Week2 기본-2 과제 학습내용 정리
피드백
20220929 과제 해설을 본 뒤 피드백 내용을 추가함
- dataset 에는 feature 들의 labels 을 가지고 있는 것이 좋다.
self.features = self.X.columns.tolist() # column 명을 저장해둠 self.classes = ['Dead','Survived']- pandas dataframe 처리
# 사용하지 않을 데이터 drop self.data.drop(drop_features, axis = 1 ) def __getitem__(self,idx): # dataframe 에서 idx 로 데이터 접근 X = self.X.iloc[idx].values y = self.y.iloc[idx]
progress_applyself.X = (self.data['title'] + " " + self.data['description']).progress_apply(lambda s: self._preprocess(s))질문
- 각 dataset 에서 classes 는 어떻게 정하는건가..?
- 사전에 주어진 정보를 이용
- loc 와 iloc 차이
아래 코드에는 오류가 있을 수 있으며, 오류 발생 가능한 부분 중 일부를 '피드백' 에 정리했습니다.
PyTorch의 Dataset
- 딥러닝 모델 학습을 위한 데이터 준비하기
- 파이토치는 멀티 스레딩을 통한 데이터 병렬화
- 데이터 증식 및 배치 처리 등의 기능을 제공
Dataset 관련 모듈
-
torch.utils.data
torch.utils.data.DataLoaderclass 를 통해 data loading 이 관리된다.- 데이터를 loading 하기 위한 배치 사이즈, shuffle 여부를 지정하거나, data augmentation 을 할 수 있다.
-
torchvision.dataset
torch.utils.data.Dataset을 상속하는 이미지 데이터셋의 모음- MNIST나 CIFAR-100과 같은 데이터셋을 제공
-
torchtext.dataset
torch.utils.data.Dataset을 상속하는 텍스트 데이터셋의 모음- IMDb나 AG_NEWS와 같은 데이터셋을 제공
-
torchvision.transforms
이미지 데이터셋에 쓸 수 있는 여러 가지 변환 필터를 담고 있는 모듈예를 들어Tensor로 변환, Resize와 Crop으로 이미지를 수정 또는 밝기(Brightness) 등의 값 조절이 가능함.
-
torchvision.utils
visualization 을 위한 도구를 포함- 이미지 저장, grid 추가 또는 bounding box 추가 등
DataSet 의 기본 구성 요소
DataLoader 생성자에서 가장 중요한 argument 는 dataset
map-stype dataset
__init__,__len__,__getitem__메서드로 구성됨
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self,):
pass
def __len__(self):
pass
def __getitem__(self, idx):
passinit: 데이터의 위치나 파일 명 등의 초기화 작업을 위한 메서드- 일반적으로 csv 파일이나 xml 파일 같은 데이터를 여기서 불러옴
- 모든 데이터를 메모리에 로드하지 않고 효율적으로 사용할 수 있음
- 이미지를 처리하기 위한 transforms 들을 정의해두기
- 일반적으로 csv 파일이나 xml 파일 같은 데이터를 여기서 불러옴
len: Dataset 에 있는 데이터의 개수를 반환- 접근하려는 인덱스가 적절한 범위 안에 있는지 확인할 수 있다.
getitem: Dataset 의 idx 번째 데이터를 반환하는 데 사용됨- 원본 데이터를 가져와 전처리하고 데이터를 증강시키는 부분이 여기서 진행될 것임
- transform 부분에서 더 자세히 보자 !
- 그 밖에 labels, target class 등과 같은 다른 정보를 가져오는 다른 메서드를 추가 정의 할 수 있다.
