8강 Transformer
GOAL
- Sequential model 의 한계점
- Transformer 모델에 대한 학습
- Encoder 와 Multi Head Attention 에 포커싱
- 앞서 소개한 RNN 기반의 모델들이 해결하기 힘든 문제들을 Transformer은 어떻게 다루나요?
- Transformer 의 Query, Key, Value 는 각각 어떤 기능을 하나요? NMT 문제에서의 예시를 구체적으로 생각해보세요.Transformer
Sequential model 이 hard problem 을 다루는 것이 어려운 이유
어떤 sequence 가 있다고 가정해보자.
- 글, 음성, 문장 등
입력 sequence 마다 길이가 달라질 수 있다.
Sequential 한 입력에서 일부 정보가 빠지거나 permutation 되어 뒤섞일 수 있다.
모델링이 어렵다.
이런 문제를 해결하고자 Transformer model 을 사용
- Transformer 에서는 기본적으로
self-attention이라는 구조를 사용함
Transformer 의 구조와 동작을 이해해보자!
Transformer is the first sequence transduction model based entirely on attention.
Transformer 는 attention 에 기반한 첫 번째 sequence transduction model 입니다.
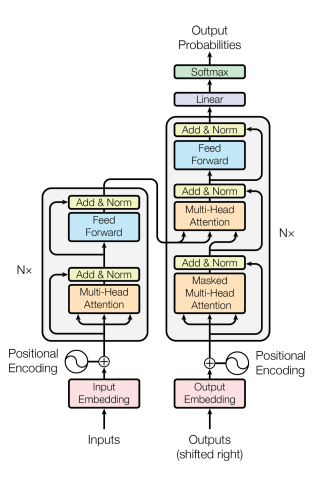
Transformer 논문에서 제시된 '기계어 번역 ( NMT ) 에 Transformer 를 어떻게 적용할까' 를 중심으로 설명
- sequential 한 데이터를 처리하고 encoding 하는 방법론
- 기계어 분석, 이미지 분류, 객체 탐지 등 여러 방면에서 사용가능하다.
모델의 목적
어떤 문장이 주어지면 번역된 문장으로 산출
- 입력 sequence 와 출력 sequence 의 length 가 다를 수 있음
- 입력 sequence 와 출력 sequence 의 domain 이 다를 수 있음
모델의 구조
RNN: n 개의 단어가 들어오면 n 번의 재귀를 돈다.Transformer: n 개의 단어가 들어와도 한 번의 attention 으로 모두 encoding 된다.- generator 에서는 autoregression 방식으로 한 단어씩 출력됨
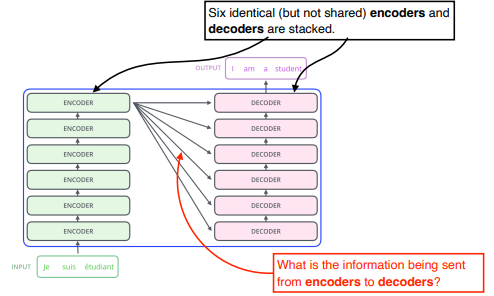
동일한 구조를 갖지만 network parameters 가 다르게 학습되는 encoder 와 decoder 가 stack 되어 있다.
TODO
- n 개의 단어가 encoder 에서 어떻게 한 번에 처리 되는지 이해해보자.
- encoder 와 decoder 사이에 어떤 정보를 주고 받는지 이해해보자.
advanced: decoder 가 어떻게 generation 할 수 있는지 이해해보자.
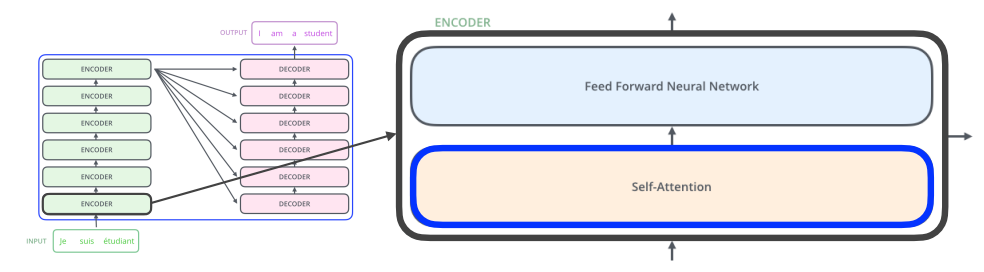
Encoder 가 n 개의 단어를 어떻게 한 번에 처리할 수 있을까?
