
3 엘라스틱서치 기본
알아야하는점 : 저장과 인출 방식을 확실히 이해해야 한다.
인출을 위해서는 가장 먼저 저장이 필요하며, 저장을 위해서는 스키마를 구성하고 데이터를 집어넣어야 한다.
이 과정에서 데이터 타입을 배우고 전문 검색 내부 동작 방식을 이해해야 한다.
이렇게 기본적인 지식을 습득하고 나서야 검색과 집계가 가능해진다.
-
실습환경인 엘라스틱 서치와 키바나를 준비하고 데이터를 불러온다.
-
저장 과정에 있어 핵심인 인덱스와 도큐먼트 개념을 이해한다.
-
도큐먼트의 생성/읽기/수정/삭제 방법에 이어, 엘라스틱서치의 스키마 개념인 매핑을 속속들이 파고든다.
-
복수의 인덱스를 묶어서 관리하는 템플릿 설정 방법을 소개한다.
-
전문 검색을 위해 문자열을 나누는 작업을 수행하는 분석기를 설명하면서 저장과정에서 알아야하는 용어와 개념을 마무리한다.
3.1 준비작업
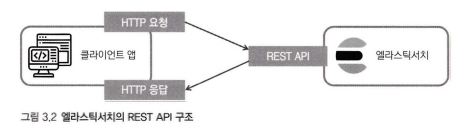
엘라스틱서치는 모든 기능은 REST API 형태다.
- 인덱스를 생성
-
설명에 맞는 인덱스 생성
-
인덱스가 너무 많아지면 관리가 힘들다.
-
인덱스를 확인하고 삭제하는 방법도 함께 이해한다.
3.1.1 엘라스틱서치 요청과 응답
엘라스틱서치는 모든 요청과 응답을 REST API 형태로 제공한다.
REST란 웹상의 모든 리소스에 URL를 부여하고 활용하는 아키텍처다.
REST를 도입하면 모든 리소스를 일관된 규칙으로 접근할 수 있어 애플리케이션을 모듈이나 기능별로 분리하기 쉬워진다.
※ REST API
REST는 Representational State Transfer 의 약자로 웹 HTTP의 장점을 이용해 리소스를 주고받는 형태며, REST API는 REST 기반으로 API를 서비스하는 것을 의미한다.
REST API는 메소드(method)와 경로(URL)가 합쳐진 형태다.
METHOD
먼저 메소드는 4가지로 나타낼수 있다.
POST : 해당 리소스를 추가한다.
GET : 해당 리소스를 조회한다.
PUT : 해당 리소스를 수정한다.
DELETE : 해당 리소스를 삭제한다.
REST API는 4 가지 메소드 타입을 가지고 리소스의 CRUD(생성/읽기/수정/삭제) 작업을 진행한다.
URL(Unifrom Resource Identifier)
URL로 리소스를 정의하고 메소드와 함께 서버에 요청하고 응답을 받는 구조다.
① POST es_index/_doc/l { "name": "kim", "age": 20 }
② GET es_index
③ GET es_index/_doc/l
④ DELETE es_index
① 은 es_index라는 인덱스를 만들고 1번 도큐먼트를 생성한다.
② 는 es_index를 조회한다.
③ 은 es_index 내부의 1번 도큐번트만 조회한다.
④ 은 es_index 삭제한다.
