1강 Historical Review
GOAL
- 딥러닝이 무엇인지 이해하기
- 딥러닝이 등장한 역사 배경과 발전 과정 살펴보기
- 2012년부터 최근까지 이어지는 딥러닝 연구 패러다임 살펴보기
- 딥러닝 관점에서 Data, Model, Loss, Optimization algorithms 에 대해 설명
good deep learner 가 되기 위한 요소
- Implementation Skills
- Math Skills ( Linear Algebra, Probability )
- Knowing a lot of recent papers
- 최신 연구 동향 따라가기
Introduction
Deep Learning 이란, Neural Network 를 활용하여 data 를 이용해 대상이 되는 것을 학습하는 것
- AI 의 일부로 이해
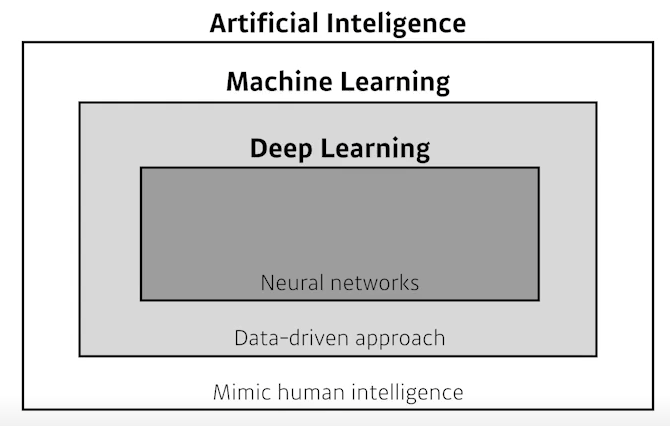
Key Components of Deep Learning
data, model, loss, algorithm 관점에서 바라보면,
새로운 연구와 논문을 볼 때 이전 연구에 비해 어떤 장점과 contribution 이 있는지 이해하기 쉽다.
- The data that the model can learn from
- The model how to transform the data
- The loss function that quantifies the badness of the model
- The algorithm to adjust the parameters to minimize the loss
Data
풀고자 하는 문제에 종속됨
-
Data depend on the type of the problem to solve
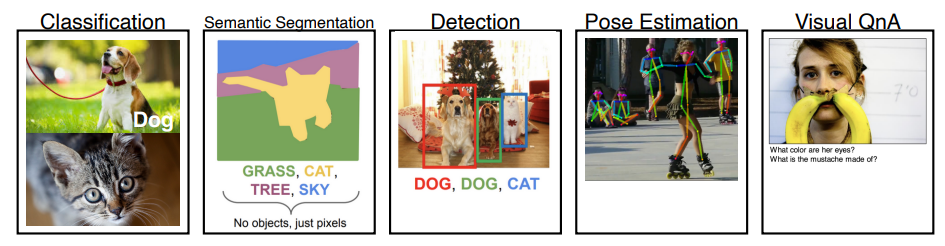
-
예를 들어- Classification : image labeling
- Semantic Segmentation : image 의 pixel 별로 각 pixel 이 어느 영역에 속하는지 판별
- Detection : Image 안의 물체에 대한 bounding box 탐색
- Pose Estimation : Image 속 사람의 3D 혹은 2D skeleton 정보 도출
- Visual QnA : 이미지와 질문이 주어졌을 때 답을 도출
Model
동일한 데이터와 태스크가 주어지더라도 어떤 모델을 사용하는지에 따라 성능이 다를 수 있다.
Loss
모델과 데이터가 정해졌을 때, weight 의 각각 parameter 들을 어떻게 업데이트할지 기준이 되는 함수를 결정
-
The loss function is a proxy of what we want to achieve
-
예를 들어- Regression Task : Neural Network 의 출력값과 타겟점 사이의 two square loss 를 최소화 시키는 것을 목표로 함
- Classification Task : Neural Network 의 출력값과 label data 사이의 cross entropy loss 를 최소화
- Probabilistic Task : 확률적인 모델을 사용할 때, 출력값을 평균과 분산 그리고 가우시안으로 모델링한다. 이 때 loss 는 Maximum liclihood Estimation 관점에서 바라본다.
- Regression Task : Neural Network 의 출력값과 타겟점 사이의 two square loss 를 최소화 시키는 것을 목표로 함
-
Loss function 은 우리 목적의
proxy(근사치)에 불과하다.- 분류 문제나 회귀 문제를 푼다고 했을 때 loss 값이 줄어드는 것을 목적으로 볼 수 있지만, loss 값이 줄어든다고 원하는 것을 항상 이룬다고 볼 수 는 없다.
예를 들어- Regression Task 를 푸는데 data 에 loss 가 많다고 해보자.
- MSE 를 사용하게 되면 outlier 값이 크게 영향을 미쳐 정상적인 학습이 어렵다.
- 1-norm 또는 roburst regression 에 등장하는 다른 loss function 을 시도해보아야 한다.
왜 이 loss function 을 사용하는지와 loss function 의 값이 줄어드는 것이 풀고자 하는 문제를 어떻게 푸는지를 이해하는 것이 중요하다.