★ Self-Attention
Encoder 에 n 개의 단어 ( vector ) 를 한 번에 입력으로 넣고, 나온 n 개의 출력값을 다음 Encoder 로 전달한다.
n 개의 단어를 특정 숫자로 표현된 vector 로 표현해서 전달하면 self-attention 이 전달된 vector 와 매칭되는 n 개의 vector 를 찾아준다.
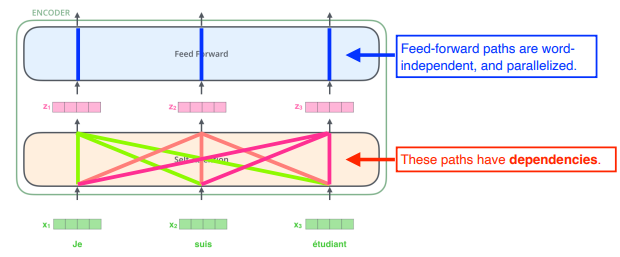
와 매칭되는 를 찾을 때, 개의 다른 단어들을 함께 활용하는 점이 self-attention 의 특이점이다.
참고Feed-forward network 는 다른 단어들과 dependency 가 없다.
문장의 전체 구조 속에서 다른 단어들과의 관계성을 학습한다.

Self-Attention 구조는 세 가지 vector 를 만들어낸다.
- Query
- Key
- Value
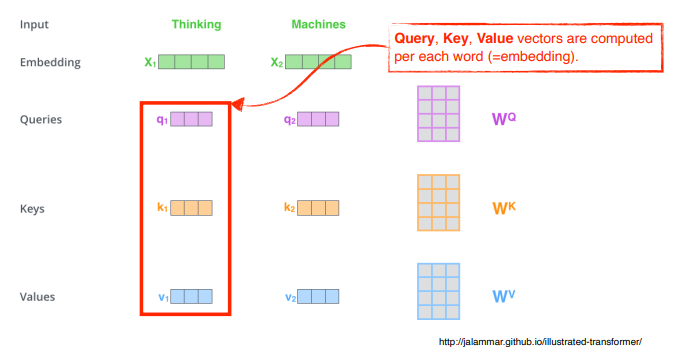
어떻게 각각의 단어 에 해당하는 를 찾을까?
score vector 를 만들어준다.
1 ) 단어 의 query vector 와 나머지 단어들의 key vector 를 내적한다.
- 단어 (
예를들어thinking )를 인코딩하고자 하면- 단어의
query vector와 나머지 모든 개에 대한key vector의 내적으로score vetor를 구한다.- 그 의미는, 두 vector 가 얼마나 잘 align 되어 있는지를 나타낸다.
- 즉, 단어가 나머지 단어가 얼마나 유사도가 있는지, 관계가 있는지 그리고 어떤 단어들과 더 많이 interaction 이 일어나야하는지를 표현한다.
- 단어의
2 ) 계산된 score vector를 8로 나눔으로써 normalize 해준다.
- 8 은 : key vector 의 dimension 에 dependent 한다.
참고key vector 를 몇 차원으로 만들지는 hyper parameter- 예시에서는 dimension 이 64 였고, 64 의 square root 를 구하면 8
- score vector 의 값이 너무 커지지 않고 어떤 range 안에 속하게 하기 위해서 나누어준다.
3 ) interaction 에 대한 값 ( attention weights ) 을 구하기 위해 softmax 연산을 해준다.
- 아래 그림에서 Thinking 은 자기 자신과 0.88의 interaction 을 가지고, 두 번째 단어 Machines 과는 0.12 를 가진다.
