6강 Recommender System with Deep Learning 1
가장 대표적인 딥러닝 모델들을 추천 시스템에 적용한 논문을 살펴보자.
- 어떤 특징이 추천 시스템에 활용되는지 고민해보기
GOAL
- Multi Neural Perceptron 과 AutoEncoder 기반 추천 시스템 모델 소개
MLP 기반 추천 시스템 모델 및 논문 소개
- Neural Collaborative Filtering (NCF)
- Neural Matrix Factorization(NMF)
- NCF 와 Matrix Factorization(MF) 통합
- Youtube Recommendation System 논문 리뷰
- MLP 기반 추천 시스템 모델 활용
AutoEncoder 기반 추천 시스템 모델 소개
- AutoRec 과 DAE 를 사용한 Collaborative Denoising Auto-Encoders(CDAE)
추천 시스템과 딥러닝
딥러닝은 두 가지 문제로 추천 시스템에 적용되기 어렵다.
- 월등히 좋은 성능을 내지 않는다.
- 모델 서빙 latency 가 중요하기 때문에 실제로 복잡한 모델을 사용하기는 어렵다.
그렇다면
- 왜 딥러닝을 사용하는지
- 딥러닝을 통해 추천 시스템을
어떻게고도화할 수 있는지
살펴보자.
장점 : Non-Linear Transformation , Representation Learning , Sequence Modeling , Flexibility
storyembedding layer 와 convolution layer 가 결합되어 복잡한 feature 를 적절한 representation 을 표현한다는 장점이 있다.
Non-Linear Transformation
Matrix Factorization 등에서 사용되는 선형 결합이 가지는 문제점
- 모델을 너무 단순하게 만든다.
- 모델이 가지는 표현력에 한계를 둔다.
DNN을 사용했을 때 이점
전통 추천 모델이 표현할 수 없는 복잡한 user-item interaction pattern 학습
Representation
데이터로부터 feature representation 을 학습하기 때문에, 직접 feature design 을 하지 않아도 된다.
- 텍스트, 이미지, 오디오 등 다양한 종류의 정보를 사용할 수 있다.
Sequence Modeling
- RNN, CNN, Transformer 같은 모델을 활용하여 sequential modeling task 에 성공적으로 적용된다.
- user / item 의 시간에 대한 정보를 학습
Flexibility
다양한 DL 프레임워크를 통해 효율적인 서빙이 가능하다.
Recommender System with MLP
여러 개의 node 로 구성된 layer 를 순차적으로 쌓은 feed-forward neural network 를 이용하면 Deep Learning 이 가진 가장 기본적인 non-linear model 을 풀 수 있다.
Neural Collaborative Filtering
Neural Collaborative Filtering 논문 - MF 한계 지적, 신경망 기반 구조 사용
Matrix Factorization
Matrix factorization 은 user 와 item embedding 의 선형 조합(linear combinartion) 을 구한다.
- user 와 item 사이의 embedding 을 구해 선형 연산 ( dot product ) 를 한다.
복잡한 관계를 표현하는 데에 한계가 있다.
한계점
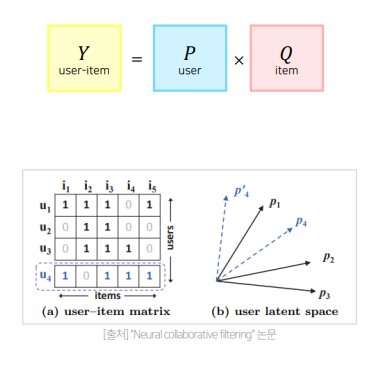
예를 들어 기존 user-item matrix 로 표현된 user latent space 가 있다고 하자.
이 때, 새로운 user 4가 입력으로 주어졌을 때, user 4 는 user 1 과 가깝게 놓인다.
그러면, user 4 와 두 번째로 유사한 user 는 user 3 임에도 불구하고 user 2 와 더 가까워진다. 모순
- 차원을 늘리는 방법으로 해결할 수 없을까요?
- 차원을 확장해나가면 overfitting 의 위험이 있다.