Dataset 실습 : scikit-learn의 붓꽃 데이터
class IrisDataset(Dataset):
def __init__(self):
iris = load_iris()
self.data = iris['data']
self.labels = iris['target']
self.feature_names = iris['feature_names']
def __len__(self):
len_dataset = len( self.labels )
return len_dataset
def __getitem__(self, idx):
data = self.data[idx]
label = self.labels[idx]
return data, label시각화
plt.figure(figsize = (12,8))
colors = ['r','g','b']
for n, c in enumerate(dataset_iris.labels ) :
plt.scatter(dataset_iris.data[n,0], dataset_iris_data[n,1], color=colors[c])
plt.title('Relationship between {} and {}'.format(dataset_iris.feature_names[0], dataset_iris.feature_names[1]))
plt.grid(True)
plt.show()데이터 출력
- iterator 로 반환
next(iter(DataLoader(dataset_iris))PyTorch의 dataLoader
모델 학습을 위해 데이터를 mini batch 단위로 제공해주거나 data augmentation 역할을 해줌
dataset: 앞에서 작성한 dataset 을 인자로 전달batch_size나collate_fn을 많이 사용함
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)DataLoader 의 기본 구성 요소
dataset: Dataset 인스턴스 전달batch_size: 1 epoch 에 전달되는 데이터의 양
next(iter(DataLoader(dataset_iris, batch_size=4)))
"""
[tensor([[5.1000, 3.5000, 1.4000, 0.2000],
[4.9000, 3.0000, 1.4000, 0.2000],
[4.7000, 3.2000, 1.3000, 0.2000],
[4.6000, 3.1000, 1.5000, 0.2000]]), tensor([0, 0, 0, 0])]
"""shuffle: 데이터를 섞어준다.
next(iter(DataLoader(dataset_iris, shuffle=True, batch_size=4)))
"""
[tensor([[5.2000, 2.7000, 3.9000, 1.4000],
[4.8000, 3.0000, 1.4000, 0.3000],
[5.7000, 2.8000, 4.5000, 1.3000],
[5.1000, 2.5000, 3.0000, 1.1000]]), tensor([1, 0, 1, 1])]
"""sampler,batch_samler- index 를 원하는 방식대로 조정한다.
- index 를 컨트롤하기 때문에 shuffle parameter 와는 함께 사용할 수 없다.
__len__과__iter__를 구현 또는 구현된 Sampler 를 사용할 수 있다.참고Sampler 구현 참고글- SequentialSampler
- RandomSampler
- SubsetRandomSampler
- WeightRandomSmapler
- BatchSampler
- DistributedSampler
- index 를 원하는 방식대로 조정한다.
불균형 데이터셋의 경우, 클래스의 비율에 맞게끔 데이터를 제공해야 하기 때문에 sampler 를 이용한다.
-
num_workers: 데이터를 불러올 때 사용하는 subprocess 의 개수- 얼마나 많은 CPU 코어들이 데이터 로딩 작업을 하는 데에 사용될 것인지 결정하는 인자
- 모든 코어가 데이터 로딩 일만 하면 다른 쪽 성능이 떨어질 수 밖에 .. ( tradeoff )
-
collate_fn: 일반적으로map-styledataset 에서 smaple list 를 batch 단위로 바꾸거나,zero-padding이나Variable Size 데이터등 데이터 사이즈를 맞추기 위해 많이 사용한다.