4 ) attention weights 를 value vector 와 weighted sum 을 한다.
- Thinking 이라는 단어가 embedding 된 vector의 encoding vector 가 된다.
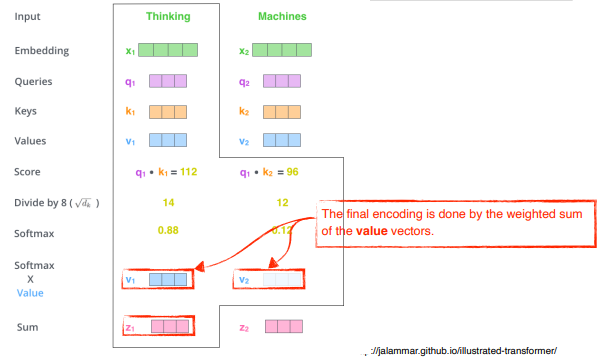
요약하자면
attention weights는 각각의 단어가 다른 단어들 ( 자기 자신 포함 ) 과 얼마나 interaction 해야하는지는 scalar 로 나온다.
이 값이 어떤 값이 될지는 value vector 로 가진다.
최종적으로 구하고자 하는 것은 각 embedding vector 에 대한 encoding vector 로, 각각의 단어의 embedding 에서 나오는 value vector 들의 weighted sum 이 된다.
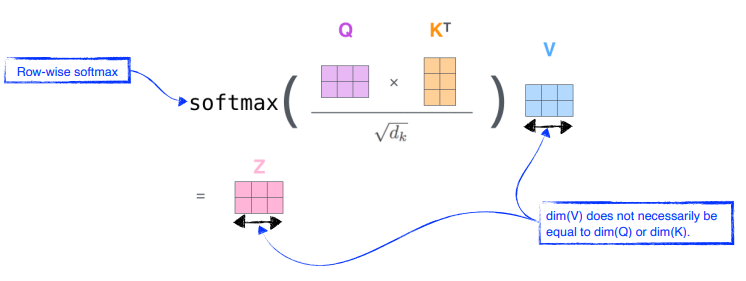
Query vector 와 Key vector 는 항상 차원이 같아야 한다.
- 두 vector 의 내적 값이 필요하기 때문이다.
하지만value vector 는 차원이 달라도 된다.
- value vector 로는 weighted sum 을 하기만 하면 된다.
encoding 된 vector 의 차원은 value vector 의 차원과 동일하다.
참고multi-head attention 으로 가면 달라지겠지만, 이 setting 에서는 그렇다 !
행렬로 표현해보자 - Single Head Attention
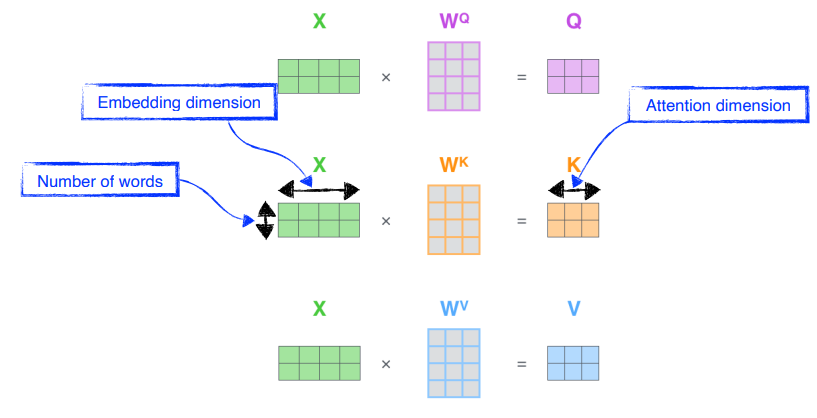
embedding dimension 이 4인 단어 2개와 ,, 를 찾는 Multi Neural Perceptron 이 존재한다고 생각하자.
