7강 Recurrent Neural Networks
GOAL
- Sequnetial data type 에 대한 학습 ( 주식 차트, 자연어 등 )
- Recurrent Neural Networks 가 Sequantial model 로서 작동하는 방법과 종류에 대해 학습
Further Questions
1. CNN 모델이 Sequantial 데이터를 처리하는 데에는 구체적으로 어떤 한계점이 있나요?
- 시간/순서 개념을 반영하지 못함
2. LSTM 에서는 Modern CNN 내용에서 배웠던 중요한 개념이 적용되어 있습니다. 무엇일까요?
-
RNN, LSTM, GRU 는 각각 어떤 문제를 해결할 때 강점을 가질까요?
- MLP : vector to vector
CNN : Image data 처리
- classification one-hot vector
- detection bounding box, classification
- segmentation fixel 별 classification
RNN : Sequential data
Sequential Model
Text, 음성 그리고 주식차트 같은 것들이 sequence data 이다.
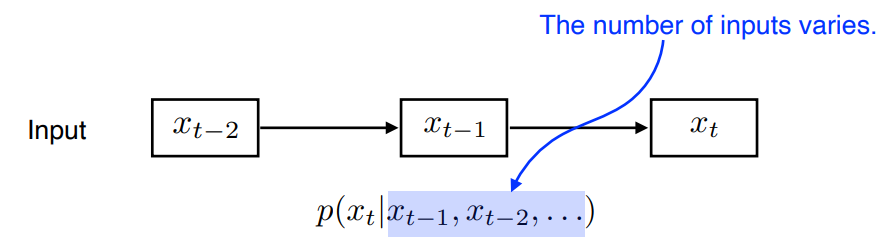
- Sequence data 를 처리하는 데 있어 가장 큰 어려움은 ?
받아들이는 input의 크기를 알 수 없다.
- Input의 shape 을 미리 고정할 수 없다.
Naive sequnce model
Autoregressive model
past time span 을 고정
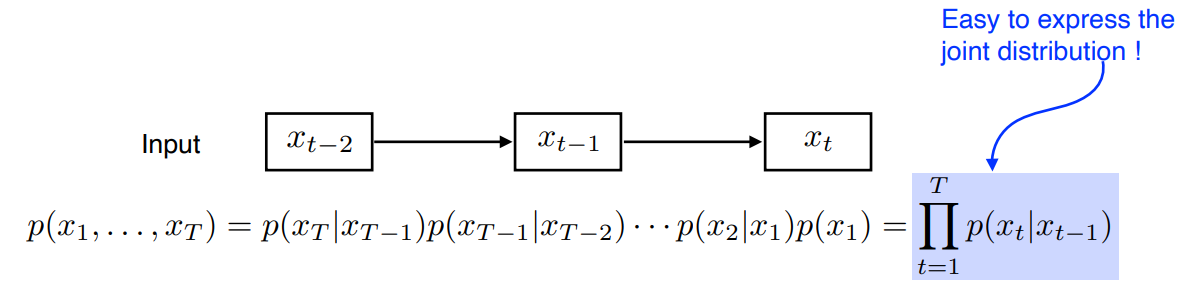
Markov model (first-order autoregressive model)
가정: 현재는직전 과거에만 dependent 한다. ( Markovian assumption )단점: 직전 과거 정보만 고려한다.장점: Joint distribution 이 쉽다.
Latent autoregressive model
중간에 hidden state ( latent state ) 를 넣어서 과거 정보를 요약한다.
다음 번 time step 은 이 hidden state 하나에만 dependent 한다.