Optimization Algorithm
Data, model 그리고 loss function 이 정해졌을 때 network 를 어떻게 줄일지에 대한 것
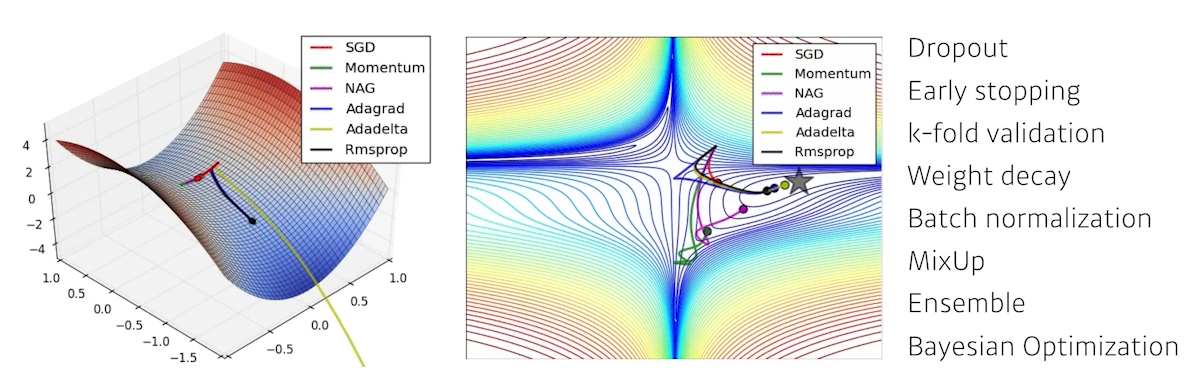
- Neural Network 의 parameter 를 loss function 에 대해 1차 미분한 정보를 활용한다.
- Stochastic Gradient Descent
- 일반적으로 SGD 의 변형인 momentum, Adam , Adam 같은 다른 momentum 과 adaptive learning rate 을 사용하는 방법론을 사용함
-Optimation 방법론들의 특성을 이해하는 것이 중요
- 학습이 잘 되지 않게 하는 방법론을 추가하기도 한다.
학습에 사용되지 않은 다른 데이터를 사용할 때도 잘 동작하도록 하기 위해- Dropout, Early Stopping, K-fold validation, Weight decay, Batch normalization, MixUp, Ensemble, Bayesian Optimization 등의 기법을 사용한다.
Historical Review
| Column 1 | Column 2 | Column 3 | Column 4 |
|---|---|---|---|
| 2012 | AlexNet | 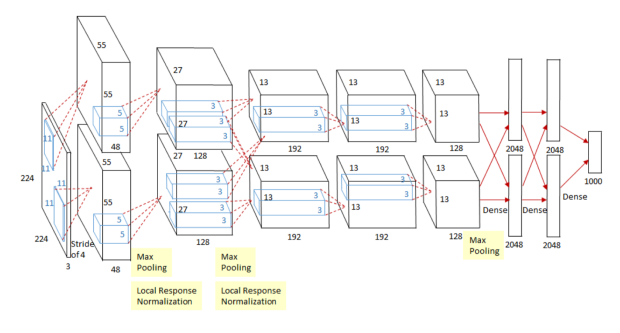 | 224x224 이미지를 분류하는 것이 목적 |
| 2013 | DQN | 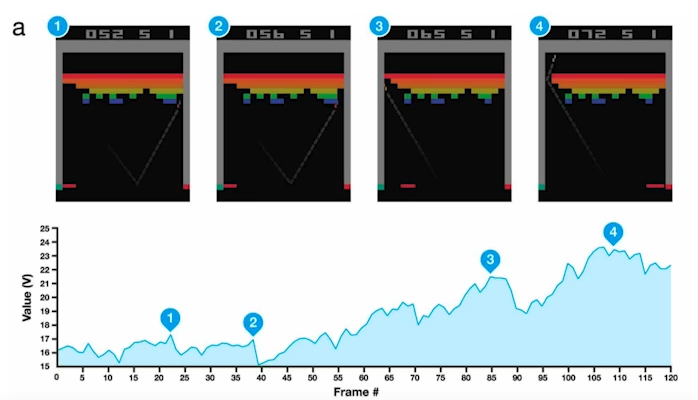 | 강화학습 방법론 |
| 2014 | Encoder/Decoder, Adam | 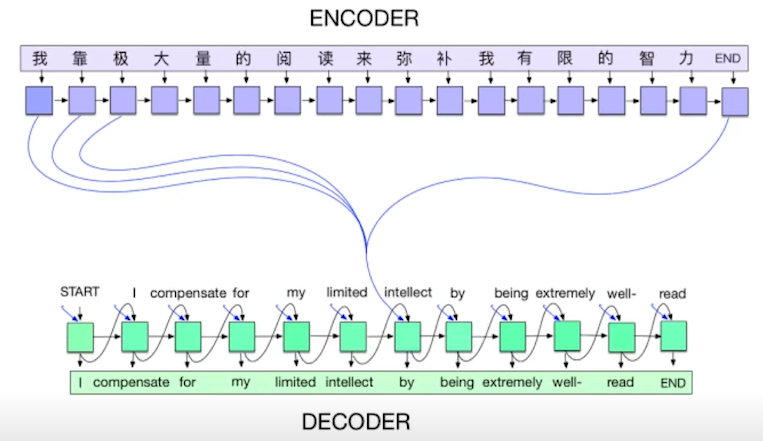 | Encoder/Decoder : Input Sequence 를 output sequence 로 변환 Adam : Hyper parameter tuning 의 부담을 줄여준 optimizer |
| 2015 | Gan,ResNet |  | GAN : Network 가 Generator 와 Discriminator를 이용해 학습 ResNet : layer 를 깊게 쌓아도 test dat a 에서 좋은 성능을 낼 수 있게 됨 |
| 2017 | Transformer |  | 다른 구조의 방법론(RNN 등)들을 대체 attention, multi-head attention 을 잘 이해해보자. |
| 2018 | BERT (Fine Tuned NLP model ) | 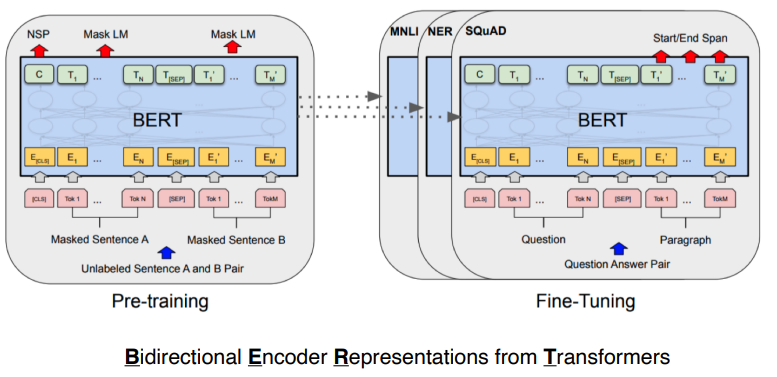 | 대량의 데이터로 pre-train 한 뒤 내 데이터로 fine tune |