참고Multi Neural Perceptron 은 encoding 된 단어마다 shared 된다.- 각각 2개의 key vector , value vector , query vector 가 나온다.
summaryquery vector , key vector 를 내적해서 scalar 를 뽑고, 그 값을 squared root key dimension 으로 나눈 후 softmax 연산을 한 다음, value vector 에 대해 weighted sum 을 한다.
embedding vector
참고value vector 의 크기는 key vector 나 query vector 와 달라도 된다. 구현할 때는 편의상 같게도 함
왜 잘 동작할까 ?
먼저 Image data 를 CNN 이나 MLP로 전달한다고 생각해보자.
- Input 이 fix 되어 있으면 output 도 fix 된다.
왜 ?convolution filter 나 weight 값이 고정되기 때문이다.
하지만 Transformer 는 하나의 input 과 network 가 fix 되어 있다고 하더라도 encoding 하려는 단어와 인접한 단어에 따라 encoding 된 값( 출력 값 )이 달라지게 된다.
Multi Neural Perceptron 보다 flexible 하고 feature 표현이 풍부하다.
- 더 많은 computation
- computation bottle neck
- n 개의 단어가 주어지면 n x n attention map 을 만들어야 한다.
- RNN 은 1,000개의 sequence 가 주어지면 1,000번 돌리면 된다.
- Transformer 는 한 번에 연산하기 때문에
더 많은 메모리가 필요하고 한 번에 많은 양의 연산을 해야하는 한계점이 있다.
- computation bottle neck
Multi-head attention ( MHA )
- 앞서 했던
single-head attention을 여러 번 하는 것
하나의 embedding 된 vector 에 대해서 query, key, value 를 n 개 만든다.
n 번의 signle attention 으로 n 개의 encoding 된 vector 를 얻을 수 있다.
입력과 출력의 차원이 같아야 한다.
- embedding 된 dimension 과 self-attention 으로 나오는 encoding vector 가 항상 같은 차원이어야 한다.
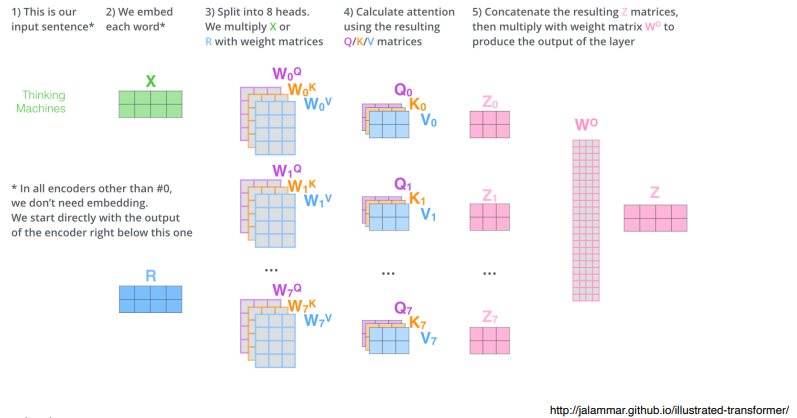
1 ) Input 이 들어오면 각각의 단어를 embedding 한다.
2 ) 8 개 ( n 번 ) 의 self-attention 을 수행한다.
3 ) 8 개의 encoding 된 vector 를 얻는다.
4 ) 원래의 dimension 으로 줄여주는 linear vector 를 찾아서 dimension 을 맞춰준다.
경고( ! )실제로 Multi-head attention 구현을 보면 이렇게 구현되어 있지는 않다.
원래 주어진 것이 100 dimension 이라고 할 때 , 10 개의 header 를 사용한다고 하면 100dim 을 10개로 나누어 query , key , vector 10 dim 을 만든다. 이것을 이용하여 연산한 다음 원래 차원으로 축소해준다. ( code 에서 다시 설명 - 실습참고 )
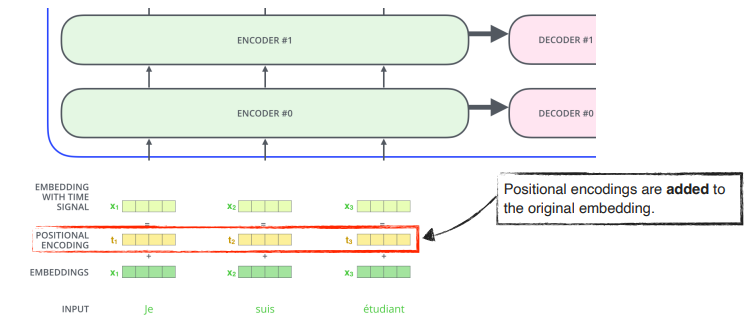
5 ) Positional Encoding ( :=bias ) 과정이 추가된다.
