
GOAL
- Alternative Least Square ( ALS ) 방식으로 Matrix Factorization 모델의 parameters update
user,item 의 latent vector 를 번갈아 가면서 least-square 문제를 품 ( 파라미터 업데이트 )
- 업데이트 대상이 아닌 것은 고정
Preference 와 Confidence 정보를 사용
Implicit Feedback 추론에 사용목적함수
solution
- 를 번갈아 가면서 고정
2차식 형태로 해가 자명해짐
- numpy.diag 문서
- 대각선 배열을 가져온다.
import numpy as np
a = np.array([1,2,3,4])
np.diag(a)
"""
array([[1, 0, 0, 0],
[0, 2, 0, 0],
[0, 0, 3, 0],
[0, 0, 0, 4]])
"""ALS 함수 구현
- Preference , Confidence 정보 사용
def als(
F : np.ndarray,
P : np.ndarray,
Q : np.ndarray,
C : np.ndarray,
K : int,
regularization : float
) -> None :
"""
ALS :
1. 모든 유저에 대해 유저의 잠재 요인 행렬 p_u 를 업데이트
2. 모든 아이템에 대해 아이템의 잠재 요인 행렬 q_i 를 업데이트
:param F: (np.ndarray) user-item preference matrix. shape: ( 유저 수, 아이템 수)
:param P: (np.ndarray) user 의 잠재 요인 행렬. shape: ( 유저 수, 잠재 요인 수 )
:param Q: (np.ndarray) 아이템의 잠재 요인 행렬. shape: ( 아이템 수, 잠재 요인 수)
:param C: (np.ndarray) 평점 테이블에 Confidence Level 을 적용한 행렬. shape: (유저 수, 아이템 수 )
:param K: (int) 잠재 요인 수
:param regularization: (float) l2 정규화 파라미터
:return None
"""
for user_id , F_user in enumerate(F):
C_u = np.diag(C[user_id])
P[user_id] = np.linalg.solve( ( ( (Q.T @ C_u) @ Q ) + regularization * torch.eye(K) ) , (Q.T @ C_u) @ F[user_id] )
for item_id , F_item in enumerate(F.T):
C_i = np.diag(C[:,item_id])
Q[item_id] = np.linalg.solve( ( ( (P.T @ C_i) @ P ) + regularization * torch.eye(K) ) , (P.T @ C_i) @ F[item_id] )
ALS 의 Loss Function 을 계산하는 함수 구현
-
( 주의 ) 실제 평가된 데이터에 대해서만 RMSE 계산
-
- stackoverflow Difference between nonzero(a), where(a) and argwhere(a). When to use which?
- where 방식은 boolean mask 를 사용해서 nonzero 보다 부하가 클 수 있음
- predict_error :
- confiduence_error :
- regularization_term for :
- regularization_term for :
def get_ALS_loss(
F: np.ndarray,
P: np.ndarray,
Q: np.ndarray,
C: np.ndarray,
regularizatoin: float
) -> float:
"""
전체 학습데이터( 중에서 실제 평가된 데이터 ) 에 대한 ALS 의 Loss 계산
:param F: (np.ndarray) 유저-아이템 preference 매트릭스. shape: (유저 수, 아이템 수)
:param P: (np.ndarray) 유저의 잠재 요인 행렬. shape: (유저 수, 잠재 요인 수)
:param Q: (np.ndarray) 아이템의 잠재 요인 행렬. shape: (아이템 수, 잠재 요인 수)
:param C: (np.ndarray) 평점 테이블에 Confidence Level을 적용한 행렬. shape: (유저 수, 아이템 수)
:param regularization: (float) l2 정규화 파라미터
:return: (float) 전체 학습 데이터에 대한 Loss
"""
user_index, item_index = F.nonzero()
loss = 0
for user_id, item_id in zip(user_index, item_index):
predict_error = (F[user_id, item_id] - P[user_id].T @ Q[item_id] )**2
confidence_error = C[user_id,item_id] * predict_error
loss += confidence_error
for user_id in range(F.shape[0]):
regularization_term = regularization * np.square(np.linalg.norm(P[user_id]))
loss += regularization_term
for item_id in range(F.shape[1]):
regularization_term = regularization * np.square(np.linalg.norm(Q[item_id]))
loss += regularization_term
return lossALS 기반 MF 구현
ALS 로 parameter 를 update 하는 matrix factorization 구현
class MF_ALS(object):
def __init__(self, F, K, C, regularizatoin, epochs, verbose=False):
self.F = F
self.num_users, self.num_items = F.shape
self.K = K
self.C = C
self.regularizatoin = regularization
self.epochs = epochs
self.verbose = verbose
self.training_process = list()
def train(self):
# user, item 잠재 요인 행렬 초기화
self.P = np.random.normal(scale=1. / self.K, size = (self.num_users, self.K))
self.Q = np.random.normal(scale=1. / self.K, size = (self.num_items, self.K))
for epoch in range(1, self.epochs + 1 ) :
als(self.F, self.P, self.Q, self.C, self.L, self.regularization)
loss = get_ALS_loss(self.F, self.P, self.Q, self.C, self.regularization)
self.training_process.append((epoch,loss))
if slef.verbose and ( epoch % 10 == 10):
print("epoch: %d, error = %.4f"% ( epoch,loss))
self.training_process = pd.DataFrame(self.trainig_process, columns = ['epoch','rmse'])
def get_predicted_full_matrix(self):
return get_predicted_full_matrix(self.P, self.Q)참고 - get_predicted_full_matrix
- 유저와 아이템의 잠재요인행렬
- 글로벌, 유저, 아이템 에 대한 bias
- bias 가 없을 때
- bias가 있을 때
- bias 가 없을 때
참고 np.newaxis
k = np.array([1,2,3,4])
k[np.newaxis,:] # array([[1, 2, 3, 4]])
k[:,np.newaxis]
"""
array([[1],
[2],
[3],
[4]])
"""
t = array([[1],
[2],
[3],
[4]])
t[np.newaxis,:]
"""
array([[[1],
[2],
[3],
[4]]]
')
"""
t[:,np.newaxis]
"""
array([[[1]],
[[2]],
[[3]],
[[4]]])
"""
def get_predicted_full_matrix(
P: np.ndarray,
Q: np.ndarray,
b: float = None,
b_u: np.ndarray = None,
b_i: np.ndarray = None
) -> np.ndarray:
"""
유저와 아이템의 잠재 요인 행렬과 글로벌, 유저, 아이템 bias를 활용하여 예측된 유저-아이템 rating 매트릭스를 구하라.