| 2019 | Big Language Models(GPT-X) |  | Fine tuning 을 통해서 여러 Sequence model( 문장, 프로그램, 표 등)을 만들 수 있다. 많은 parameter 가 특징 |
| 2020 | Self-Supervised Learning | 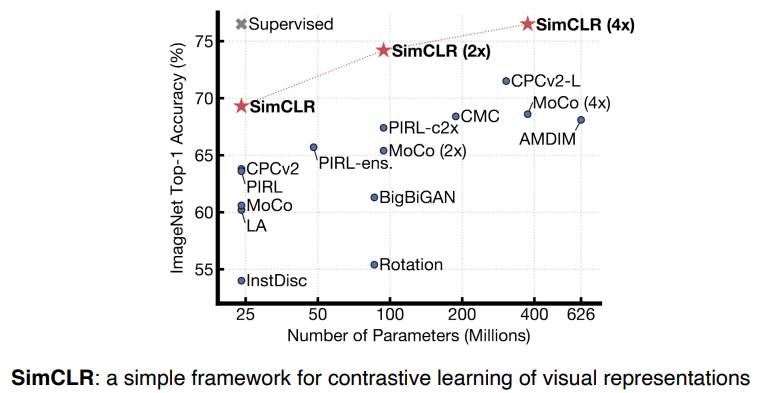 | 한정된 학습 데이터가 주어졌을 때 labeling 되지 않은 데이터를 학습에 함께 씀 도메인 지식을 바탕으로 데이터셋을 추가로 만들어서 데이터셋을 뻥튀기 하는 방법 ( self-supervised data sampling ) |
2강 Neural Networks & Multi-Layer Perceptron
GOAL
- 신경망(Neural Networks) 의 정의와 Deep Neural Networks 에 대한 이해
- Linear neural networks 의 예시로 Data, Model, Loss, Optimizatoin algorithm 정의
- Multi-layer perceptron 와 같이 더 깊은 네트워크는 어떻게 구성하는지 학습
- Deep Learning 에서
학습이 가지는 의미에 대해 설명- MLP 실습
- MLP 과제
1. Regression Task와 Classification Task의 loss function이 다른 이유는 무엇인가요?
- Regression Task 은 n차원 input 과 output 을 이용하여 서로 간의 관계성을 찾아나가는 문제이다. 예측값과 실제값을 비교하며 차이를 줄여나가는 방법을 사용한다.
- Classification 은 어떤 대상을 n 개의 분류 중하나로 특정하는 문제이다. input 이 주어졌을 때 가장 확률이 높은 카테고리로 분류하는 방법을 사용한다.
2. Regression Task, Classification Task, Probabilistic Task의 Loss 함수(or 클래스)는 Pytorch에서 어떻게 구현이 되어있을까요? ( 참고 페이지: [pytorch official docs](https://pytorch.org/docs/stable/nn.html#loss-functions) )
Neural Networks
Affine transformation 에 nonlinear transformation(activation function)이 반복적으로 일어나는 function approximators 로 정의하기도 함
- Neural networks are function approximators that stack affine transformations follwed by nonlinear transformations.
