실습 - Recurrent Neural Networks
GOAL
- LSTM( Long short-term memory ) 를 사용한 MNIST classification
- LSTM 의 입력 형태 알아보기
- x sequence 외의 initialize 형태 알아보기
- 결과값으로 나오는 구조체가 어떤 차원형태를 가지고 있는지 학습
MORE
- LSTM 의 cell state dimension 과 output dimension 은 서로 같아야 한다. ( := 입력과 똑같은 dimension, 코드에서는 hdim ( hidden dimension ) 으로 표기 )
- initial cell state , initial output , input 이 모여 network 를 거쳐 hidden output 을 낸다.
- hidden output 이 과 initial cell state 가 다시 network 로 feed
- RNN 은 parameter 의 수가 많은 편
: 각 gate function 마다 hidden x hidden 개의 parameter 를 가지기 때문이다.
Hidden dimension 의 수를 줄여야 parameter 의 수를 줄일 수 있다.
Define Model
- N : number of batches
- L : sequence length
- Q : input dim
- K : number of layers
- D : LSTM Dimension
Y, (hn, cn) = LSTM(X)
- X : [N x L x Q] - N inputsequnce of lenght L with Q dim.
- Y : [N x L x D] - N output sequence of length L with D feature dim.
- hn : [K x N x D] - K (per each layer) of N final hidden state with D feature dim.
- cn : [K x N x D] - K (per each layer) of N final hidden state with D cell dim
: hidden state
: cell state
참고 hidden state 와 cell state의 shape 이 같다.
-
n_layer : LSTM 을 몇 개 쌓을지
-
x.size(0) : x의 sequence 길이
-
self.hidm : LSTM 의 hidden dim
-
rnn_out : [N x L x D]
- N : 몇 개의 batch 가 들어올지
- L : sequence 의 길이
- D : hidden state 의 dimension
-
rnn_out[:,-1,:] : sequence 의 마지막 cell state를 가져온다.
class RecurrentNeuralNetworkClass(nn.Module):
def __init__(self, name='rnn', xdim=28, hdim=256, ydim=10, n_layer=3):
super(RecurrentNeuralNetworkClass,self).__init__()
self.name = name
self.xdim = xdim
self.hdim = hdim
self.ydim = ydim
self.n_layer = n_layer
self.rnn = nn.LSTM(
input_size = self.xdim,
hidden_size = self.hdim,
num_layers = self.n_layer,
batch_first = True
)
self.lin = nn.Linear(self.hdim, self.ydim)
def forward(self,x):
# Set initial hidden and cell states
h0 = torch.zeros(
self.n_layer, x.size(0), self.hdim
).to(device)
c0 = torch.zeros(
self.n_layer, x.size(0), self.hdim
).to(device)
# RNN
rnn_out, (hn,cn) = self.rnn(x, (h0,c0))
# x : [ N x L x Q ] => rnn_out : [ N x L x D ]
# Linear
out = self.lin(
rnn_out[:,-1,:]
).view([-1,self.ydim])
return out
R = RecurrentNeuralNetworkClass(
name='rnn', xdim=28, hdim=256, ydim=10, n_layer=2).to(device)
loss = nn.CrossEntropyLoss()
optm = optim.Adam(R.parameters(), lr=1e-3)
print ("Done")!pip install torchinfo
import torchinfo
input_size =( 2, 20, 28 )
torchinfo.summary( MyModel, input_size ) 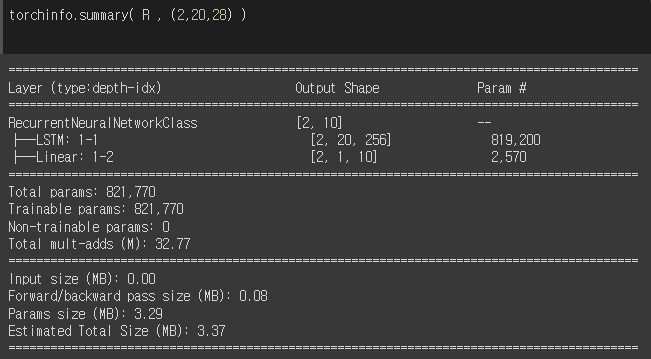
:,-1,: 과 :,-1: 차이 있을까 ? ??
이 글은 커넥트 재단 Naver AI Boost Camp 교육자료를 참고했습니다.