왜 ?: n 개의 단어가 sequenctial 하게 넣어줬을 때, 이 sequential 한 정보가 포함되지 않는다.예를들어( a,b,c,d ) / ( b,c,d,a ) / ( d,a,c,b) 등등과 같은 sequential data 가 있을 때,
각 단어가 encoding 되는 값은 달라지지 않는다.
encoding 값이order independent하다.따라서,주어진 값에다 어떤 값을 더해주어 단어의 위치 정보 ( sequential 정보 ) 를 추가해주고자 함
값에 offset 을 주는 느낌
★ 단어를 encoding 할 때는 나머지 개의 단어를 모두 활용해서 의 단어의 encoding vector 를 찾는다.
6 ) encoding vector z 에 layer normalization 을 한다.
참고layer normalization 이란 ?
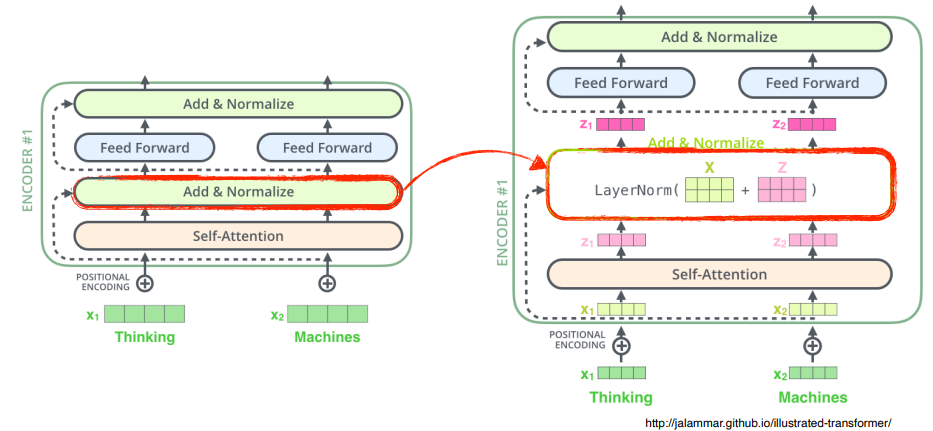
7 ) feed forward ... 반복
- encoder 안은
self-attendion,add & normalization을 거친 다음 feed forward 된다.add & normalization: ResNet 스럽게 Identical connection 을 둔다.- 각각의 z vector들 ( encoding 된 vector 들 ) 에 대해서 독립적으로 동일한 neural network 가 동작하는 것이 반복됨
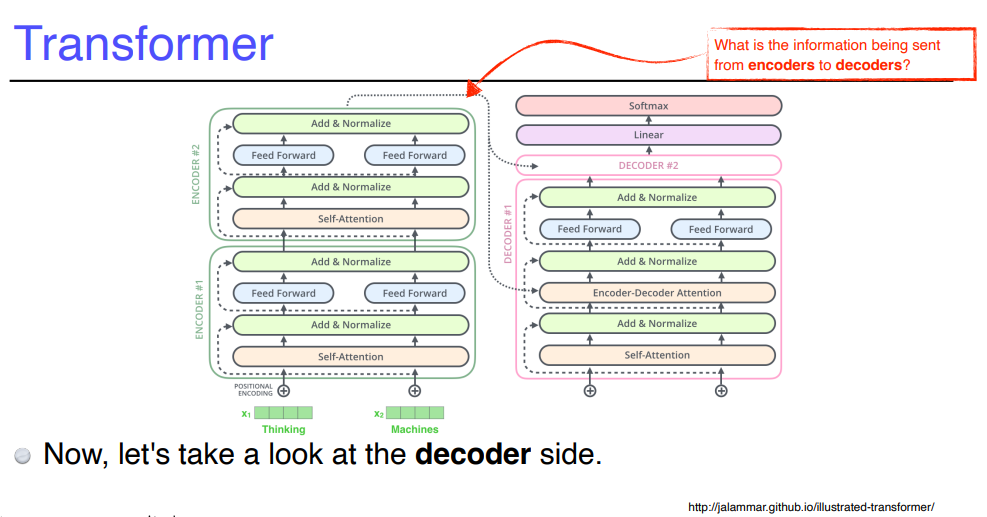
Encoder 에서 Decoder 로 어떤 정보가 전해질까?