Linear Neural Networks
목적 : 1차원인 입력과 출력의 관계를 나타내는 모델(함수)을 찾는 것

- 선형 문제를 정의하고 convex loss function 을 정의하면 W와 b에 대해 analytics function이 존재 ( := loss 가 최소가 되는 최적의 W, b를 찾을 수 있다. )
하지만데이터의 수 , 모델의 선형성, convex function 이라는 많은 제약 조건이 존재
-
backpropagation: parameter 가 어느 방향으로 움직였을 때, loss 가 줄어드는지 찾아 그 방향으로 parameter 학습loss function 을 W에 대해 편미분한 값,loss function을 b에 대해 편미분한 값을 구해서 특정 step size 를 곱해 빼줌으로써 업데이트- parameter 에 대한 편미분 값을 구해서 업데이트하는 방식
- 적절한 step size 를 찾는 것이 중요 ( adaptive learning rate , ... )
Multi-dimensional input and output
행렬 ( 2개의 vector space 또는 서로 다른 차원 사이의 선형 변환 ) 로 표현할 수 있다.
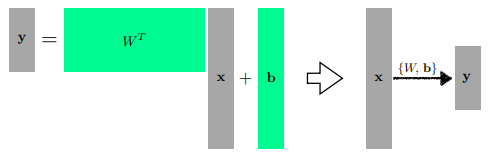
Beyond Linear Neural Networks
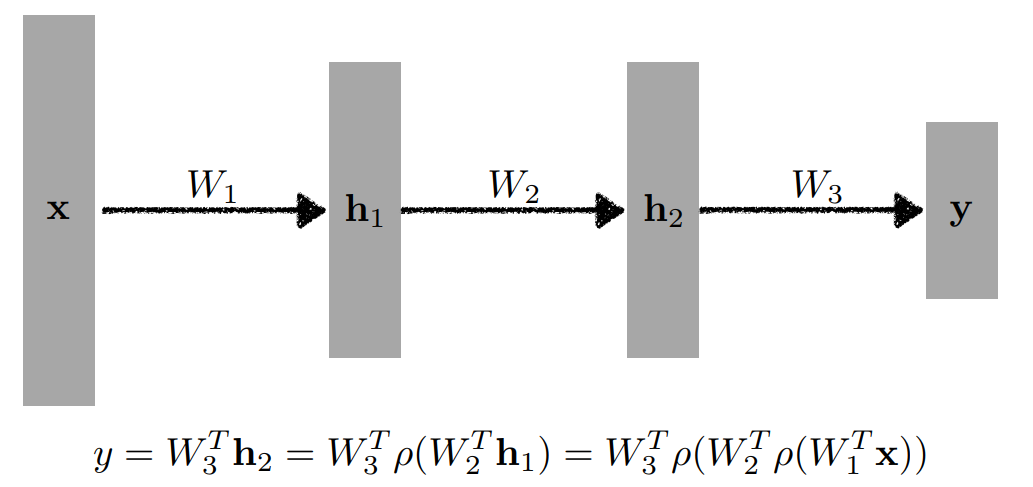
선형 변환만 쌓으면 결국 선형 변환으로 귀결되기 때문에 아무리 쌓아도 1단짜리 레이어와 같아진다.
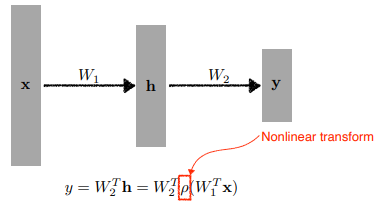
Nonlinear transform (activation function) 으로 표현력을 증대해줌
Multi-Layer Perceptron
loss function
왜 이 loss function 을 사용하는지와 loss function 의 값이 줄어드는 것이 풀고자 하는 문제를 어떻게 푸는지를 이해하는 것이 중요하다.
- input 과 output 의 값의 차이를 최소화
- 분류 문제의 output 은 일반적으로 one-hot vector 로 표현된다.
- 내 neural network 의 출력값 중에서 ( logits )만 높이려고 함
- 해당하는 class 의 해당하는 값만 높여 classification 을 도움
- Output 을 확률적으로 모델링함
예를 들어기쁨 20%, 슬픔 30%, 환호 50%
- Output 을 확률적으로 모델링함
3강 Optimization
GOAL
용어의 명확한 컨셉을 이해하자 !
- Optimization 과 관련된 용어 이해
- 다양한 최적화 기법(gradient descent) 에 대한 학습
- Regularization 방법 학습
Further Questions
- Cross-Validation을 하기 위해서는 어떤 방법들이 존재할까요?
- Time series의 경우 일반적인 K-fold CV를 사용해도 될까요?MORE
Introduction
Gradient Descent
찾고자 하는 parametre 를 loss function 에 대해 미분한 편미분값을 이용하여 parameter update local minimum을 찾아가는 과정
- First-order iterative optimization algorithm for finding a local minimum of a differentiable function.