3.1.2 키바나 콘솔 사용법
REST API 호출 하는 방법
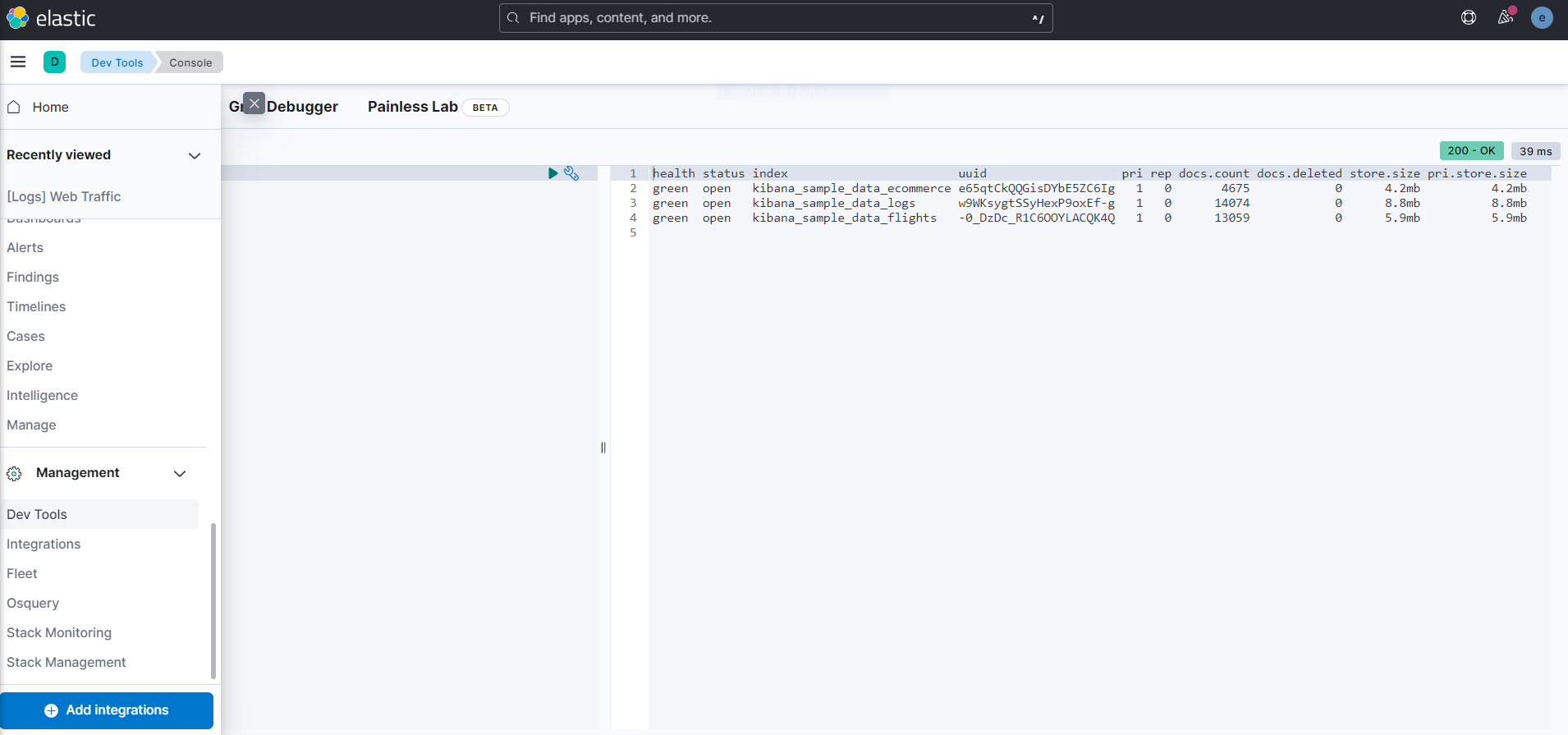
Management → Dev Tools → Console
- GET _cat
- cat API가 지원하는 목록을 확인할 수 있다.
cat : compact and aligned text 의 약어
cat API를 통해 노드, 샤드, 템플릿 등의 상태 정보나 통계 정보를 확인할 수 있다.
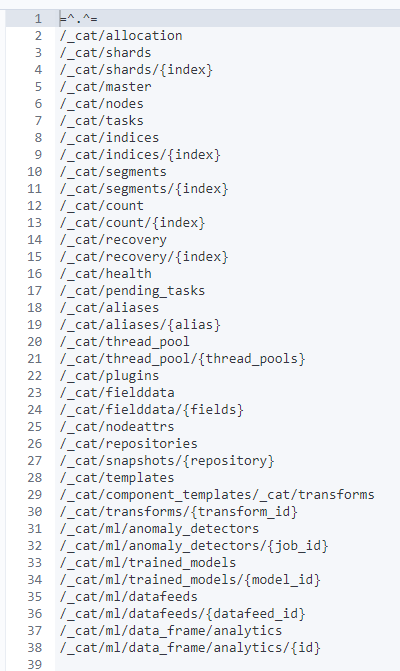
- GET _cat/indices?v
- cat API의 클러스터 내부 인덱스 목록을 확인

3.2 인덱스와 도큐먼트
index(인덱스) : 인덱스는 도큐먼트를 저장하는 논리적 구분자이며, 도큐먼트는 실제 데이터를 저장하는 단위다.
