clickhouse
What is ClickHouse
클릭하우스는 간단하게 ch로 언급.
- ch는 온라인 분석 처리(OLAP)를 위한 고성능 열 기반 SQL 데이터베이스 관리 시스템(DBMS)으로, 오픈소스 소프트웨어와 클라우드 서비스 형태로 제공
분석이란?
- OLAP(Online Analytical Processing)은 대량의 데이터를 다양한 각도에서 빠르게 분석하기 위한 데이터 처리 방식.
- 데이터 분석 = OLAP 을 의미하며, 방대한 데이터 세트에 대한 복잡한 계산(집계, 문자열 처리, 산술)을 포함하는 SQL 쿼리 자체를 의미.
- 트랜잭션 쿼리(OLTP와 같은)는 쿼리 당 몇 개의 행만 읽기 때문에 밀리초 단위로 완료되지만 OLAP은 보통 수십 억, 수조 개의 행을 처리한다.
- 보통의 분석쿼리도 실시간성을 요구하기 때문에 1초 내로 결과가 반환되어야 한다.
열(column,세로)기반 vs. 행(row,가로)기반
- ch는 열기반 데이터베이스로, 테이블에는 컬럼의 집합이 저장된다.
- 즉, 각 열의 값의 순차적으로 저장되는 방식이다.
- column oriented 방식의 경우 row 값 간에 간격이 발생할 수 있어 단일 행을 복원하는 작업은 복잡할 수 있지만 필터, 집계와 같은 column 기반의 작업은 row oriented DB보다 훨씬 빠르다.
Concepts
what is OLAP
- OLAP은 Online Analytical Processing 를 뜻하며 processing -> 여러 소스에서 인입되는 데이터를 처리할 수 있으며, analytical -> 분석을 위한 리포트와 인사이트를 제공하고, online -> 이걸 실시간으로 처리한다. 는 의미를 가지고 있다.
- OLAP은 기술적, 사업적인 의미를 지님.
- 사업적으로 OLAP은 데이터 분석의 의미가 커진 시점에서 OLAP을 통해 회사는 지속적인 계획, 분석, 활성화 데이터를 기반으로 한 보고서 작성, 효율성 증대, 비용 절감, 마켓 share에서 고점 차지 등을 구현할 수 있음.
- 기술적으로, DB 관리 시스템은 OLAP, OLTP로 구분할 수 있는데 OLAP은 대규모의 과거 데이터 기반의 리포트 생성을 목적으로 하며, OLTP는 지속적인 데이터 교환 스트림을 처리하여 현재 데이터 상태를 지속적으로 수정한다. OLAP과 OLTP는 이분법적으로 구분할 수 있는 개념은 아니고 각 영역의 솔루션들은 HTAP(Hybrid Transactional/Analytical Processing) 방향으로 가고 있다.
Why is ClickHouse so Fast?
- 다른 열기반 db 대비 왜 빠른것인지 storage layer와 query processing layer 측면에서 설명.
- 기본적으로 ch는 이 2개 레이어에서 모두 빠른 insert와 Select 쿼리를 구현.
Storage layer: concurrent inserts are isolated from each other
- ch는 사용자가 테이블에 데이터를 insert할 때 생성되는 part라는 개념이 있음.
- 이는 다른 db의 partition과는 다른 개념으로, 논리적으로 테이블을 나눈것이 아닌 실제 테이블 내 데이터의 일부를 가지고 있는 단위.
- ch 내에서는 너무 많은 part가 생성되는 것을 방지하기 위해 백그라운드로 작은 part들을 merge하는 작업들이 수행됨.
- 데이터 처리가 백그라운드의 파트 병합으로 오프로딩된 형태이기 때문에 개별적인 insert는 global 업데이트가 아닌 개별 part 단위로 수행되게 된다. 결과적으로 insert속도는 실제 disk I/O와 거의 유사하게 동작하게 됨.