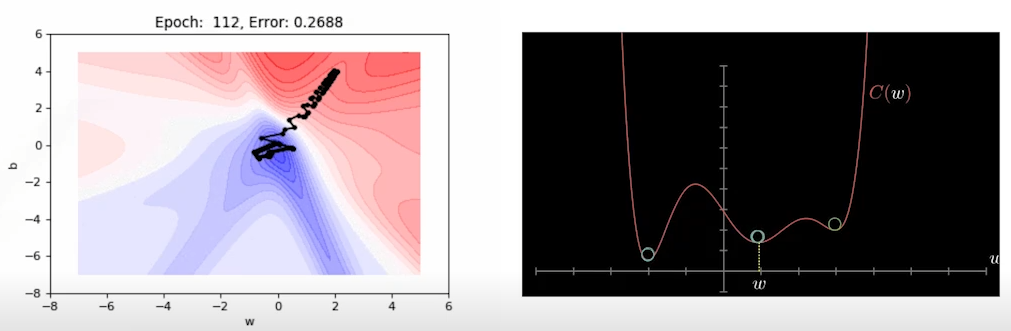
Important Concepts in Optimization
- Generalization
- Under-fitting vs. over-fitting
- Cross validation
- Bias-variance tradeoff
- Bootstrapping
- Bagging and boosting
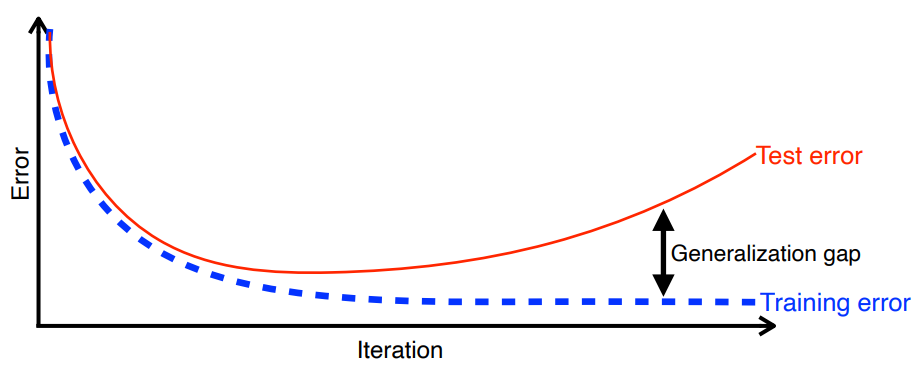
Generalization
학습 데이터로 평가한 성능과 테스트 데이터로 평가한 성능이 얼마나 차이가 있는지에 대한 지표
- How well the learned model will behave on unseen data.
참고Generalization 이 좋다는 것이 성능이 좋다는 것은 아님
- 학습 데이터의 성능이 좋다는 의미를 내포하는 것이 아니기 때문
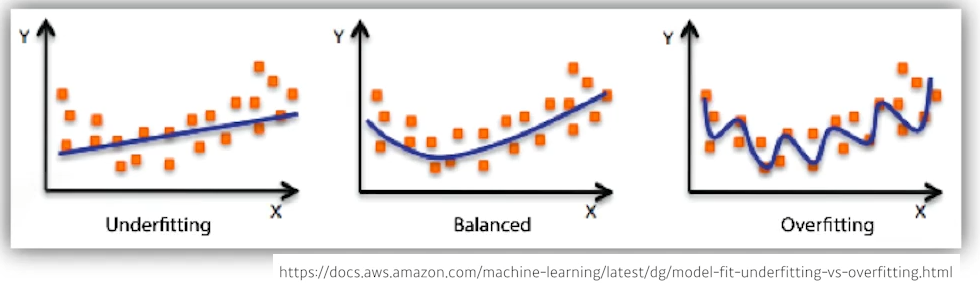
Under-fitting vs. over-fitting
학습 데이터를 hit 하지 못하는 under-fitting 과 학습 데이터에 과적합되는 over-fitting
Cross Validation
training data 와 validation data 를 나눠서 제공하여 학습에 사용되지 않은 validation dataset 에서 성능을 얼만큼 내는지 확인할 수 있다.
- Cross-validation is a model validation technique for assessing how the model will generalize to an independent(test) dataset.
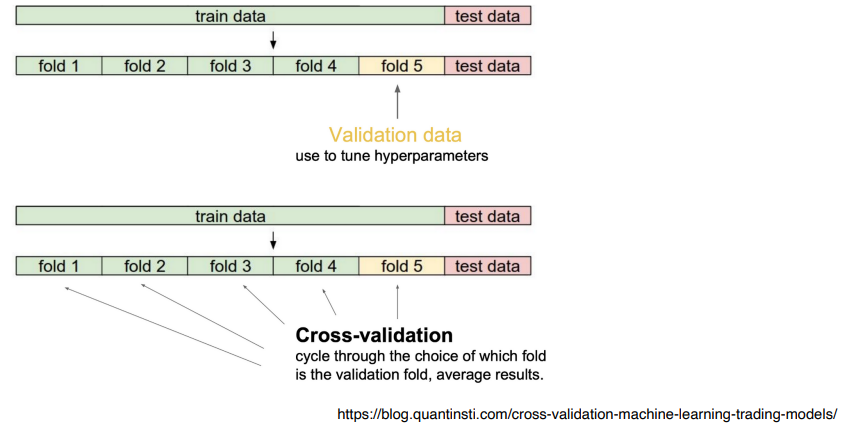
- 학습 데이터를 k개로 나누어 일부를 validation dataset 으로 쓴다. ( K-fold cross validation)
예를 들어10만개의 데이터셋을 5개로 나누어 {1,2,3,4} 를 training 으로 {5}를 validation 으로 사용- 다음 번에는 {1,2,3,5} / {4} 로 나누어 사용
- Cross Validation 으로 hyper parameter 를 search 하는 방법을 사용한다.