collate_fn 예시
def collate_fn(batch):
print('Original:\n', batch)
print('-'*100)
data_list, label_list = [], []
for_data, _label in batch:
data_list.append(_data)
label_list.append(_label)
print('Collated:\n', [torch.Tensr(data_list), torch.LongTensor(label_list)])
print('-'*100(
return torch.Tensor(data_list),torch.LongTensor(label_list)
next(iter(DataLoader(dataset_random, collate_fn=collate_fn, batch_size=4)))
"""
Original:
[(tensor([0.7557]), tensor(1)), (tensor([0.7593]), tensor(0)), (tensor([0.3026]), tensor(0)), (tensor([0.7270]), tensor(0))]
----------------------------------------------------------------------------------------------------
Collated:
[tensor([0.7557, 0.7593, 0.3026, 0.7270]), tensor([1, 0, 0, 0])]
----------------------------------------------------------------------------------------------------
(tensor([0.7557, 0.7593, 0.3026, 0.7270]), tensor([1, 0, 0, 0]))
"""collate_fn 실습
더 공부해야 할 것들
- list 의 deep copy 개념
- torch 의 stack
- torch 의 pad_sequence
- torch 의 contiguous
구현한 방법
- sample 데이터에서 data 와 label 을 구분하여 수집
- 수집된 data 중 가장 긴 것의 길이 ( max_len ) 를 저장해둠
- 다시 data 를 돌면서 max_len 보다 짧은 데이터에 zero padding 추가
def custom_collate_fn( samples ):
collate_data = []
collate_labels = []
# batch 에 포함된 data 중에서 가장 긴 것의 길이를 찾는다.
max_len = 0
temp_collate_X = []
# samples 를 돌면서 data 와 label 을 분리하여 수집한다.
for sample in smaples:
temp_collate_data.append( sample['data'])
collate_labels.append( sample['y'])
cur_len = len(sample['data'])
max_len = cur_len if cur_len > max_len else max_len
for d in temp_collate_data :
cur_data_len = len(d)
spare_len = max_len - cur_data_len
collate_data.append( torch.cat([x, torch.zeros(spare_len)]))
return { 'data' : torch.stack(collate_data),
'labels' : torch.stack(collate_y)}
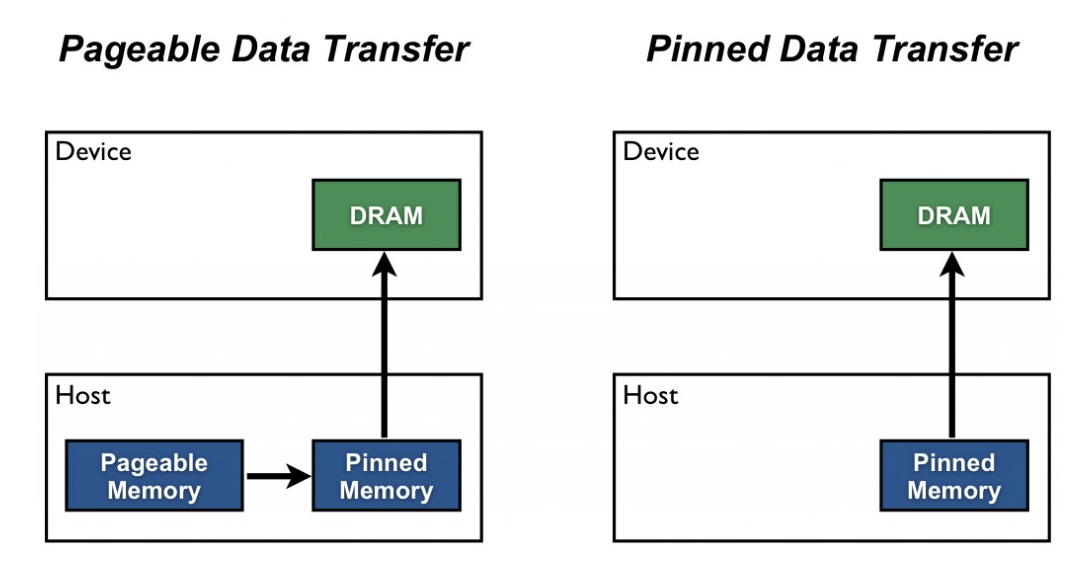
pin_memory
:True이면 Tensor 를 CUDA 고정 메모리에 할당- pinned 메모리에 있는 데이터의 경우 GPU로 비동기 데이터 전송
- 데이터의 고정된 메모리에서 데이터를 가지고 오기 때문에 데이터 전송이 훨씬 빠르다.
- 너무 많은 메모리를 점유하게 될 경우, 다른 데이터가 메모리에 못 올라오는 문제가 생길 수 있다.