구조
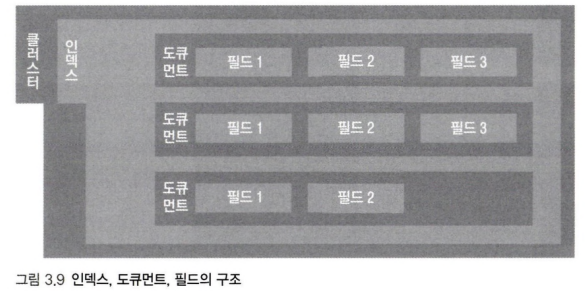
3.2.1 도큐먼트
도큐먼트는 엘라스틱서치에서 데이터가 저장되는 기본 단위로 json 형태며, 하나의 도큐먼트는 여러 필드와 값을 가진다.

{
"name":"mike",
"age":25,
"gender":"male",
}3.3.1 인덱스 생성/확인/삭제
PUT index1
GET index1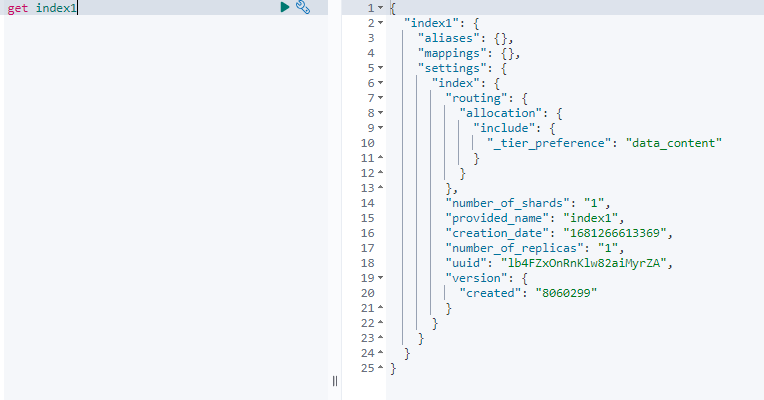
DELETE index1
실습
put index2/_doc/1
{
"name":"mike",
"age":25,
"gender":"male"
}
put index2/_doc/2
{
"name":"jane",
"country":"france"
}
put index2/_doc/3
{
"name":"kim",
"age":"20",
"gender":"female"
}
get index2
get index2/_search
put index2/_doc/1
{
"name":"park",
"age":45,
"gender":"male"
}
get index2/_doc/1
get index2/_search
POST index2/_update/1
{
"doc":{
"name":"lee"
}
}
get index2/_search
delete index2/_doc/2
get index2/_search
get index2
get index5
POST _bulk
{"index": {"_index": "index2", "_id":"4"}}
{"name" : "park", "age": 30, "gender": "female"}
{"index": {"_index": "index2", "_id":"5"}}
{"name":"jung", "age": 50, "gender": "male"}
get index2/_search
3.6 매핑
관계형 데이터베이스는 테이블을 만들 때 반드시 스키마 설계가 필요하다. (논리적인 관계)
→ 이와 같은 것이 엘라스틱 서치에서 매핑이다.
엘라스틱 서치가 검색엔진으로 전문 검색과 대용량 데이터를 빠르게 실시간 검색할 수 있는 이유는 매핑이 있기 때문인데, 매핑의 방식에는 2가지 방식이 있다.
- 자동으로 엘라스틱서치가 매핑하는 경우 → 다이내믹 매핑
- 사용자가 직접 설정하는 경우 → 명시적 매핑
매핑할때 사용하는 데이터 타입의 종류
- 텍스트(text)
- 키워드(keyword)
전문 검색을 활용하려면 반드시 두 가지 타입을 이해하고 있어야 한다.
3.6.1 다이내믹 매핑
엘라스틱서치의 모든 인덱스는 매핑 정보를 갖고 있지만 유연한 활용을 위해 인덱스 생성시 매핑 정의를 강제하지는 않는다. 앞에서 index2 인덱스를 만들 때 우리는 따로 매핑을 설정하지 않았다. 하지만 도큐먼트가 인덱싱되었던 이유는 엘라스틱서치의 다이내믹 매핑기능 때문이다.