- Training 시에는 모든
학습데이터를 사용
- Training 시에는 모든
Bias and Variance
Variance: 어떤 입력을 넣었을 때 출력이 얼마나 일관적으로 나오는지- Variance 가 낮다 := 출력이 일관된다.
Bias: 평균적으로 봤을 때 내가 원하는 값과 얼마나 근사한지- Bias 가 낮다 := 근사한 값을 가진다.
- 모델이 단순해질수록 입력에 대한 민감도가 낮아지기 때문에 variance 가 낮아지고 기댓값과 차이가 커지기 때문에 bias 가 커진다.
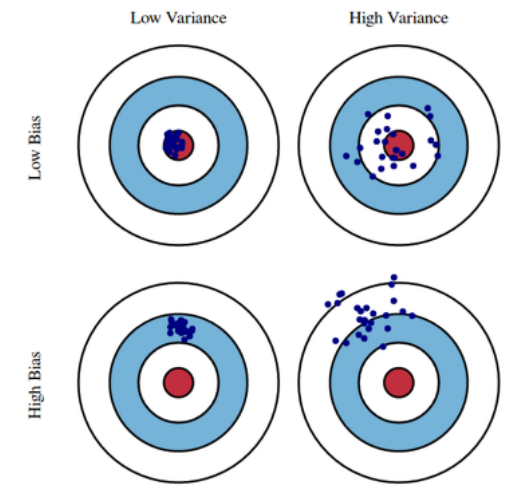
Bias and Variance Tradeoff
입력 데이터에 noise가 껴 있다고 가정했을 때, 최소화 대상인 cost 는 bias, variance 그리고 noise 의 합성으로 볼 수 있다. ( := cost 를 minimize 할 때 세 개의 요소들은 tradeoff 관계이다. )
- We can derive that what we are minimizing (cost) can be decomposed into three different parts: bias, variance, and noise.

Bootstrapping
고정된 학습 데이터에서 sub sampling 을 이용하여 여러 모델을 만들어서 지표로 사용
- Bootstrapping is any test or metric that uses random sampling with replacement.
Bagging and boosting
-
Bagging( Bootstrapping aggregating)- 학습 데이터가 고정되어 있을 때, 여러 개의 모델들을 만들어 그 결과값을 평균 내는 것 (
Enssemble) - Multiple models are being trained with bootstrapping
- ex) Base classifiers are fitted on random subset where individual predictions are aggreagted (voting or averaging)
- 학습 데이터가 고정되어 있을 때, 여러 개의 모델들을 만들어 그 결과값을 평균 내는 것 (
-
Boosting- 예측이 잘 안된 데이터만 모아서 모델을 따로 만들어 합치는 방법
- weak learner 들을 sequence 하게 합쳐서 하나의 strong learner 를 만들어 냄
- 각각의 weak learner 들의 weight 를 찾는 방법으로 정보를 취합함
- It focuses on those specific training samples that are hard to classify.
- A strong model is built by combining weak learners in sequence where each learner learns from the mistakes of the previous weak learner.
- weak learner 들을 sequence 하게 합쳐서 하나의 strong learner 를 만들어 냄
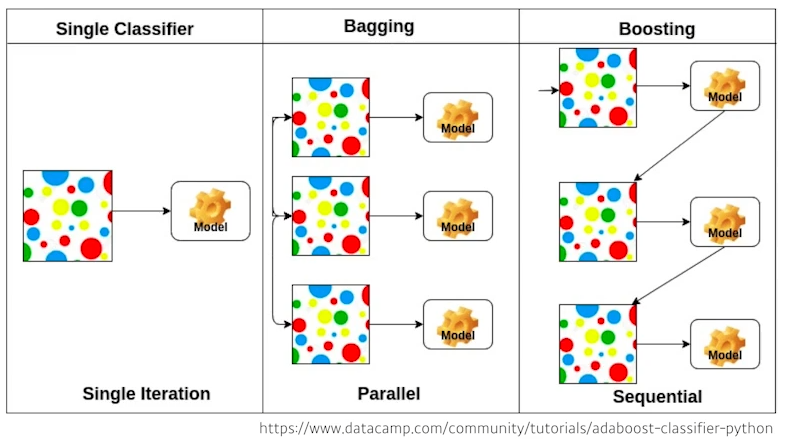
- 예측이 잘 안된 데이터만 모아서 모델을 따로 만들어 합치는 방법
Gradient Descent Methods
Stochastic gradient descent
- 하나의 sample 을 통해서 gradient 를 업데이트 하는 것
- Update with the gradient computed from a single sample
★Mini-batch gradient descent
- 지정한 batch size 만큼의 sample 을 통해서 gradient 를 구해서 업데이트 하는 방법
- 일반적으로 batch-size 가 작을수록 좋은 generalization 성능을 보인다.