모델 구성
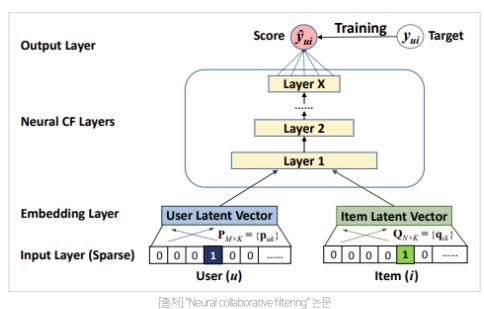
- Input Layer
- one-hot encoding 된 user(item) vector :
- Embedding Layer
- user latent vector ( embedding matrix ) 를 통해 각각의 user 와 item 이 dense 한 형태의 embedding 으로 표현된다.
- Neural CF Layers
- FFNN 형태로 x 개의 layer 가 쌓인다.
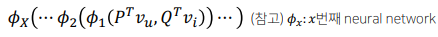
- FFNN 형태로 x 개의 layer 가 쌓인다.
- Output Layer
user 와 item 사이의 관련도를 추론- activation function 으로 logistic , probit 함수를 사용하여 output 값을 [0,1]로 제한
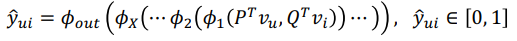
- activation function 으로 logistic , probit 함수를 사용하여 output 값을 [0,1]로 제한
최종 모델
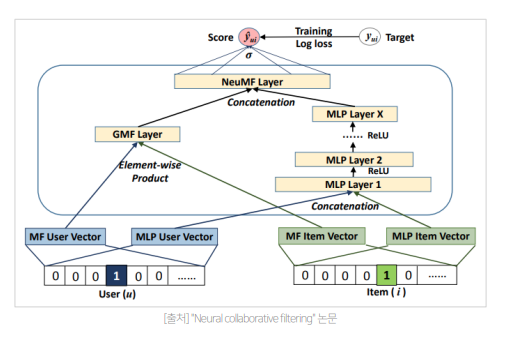
General Matrix Factorization 과 MLP 를 ensemble 하여 사용
- GMF 와 MLP 가 서로 다른 embedding layer 를 사용한 것이 특징
- 두 값을 concatenation 하여 sigmoid function 을 이용해 값 계산
결과
Matrix Factorization 의 한계를 지적하고 Deep Learning Model 을 활용하여 개선을 시도한 점에서 의미가 있다.
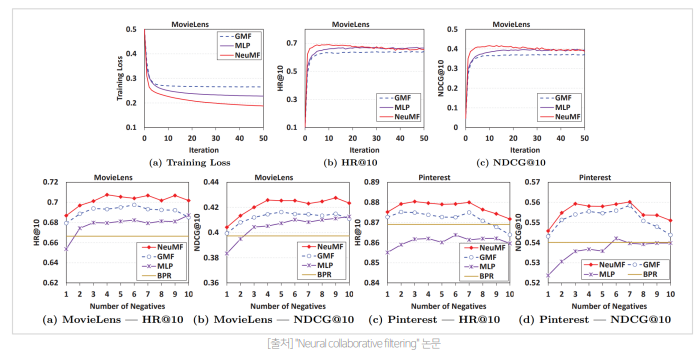
YouTube Recommendation
★Deep Neural Networks for YouTube Recommendations
- 읽어보길 추천해요 !
Candidate GenerationDeep Learning 기반의 2단계 추천을 처음으로 제안Candidate Generation모델을 가지고 어떻게 서빙해야 현업에서 사용할 수 있을지까지 제시Candidate Generation기본적인 CF 아이디어 활용 + user_id 외 다양한 feature 들을 사용하여 더 정확한 Top N 아이템 생성Candidate Generation아이템의 최신성을 반영하기 위해Example Age사용Rankinglogistic regression 이나 Tree model 보다 뛰어난 성능
다양한 feature 들을 사용하여 마지막 layer 에서 concat , MLP layer 로 예측RankingExpected Watch Time 을 예측
도전 과제 : Scale, Freshness , Noise
- Scale
많은 user 와 item 이 있지만 computing power 는 제한적이기 때문에 효율적인 서빙, 학습이 중요 - Freshness
잘 학습된 컨텐츠와 새로 업로드된 컨텐츠를 실시간으로 적절히 조합해야 한다.