특별히 데이터 타입이나 스키마에 고민하지 않아도 JSON 도큐먼트의 데이터 타입에 맞춰 엘라스틱서치가 자동으로 인덱스 매핑을 해주는 것이다.
데이터 타입을 확인 하는 방법
get index2/_mapping지금은 간단한 예제를 작성하는 수준이라서 특별히 문제가 없지만 규모가 커진다면 효율이 떨어진다.
일례로 age 필드는 사람의 나이인데, 적어도 이 책을 쓰는 시점을 기준으로 200살을 넘긴 사람은 없으므로 수십억을 표현하는 long타입 보다는 메모리를 조금 쓰는 short 타입이 유리할 것이다.
또한 country나 gender 같은 범주형 데이터는 전문 검색보다는 일반적으로 집계나 정렬, 필터링을 위해서 사용되기 때문에 키워드 타입으로 지정하는 것이 좋다.
3.6.2 명시적 매핑
인덱스 매핑을 직접 정의하는 것을 명시적 매핑이라고 한다.
인덱스를 생성할때 mappings.properties 아래에 필드명과 필드 타입을 지정해주면 된다.
PUT index3{
"mappings":{
"properties":{
"age":{"type":"short"},
"name":{"type":"text"},
"gender":{"type":"keyword"}
}
}
}
※ 주의할점!
명시적 매핑을 사용을하게 되면 새로운 필드를 추가할수는 있다. 하지만
이미 정의된 필드를 수정하거나 삭제할 수는 없다.
필드 이름을 변경하거나 데이터 타입을 변경하기 위해서는 새로운 인덱스를 만들거나, reindex API를 이용해야 하니 매핑 작업은 신중하게 하는 것이 좋다.
properties 파라미터 이외에도 분석기(analyzer)나 포맷(format) 등을 설정하는 파라미터도 있다.
3.6.3 매핑 타입
명시적 매핑을 위해서는 엘라스틱서치에서 사용하는 데이터 타입에 대한 이해가 필요하다.
좋은 스키마가 관계형 데이터베이스의 성능을 끌어올리는 것처럼 매핑을 잘 활용하면 엘라스틱 서치의 인덱스 성능을 올릴수 있다.
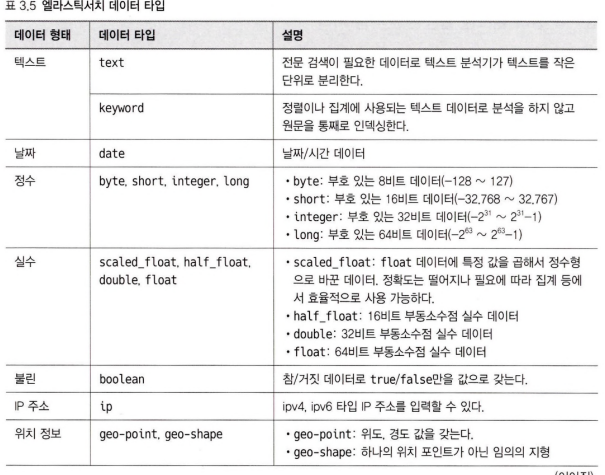
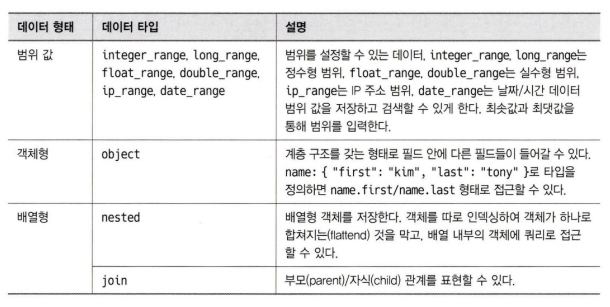
3.6.4 멀티 필드를 활용한 문자열 처리
엘라스틱 서치 5.x 버전부터 문자열 타입이 텍스트와 키워드라는 두 가지 타입으로 분리되었다. 이 두가지 타입이 어떤 용도로 사용되는지 알아보고, 멀티 필드를 사용해 두 타입을 동시에 활용하는 방법도 알아보자.
3.6.4.1 텍스트 타입
엘라스틱서치에서 텍스트 타입은 일반적으로 문장을 저장하는 매핑타입으로 사용된다. 강제성은 없지만 일반적으로 문장이나 여러 단어가 나열된 문자열을 텍스트 타입으로 지정한다.
