8강 Multi-GPU 학습
GOAL
- PyTorch 에서 Multi GPU를 사용하기 위해 모델을 병렬화하는 Model Parallel 개념 학습
- PyTorch 에서 데이터 로딩을 병렬화하는 Data Parallel 개념 학습
- 다중 GPU 환경에서 딥러닝을 학습할 때 효율적으로 하드웨어 사용 방법에 대해 배우자.
- 딥러닝 학습시에 GPU가 동작하는 프로세스 개념을 학습하자.참고 Distributed Data Parallel tutorial
Multi-GPU : 여러 장의 GPU를 어떻게 다룰 것인가
GPU가 2장 이상 있어야 실습할 수 있다.
개념 정리
- Single GPU VS. Multi GPU
- GPU 를 쓴다 VS. Node 를 쓴다.
- Node ( System ) : 한 대의 컴퓨터
- Single Node Single GPU
- 1대 컴퓨터의 1개 GPU 사용
- Single Node Multi GPU
- Multi Node Multi GPU
- NVIDIA 에서는 TensrorRT8.0 같은 도구를 사용해서 Multi GPU 학습을 지원
Model Parallel
다중 GPU를 이용하여 학습을 분산하는 방법은 두 가지가 있다.
- 모델 나누기
- 연결된 하나의 모델을 나누어 서로 다른 GPU에 병렬적으로 돌리는 것
- 데이터 나누기
- Data 를 나누어 서로 다른 GPU 에서 돌리고 각각의 미분 값의 평균을 구해주는 것
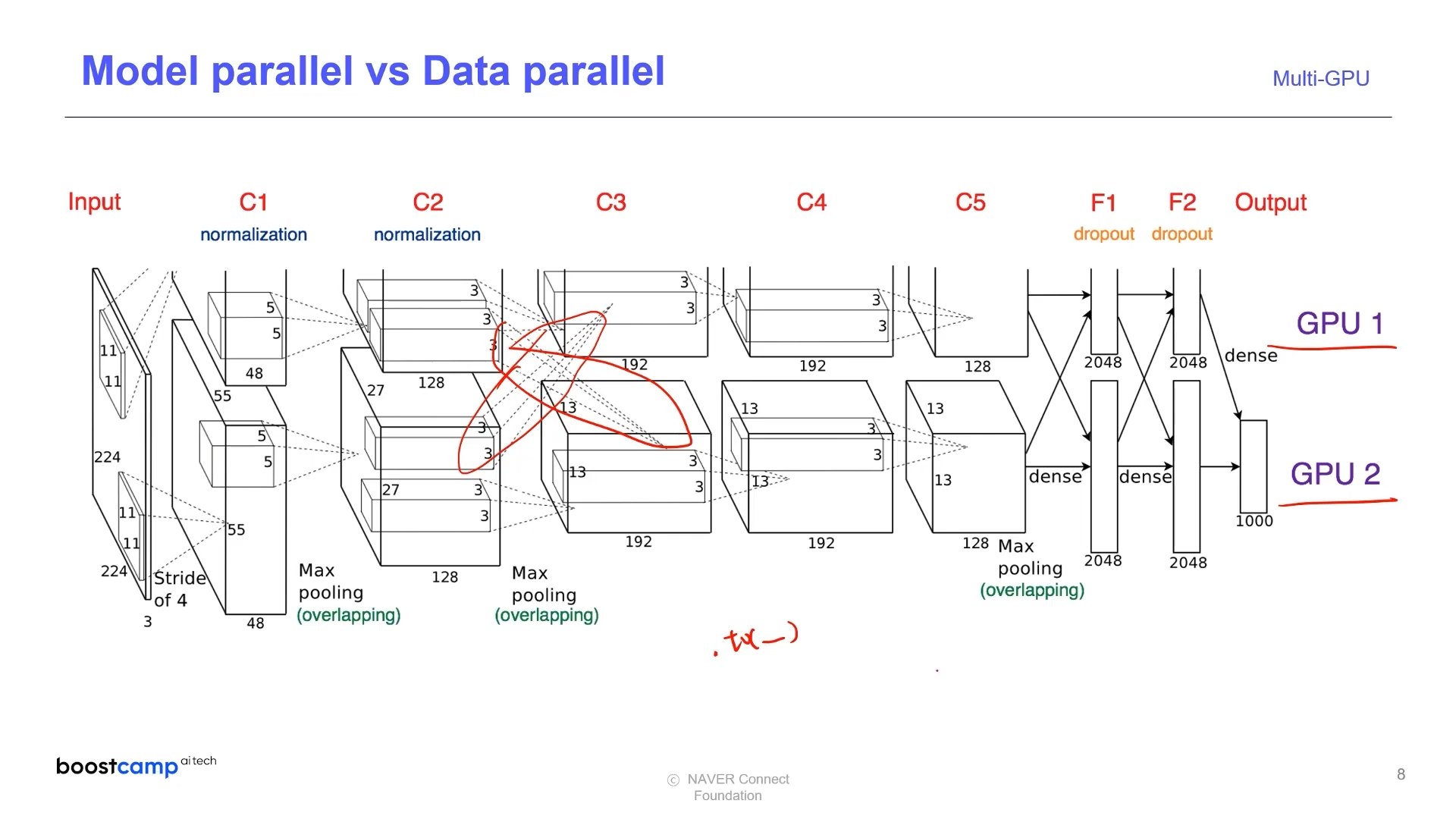
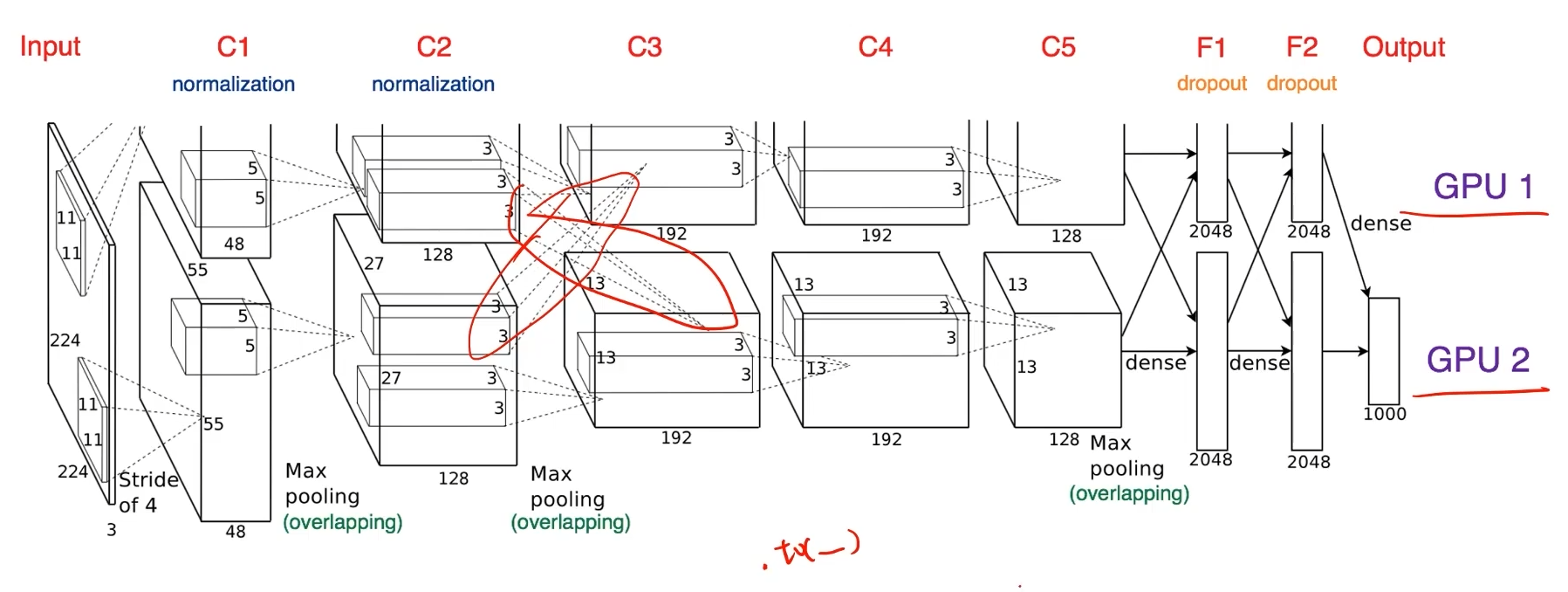
모델 나누기의 경우 alexnet 에서 예전부터 사용
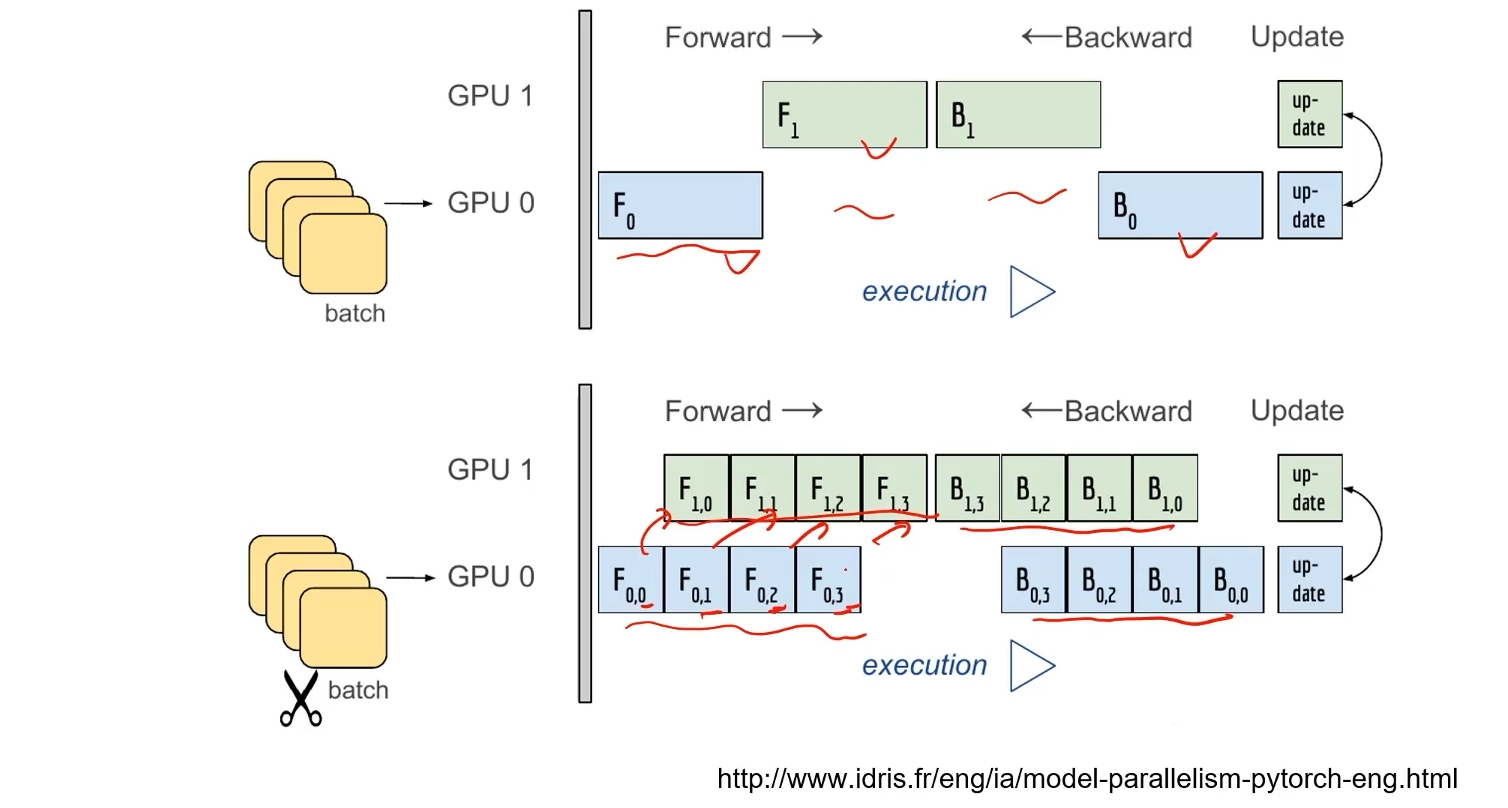
파이프라인의 어려움과 모델의 병목 현상 때문에 모델 병렬화는 고난이도 과제이다.