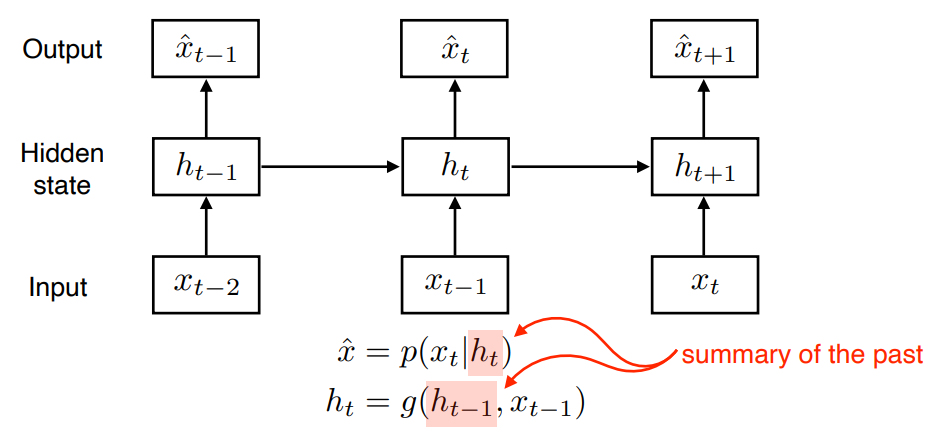
Recurrent Neural Network
Time step 에서 hidden state 는 에만 dependent 하는게 아니라, 이전 cell state 에서 얻어진 어떤 에도 dependent 한다.
단점Short-term dependencies 과거의 정보를 누적하여 취합한다.- 오래된 과거 정보를 취합하기에 부적합하다.
RNN 을 time step 을 fix 하고 시간순으로 풀면
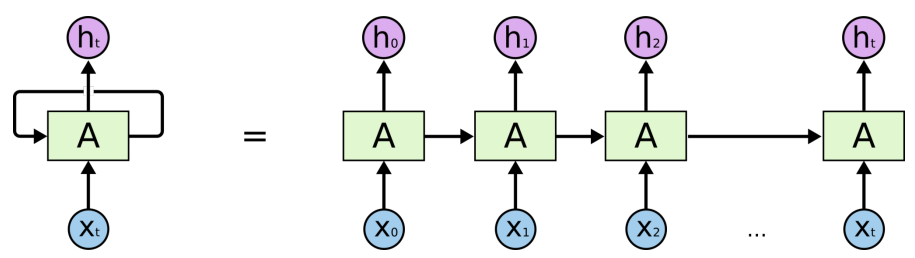
Recurrent model 을 시간 순으로 풀면 입력이 아주 많은 fully connected layer 로 표현될 수 있다.
- 각각의 network 의 parameter 를 share 하는 network 하나가 됨
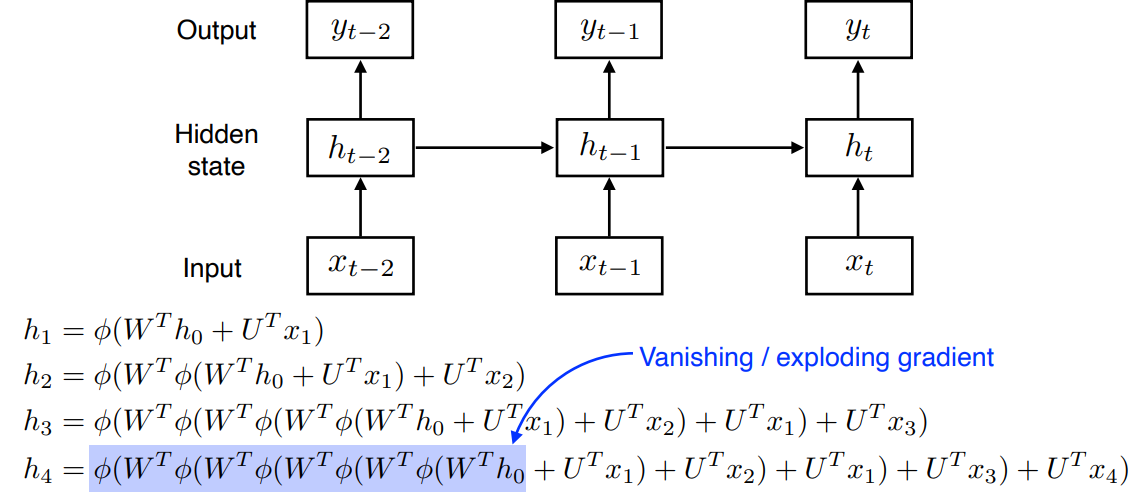
RNN 는 width 가 큰 network 이다.