- 과거의 인기 동영상만 계속 추천되고 새로운 동영상은 추천되지 않으면 안된다. - Noise
높은 Sparsity, 다양한 외부 요인으로 유저의 행동을 예측하기 어렵다. noise 가 높은 상황에서도 잘 동작해야한다.
Implicit Feedback, 낮은 품질의 메타데이터를 잘 활용해야 한다.
- 리뷰, 좋아요 같은 explicit feedback 과 함께 클릭 수 , 시청 시간 같은 explicit feedback 도 활용해야 함
전체 구조 : Candidate Generation, Ranking
추천 시스템이 추구하는 목표를 두 가지로 나누어 구성
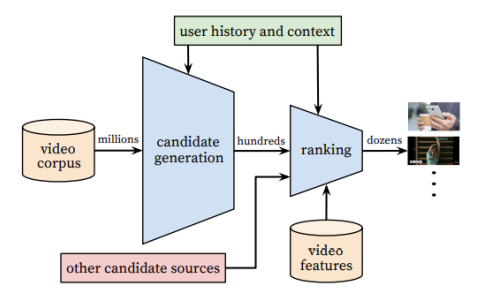
- Candidate Generation
High Recall ( 유저가 선호하는 아이템 대비 추천 아이템 ) 을 목표
주어진 사용자에 대해 Top N 추천 아이템 생성
- 수백 개의 아이템을 추천 - Ranking
유저, 비디어 피쳐를 더 풍부하게 사용하여 스코어를 구하고 최종 추천 리스트 제공
- 수십 개의 아이템 추천
Candidate Generation - 문제정의
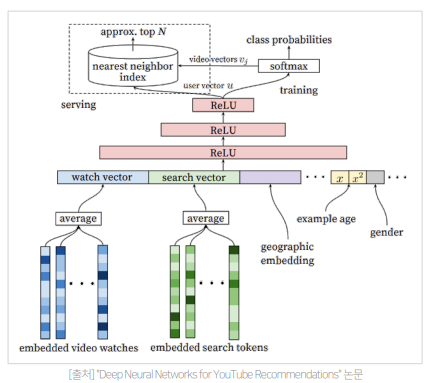
문제점
주어진 유저와 수백만 개의 비디오에 대해 연산이 필요하다.
Watch Vector and Search Vector 를 이용
Candidate Generation - 모델
각 user 의 행동 벡터( watch, search )들을 embedding 해서 평균을 낸 watch vector 와 search vector 로 예측한다.
- 마지막 검색이 너무 큰 힘을 갖지 않도록 평균을 구함
Demographic & Geographic features
'Example Age' feature
모델이 과거 데이터 위주로 편향되어 학습되지 않도록 시청 로그가 학습 시점으로부터 얼마나 경과되었는지에 대한 정보를 피쳐로 표현한다.
- Bootstraping 현상 방지 및 Freshness 제고
1 ) 다양한 feature vector 들을 한 번에 concatenate
2 ) n 개의 dense layer(Feed Forward Neural Networ) 를 거쳐 User Vector 생성
3 ) 최종 output layer 는 비디오를 분류하는 softmax function
- 고양이에 관련된 비디오를 많이 본다면 고양이 관련 영상이 추천
Candidate Generation - Serving
수백만 개의 비디오 중 수백 개의 비디오를 추출하는 모델을 어떻게 서빙할까 ?
Challenge
유저를 input 으로 하여 상위 N 개 비디오를 추출한다.
- 수백만 개의 비디오에 대해 모두 softmax probability 를 계산하여 prob 이 높은 비디오 N 개를 추출한다.
주어진 수백만 개의 벡터와 모두 내적해야 한다.
시간이 오래 걸려 실시간 서빙이 어렵다.
Suppose
Annoy, Faiss 같은 주어진 vector 와 가장 유사한 것을 찾는 ANN 라이브러리를 이용해 빠르게 서빙한다.