정답 : key 와 value
왜 ?
- 단어의 query vector 와 나머지 단어들의 key vector 를 내적해서
attention map을 만든 후 value vector 와 weighted sum 을 한다.- input 의 단어들을 decoder 에 있는 단어들( output 단어 ) 에 대해 attention map 을 만드려면 key 와 value vector 가 필요하다.
가장 상위에 있는 decoder 에서 만들어지는 단어를 생성함
8 ) Decoder 에 주어진 단어들로 만들어진 query vector 와 encoder 에서 얻어지는 key, value vector 가 조합되어 최종 output 이 된다.
참고 - jalammar illustrated-transformer
The output sequence is generated in an auto regressive manner.
참고 학습 단계에서 masking 을 한다.
- 해당 입력의 이전 정보만 활용 ( 미래의 정보는 활용하지 않도록 마스킹 )
In the decoder, the self-attention layer is only allowed to attend to earlier positions in the output sequence which is done by masking future positions before the softmax step.
9 ) 이전까지 generation 된 단어들 ( decoder 의 입력 ) 만 가지고 query 를 만들고, key , value 는 encoder 에서 나온 vector 를 사용 ( MHA )
The “Encoder-Decoder Attention” layer works just like multi-headed selfattention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values from the encoder stack.
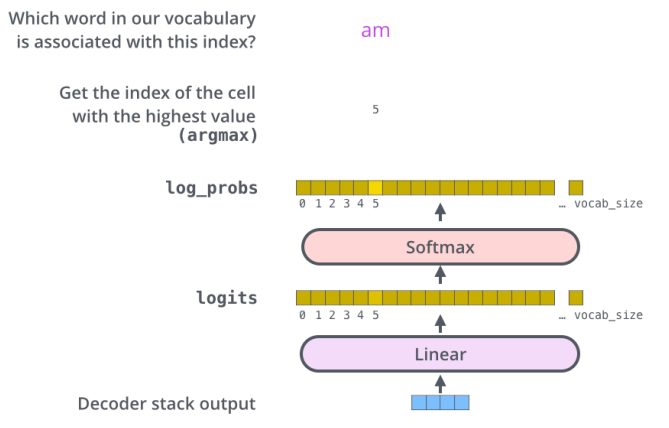
10 ) 단어들의 분포를 만들어서 sampling 하여 output 을 낸다.
The final layer converts the stack of decoder outputs to the distribution over words.
CV 에서 사용되는 Transformer
Transformer 모델은 단순히 단어들의 sequence 를 변환하는 NLP 문제 뿐만 아니라 이미지 데이터 등 다양한 분야에 활용되고 있다.
1 ) 이미지를 특정 영역으로 나눈다.
2 ) 각 영역의 sub-feature 들을 추출
3 ) linear layer 통과
4 ) position layer
- DETR
- ViT ( image 분류 )
- encoder 만 활용
- encoder 에서 나오는 첫 번째 encoded vector 를 classify 에 넣는다.
- DALL-E
- decoder 만 활용
- 특정 grid 로 나누어 sequence 로 전달, 문장도 단어들의 sequence 로 전달
- 조합하여 문장에 대한 이미지를 만들 수 있음
- GPT-3 활용
퀴즈 : 주어진 단어의 representation 을 구해보자.

이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