- 파이프라인을 잘못구성하면 첫 번째 케이스처럼 작업이 blocking 되는 현상이 발생한다.
- 두 번째 케이스처럼 병렬적으로 작업될 수 있도록 구성해야함
AlexNet
GPU 성능이 좋지 않아 나누어 처리하는 방법을 채택
- 현재는 더 큰 모델을 돌리기 위해 GPU를 병렬적으로 사용한다.
basic example
- 아래 코드는 하나의 모델이 처리를 끝낼 때까지 blocking 되어 있는 구조이므로 좋지 않다.
- 파이프라이닝을 적절하게 해서 병렬적으로 동작할 수 있도록 구성해야 한다.
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelNet50, self).__init__(Bottleneck, [3,4,6,3], num_classes=num_classes, *args, **kwargs)
# 첫 번째 모델을 cuda 0 에 할당
self.seq1 = nn.Sequential(
self.conv1, self.bn1, self.relu, self.maxpool, self.layer1, self.layer2).to('cuda:0')
# 두 번째 모델을 cuda 1 에 할당
self.seq2 = nn.Sequential(
self.layer3, self.layer4, self.avgpool,).to('cuda:1')
self.fc.to('cuda:1')
# 두 모델 연결하기
def forward(self,x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0),-1))Data Parallel
데이터를 나눠서 GPU에 할당해서 각각의 결과에 대한 평균을 구하는 방법
- 하나의 GPU가 다른 GPU의 일을 받아서 처리해주는 경우가 있다.
- GPU 사용 불균형 문제가 발생할 수 있다.
- 해당 GPU Size 에 맞게 Batch Size 를 조절해야한다.
- Global InterPreter Lock
- GPU 사용 불균형 문제가 발생할 수 있다.
- minibatch 와 유사한 개념으로 각 batch가 여러 GPU에서 수행된다.
DistributedDataParallel: 각 CPU마다 Process를 생성하여 개별 GPU에 할당하여 학습하는 모듈- DataParallel 로 한 뒤, 개별적으로 연산을 해 평균을 냄
- 각각 forward , backward 를 통해 gradient 를 구하고 , gradient 의 평균을 구하는 방식
- DataParallel 로 한 뒤, 개별적으로 연산을 해 평균을 냄
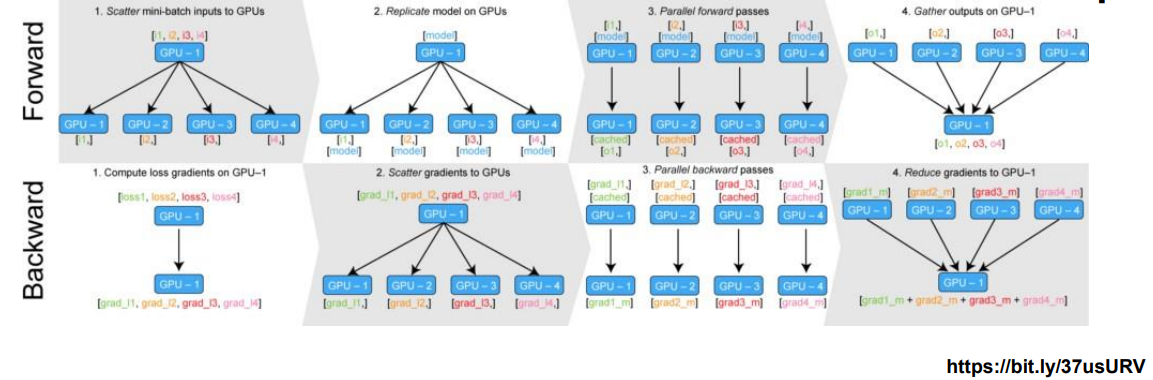
basic example - DataParallel
parallel_model = torch.nn.DataParallel(model) 을 이용해 DataParallel 를 이용할 수 있다.
