6강 모델 불러오기
GOAL
- PyTorch 모델 저장 및 불러오는 방법
- Transfer Learning ( 전이 학습, 이어 학습하기 )
- state_dict 의 의미
- 모델의 파라미터를 여러 정보들과 함께 저장하고 불러오는 법
- 학습된 모델을 활용하는 법
- pytorch built-in model or huggingface
- github rwightman/pytorch-image-models
- github qubvel/segmentation_models.pytorch
- Loss 와 Metric 에 따라 모델 저장하는 방법
- 이어 학습하는 법
- 학습된 모델을 활용하는 법이미 학습되어 있는 모델 (backbone) 을 가지고 와 내가 가진 데이터로 fine tuning 하는 방식을 많이 사용한다.
- 어떻게 모델을 저장할 수 있을까 ?
- 어떻게 모델을 불러올 수 있을까 ?
- Fine tuning 을 하는 방법
model.save()
- 학습의 결과를 저장하기 위한 함수
- 모델의 형태( architecure ) 와 parameters 를 저장할 수 있다.
- parameters 저장 : torch.save(model.state_dict(),PATH)
- model의 architecture와 함께 저장 : torch.save(model, PATH)
- 모델 학습 중간 과정을 저장해서 최선의 결과 모델을 선택할 수 있다.
Early stopping
- 만들어진 모델을 공유하여 재연성을 향상 시킬 수 있다.
state_dict: 모델의 parameters 를 표시load_state_dict: 같은 모델의 형태에서 parameters 만 로드할 수 있다.load: 모델의 architecture 를 함께 load 할 수 있다.
참고 모델의 parameters 는 Ordered Dict 로 저장된다.
참고 PyTorch 모델 저장할 때는 PyTorch 의 모델임을 드러낼 수 있는 .pt 를 많이 쓴다. .pth 나 .ptc 같은 다른 확장자도 있다.
# Print model's state_dict
print('Model's state_dict:')
# state_dict : 모델의 파라미터를 표시한다.
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# 모델의 파라미터 저장
torch.save(model.state_dict(), os.path.join(MODEL_PATH, model.pt"))
# 같은 모델의 형태에서 parameters 만 load
new_model = TheModelClass()
new_model.load_state_dict(torch.load(os.path.join( MODEL_PATH, "model.pt")))
# 모델의 architecture와 함께 저장
torch.save(model, os.path.join(MODEL_PATH, "model.pt"))
# 모델의 architecture와 함께 load
model = torch.load(os.path.join(MODEL_PATH, model.pt"))6강 실습 - Saving Model And Loading
참고 torchsummary : model 과 input size ( ex. (3,224,224) ) 를 넘겨주면 model summary 를 볼 수 있다.
Saving and Loading Model
pytorch tutorial - saving_loading_models.html
import library
import torch
import torch.nn as nn
import torch.optim as optim
import osModel Class 작성
class TheModelClass(nn.Module):
def __init__(self:
super(TheModelClass, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d( 3, 16, kernel_size=3, stride=2, padding=0 ),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernal_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d( 3, 32, kernel_size=3, strice=2, padding=0),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer3 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.drop_out = nn.Dropout()
self.fc1 = nn.Linear(3*3*64, 1000)
self.fc2 = nn.Linear(1000,1)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0), -1)
out = self.drop_out(out)
out = self.fc1(out)
out = self.fc2(out)
return out모델 및 optimizer 초기화
# 모델 초기화
model = TheModelClass().cuda()
# optimizer 초기화
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9)model 의 parameter 출력하기
state_dict 를 이용하는 방법
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())torchsummary 를 이용하는 방법
from torchsummary import summary
summary(model, (3,224,224))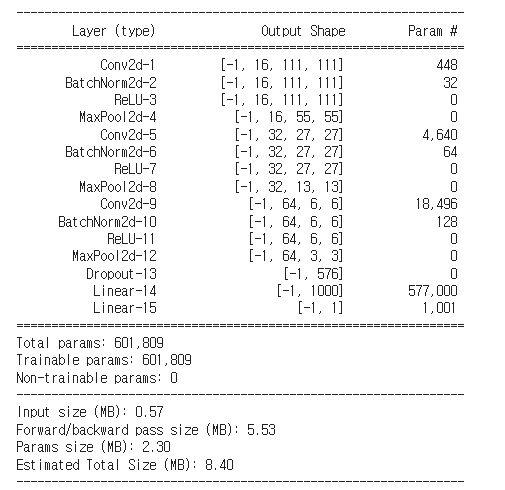
model의 parameters 저장하기
MODEL_PATH = "saved"
if not os.path.exists(MODEL_PATH):
os.makedirs(MODEL_PATH)
torch.save(model.state_dict(),
os.path.join(MODEL_PATH, "model.pt"))model의 parameters 불러오기
반드시 같은 architecture 를 가져야 한다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
new model = TheModelClass()
new_model.load_state_dict(torch.load(os.path.join(MODEL_PATH,"model.pt")))pickle 형태로 모델 전체를 저장할 수 도 있다.
torch.save(model, os.path.join(MODEL_PATH, "model_pickle.pt"))
model = torch.load(os.path.join(MODEL_PATH, "model_pickle.pt"))
model.eval()
checkpoints
testing loss 가 어느 순간 커질 수 있다.
early stopping기법을 이용하여 최선의 선택을 한다.