- Batch-size Matters
- Update with the gradient computed from a subset of data
참고On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
- Batch-size 가 작을수록 좋은 generalization 성능을 보임을 실험적으로 증명
- 큰 batch-size 를 사용하기 위한 방법 소개
Batch gradient descent
- 한 번에 모든 데이터를 다 사용해서 gradient 의 평균을 이용해 업데이트 하는 방법
- Update with the gradient computed from the whole data
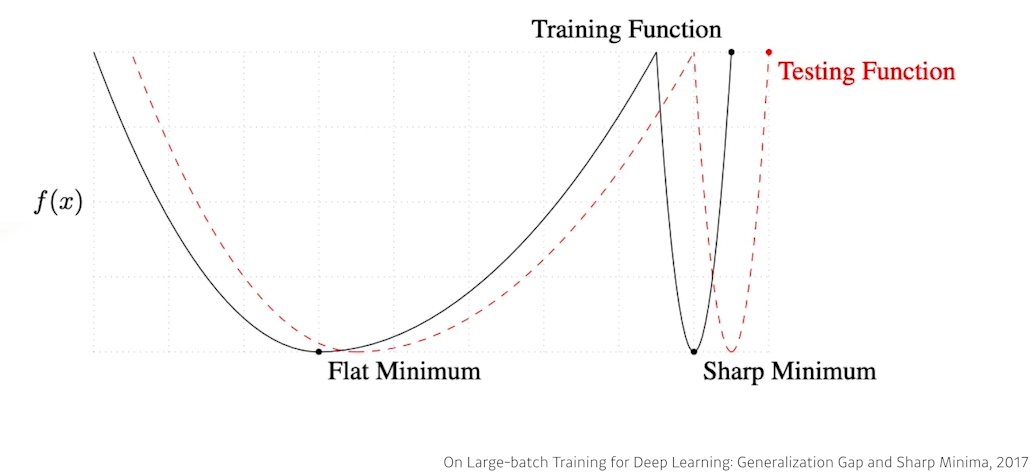
Note
각각의 optimization 이 어떤 성질을 가지고 있는지, 왜 제안되었는지 이해해보자.
- Stochastic gradient descent
gradient 를 다음 gradient 계산에 전달하여 local minimum 탐색을 도움
- Momentum
- Nesterov accelerated gradient
- Adagrad
- Adadelta
- RMSprop
- Adam
Stochastic gradient descent
단점: learning rate 이 너무 크면 학습이 잘 되지 않고 너무 작으면 학습이 너무 느리게 된다. learning rate 을 적절히 설정하는 것이 중요
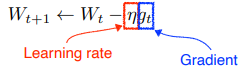
Momentum
현재 주어진 parameter 에서 gradient 를 계산해서 그 gradient 를 이용해 momentum을 accumulation
idea: 이전 batch 에서 얻어진 gradient 를 활용해보자.how: hyper parameter 와 현재 gradient 를 합친 accumulation 을 이용하여 업데이트 하는 것단점: local minimum 에 수렴하는 속도가 느릴 수 있다.
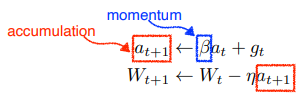
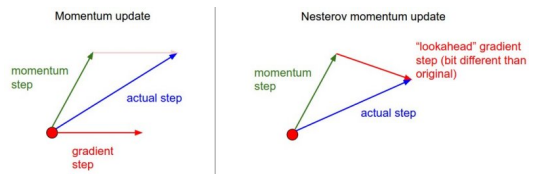
Nesterov Accelerated Gradient (NAG)
Lookahead gradient : 라는 현재 정보가 있을 때, 그 방향으로 이동해서 gradient 를 구하고 accumulate 해준다.
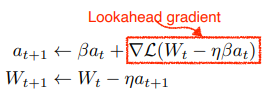
장점: local minimum 에 조금 더 빨리 수렴하는 효과가 있음
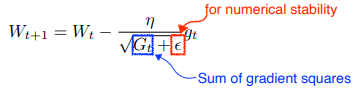
Adagrad
목적: 많이 변한 parameter 는 적게 변화 시키고, 적게 변한 parameter 는 많이 변화시키려고 함
각각의 parameter 가 얼만큼 변했는지를 알아야 한다.단점: 학습이 길어지면 의 값이 커져 가 갱신되지 않는 문제점이 발생한다.monotonically decreasing property- Adagrad adapts the learning rate, performing larger updates for infrequent and smaller updates for frequent parameters.
Adadelta
how: 현재 timestep t 가 주어졌을 때, window size 만큼의 parameter 들에 대해 시간에 대한 gradient 제곱의 변화를 살펴본다. 이 때, 이전 window size 동안의 모든 parameter 정보를 가지고 있어야 하는 문제가 있어 Exponential Moving Average of gradient squares 를 이용한다.- Adadelta extends Adagrad to reduce its monotonically decreasing the learning rate by restricting the accumulation window.