parallel_model = torch.nn.DataParallel(model)
# Forward pass on multi-GPUs
predictions = parallel_model(inputs)
# Compute loss function
loss = loss_function(predictions, labels)
# Average GPU-losses + backward pass
loss.mean().backward()
# Optimizer Step
optimizer.step()
# Forward pass with new parameters
predictions = parallel_model(inputs)
basic example - DistributedDataParallel
DistributedSampler를 사용해야 한다.
- index 를 어떻게 사용할 것인지에 대한 전략
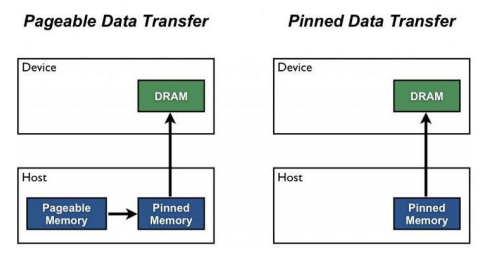
pin memory설정 : GPU 데이터 공간으로 바로 전달 하기 위함num_workers는 GPU 개수의 4배를 입력batch_size와num_worker를 n_gpus 로 나누어 주어야 한다.
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data).shuffle=False
pin_memory = True
trainloader = torch.utils.data.DataLoader(train_data,batch_size=20, pin_memory=pin_memory,num_workers=3,shuffle=shuffle,sampler=train_sampler)
pin_memory
DRAM 을 거치지 않고 GPU 용 메모리인 VRAM 으로 바로 할당
def main():
n_gpus = torch.cuda.device_count()
torch.multiprocessing.spawn(main_worker,nprocs = n_gpus.args=(n_gpus,))
def main_worker(gpu, n_gpus):
image_size = 224
batch_size = 512
num_worker = 8
epochs = ...
batch_size = int(batch_size/n_gpus)
num_worker = int(num_worker / n_gpus)
# 멀티프로세싱 통신 규약 정의
torch.distributed.init_process_group(
backend='nccl’,init_method='tcp://127.0.0.1:2568’ , world_size=n_gpus,rank=gpu)
model=MODEL
torch.cuda.set_device(gpu) model=mod
el.cuda(gpu)
# Distriubted dataparallel 정의
model=torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
# Python 의 멀티 프로세싱 코드
from multiprocessing import Pool
def f(x):
return x*x
if__name__=='__main ':
with Pool(5) asp: print(p.map(f, [1, 2, 3]))9강 Hyperparameter Tuning
참고 Pytorch 와 Ray 같이 사용하기 Tutorial
TODO 89강 실습파일 다시보기
TODO Ray 사용법 이해하기
GOAL
- Ray Tune 프레임워크로 HyperParameter 최적화 방법 학습 : PyTorch 기반으로 여러 config 들을 통해 parameter 의 지역 최적해를 구할 수 있도록 도와줌
- Parameter Search 방법론 학습 : Grid & Random, Bayesian
- Ray Tune 모듈을 사용하여 PyTorch 딥러닝 프로젝트 코드 구성을 하는 방법을 익히기
1. 모델의 모든 layer에서 learning rate가 항상 같아야 할까요? 같이 논의해보세요!