- pageable Memory 와 Non-Pageable Memory 알아보기
drop_last
: batch 단위로 데이터를 불러올 때 마지막 batch 의 길이가 달라질 수 있음- batch 의 크기에 의존도가 높은 함수를 사용하거나, batch의 길이가 다른 경우 loss를 구하는 것이 어려운 경우 마지막 batch 를 사용하지 않을 수 있다.
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))
[[0, 1, 2], [3, 4, 5], [6, 7, 8]]timeout: 양수일 때 , DataLoader 가 data 를 불러오는 데 걸리는 시간을 제한한다.- (?) 시간의 단위는 뭘까? 초..겠지 ? 검색해도 잘 안나온다.
worker_init_fn: 어떤 worker 를 사용할지를 list 로 전달
torchvision 에서 제공하는 transform 함수
Image data 를 일괄 resize 하거나 crop, zoom 등의 이미지 변환을 도와준다.
참고 torchvision 을 사용할 때, 이미지는 항상 PIL 객체여야 한다.
- transforms.Resize
- transforms.RandomCrop
- transforms.RandomRotation
조건에 맞게 데이터를 변환해보자.
참고 transforms 공식문서
참고 dir(transform) 으로 transforms 에 속하는 것들을 조회할 수 있다.
참고 albumentations 같은 다른 Python library 도 많음
- 이미지 사이즈 (224,224)
- 상하 반전
- 이미지 중심에서 가로, 세로 90 만큼 자르기
def get_transforms_img(im):
im = transforms.Resize((224,224))(im)
im = transforms.RandomVerticalFlip()(im)
im = transforms.CenterCrop(90)(im)함께 묶어 처리해줄 수 있다.
transforms.Compose([transforms.Resize((224,224)), transforms.RandomVerticalFlip(), transforms.CenterCrop(90)])(im)
Image to Tensor / Array to Image
- Image to Tensor
transforms.ToTensor()(im)- Tensor to Image
im_arr = torch.rand((3, 224, 224))
# cv.imread나 plt.imread 와 같은 함수와 함께 사용된다.
im_pil = transforms.ToPILImage()(im_arr)
im_pilimgaug 소개
transformation 에 의해 input 값이 변하면서 GT( Ground Truth, 데이터의 라벨 값) 가 변하는 경우가 있다.
예를 들어object detection 에서 bounding box- 원돈 이미지를 뒤집거나 회전시키면 바운딩 박스의 좌표도 변환되어야 한다.
이 때, imgaug 를 사용해 label 값 변화를 함께 처리해줄 수 있다.

torchvision 에서 제공하는 여러가지 dataset
참고 torchvision built-in dataset 구경하기
데이터 다운로드 경로, transfrom, 다운로드 여부를 인자로 넘길 수 있다.
CIFAR100 예제
dataset_train_CIFAR100 = torchvision.datasets.CIFAR100('data/CIFAR100/', # 다운로드 경로 지정
train=True, # True를 지정하면 훈련 데이터로 다운로드
transform=transforms.Compose([transforms.RandomHorizontalFlip(0.5),
transforms.ToTensor(),
transforms.Normalize(std=0.5,mean=0.5)]), # 텐서로 변환
download=True
)torchtext 의 데이터 셋
참고 torchtext dataset 구경하기
참고 Huggingface 를 이용하면 훨씬 더 편하게 Dataset 과 DataLoader를 사용할 수 있다.