- 정확한 softmax 값을 계산하는 것이 아닌 최대한 유사한 item vector 를 찾는 것
Ranking - 문제 정의
user , item , context 에 대해 어떤 item 이 주어졌을 때, 클릭할 확률을 구하는 문제
Candidate Generatioon 단계에서 생성한 비디오 후보들을 input 으로 하여 최종 추천될 비디오들의 순위를 매기는 문제
- Logistic 회귀를 사용하는 기본적인 방법을 사용한다.
- 딥러닝 모델로 user, video feature 들을 풍부하게 사용하여 정확한 랭킹 스코어를 구한다.
- weighted logistic : loss function 에 시청 시간을 가중치로 한 값을 반영한다.
Ranking - 모델
input 으로 user actions feature 사용
- user 가 특정 채널에서 얼마나 많은 영상을 봤는지
- user 가 특정 토픽의 동영상을 본지 얼마나 지났는ㄴ지
- 영상의 과거 시청 여부 등을 입력
많은 Feature Selection / Engineering 필요
서비스에 맞는 feature 를 잘 찾아서 ranking model 을 구성하는 것이 중요하다.
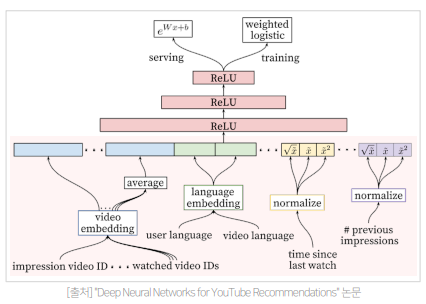
input feature 들이 마지막 layer 에서 합쳐지고, network 를 통과하면
비디오가 실제로 시청될 확률로 매핑된다.
Loss function 으로는 weighted cross-entropy loss 를 사용하여 비디오 시청 시간으로 가중치를 준다.
- 클릭은 했지만 시청시간이 적은 낚시성 / 광고성 콘텐츠의 학습 반영률을 낮춘다.
Recommender System With AE
Input Data 를 똑같이 복원한 Output data 를 생성 ( unsupervised learning )
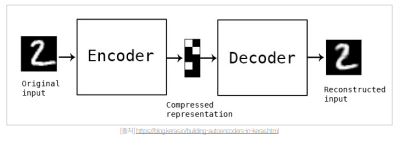
AutoEncoder ( AE )
주어진 Input 과 추론된 reconstruct Input 과의 차이를 최대한 줄이는 방법을 사용한다.
- 중간 hidden layer 를 input data 의 feature representation 으로 활용
- Anomaly Detection, Representation Learning , Image Denoising Task
- Encoder : Compressed representation
- Decoder : Reconstructed input
Denoising AutoEncoder
입력 데이터에 random noise 나 dropout 을 추가하여 학습
- noise 를 더 잘 복원할 수 있는 robust 한 모델이 학습되어 성능이 향상됨
- noise 가 없는 original input 으로 복원될 수 있도록 학습을 구성
overfitting 위험을 줄여 generalizatoin 성능을 높임
AutoRec : Autoencoders Meet Collaborative Filtering
- user 와 item vector 를 더 잘 표현하였고 복잡도는 낮춘 논문
AutoRec - Idea
Rating Vector 가 AutoEncoder 의 입력과 출력
- user 또는 item vector 를 저차원의 latent feature 로 나타내 이것으로 평점 예측
- Autoencoder 의 representation learning 을 user 와 item 에 적용
반면, MF: linear, low-order interaction 으로 인해 복잡한 interaction 표현에 한계가 있다.
AutoRec - 학습
RMSE : 기존 rating 과 reconstructed rating 의 차이를 최소화하는 방향
관측된 데이터에 대해서만 역전파 및 파라미터 업데이트

복원 data 인 와 실제 평점의 차이를 최소화한다.