Storage layer: concurrent inserts and selects are isolated
- 쓰기작업(insert)는 읽기작업(SELECT query) 와 완전히 분리되어 있고, part들을 병합하는 과정은 쿼리에 영향 없이 백그라운드로만 수행된다.
Storage layer: merge-time computation
- 다른 DB와는 다르게 ch는 추가적인 데이터 처리 작업을 백그라운드 병합 작업 시 수행하기 때문에 데이터 쓰기가 가볍과 효율적으로 유지된다.
- 병합 시 최신 데이터만 유지.
- 증분 데이터만 업데이트.
- TTL 기반으로 압축, 이동, 삭제 등의 작업을 수행.
Storage layer: data pruning
- 많은 쿼리는 보통 반복적으로 수행됨. 따라서 동일한, 비슷한 쿼리가 반복해서 수행될 때는 index를 추가하거나 데이터를 좀 더 빠른 접근이 가능하도록 재구성한다. 이러한 접근 방식을 data pruning 이라고 하고 ch는 아래 3가지로 pruning을 구현함.
- 데이터 정렬 순서 정의를 위해 primary key index 사용.
- ch에서 primary key는 데이터가 disk에 쓰이는 순서를 의미하며, 전통적인 DB에서 언급되는 pk와는 다르게 유니크함을 유지 하지 않음. (여러 행에서 중복된 값을 가질 수 있음)
- table projections (예상되는 테이블)
- 같은 데이터를 가지지만 primary key가 다른 테이블. 하나 이상의 빈번히 사용되는 필터 옵션이 있을 경우 유용.
- skipping indexes ( 내장된 인덱스 값으로 데이터 통계지표 등의 추가적인 데이터가 저장된다.)
- 쿼리 실행 시 필터 추가 데이터를 기반으로 조건을 만족할 가능성이 없는 데이터는 스킵.
- 데이터 정렬 순서 정의를 위해 primary key index 사용.
Storage layer: data compression
- ch는 다양한 코덱을 사용하여 taw table data를 추가적으로 압축.
State-of-the-art query processing layer
최첨단 쿼리 처리 레이어.
- ch는 쿼리 실행을 최대한 병렬화하여 모든 리소스를 최대한 활용하여 속도와 효율성을 극대화하는 벡터화된 쿼리 처리 계층을 사용.
벡터화란 쿼리 연산자가 단일 행 대신 중간 결과 행을 일괄적으로 전달하는 것을 의미.
Deployment and Scaling
용어 정리
-
Replica
- ch는 하나 이상의 데이터 복제본을 갖음. (최소 1)
-
shard
- 데이터의 서브셋.
- ch는 최소 하나의 샤드를 갖음. 따라서 여러 서버에 걸쳐 데이터를 나눠서 저장하지 않으면 데이터는 하나의 샤드에 모두 저장된다.
- 만일 한대의 서버에서 수용 가능한 capa를 넘어서면 여러대의 서버에 샤딩된 데이터를 나눠 저장할 수 있다.
- 데이터가 저장되는 위치는 샤딩 키에 의해서 결정되고, 이는 분산 테이블 생성 시에 정의된다.
-
distributed coordination
-
ClickHouse Keeper는 데이터 복제 및 분산 DDL 쿼리 실행을 위한 coordination system을 제공.
-
ClickHouse Keeper는 Apache ZooKeeper와 호환됨.
-
ch는 scale out보다는 scale up을 선호.
-
scale out이라는 개념은 ch에서 샤드수를 늘리는 건데, 이렇게 되면 각 호스트별로 독립적인 테이블이 생성되게 됨
-

-
이 때 편의를 위해서 distributed table이란걸 사용하는데, 이 테이블은 자체적으로 데이터를 저장하거나 하진 않고 다른 호스트에 있는 테이블에 원격으로 접근하기 위한 인터페이스 역할을 한다고 생각하면 된다.
-
distributed table에 쿼리를 날리면 쿼리는 각 호스트에 각 쿼리를 포워딩하고, 데이타 insert 시에는 distributed table 이 자체적으로 데이터를 호스트에 분배한다.