Vanishing / exploding gradient 문제가 생긴다.
sigmoid: 0 과 1 사이의 값을 가져 layer 가 깊어질수록 정보가 소실vanishing gradientReLU: max(0,x) 이기 때문에 layer 가 깊어질수록 발산하는 문제exploding gradient- RNN 할 때 ReLU 를 잘 사용하지 않는 이유기도 하고, 학습이 어려운 이유기도 하다.
Long Short Term Memory
Vanilla RNN
1 ) 를 network 로 전달한다.
2 ) weight 를 곱한다.
3 ) 이전 cell state 와 연결 ( concatenation ) 한다.
4 ) 다시 network 를 통과한다. ( weight 를 곱한다. )
5 ) non-linear function ( 여기서는 tanh ) 을 거쳐 output 을 낸다.
6 ) 그 output이 다시 입력으로 전달되어 반복된다.
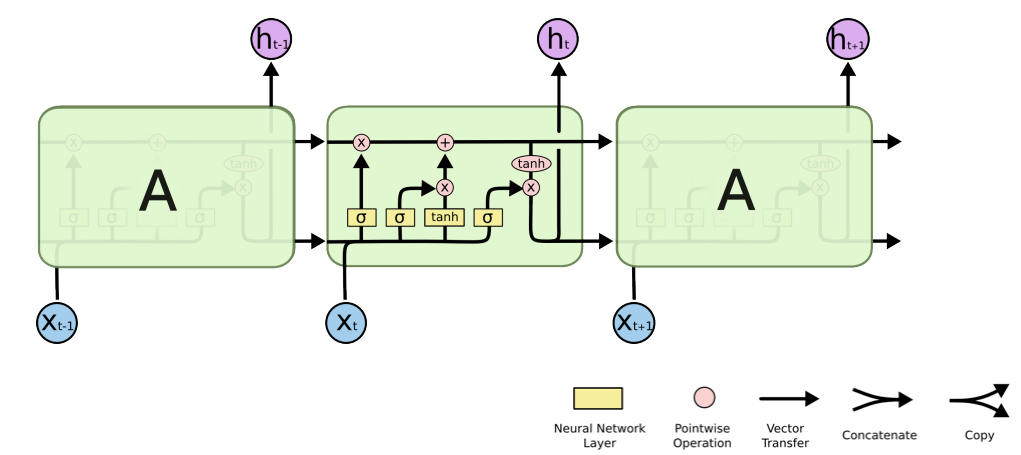
- LSTM 에서 각각의 component 의 역할 알아보기
- LSTM 이 어떻게 Long Term Dependency 를 가져오는지 학습하기
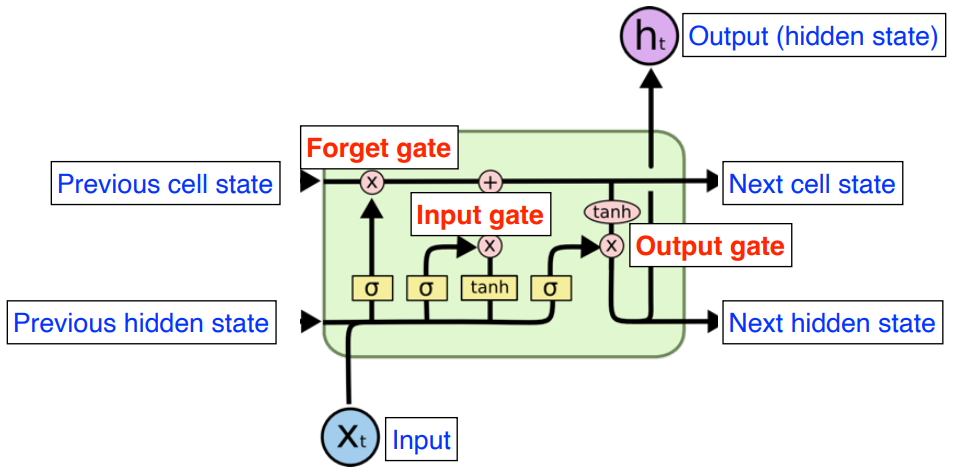
-
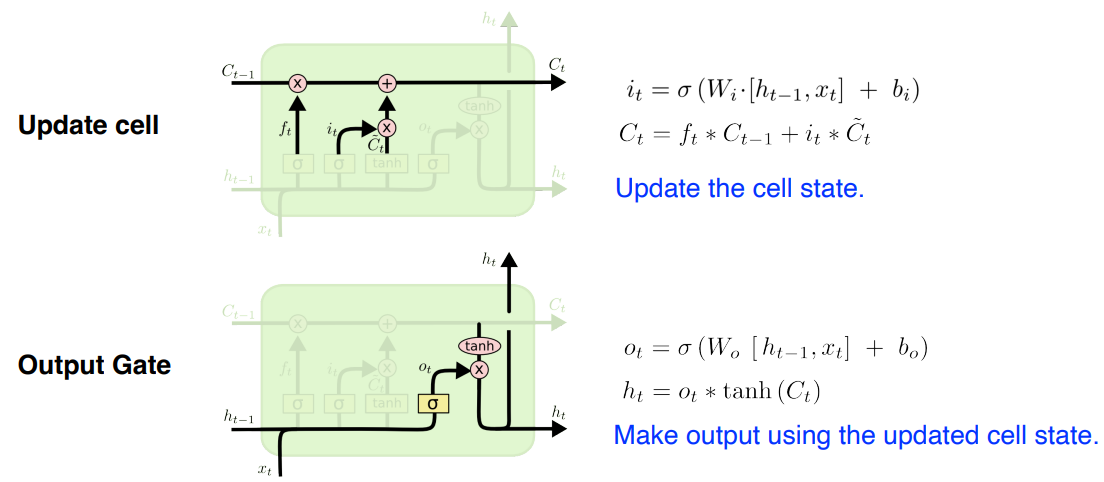
Forget Gate
