- 대규모 분산 모델 학습 환경의 노드 장애 탐지 시스템인 Minder의 개요 및 설계의 핵심, 성과에 대해 설명한 자료.
- CPU,DB 기반 서비스 제공을 위한 아키텍처에서 GPU 학습 및 추론을 기반으로 한 서비스로 아키텍처가 변경됨에 따라 장애를 탐지하고 처리하는 방법론 자체도 다시 한 번 고민해봐야함.
- 클러스터로 구성되어 있다 하더라도 클러스터로 구성된 1대의 노드에서 하드웨어 또는 소프트웨어적인 결함이 발생할 경우 레거시 아키텍쳐와는 다르게 심각한 경제적 손실을 야기할 수 있기 때문에 장애 민감도가 더욱 커졌다고 볼 수도 있음.
Minder: Faulty Machine Detection for Large-scale Distributed Model Training
Background & Problem
- 대규모 언어 모델(LLM) 등을 학습할 때는 수천 대의 장비(GPU 등)가 동원되며, 하루 평균 2건 이상의 예기치 않은 하드웨어 및 소프트웨어 결함(장애)이 발생
- 기존에는 작업이 중단된 후 엔지니어가 수동으로 방대한 로그를 분석해야 했기 때문에 진단에 수 시간에서 며칠이 소요되었고, 이는 심각한 자원 낭비와 학습 지연을 초래.
- GPU 노드의 하드웨어 fault로 인해 task가 실패하면 그에 따른 경제적 손실은 매우 큼.
- 예시로, 128대의 머신으로 40분 동안 수행되는 task가 실패할 경우 경제적 손실에 $1700 이상에 달함.
- 따라서, 장애 복구 시간을 단축하는 것이 클러스터 운영의 핵심 지표.
Minder의 핵심 설계 및 작동 원리
7개월간 수집된 실제 운영 데이터를 바탕으로 Real-world Faulty Case Studies를 진행.
주요 결함의 유형과 발생 빈도
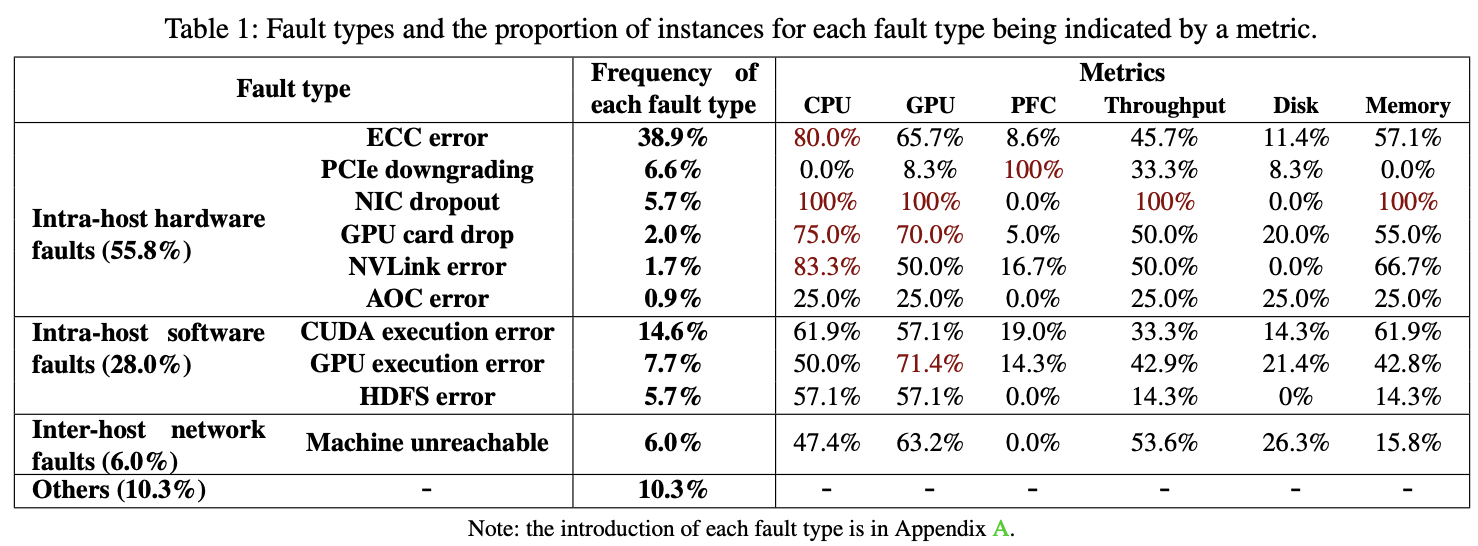
실제 분산 학습 환경에서 기계가 멈추거나 느려지는 원인은 매우 다양했으며, 크게 다음과 같이 분류
- 하드웨어 결함 (55.8%): 전체 결함 중 가장 큰 비중을 차지 특히 메모리 손상 등으로 인한 ECC 에러(38.9%)가 가장 빈번했으며, PCIe 성능 저하(6.6%), NIC 드롭아웃(5.7%) 등이 그 뒤를 이음.