torchtext 의 간단한 동작
- sentence tokenizer
tokenizer = torchtext.data.utils.get_tokenizer('basic_english')
tokenizer('Hello World!')- vocabulary counter
counter = collections.Counter()
for (label, line) in dataset_train_AG_NEWS:
counter.update(tokenizer(line))
vocab = torchtext.vocab.vocab(counter, min_freq=1)- text encode / decoder
def encode(x):
return [vocab.get_stoi()[s] for n, s in enumerate(tokenizer(x))]
def decode(x):
return [vocab.get_itos()[i] for n, i in enumerate(x)]
encode('I love my pictures and cat')
# [599, 3279, 225, 3195, 41, 2151]
decode(encode('I love my pictures and cat'))
# ['i', 'love', 'my', 'pictures', 'and', 'cat']- CounterVectorizer
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
corpus = [
'I like hot dogs.',
'The dog ran fast.',
'Its hot outside.',
]
vectorizer.fit_transform(corpus)
vectorizer.transform(['My dog likes hot dogs on a hot day.']).toarray()
# array([[1, 1, 0, 2, 0, 0, 0, 0, 0]])
- AG_NEWS 데이터 셋을 위한 vocab counter 준비
vocab_size = len(vocab)
def to_bow(text,bow_vocab_size=vocab_size):
res = torch.zeros(bow_vocab_size,dtype=torch.float32)
for i in encode(text):
if i<bow_vocab_size:
res[i] += 1
return res
print(to_bow(dataset_train_AG_NEWS[0][1]))- AG_NEWS 데이터 셋을 위한 collate_fn 정의
# batch_size tuples 의 list 를 얻는 collate function
# 전체 minibatch 에 대해 label-feature tensors 의 쌍을 반환
def bowify(b):
return (
torch.stack([to_bow(t[1]) for t in b]),
torch.LongTensor([t[0]-1 for t in b]),
)- AG_NEWS 데이터 로드
dataloader_train_AG_NEWS = DataLoader(dataset_train_AG_NEWS, batch_size=4, collate_fn=bowify, shuffle=True)
dataloader_test_AG_NEWS = DataLoader(dataset_test_AG_NEWS, batch_size=4, collate_fn=bowify, shuffle=True)Titanic dataset 으로 실습
dataset : 캐글 타이타닉 데이터 셋
구현 방법
- pandas dataframe type 으로 불러온 데이터 처리
- drop_features 를 제외한 feature를 self.features 에 저장
- (?) tensor 로 변환해서 저장해야하나?
- train data 여부를 저장해둠
class TitanicDataset(Dataset):
def __init__(self, path, drop_features, train=True):
self.data = pd.read_csv(path)
self.data['Sex'] = self.data['Sex'].map({'male':0, 'female':1})
self.data['Embarked'] = self.data['Embarked'].map({'S':0,'C':1,'Q':2})
self.items =[]
self.labels = []
# classification 대상이 되는 label
label_name = 'Survived'
valid_keys = [key for key in self.data.keys() if key not in drop_features and key != label_name]
# tensor 로 저장해야 한다면
# self.features = torch.tensor( self.data[valid_keys].values )
# self.classes = torch.tensor( self.data[label_name].values )
self.items = self.data[valid_keys].values
self.labels = self.data[label_name].values
self.is_train = train
def __len__(self):
len_dataset = len(self.labels)
return len_dataset
def __getitem__(self, idx):
X, y = self.items[idx], None
if( True == self.is_train ):
y = self.labels[idx]
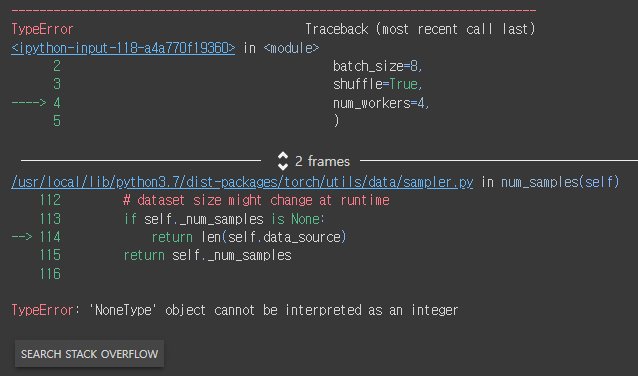
return torch.tensor(X), torch.tensor(y)len method 가 구현안됐을 때 발생하는 오류
'NoneType' object cannot be interpreted as an integer
MNIST dataset 으로 실습
data 경로 설정
BASE_MNIST_PATH = 'data/MNIST/MNIST/raw'
TRAIN_MNIST_IMAGE_PATH = os.path.join(BASE_MNIST_PATH, 'train-images-idx3-ubyte.gz')