다음 문장은 텍스트 타입으로 지정하는 것이 좋다.
"We offer solution for enterprise search, observability, and security that are built on a single, flexible technology stack that can be deployed anywhere"
# 클러스터 구조 및 인덱스 구조설정 명시적방안
put text_index
{
"mappings":{
"properties":{
"contents":{
"type":"text"
}
}
}
}
# text_index document 안에 contents 내용을 넣음 id:1, id:2, id:3
put text_index/_doc/1
{
"contents":"beautiful day"
}
put text_index/_doc/2
{
"contents":"beautiful"
}
put text_index/_doc/3
{
"contents":"beautiful day"
}
# 해당되는 단어를 찾는 방법
get text_index/_search
{
"query":{
"match":{
"contents": "day"
}
}
}
3.6.4.2 키워드 타입
키워드 타입은 카테고리나 사람 이름, 브랜드 등 규칙성이 있거나 유의미한 값들의 집합, 즉 범주형 데이터에 주로 사용된다.
키워드 타입은 텍스트 타입과 다르게 분석기를 거치지 않고 문자열 전체가 하나의 용어로 인덱싱 된다.
앞서 텍스트 타입은 beautiful day 라는 문자열을 [beautiful, day] 라는 용어로 분리했는데,
키워드 타입은 beautiful day 라는 1개의 용어로 만든다.
따라서 키워드 타입으로 매핑된 데이터는 부분 일치 검색은 어렵지만 대신 완전 일치 검색을 위해 사용할 수 있으며 집계나 정렬에 사용할 수 있다.
예를 들어 성별을 나타내는 필드(male/female)나 상태를 나타내는 필드(active/deactive)와 같이 범주형 데이터는 용어를 분리할 필요가 없다.
범주형 데이터의 경우 데이터 형태가 몇 가지로 고정되기 떄문에 문자열 집계나 정렬 작업에 활용 가치가 더 높다.
keyword 데이터 타입 클러스터 인덱스 생성
put keyword_index
{
"mappings":{
"properties":{
"contents":{
"type":"keyword"
}
}
}
}내용 삽입
put keyword_index/_doc/1
{
"contents":"beautiful day"
}결과 없음
get keyword_index/_search
{
"query":{
"match":{
"contents":"beautiful"
}
}
}결과 나옴
get keyword_index/_search
{
"query":{
"match":{
"contents":"beautiful day"
}
}
}
3.6.4.3 멀티 필드
멀티 필드는 단일 필드 입력에 대해 여러 하위 필드를 정의하는 기능으로, 이를 위해 fields 라는 매핑 파라미터가 사용된다.
fields는 하나의 필드를 여러 용도로 사용할 수 있게 만들어 준다.
문자열의 경우 전문 검색이 필요하면서 정렬도 필요한 경우가 있다.
또한 처음 데이터 스키마를 잡는 시점에서는 키워드 타입으로 충분한 처리가 가능한 범주형 데이터 였지만 데이터가 늘어나면서 전문 검색이 필요해지는 경우도 생긴다.
이런 경우 처음 매핑할 때 텍스트와 키워드를 동시에 지원해야한다.
put multifield_index
{
"mappings":{
"properties":{
"message":{"type":"text"},
"contents":{
"type":"text",
"fields":{
"keyword":{"type":"keyword"}
}
}
}
}
}
put multifield_index/_doc/1
{
"message":"1 document",
"contents":"beautiful day"
}
put multifield_index/_doc/2
{
"message":"2 document",
"contents":"beautiful day"
}
put multifield_index/_doc/3
{
"message":"3 document",
"contents":"wonderful day"
}
get multifield_index/_search
{
"query":{
"match":{
"contents":"day"
}
}
}
get multifield_index/_search
{
"query":{
"term":{
"contents.keyword": "day"
}
}
}
get multifield_index/_search
{
"query":{
"term":{
"contents.keyword": "wonderful day"
}
}
}
get multifield_index/_search
{
"query":{
"term":{
"contents.keyword": "beautiful day"
}
}
}
get multifield_index/_search
{
"size":0,
"aggs":{
"contents":{
"terms":{
"field": "contents.keyword"
}
}
}
}
3.7 인덱스 템플릿
인덱스 템플릿은 주로 설정이 동일한 복수의 인덱스를 만들 때 사용한다.
