DataLoader 는 index 를 이용하여 여러 개의 데이터를 한 번에 묶어서 모델에 던져주는 역할
- 학습 직전 데이터의 변환을 책임진다.
- CPU에서 데이터 전처리 및 Tensor 변환을 해서 GPU로 넘겨 학습을 한다. ( 병렬 처리 )
- GPU 로 전달하기 전에 Tensor로 변환되는데 이 부분을 책임진다.
- Tensor로 변환하고 Batch 를 처리하는 것이 메인 업무
- 병렬적인 데이터 전처리 코드의 고민이 필요하다.
- framework 내에 잘 되어있어서 큰 고민은 안해도 된다.
basic dataloader 클래스
- Dataloader 는 기본적으로 iterator 형태이다.
next(iter(MyDataLoader))- 호출하는 시점에 데이터가 메모리에 올라간다.
# dataset 생성
# text 와 labels 는 1 대 1 대응 관계이다.
text = ['Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
MyDataset = CustomDataset(text, labels)
next(iter(MyDataLoader))
"""
# batch size 개수만큼 묶어서 보여준다.
{'Text': ['Glum', 'Amazing'], 'Class': ['Negative', 'Positive']}
"""
MyDataLoader = DataLoader( MyDataset, batch_size = 2, shuffle = True )
for dataset in MyDataLoader:
print(dataset)
Casestudy
- 데이터 다운로드부터 loader까지 직접 구현해보기
- NotMNIST 데이터의 다운로드 자동화 도전
참고TODOPyTorch template 에서 dataloader 가 어떻게 사용되었는지 살펴보기참고TODOclone coding 하면서 이해해보기- 참고 예제 : dataloader tutorial
- 참고 예제 : 5강 실습 파일
이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