-
-
데이터 안정성을 위해서 shard 수 * 2 만큼의 replica 설정이 필요.
- replica가 설정되어 있으면 한대가 완전히 죽어도 다른 한대에서 서비스가 가능하며, recovery 후 자체적으로 누락된 데이터를 sync 함.
-
clickhouse keeper는 데이터 레플리케이션을 위한 코디네이션 시스템.
- clickhouse keeper는 zookeeper와 완전히 호환되며, 레플리카 간 상태 변화가 있을 때 이를 상태 레플리카에 알리는 역할을 함.
- clickhouse keeper는 clickhouse의 metadata만 저장함.
-
Replication은 데이터 무결성 및 자동 페일오버를 위해 사용되며, sharding은 클러스터의 수평 확장(scale out)을 위해 사용된다.
- sharding은 필수가 아님.
-
clickhouse keeper는 쿼럼 유지를 위해 최소 3대로 구성하는 것을 권장.
- standalone 형식으로 구성도 가능하긴 함.
-
이 모든 설정은 /etc/clickhouse-server/config.xml에 저장됨. -> clickhoust-keeper도 clickhoust-server 패키지 내 번들이라 별도 설치 없이 여기서 설정함.
ch에서 데이터를 관리하는 방법
ch가 데이터를 관리하는 방법 중 아래의 핵심 개념 위주로 정리.
- table parts
- table partitions
- table part merges
- table shards and replicas
- primary indexes
ch에서 table parts란
ch의 mergetree 엔진 제품군의 각 테이블 내 데이터는 변경이 불가한 data parts의 집합으로 disk에 저장된다.
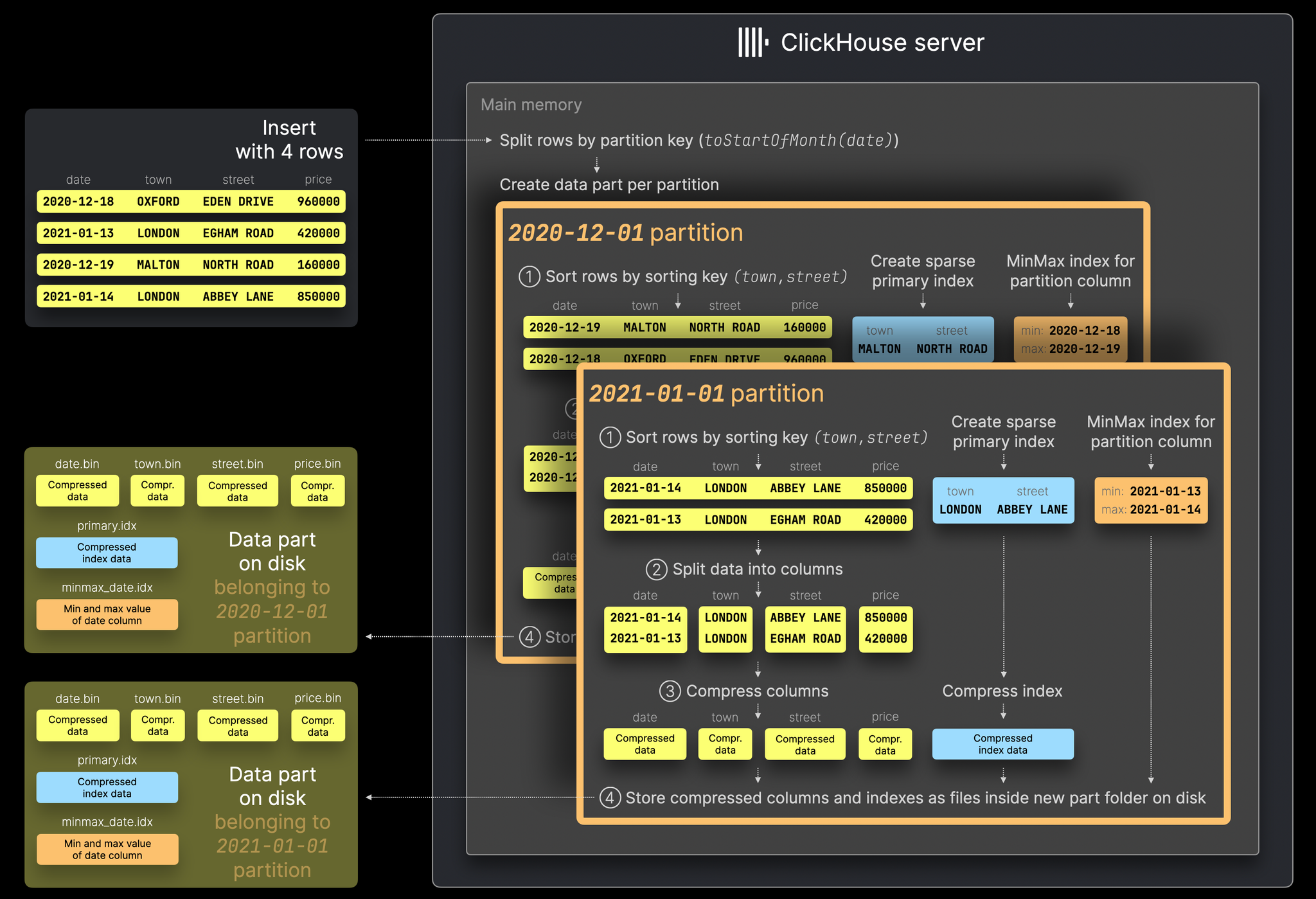