2. ray tune을 이용해 hyperparameter 탐색을 하려고 합니다. 아직 어떤 hyperparmeter도 탐색한적이 없지만 시간이 없어서 1개의 hyperparameter만 탐색할 수 있다면 어떤 hyperparameter를 선택할 것 같나요? 같이 논의해보세요!모델 학습 결과가 만족스럽지 못할 때 아래 세 가지 방법을 사용해 볼 수 있다.
1. 모델을 바꿔보기
- 어느정도 정량화 되어 있다.
- CV : ResNet, ImageTransFormer
- NLP : TransFormer
2. 데이터 추가 또는 오류 제거
- 가장 효과가 좋다.
3. Hyper Parameter Tuning
- 조금 더 성능 개선을 원할 때
Hyperparmeter Tuning
- learning rate , 모델 크기 , optimizer 등..
- NAS 나 AutoML 등으로 일부 자동화하는 방법도 있다.
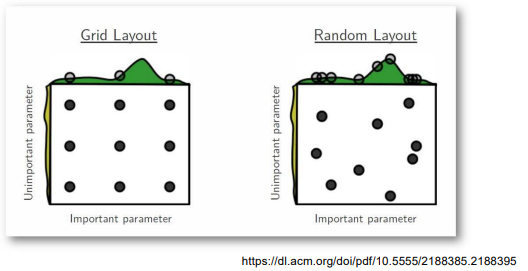
Grid 와 Random
- Grid Search : 값에 log 를 취하여 일정한 격자 간격으로 샘플링
- 최근에는 베이지안 기법을 다룬 BOHB 같은 논문들이 주고 하고 있다.
Ray
참고 Ray 를 사용하려면 TensorBoard 를 설치해주어야 한다.
참고 Weight and Bias 를 설치해서 확인하는 것도 도움이 된다.
Multi-node 와 multi processing 모듈을 지원한다.
- 병렬 처리를 위해 개발된 모듈
- 기본적으로 현재의 분산 병렬 ML/DL 모듈의 표준
- Hyperparameter Search 를 위한 다양한 모듈을 제공한다.
- 스케줄러를 잘 선택하면 효율적으로 hyper parameter 를 선택할 수 있다.
- Hyper Parameter tuning 할 때, Ray 를 사용할 때는 학습하려는 모델을 하나의 함수에 몽땅 넣어줘야 한다.
- 학습공간 지정
- 학습 스케줄링 알고리즘 지정
- 의미없는 metric 을 잘라냄
- 결과 출력 양식 지정
- 병렬 처리 양식으로 학습 시행
- 학습하려는 모델을 하나의 함수에 몽땅 넣어주어야 한다.
가벼운 모델이 조금 더 좋은 성능을 낼 수 있도록 하기 위해 Hyper Parameter Tuning 을 사용한다.
처음 프로젝트를 할 때는 어떻게하면 데이터를 더 모을 수 있을까를 생각하는 것이 좋은 성능을 낼 수 있는 지름길 !
10강 PyTorch Troubleshooting
GOAL
- PyTorch 를 사용할 때 자주 발생할 수 있는 OOM 오류 살펴보기
- GPU 에서의 Out Of Memory ( OOM ) 에러 상황들의 예시 및 해결 방법 학습
- GPU 사용시 발생할 수 있는 문제들이 생겼을 때, GPU 메모리 디버깅을 도와주는 툴 소개
- 놓칠 수 있는 사소한 실수들의 예제 확인하기
참고자료
왜, 어디서 발생했는지 알기 어렵고 , Error Backtracking 이 이상한 곳으로 가기도 하고, 메모리의 이전 상황 파악이 어렵다.
- iteration 을 돌다가 오류가 발생하는 경우가 있는데, 메모리의 이전 상황을 파악하기 어렵다.
Batch Size 를 줄이고 GPU 를 clean 한 다음 Run !
- a.k.a 런타임 다시 시작 ...
- 이렇게 된다면 코드엔 문제가 없다.!