관리 편의성, 성능 등을 위해 인덱스를 파티셔닝하는 일이 많은데 이때 파티셔닝되는 인덱스들은 설정이 같아야 한다.
설정이 동일한 인덱스를 매번 일일이 작성하는 것은 비효율적일 뿐만 아니라 실수를 유발할 수 있다.
직접 인덱스 템플릿을 만들고 적용하고 삭제까지 해보자.
3.7.1 템플릿 확인
템플릿 API를 사용해 현재 등록된 인덱스 템플릿을 확인해보자.
다음 API는 전체 인덱스 템플릿을 검색한다.
get _index_template
get _index_template/ilm-history
get _index_template/ilm*
3.7.2 템플릿 설정
인덱스 템플릿을 생성할 때 다양한 설정을 할 수 있지만, 일반적으로 매핑과 세팅설정을 가장 많이한다. 인덱스 템플릿 기술을 이용해 인덱스 매핑과 세팅을 효율적으로 설정해보자.
3.7.2.1 템플릿 생성
인덱스 템플릿을 하나 만들어보자. 템플릿 이름은 test_template
put _index_template/test_template
{
"index_patterns":["test_*"],
"priority":1,
"template":{
"settings":{
"number_of_shards":3,
"number_of_replicas" :1
},
"mappings":{
"properties":{
"name":{"type":"text"},
"age":{"type":"short"},
"gender":{"type":"keyword"}
}
}
}
}

test_template이라는 이름의 템플릿을 생성한다.
인덱스가 아닌 템플릿이니 헷갈리면 안됀다.
index_patterns,priority,template은 템플리에서 사용하는 파라미터로, 인덱스 템플릿을 생성하는데 필요한 중요한 파라미터다.
3.7.2.2 템플릿 적용
※ 주의할점
반드시 기억해야 하는 것은 템플릿을 만들기 전에 이미 존재하던 인덱스는 비록 템플릿 패턴이 일치하더라도 템플릿이 적용되지 않는다.
즉, 어떤 새로운 템플릿을 생성을 할때 만들기 전부터 존재했던 인덱스들은 템플릿의 영향을 받지 않는다. 오직 템플릿을 만든 이후에 새로 만들어지는 인덱스들만 템플릿의 영향을 받는다.
템플릿을 생성해서 데이터를 받아줘야한다.
이유 : 실제로 특정 날짜/시간 별로 인덱스를 만드는 경우나 로그스태쉬 비츠 같은 데이터 수집 툴에서 엘라스틱 서치로 데이터를 보낼 때 템플릿을 이용해 인덱스를 생성하는 경우가 많다.
3.7.2.3 템플릿 삭제
템플릿 생성 시 기존 인덱스들은 영향을 받지 않는다고 했다. 삭제 역시 마찬가지이다.
템플릿을 지워도 기존 인덱스들은 영향을 받지 않는다.
이미 만들어진 인덱스들이 변경되는 것이 아니고 단순히 템플릿이 지워지는 것 뿐이다.
확인해본결과
delete _index_template/test_template
get test_index1/_doc/1
get test_index1/_mapping
템플릿을 지우고 난후 : 기존에 있었던 템플릿에서 인덱스를 생성했던 test_index1 은 사라지지 않고 남아있었다. 즉 단순히 템플릿을 지운다고해서 기존에있었던 데이터가 사라지는 것은 아니다.
put _index_template/multi_template1
{
"index_patterns":"multi_*",
"priority":1,
"template":{
"mappings":{
"properties":{
"age":{"type":"integer"},
"name":{"type":"text"}
}
}
}
}
put _index_template/multi_template2
{
"index_patterns":"multe_data_*",
"priority" : 2,
"template":{
"mappings":{
"properties":{
"name":{"type":"keyword"}
}
}
}
}
1번과 2번의 template 형식은 동일하다. 허나 뒤에 template 번호가 다르다.
우선적으로 숫자가 높은것 위주로 index가 추가된다.
예를들어 put multi_data_index 할 경우 template2에 추가된다.
3.7.4 다이내믹 템플릿
다이내믹 템플릿은 매핑을 다이내믹하게 지정하는 템플릿 기술이다.