insert로 4개 rows 저장하는 예시를 기반으로 ch가 내부적으로 어떤 프로세스를 수행하는지 확인해보자.
1. 테이블의 sorting key 기반으로 데이터를 소팅한다.
2. 소팅한 데이터를 컬럼으로 쪼갠다.
3. 각 컬럼을 압축한다.
4. 압축된 컬럼을 바이너리 파일로 저장한다. -> 이 각각의 바이너리 파일이 데이터 파츠.
데이터 파트는 중앙 카탈로그 없이도 콘텐츠를 해석하기 위한 모든 메타데이터를 자체적으로 포함하고 있다.
테이블 파츠 병합
수많은 테이블 파츠를 관리하기 위해 ch는 주기적으로 백그라운드에서 작은 파츠를 지정한 압축사이즈 만큼 큰 단위로 병합하는 프로세스를 수행한다.
병합된 부분은 일정 기간 비활성화 상태로 표기된 후 삭제된다. (mergetree table이라 불리는 이유)
초기 파츠수를 최소화하고 병합의 오버헤드를 줄이기 위해 데이터베이스 클라이언트에서 대량 튜플을 삽입하는 것이 좋다. -> 그래서 클릭하우스에서는 한번에 삽입되는 데이터 수가 너무 작으면 ClickhouseLowInsertedRowsPerQuery 에러가 발생힐 수 있음. (한 번에 insert하는 row 수가 초당 1000개보다 적으면 에러 발생)
테이블 파티션
파이션은 mergetree 엔진 테이블의 데이터 파츠를 체계적이고 논리적인 단위로 그룹화한다.
파티션을 통해 시간 범위, 범주 또는 기타 주요 속성과 같은 특정 기준에 맞춰 개념적으로 의미있고 정렬될 데이터를 구성하여, 데이터 관리, 쿼리 및 최적화가 더 쉬워진다.
파티셔닝은 테이블 생성 시 PARTITION BY clause를 정의하면 활성화할 수 있다.
파이셔닝이 적용되지 않았을 경우 데이터가 삽입될 때 row 단위로 파츠를 생성하지만, 파티셔닝이 적용된 경우 파티션을 우선 생성한 후 파티션에 속하는 데이터 기반으로 위의 4단계를 거쳐 파츠를 생성한다.