런타임 재시작 외에 사용할 수 있는 방법
GPUUtil 사용하기
- nvidia-smi 처럼 GPU 의 상태를 보여주는 모듈
참고COLAB은 환경에서 GPU 상태 보여주기 편함
- iteration 마다 메모리가 늘어나는지 확인
- 메모리 사용량이 점차 늘어난다면 메모리가 잘 못 쌓이고 있음을 알 수 있음
!pip install GPUtil
import GPUtil
GPUtil.showUtilization()torch.cuda.empty_cache() 써보기
loop 이 시작되기 전에
torch.cuda.empty_cache()
- 이전 학습에 의해 점유된 memory 를 정리한다.
- GPU 상에서 사용되지 않는 cache 를 정리한다.
- backward 연산을 할 때 buffer 에 연산이 쌓이고 있다.
- 가용 메모리를 확보할 수 있다.
- 메모리 연결을 끊어주는 del 과는 구분이 필요하다.
- relunch ( reset ) 대신 쓰기 좋은 함수

training loop 에 tensor 로 축적되는 변수 확인하기
- tensor 로 처리된 변수는 GPU 메모리를 사용한다.
required_grad = True이면 memory buffer 까지 사용
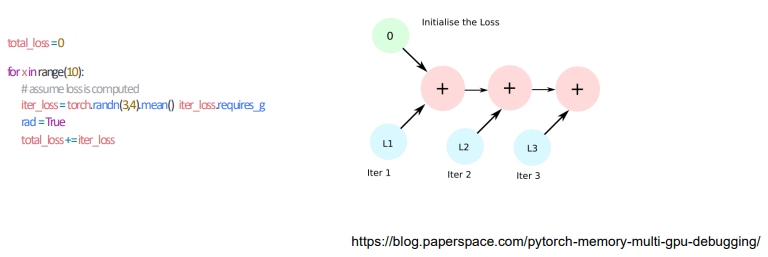
- loop 안의 연산 과정에 있을 때 GPU 에 computational graph 를 생성하여 메모리를 잠식하게 되는 현상이 발생
- 각 loss 의 값이 축적되는 과정에서 계속 쌓기게 되는 문제
- 미분은 가능하지만 과도하게 메모리를 많이 잡아먹는 코드가 생성됨

1-d tensor 의 경우 python 기본 객체로 변환하여 처리할 것
- 일회성으로 사용되는 변수가 불필요하게 메모리에 쌓이는 것을 방지
iter_loss.item# python 기본 객체로 반환float(iter_loss)
del 명령어 적절히 사용하기
- 필요 없어진 변수는 적절히 삭제해주어야함
- Python 의 메모리 배치 특성상 loop 이 끝나도 메모리를 차지하기 때문이다.
- Python의 메모리 읽어보기
TODO글만 읽어봤을 땐 언제 써야하는지 잘 모르겠다.
- Python의 메모리 읽어보기
가능한 batch 사이즈 실험해보기
- batch_size 를 1로 해서 몇 번까지 돌릴 수 있는지 실험해보기

torch.no_grad() 사용하기
- Inference 시점에서는 torch.no_grad() 구문을 사용
- 학습을 통해 만들어진 모델에 새로운 데이터를 적용하여 결과를 만드는 단계
- backward pass 로 인해 쌓이는 메모리에서 자유롭다.


그 외 에러들 ( CUDNN_STATUS_NOT_INIT, device-side-assert )
그외 다양한 에러들이 발생할 수 있으므로 검색을 통해 해결하고 잘 정리해놓는 것이 좋음
- CUDNN_STATUS_NOT_INIT : GPU 설치 문제일 확률이 높음
그 외 ( Colab 에서 LSTM, CNN 에러 : SIZE 확인 등 )
colab 에서 너무 큰 사이즈는 실행하지 말자
- 예를 들어 LSTM..
CNN 에러의 경우 크기가 안맞아서 생길 확률이 높음
- torch summary 등으로 사이즈 확인 후 맞춰주기
tensor 의 float precision 을 16bit로 줄이는 방법을 사용할 수도 있음
- 효과가 크지는 않음
- 잘 안씀