Activation function 으로 sigmoid 를 사용해 0 과 1 사이 값을 가진다.
이전 cell state 값 중 어떤 것을 버리고 어떤 것을 가져갈지 결정
-
Input Gate
입력 중 어떤 정보를 올릴지 안올릴지를 결정
- previous cell state 와 현재 입력으로 를 만든다.
- Cell state candidate : 현재 정보와 이전 출력값으로 만들어지는 Cell state 후보군
- 이전의 cell state 와 현재 입력이 들어와 다른 Neural network 을 통해서 tanh 를 통과했을 때, 모든 값이 -1 과 1 사이로 정규화 되어 있는 것
- previous cell state 와 현재 입력으로 를 만든다.
-
Update Gate
1 ) ( forget gate 에서 나온 값 ) 만큼 이전 을 곱한다.
2 ) 를 만큼 곱한다.
3 ) 어느 값을 올릴지를 결정한 뒤 두 값을 combine 한다.
4 ) 새로운 cell state 로 올린다.
-
Output Gate
어떤 값을 밖으로 내보낼지를 계산하여 output 으로 도출
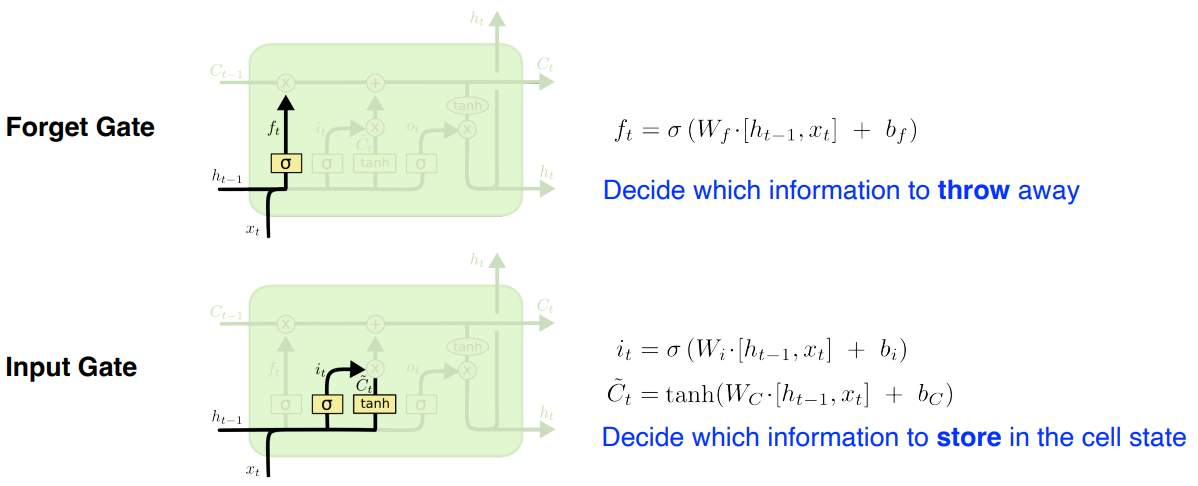
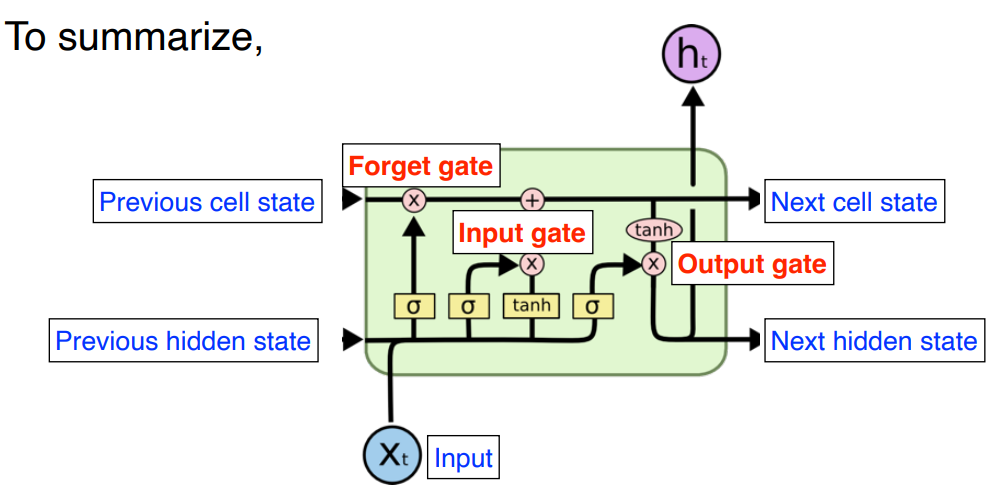
To Summarize ( 22분 )