파티션 병합
파티션이 활성화되어 있으면 클릭하우스는 파티션 내에서만 파츠들을 병합하고 파티션 간 파츠는 병합하지 않는다.
서로 다른 파티션에 포함된 파츠는 절대 병합되지 않는다.
따라서, 중복이 많은 값을 파티션 키로 설정할 경우 여러 파티션에 존재하는 중복된 파츠는 절대 병합되지 않고 중복된 채로 남아 있게 되기 때문에 Too many ^^parts^^오류가 발생할 수 있다.
쿼리 속도를 고려했을 때 파티션 수는 100~10000개 정도가 적합하다.
파티션은 어떻게 사용되는가 ?
- 데이터 관리
- 쿼리 최적화
데이터 관리
클릭하우스에서 파티셔닝은 데이터 관리를 위한 주요 기능이다.
파티션을 사용하면 각 파티션에 포함된 데이터를 독립적으로 관리할 수 있게된다. 데이터 관리를 위해 TTL을 사용할 수 있는데, month 단위로 파티션을 관리하고 있을 때 TTL을 12 months로 지정하면 12개월의 데이터만 보존하는 시나리오가 가능해진다.
TTL로 데이터를 삭제할 수도 있지만 특정 기간 이후 스토리지도 옮기는 등의 작업도 가능하다.
쿼리 최적화
쿼리 최적화를 위해서 클릭하우스는 파티션 건너뛰기 -> 데이터 조각 건너뛰기를 수행한다.
쿼리의 조건 절에서 파티셔닝 데이터 기반으로 쿼리 범위에 포함되지 않는 파티션은 우선 건너뛰고 -> 파티셔닝 데이터가 아닌 조각 데이터 기반으로 아닌 데이터 조각을 건너뛴다.
WHERE date >= '2020-12-01'
AND date <= '2020-12-31'
AND town = 'LONDON';
위 조건으로 쿼리를 수행했고, 파티션이 PARTITION BY toStartOfMonth(date) 설정되어 있을 때
클릭하우스는 날짜 필드의 MinMax 인덱스를 사용하여 날짜 필터와 일치하는 데이터만 사용하고 그외 데이터는 건너뛴다.
그 다음 걸러진 데이터에서 town 필드 필터와도 일치하는 데이터 행을 찾고 그 외 데이터는 건너뛴다.
파츠 병합
클릭하우스는 LSM 트리와 비슷하게 동작하는 스토리지 레이어 덕에 쿼리뿐만 아니라 데이터 삽입 속도도 빠르다.
1. 삽입된 데이터는 정렬된 후에 불변의 파츠가 되고
2. 클릭하우스는 백그라운드로 파츠를 병합하여 데이터를 처리
이러한 동작 방식때문에 데이터 쓰기가 가벼워지고 효율이 높아진다.
파츠 병합은 압축 크기가 대략 150GB 정도가 될 때까지 병합된다.
병합된 파츠는 일정 기간동안 비활성화된 후 삭제된다.
동시 병합
단일 클릭하우스 서버는 동시 파츠 병합을 위해 여러개의 병합 쓰레드를 사용한다.
- 병합될 파츠를 메모리에 올리고 -> CPU 코어수와 메모리 사이즈가 여유 있으면 백그라운드 병합 처리량을 증가시킬 수 있다.
- 메모리에서 파츠를 병합하고
- 병합된 파츠를 디스크에 쓴다.
병합을 위한 메모리 최적화
클릭하우스는 한번에 모든 파츠를 병합하기 위해 메모리에 올리지 않는다.
여러 요인을 고려하여 메모리 사용량을 줄이기 위해 수직병합(vertical merging)이라 불리는 방식을 사용한다.
이는 한꺼번에 메모리에 올리는 것이 아니라 블럭의 청크 단위로 파츠를 병합하는 방식을 의미한다.
병합 방식
파츠 병합은 아래 단계를 거친다.