TRAIN_MNIST_LABEL_PATH = os.path.join(BASE_MNIST_PATH, 'train-labels-idx1-ubyte.gz')
TEST_MNIST_IMAGE_PATH = os.path.join(BASE_MNIST_PATH, 't10k-images-idx3-ubyte.gz')
TEST_MNIST_LABEL_PATH = os.path.join(BASE_MNIST_PATH, 't10k-labels-idx1-ubyte.gz')
TRAIN_MNIST_PATH = {
'image': TRAIN_MNIST_IMAGE_PATH,
'label': TRAIN_MNIST_LABEL_PATH
}MNIST RAW 데이터 불러오는 함수
stackoverflow extract-images-from-idx3-ubyte-file-or-gzip-via-python
- 16byte 의 header 를 통해 정보를 얻는다. ( 각각 4byte 로 이루어져 있다. )
- magic_number
- 파일 첫 부분에 들어가는 고유한 값으로 파일의 형식을 식별할 수 있게 해줌( 위키-Magic number(programming)
- nums
- rows
- cols
- magic_number
이미지 데이터 로딩
def read_MNIST_images(path):
with gzip.open(path, 'r') as f:
# 첫 4byte : masic number
masic_number = int.from_bytes(f.read(4), 'big')
# 두 번째 4byte : image의 수
image_count = int.from_bytes(f.read(4), 'big')
# 세 번째 4byte : row count
row_count = int.from_bytes(f.read(4), 'big')
# 네 번째 4byte : column count
column_count = int.from_bytes(f.read(4), 'big')
# 나머지는 image pixel data 로 , 각 픽셀은 unsigned byte 로 저장되어 있다.
# pixel value 는 0 부터 255
image_data = f.read()
images = np.frombuffer(image_data, dtype=np.unint8).reshape((image_count, row_count, column_count))
return iamges라벨 데이터 로딩
def read_MNIST_labels(path):
with gzip.open(path,'r') as f:
# 첫 4byte : masic number
masic_number = int.from_bytes(f.read(4), 'big')
# 두 번째 4byte : label의 수
label_count = int.from_bytes(f.read(4), 'big')
# 나머지는 label data
label_data = f.read()
labels = np.frombuffer(label_data, dtype=np.uint8)
return labelsMNIST DataSet 작성
참고 pytorch torchvision/datasets/vision.py
class MyMNISTDataset(Dataset):
def __init__(self, path, transform, train=True):
self._repr_indent = 4
self.path = path
self.data = read_MNIST_images(path['image'])
self.labels = read_MNIST_labels(path['label'])
self.cur_transform = transform
self.is_train = train
def __len__(self):
len_dataset = len(self.classes)
return len_dataset
def __getitem__(self,idx):
X,y = self.data[idx], None
if( True == self.is_train):
y = self.classes[idx]
return torch.tensor(X, dtype=torch.double), torch.tensor(y, dtype=torch.long)
def __repr__(self):
head = "(PyTorch Practice) My Custom Dataset : MNIST"
data_path = self._repr_indent*" " + "Data path: {}".format(self.path['image'])
label_path = self._repr_indet*" " + "Label path: {}".format(self.path['label'])
num_data = self._repr_indent*" " + "Number of datapoints: {}".format(self.__len__())
num_classes = self._repr_indent*" " + "Number of classes: {}".format(len(self.labels))
return '\n'.join([head,
data_path, label_path,
num_data, num_labels])
Dadaset 생성
dataset_train_MyMNIST = MyMNISTDataset(path=TRAIN_MNIST_PATH,
transform=transforms.Compose([
transforms.ToTensor()
]),
train=True,
)image data 조회하기
image, label = next(iter(dataset_train_MyMNIST))
image, label
plt.imshow(image.numpy().squeeze(),cmap='gray')
plt.title("{}".format(dataset_train_MyMNIST.labels[label]))
plt.axis('off')
plt.show()torchvision 의 datasets.ImageFolder 를 이용하면 쉽게 Dataset 을 생성할 수 있다.