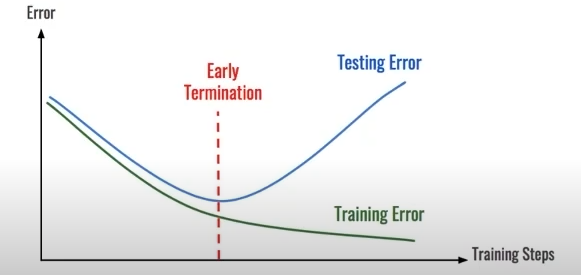
- 학습의 중간 결과를 저장해서 최선의 결과를 선택한다.
early stopping기법을 사용해 이전 학습의 결과물을 저장- loss 와 metric 값을 지속적으로 확인하고 저장
- 일반적으로 epoch, loss, metric 을 함께 저장해 확인한다.
- colab에서 작업시 런타임 연결이 끊기는 경우가 있기 때문에 지속적인 학습을 위해 필요
epoch, loss, metric 을 알아볼 수 있게 파일명에 포함한다.
torch.save({
'epoch': e,
'model_state_dict': model.state_dict(),
'optimizer_state_dict' : optimizer.state_dict(),
'loss': epoch_loss',
},f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt")
모델을 학습시켜보자.
- 폴더 명 변경
- 폴더 내의 데이터를 열어보면서 유효하지 않은 것들은 삭제 처리
데이터 파일 준비
import zipfile
import shutil
filename = "kagglecatsanddogs_5340.zip"
with zipfile.ZipFile(filename, 'r') as zip_ref:
zip_ref.extractall()
import shutil
shutil.move('PetImages', 'data')
import os
from os impor walk
mypath = "data"
f_path = []
for (dirpath, dirnames, filenames) in walk(mypath):
f_path.extend([os.path.join(dirpath, filename) for filename in filenames])
from PIL import image
# 유효하지 않은 파일들은 삭제 처리
for f_name in f_path:
try:
image.open(f_name)
except Exception as e:
print(e)
os.remove(f_name)dataset 준비
참고
torchvision.transforms.Normalize(mean, std, inplace=False)(mean[1], ...,mean[n]) , (std[1],...,std[n])으로 주어졌을 때, 각각은 아래와 같이 계산됨
output[channel] = (input[channel] - mean[channel]) / std[channel] )
from torchvision import datasets
import torchvision.transforms as transforms
import torch
dataset = datasets.ImageFolder(root="data,
transform=transforms.Compose([
transforms.Resize(244),
transforms.CenterCrop(244),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),
(0.5, 0.5, 0.5((,
]))
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=8,
shuffle=True,
num_workers=8)warning ignore option
import warnings
warnings.filterwarnings("ignore")binary acc 구하는 함수 정의
def binary_acc(y_pred, y_test):
y_pred_tag = torch.round(torch.sigmoid(y_pred))
correct_results_sum = ( y_pred_tag == y_test).sum().float()
acc = correct_results_sum/y_test.shape[0]
acc = torch.round(acc * 100)
return accparameters 정의
EPOCHS = 100
BATCH_SIZE = 64
LEARNING_RATE = 0.1모델 학습을 위한 criterion ( loss ) , optimizer 선언
BCEWithLogisticLoss: Binary Cross Entropy With Logistic Regression- 마지막 layer 에 sigmoid 함수를 씌워준다.
- 맨 마지막에 loss만 바꿔서 사용할 수 있도록 도와준다. ( 무슨 말인지 잘 이해못함. 강의 18분 )
model.to(device)
criterion = nn.BCEWithLogisticLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)모델 학습
- acc 와 loss 값을 이용하여 early stopping기법을 사용할 수 있다.
- 5회째 loss 가 같으면 stop
- acc 가 떨어지는 순간 stop
- ..
for e in range( 1, EPOCHS + 1 ):
epoch_loss = 0
epoch_acc =0
# data 를 GPU 로 전달해줌
for X_batch, y_batch in dataloader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor)
# optimizer 의 gradient를 zero 로 초기화 해주어야 한다.
optimizer.zero_grad()
y_pred = model(X_batch)
loss = criterion(y_pred, y_batch.unsqueeze(1))
acc = binary_acc(y_pred, y_batch.unsqueeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
# Check point 를 저장한다.
torch.save({
'epoch': e,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': epoch_loss,
}, f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt")6강 실습 - Transfer Learning
Basic Code
# vgg16 모델을 할당한 변수 vgg
vgg = models.vgg16(pretrained=True).to(device)
class MyNewNet(nn.Module):
def __init__(self):
super(MyNewNet, self).__init__()
self.vgg19 = models.vgg19(pretrained=True)
# 모델에 마지막 linear layer 를 추가한다.
self.linear_layers = nn.Linear(1000,1)
# Defining the forward pass
def forward(self, x):
x = self.vgg19(x)
return self.linaer_layers(x)
# 마지막 layer 를 제외하고 frozen 시킨다 ( 학습되지 않음 )
for param in my_model.parameters():
param.requires_grad = False
for param in my_model.linear_layers.parameters():
param.requires_gard = True
Pretrained Model Loading
pytorch에서 제공하는 vgg16 모델을 불러온다.
import torch
from torchvision import models
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
vgg = models.vgg16(pretrained=True).to(device)
print(vgg)model summary 확인
from torchsummary import summary
summary(vgg, (3,224,224))
for name, layer in vgg.named_modules():
print(name, layer)
"""
...
classifier Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
...