- 학습
- : recondstructed rating
- : encoder function
- : decoder matrix
- : 중간 representation
- : bias
AutoRec - 결과
hidden unit 의 개수가 많아질수록 RMSE 가 감소
- hidden unit 의 개수 : 중간 node 의 개수 ( 몇 차원으로 embedding 할지 )
Denoising Auto Encoder ( 노이즈 제거 ), Variational Auto Encoder ( 노이즈 추가 ) 같은 연구들로 이어짐
CDAE
- Collaborative Denoising Auto-Encoders for Top-N Recommender Systems
Denoising AutoEncoder 를 CF 에 적용하여 top-N 개 추천
CDAE - 특징
AutoRec : Rating Prediction
- RMSE : 얼마나 잘 복원했는지 평가
CDAE: Ranking 을 통해 Top-N 추천 제공 - NDCG : Top-N 추천을 얼마나 잘 제공했는지 평가
개별 유저에 대해 아이템의 preference를 학습
- 유저-아이템 상호 작용 정보를 0 또는 1로 바꿔서 학습 데이터로 사용
CDAE - 문제 정의 및 모델
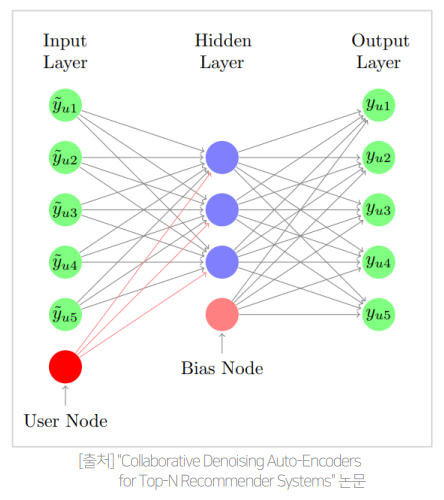
AutoRec 과 다르게 DAE 를 사용하여 noise 추가

- 의 확률로 기존 평가값 에 가 곱해짐
개별 유저에 대해 를 학습 ( Collaborative )
- user 에 따른 특징을 해당 parameter 가 학습하고 Top N 추천에 사용
- 각 user 별 특징을 parameter 로 학습
Encoder : latent representation
Decoder : regenerate

AutoRec 과 차이점
- DAE 를 활용하여 Input 에 noise 추가
- 각 user 에 대한 parameter 를 추가하여 유저 별 특징을 학습
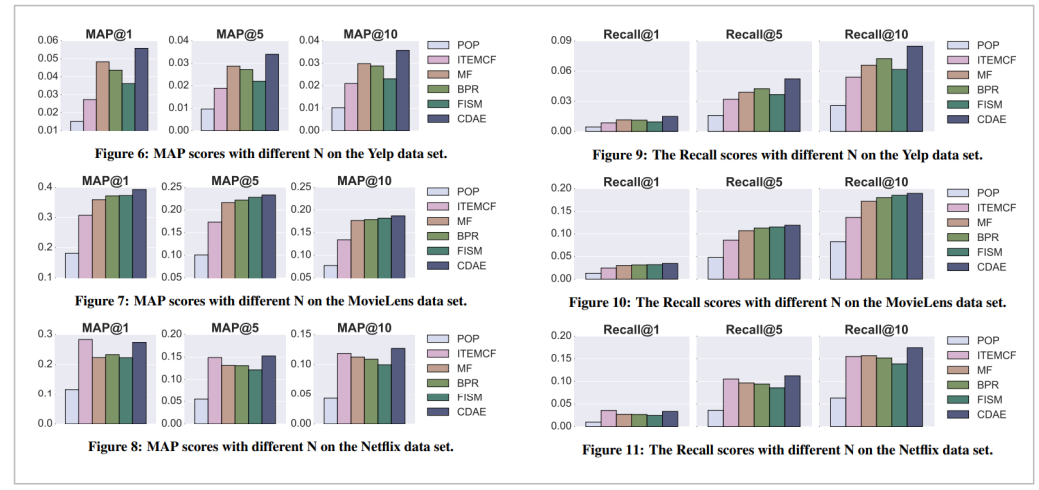
CDAE - 결과
대체적으로 다른 top-N 추천 모델에 비해 더 높은 MAP 과 Recall
★Auto Encoder 를 활용한 모델이 어떻게 user-item embedding vector 학습에 활용되는지를 배우자!★
이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