- 폴더 구조
- class 별로 분리하여 저장
data/train/ants/xxx.png data/train/ants/xxz.jpeg . . . data/train/bees/123.jpg data/train/bees/asdf3.png
- 데이터 로딩
dataset_train = datasets.ImageFolder(root='data/train', transform=transform_train)
AG_NEWS 로 연습
파일 경로 설정
BASE_AG_NEWS_PATH = 'data/datasets/AG_NEWS'
TRAIN_AG_NEWS_PATH = os.path.join(BASE_AG_NEWS_PATH, 'train.csv')
TEST_AG_NEWS_PATH = os.path.join(BASE_AG_NEWS_PATH, 'test.csv')class My_NEWSDataset(Dataset):
def __init__(self, path='./data/AG_NEWS/traincsv',train=True):
tqdm.pandas()
self._repr_index = 4
self.data = pd.read_csv(path, sep=',', header=None, names=['class','title','description'])
self.path = path
self.items = self.data['title'] + ' ' + self.data['description']
self.items = self.items.astype(str).apply(self._preprocess)
self.classes = self.data['class']
self.encoder = None
self.decoder = None
self.is_train = train
for item in self.items:
item = self._preprocess(item)
counter.update(tokenizer(item))
self.vocab = torchtext.vocab.vocab(coutner, min_freq=1)
self.encoder = self.vocab.get_stoi()
self.decoder = self.vocab.get_itos()
def __len__(self):
len_dataset = len(self.classes)
return len_dataset
def __getitem__(self, idx):
X,y = self.items[idx], None
if( True == self.is_train):
y = self.classes[idx]
return y,X
def __repr__(self):
'''
https://github.com/pytorch/vision/blob/master/torchvision/datasets/vision.py
'''
head = "(PyTorch Practice) My Custom Dataset : AG_NEWS"
data_path = self._repr_indent*" " + "Data path: {}".format(self.path)
num_data = self._repr_indent*" " + "Number of datapoints: {}".format(self.__len__())
num_classes = self._repr_indent*" " + "Number of classes: {}".format(len(self.classes))
return '\n'.join([head, data_path, num_data, num_classes])
def _preprocess(self, s):
# 영어, 숫자 외 모두 제거
# 소문자로 변환
s = re.sub('[^a-zA-Z0-9 ]', '', s).lower()
return s
dataset 선언
dataset_train_MyAG_NEWS = MyAG_NEWSDataset(TRAIN_AG_NEWS_PATH, train=True)collate_fn
vocab_size = len(dataset_train_MyAG_NEWS.vocab)
def custom_to_bow(text,bow_vocab_size=vocab_size):
res = torch.zeros(bow_vocab_size,dtype=torch.float32)
for n, i in enumerate(text.split(' ')):
idx = dataset_train_MyAG_NEWS.encoder[i]
if idx<bow_vocab_size:
res[idx] += 1
return res
print(custom_to_bow(dataset_train_MyAG_NEWS[0][1]))
def custom_bowify(b):
return (
torch.stack([custom_to_bow(t[1]) for t in b]),
torch.LongTensor([t[0]-1 for t in b]),
)dataloader
dataloader_train_AGNEWS = DataLoader(dataset_train_MyAG_NEWS,
batch_size=4,
collate_fn=custom_bowify,
shuffle=True)이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.

너무 도움이 됩니다 ^^!