- learning rate 이 없다. 바꿀 수 있는 것이 별로 없어 잘 사용되지 않음
RMSProp
Adadelta 에서 살펴본 EMA of gradient squares 를 그대로 사용하고, 분모에 stepsize 를 사용한다.
- RMSprop is an unpublished, adaptive learning rate method proposed by Geoff Hinton in his lecture.
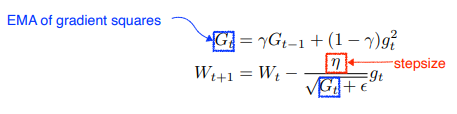
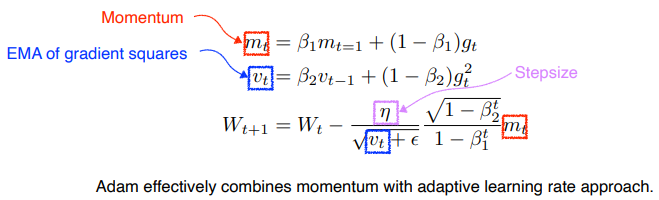
Adam
Momentum 과 adaptive learning rate 방법을 적절히 섞어 사용 의 값을 잘 바꿔주는 것이 중요
- Adaptive moment Estimate (Adam) leverages both past gradients and squared gradients.
Regularization
Generalization 을 높이기 위한 방법론
- Early stopping
- Parameter norm penalty ( weight decay )
- Data augmentation
- Noise robustness
- Label Smoothing
- Dropout
- Bath normalization
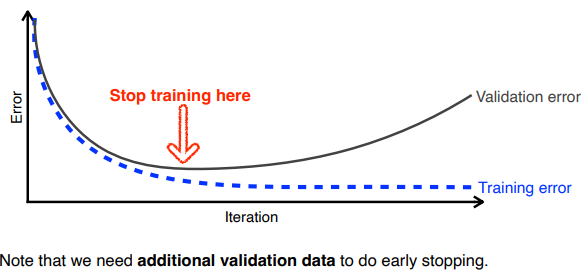
Early Stopping
학습 중 validatoin data set 에 대한 loss 값이 증가하는 시점에서 학습을 중단하는 방법
Parameter norm penalty ( weight decay )
질문 부드러운 함수( smoothness ) 가 의미하는 것이 뭘까 ? (35분)
Neural Network parameter 가 너무 커지지 않게 network weight 을 함께 줄인다.
- Neural Network 가 만들어내는 함수 공간 속에서 이 함수를 부드러운 함수로 보자.
- 부드러운 함수일수록 genearalization performance 가 높을 것이라는 가정
- It adds smoothness to the function space.

Data augmentation
Deep Learning 방법론에서는 데이터가 많을수록 performance 가 높아진다.
Label preserving augmentaion
- label 이 변경되지 않는 선에서 augmentation
참고MNIST dataset 에서 flip 을 해버리면 label 정보가 바뀌어버릴 수 있으므로 flip 은 하지 않는 것이 좋다. ( 예 : 6 9 )

Noise robustness
Weight 를 학습시킬 때 noise 를 추가하는 것이 성능을 높일 수 있음이 실험적으로 증명
- Add random noises inputs or weights

Label Smoothing
★Data 가 상대적으로 적다면 mixup 와 cutmix 사용을 고려해보자.
두 개의 training data 를 섞는 것
Decision boundary 를 부드럽게 만들어주는 효과가 있음
- Mix-up constructs augmented training examples by mixing both input and output of two randomly selected training data.

두 개의 training data 를 blending 하지 않고 합쳐 놓는 방법
- CutMix constructs augmented training examples by mixing inputs with
cut and paste and outputs with soft labels of two randomly selected
training data.

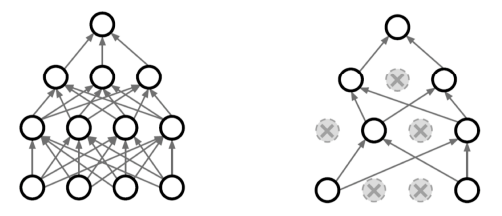
Dropout
Neural network 에서 일정 비율의 weight 를 0으로 바꾸는 것
- In each forward pass, randomly set some neurons to zero.
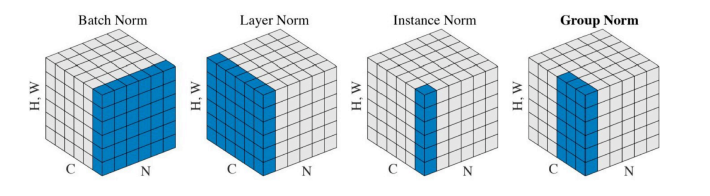
Bath normalization
적용하고자 하는 layer 의 statistics를 정규화시키는 것
예를 들어Neural network 각각의 layer가 1,000개의 parameter 를 가질 때, 1,000개의 parameter 각각에 대한 statics 가 mean zero , unit variance 가 되도록 만드는 것

Batch Normalization 의 다른 방법론들
이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