- 내부 소프트웨어 결함 (28.0%): CUDA 실행 에러(14.6%)와 GPU 실행 에러(7.7%) 등 예측하거나 피하기 어려운 프레임워크 및 라이브러리 레벨의 에러가 다수 발생.
- 호스트 간 네트워크 결함 (6.0%): 기계 도달 불가(Machine unreachable)와 같은 통신 장애가 포함
특정 결함의 연쇄 파급 효과 (PCIe 성능 저하 사례)
단일 노드 장애가 전체 작업에 어떤 악영향을 미치는지 확인하기 위해 PCIe 성능 저하(PCIe downgrading) 사례를 분석
- 128대의 기계로 구성된 학습 환경에서 한 기계의 내부 고속 버스인 PCIe 대역폭이 6.4Gbps에서 4Gbps로 저하발생.
- 이로 인해 해당 기계의 네트워크 카드(NIC) 버퍼가 가득 차게 되었고, 병목 현상으로 인해 통신을 일시 정지시키는 PFC(Priority-based Flow Control) 송신 패킷이 결함 기계에서만 비정상적으로 급증
- 결과적으로 전체 클러스터의 네트워크 처리량이 6.5Gbps에서 4.9Gbps로 떨어졌고, 수천 개의 GPU가 동기화를 기다리며 40분 동안 연산 자원 활용도가 급감하는 Cascade effect 발생.
모니터링 지표와의 상관관계
결함을 탐지하기 위해 어떤 지표를 봐야 하는지 분석한 결과, 모든 결함을 완벽하게 지시하는 단 하나의 만능 지표는 없다는 것을 발견했습니다. 각 결함 유형마다 민감하게 반응하는 지표가 다름.
- CPU/GPU 지표가 중요한 경우
- ECC 에러, NIC 드롭아웃, GPU 카드 끊김, NVLink 에러, CUDA/GPU 실행 에러는 CPU 및 GPU 사용량 지표와 강한 상관관계를 보임.
- 결함이 발생한 기계는 연산 프로세스가 죽으면서 사용량이 급감하지만, 정상 기계들은 타임아웃이 발생하기 전까지 연산을 유지하며 기다리기 때문에 뚜렷한 차이가 발생
- 네트워크 지표가 중요한 경우
- PCIe 성능 저하이나 기계 도달 불가 장애는 CPU보다는 PFC 패킷 수치나 네트워크 처리량(Throughput) 지표에서 비정상적인 패턴이 훨씬 뚜렷하게 나타남.
- 예외 상황
- 광케이블(AOC) 결함이나 스위치 문제처럼 발생하는 즉시 여러 기계에 동시에 악영향을 미치는 장애는 특정 기계 하나만의 튀는 패턴을 초 단위 데이터로 캡처하기 어렵다는 한계 확인.
Minder 설계에 미친 영향
- 여러 지표를 하나의 딥러닝 모델에 전부 때려 넣으면, 서로 다른 패턴들 때문에 혼동 발생.
- 따라서 Minder는 모든 데이터를 통합하는 대신, 각 모니터링 지표마다 개별적인 모델(Individual Models)을 훈련시키고, 결함 탐지 시 CPU, GPU, PFC 등 가장 민감하고 효과적인 지표부터 순차적으로 검사하도록 우선순위(Prioritization)를 부여하는 방식으로 설계
Minder 핵심 설계
Minder는 예기치 않은 노드 장애를 자동으로, 즉각적으로, 정확하게 탐지하는 것을 목표로 함.