"""마지막에 fully connected layer 추가
새로운 layer 추가 (권장)
vgg.fc = torch.nn.Linear(1000,1)
vgg.cuda
# GPU 로 전달
vgg = models.vgg16(pretrained=True).to(device)
print(vgg)
기존 모델의 마지막 레이어 변경
vgg.classifier._moduels['6'] = torch.nn.Linear(4096,1)
Dataset 및 Dataloader 선언
import torchvision import datasets
import torchvision.transforms as transforms
import torch
dataset = datasets.ImageFolder(root="data/",
tranforms=transforms.Compose([
transforms.Resize(244),
transforms.CenterCrop(244),
transforms.ToTensor(),
transfroms.Normalize((0.5,0.5,0.5),
(0.5,0.5,0.5)),
]))
dataloader = torch.utils.data.DataLoader( dataset,
batch_size=2,
shuffle=True,
num_workers=8)network class 생성
from torch import nn
from torchvision import models
class MyNewNet(nn.Module):
def __init__(self):
super(MyNewNet, self).__init__()
self.vgg19 = models.vgg19(pretrained=True)
self.linear_layers = nn.Linear(1000,1)
# Defining the forward pass
def forward(self, x)
x = self.vgg19(x)
return self.linear_layers(x)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
my_model = MyNewNet()
my_model = my_model.to(device)★Parameter frozen
- 이미 train 된 parameter 는 학습되지 않도록 layer 를 frozen 시킨다.
- 학습할 layer 만 requires_grad 를 True 로 두어 parameter가 업데이트될 수 있도록 함.
for param in my_model.parameters():
param.requires_grad = False
for param in mymodel.linear_layers.parameters():
param.requires_grad = True
my_model.eval()
"""
...
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
(linear_layers): Linear(in_features=1000, out_features=1, bias=True)
)
...
"""data 확인
x = next(iter(dataloader))
x[0].shape # torch.Size([2, 3, 244, 244])
# BCEWithLogisticRegression 을 거치고 나면 0 또는 1로 binary classifier 된다.
my_model(x[0].to(device))
"""
tensor([[2.0336],
[0.4950]], device='cuda:0', grad_fn=<AddmmBackward0>)
"""
x[1] # tensor([2,2])학습 준비
EPOCHS = 100
BATCH_SIZE = 128
LEARNING_RATE = 0.001
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=8)학습
Tip loss 와 acc 는 slack 이나 다른 메신저로 전송하는 코드를 짜서 확인하는 것이 편하다.!
`참고` Hugging Face 는 NLP 에서 완전 필수! 이 때 Transfer Learning 이 사용된다.
# 예측 정확도 계산
def binary_acc(y_pred, y_test):
y_pred_tag = torch.round(torch.sigmoid(y_pred))
correct_results_sum = (y_pred_tag == y_test).sum().float()
acc = correct_results_sum/y_test.shape[0]
acc = torch.round(acc * 100)
return acc
my_model = MyNewNet()
my_model = my_model.to(device)
# 이미 학습된 layer는 학습되지 않도록 frozen
for param in my_model.parameters():
param.requires_grad = False
for param in my_model.linear_layers.parameters():
param.requires_grad = True
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(my_model.parameters(), lr=LEARNING_RATE)
for e in range(1, EPOCHS+1):
epoch_loss = 0
epoch_acc = 0
for X_batch, y_batch in dataloader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor)
optimizer.zero_grad()
y_pred = my_model(X_batch)
loss = criterion(y_pred, y_batch.unsqueeze(1))
acc = binary_acc(y_pred, y_batch.unsqueeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
print(f'Epoch {e+0:03}: | Loss: {epoch_loss/len(dataloader):.5f} | Acc: {epoch_acc/len(dataloader):.3f}')parameter 확인
마지막 layer 의 parameter 만 업데이트 됨
it = my_model.linear_layers.parameters()
next(it)[0][:10]7강 Monitoring tools for PyTorch
GOAL
- PyTorch 를 이용해서 학습할 때, metric 을 살펴볼 수 있는 Tensorboard, weight&biases 에 대해 배워보자.
- 딥러닝 모델 학습 실험 시에 파라미터와 metric 을 자동으로 저장하는 관리 프로세스를 익힐 수 있다.
- code versioning , 협업 관리, MLOps 의 전체 흐름 확인이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