1 ) Input , previous cell state , previous hidden state 이 neural network 안으로 들어오면
2 ) 이전 cell state 를 얼만큼 지울지 정한다.
3 ) previous cell state , previous hidden state 로 어떤 값을 올릴지 를 정한다.
4 ) update 된 cell state 와 candidate cell state 를 combine 해서 새로운 cell state 를 만든다.
5 ) 정보를 얼만큼 밖으로 빼낼지 정하면 최종적인 출력값이 된다.
Gated Recurrent Unit
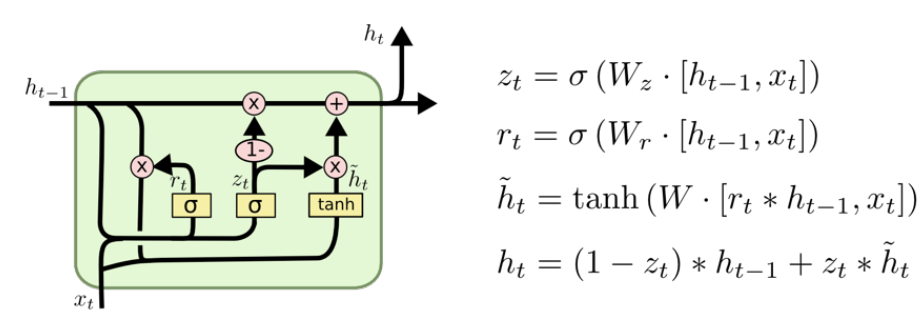
parameter 의 수가 줄어들기 때문에 Generalization Performance 가 좋아진다.
- hidden state 가 곧 output
- cell state 가 없다.
reset gate:=forget gateupdate gate
CHECK
RNN 의 단점
- Long Term Dependency 를 잡지 못함
LSTM 의 단점
- gate 가 3개 필요해서 parameter 의 수가 늘어남
GRU
- LSTM에서 gate 를 하나 줄임
- 대부분의 경우 LSTM 을 쓸 때 보다 성능이 올라감
이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