1. 압축 해제 후 메모리에 올려지고
2. 컬럼파일로 병합되고
3. 병합된 컬럼파일에 새로운 프라이머리 인덱스가 추가되고 (이를 sparse primary index라고 함, 모든 데이터에 붙는 인덱스가 아닌 병합된 컬럼에 새로 추가되는 인덱스라 sparse, 희소한 이라는 표현이 붙는 것 같음)
4. 새로운 병합컬럼파일은 압축되어 새로운 디렉토리에 저장된다.
병합에는 아래와 같은 방식이 존재한다.
1. standard merges -> 위에서 설명한 그대로 병합이 진행되는 방식.
2. replacing merges -> standard와 비슷한데, 행의 가장 최신 버전만 보존되고 나머지는 버려짐.
3. summing merges -> 숫자 데이터가 병합과정에서 자동으로 요약됨.
4. aggregating merges -> summing 은 aggregating의 특수 변형 중 하나로 aggregating은 병합 중 90개 이상의 집계 함수를 적용하여 자동 증분 데이터 변환을 허용.
테이블 샤드와 레플리카
클릭하우스에서는 데이터가 단일 서버에 비해 너무 크거나, 단일 서버가 데이터 처리 속도가 너무 느릴 때 샤딩을 사용한다.
각 샤드는 데이터 하위 집합을 저장하고 독립적으로 쿼리할 수 있는 일반 클릭하우스 테이블처럼 동작한다.. (샤딩이 분리되면 테이블이 분리되는 것과 같음)
하지만 쿼리는 샤드별로 동작하기 때문에 일반적으로 클릭하우스에서 제공하는 분산 테이블을 통해 전체 데이터에 대한 통합 뷰를 제공한다.
분산 테이블 자체가 데이터를 저장하고 있는 것은 아니고 SELECT를 수행할 때는 전체 샤드에 쿼리를 포워딩해서 데이터를 셀렉하고, INSERT 수행 시에는 전체 샤드에 동등하게 데이터를 분산한다.
분산 테이블 생성
ENGINE = Distributed('test_cluster', 'uk', 'uk_price_paid_simple', rand()) 와 같은 구문을 사용하여 분산 테이블을 생성할 수 있다.
클릭하우스에서 레플리카란?
클릭하우스에서 레플리카는 여러 서버 간 샤드 데이터를 복사하여 유지함으로써 데이터 무결성과 페일오버를 보장한다.
하드웨어 오류는 불가피하기 때문에 레플리케이션을 통해 데이터 손실을 방지할 수 있다.
클릭하우스에서 레플리케이션을 사용하기 위해서는 keeper가 필요 하다.
프라이머리 인덱스 (https://clickhouse.com/docs/primary-indexes)
sparse primary index는 ch에서 어떻게 동작하나 ?
클릭하우스에서 파츠 병합시 병합된 컬럼파일에 새로운 프라이머리 인덱스가 추가되는데 이를 sparse primary index라고 한다. (모든 데이터에 붙는 인덱스가 아닌 병합된 컬럼에 새로 추가되는 인덱스라 sparse, 희소한 이라는 표현이 붙는 것 같음)
클릭하우스에서 sparse primary index는 테이블의 primary key 기반 쿼리 조건과 일치하는 데이터가 포함될 수 있는 그레뉼(행 블록) 효율적으로 식별하는데 도움을 준다.
- 그래뉼(granule) : 압축되지 않은 블록에 있는 행들의 배치. ch는 데이터를 읽을 때 개별행이 아닌 그래뉼에 접근하기 때문에 빠른 분석이 가능하다. ch에서 그래뉼은 기본적으로 8,192개의 행을 포함한다.
클릭하우스는 전체 행을 인덱싱 하지 않고 primary key로 지정된 컬럼 파일에서 그래뉼 하나당 primary key(첫번째 행)를 저장한다.
이렇게 되면 전체 row에 indexing이 추가되는 것보다 훨씬 밀도가 작게 index가 설정되게 된다.
이 덕분에 primary index는 전체를 memory에 올려도 될 정도로 사이즈가 작아지고 빠른 필터링이 가능해진다.