아래 4가지 핵심 설계 원칙을 기반으로 작동.
- Machine-level Similarity
- Machine-level Continuity
- Individual Learning-Based Denoising Models
- Prioritized Metric Sequence
Machine-level Similarity
대규모 분산 학습 환경에서는 노드 간 연산, 저장, 통신 부하 등이 균등하게 분배됨을 기반으로 함.
- 정상적인 노드는 유사한 변동 패턴을 보이게 될 것이고.
- 전체 노드의 데이터 벡터 간 수학적 차이를 모니터링하면, 결함이 발생한 노드에서만 이상 결과가 나올 것.
- 또한, 라벨링이 필요 없는 unsupervised learning을 기반으로 모니터링을 수행하여 정상, 비정상을 분류하는 것이 아닌 현재 진행 중인 작업이 균일한 분포화 패턴을 가지는지를 판단.
Machine-level Continuity
- 이상 패턴 발생을 바로 장애로 인식하지 않고 일정 기간 지속되는지를 확인.
- 분산 학습의 특정 상 bursty noises는 빈번히 발생하므로 이를 필터링하기 위함.
Individual Learning-Based Denoising Models
- 단일 지표로 특정 결함을 판단할 순 없으며, 지표 별로 판단할 수 있는 결함의 종류도 다름.
- 따라서, 모든 지표를 하나의 큰 모델로 묶지 않고 CPU 사용량, 메모리 사용량 등 각 지표별로 개별적인 모델을 따로 훈련
Prioritized Metric Sequence
- 다양한 지표 중 더 장애에 민감한 지표가 존재함.
- 이를 반영하여 우선순위를 정하고, 우선순위가 가장 높은 지표와 그 지표에 해당하는 모델을 사용하여 먼저 장애 노드를 판별.
- 우선순위에 따라 순차적으로 검사를 진행하는 방식을 반복하여 더 빠른 탐지가 가능.
Minder 동작 방식
Processing -> per-metric Model Training -> Monitoring Metric Prioritization -> Online Faulty Machine Detection 4단계 과정을 통해 모니터링 데이터 처리 및 장애 탐지를 수행.
- 데이터 전처리 (Preprocessing): 각 기계에서 수집된 원시 모니터링 데이터의 타임스탬프를 정렬 및 패딩하고, Min-Max 정규화를 수행하여 다차원 데이터를 통합
- 지표별 모델 학습 (Per-metric Model Training): 일시적인 노이즈를 제거하고 데이터를 정제된 임베딩으로 재구성하기 위해, 각 모니터링 지표마다 개별적인 비지도 학습 모델(LSTM-VAE)을 훈련
- 모니터링 지표 우선순위 지정 (Monitoring Metric Prioritization): Z-score(지표 별 민감도)와 의사결정 나무(Decision Tree)를 활용하여 수많은 모니터링 지표 중 기계 결함에 가장 민감하게 반응하는 지표들의 검사 우선순위를 결정
- 실시간 결함 기계 탐지 (Online Faulty Machine Detection): 우선순위가 높은 지표와 모델부터 순차적으로 사용하여 기계들 간의 모니터링 데이터 거리(이질성)를 계산하고, 이러한 이상 패턴이 일정 시간 연속적으로 나타나는 기계를 최종 결함 기계로 확정
성과 및 결과
- 결함 발생 시 데이터를 가져오고 처리하여 알림을 보내는 데까지 평균 3.6초가 소요. 이는 기존 수동 디버깅에 걸리던 시간을 99% 이상(약 500배) 단축한 수치.
- 정밀도(Precision) 0.904, F1-score 0.893을 달성 -> 기존의 통계적 이상 탐지 알고리즘(ex. Mahalanobis Distance)과 비교했을 때 더 높은 정확도를 보여줌.
참고
- https://www.backend.ai/ko/blog/2026-02-listening-to-500-plus-gpus-pulse 이 글을 읽다 참고 문서 중 https://arxiv.org/pdf/2411.01791 내용이 좋아서 핵심 내용 발췌.

Whatever you're not changing, you're choosing