:param P: (np.ndarray) 유저의 잠재 요인 행렬. shape: (유저 수, 잠재 요인 수)
:param Q: (np.ndarray) 아이템의 잠재 요인 행렬. shape: (아이템 수, 잠재 요인 수)
:param b: (float) 글로벌 bias
:param b_u: (np.ndarray) 유저별 bias
:param b_i: (np.ndarray) 아이템별 bias
:return: (np.ndarray) 예측된 유저-아이템 rating 매트릭스. shape: (유저 수, 아이템 수)
"""
if b is None:
return P.dot(Q.T)
else:
return P.dot(Q.T) + b_i[np.newaxis, :] + b_u[:,np.newaxis] + bTODO
ALS 기반 MF 모델 실습
user_item_matrix = ratings_df.pivot_table('rating', 'userId', 'movieId').fillna(0)
user_num = int(user_item_matrix.shape[0] / 10)
movie_num = int(user_item_matrix.shape[1] / 10)
preference_matrix = np.copy(user_item_matrix.iloc[:user_num,:movie_num])
preference_matrix[preference_matrix > 0] = 1신뢰도 행렬 , 잠재 요인 수, l2 정규화 파라미터 설정
# 신뢰도 행렬 (C)
alpha = 40
C = 1 + alpha * np.copy(preference_matrix)
# 잠재 요인 수
K = 200
# l2 정규화 파라미터
regularization = 40
# 총 epoch 수
epochs = 500
# 학습 과정의 status print 옵션
verbose = True모델 학습
mf_als = MF_ALS(preference_matrix, K, C, regularization, epochs, verbose)
mf_als.train()
train_result_df = mf_als.training_process
x = train_result_df.epoch.values
y = train_result_df.rmse.values
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("ALS Loss")
plt.grid(axis="y")
plt.show()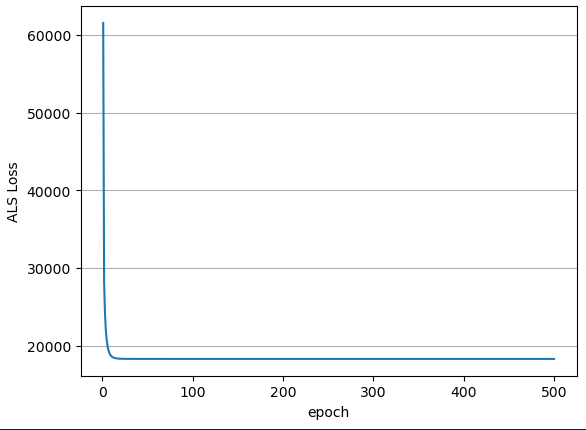
predicted_user_item_preference = pd.DataFrame(mf_als.get_predicted_full_matrix(), columns=user_item_matrix.iloc[:user_num,:movie_num].columns, index=user_item_matrix.iloc[:user_num,:movie_num].index)
predicted_user_item_preference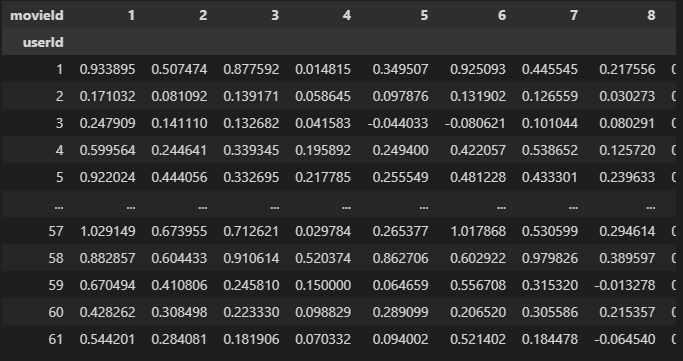
이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