매핑은 인덱스 내부의 데이터 저장과 검색 등의 기초가 되기 때문에 매핑은 신중하게 진행하라고 했다.
하지만 로그 시스템이나 비정형화된 데이터를 인덱싱하는 경우를 생각해 보자.
put dynamic_index1
{
"mappings":{
"dynamic_templates":[{
"my_string_fields":{
"match_mapping_type": "string",
"mapping" : {"type": "keyword"}
}
}]
}
}
match_mapping_type은 조건문 혹은 매핑 트리거다. 조건에 만족할 경우 트리거링이 된다. 여기서는 문자열 string 타입 데이터가 있으면 조건에 만족한다. 매핑은 실제 매핑을 적용하는 부분이다. 리스트 3.34의 경우 문자열 string 타입의 데이터가 들어오면 키워드타입으로 매핑한다. 문자열과 숫자 데이터를 넣어보고 다이내믹 템플릿에 의해 타입이 어떻게 매핑되는지 확인해보자.
put dynamic_index2/doc/1
{
"long_num":"5",
"long_text":"170"
}
dynamic_index2 인덱스에 2개의 필드가 들어있는 도큐먼트를 인덱싱한다. long_num, long_text 필드가 어떻게 매핑되었는지 확인해보자.
long_num 필드는 match 조건에 의해 문자열이 숫자(long)타입으로 매핑되었다.
long_text는 match 조건에 부합하지만 unmatch 조건도 부합하여 다이내믹 템플릿에서 제외되어 다이내믹 매핑에 의해 텍스트/키워드를 갖는 멀티 필드 탑이 되었다.
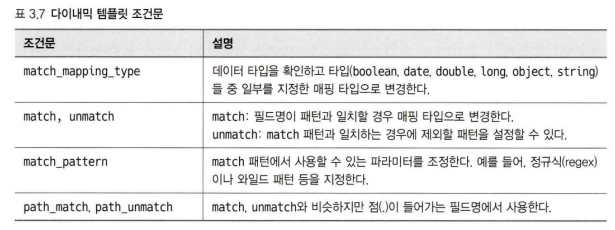
다이내믹 템플릿에서 사용할 수 있는 조건문은 표3.7과 같다.
get dynamic_index2

분석기에는 하나의 토크나이저가 반드시 포함돼야 하며, 캐릭터 필터와 토큰 필터는 옵션이므로 없어도 되고 여러 개를 함께 사용해도 된다. 사용자는 엘라스틱서치에서 제공하는 분석기를 사용하거나 필터와 토크나이저를 조합하여 원하는 분석기를 직접 만들어 사용하기도 한다.
토크나이저, 필터 등을 이해하고 커스텀 분석기를 만드는 방법까지 익혀보자.
토큰과 용어
앞으로 토큰과 용어(term)라는 단어가 많이 사용되는 두 단어가 헷갈리기 쉽다. 간단히 토큰과 용어를 정의하고 넘어가자.
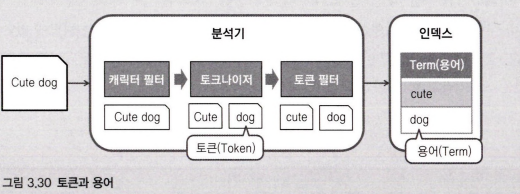
cute dog라는 문자열이 분석기를 거쳐 인덱스에 저장된다고 가정해보자. 분석기는 먼저 캐릭터 필터를 통해 원문에서 불필요한 문자들을 제거한다. 이 과정까지는 문자열 자체가 분리되지 않기 때문에 그저 필터링된 문자열 정도로 볼 수 있다.
이후 분석기는 토크나이저를 이용해 필터링된 문자열을 자르게 되는데, 이때 잘린 단위를 토큰이라고 지칭한다.
이러한 토큰들은 복수의 토큰 필터를 거치며 정제되는데, 정제 후 최종으로 역 인덱스에 저장되는 상태의 토큰들을 용어라고 한다.
토큰은 분석기 내부에서 일시적으로 존재하는 상태이고, 인덱싱되어 있는 단위, 또 검색에 사용되는 단위는 모두 용어라고 할 수 있다.
3.8.1 분석기 구성
캐릭터 필터 : 입력받은 문자열을 변경하거나 불필요한 문자들을 제거한다.
토크나이저 : 문자열을 토큰으로 분리한다. 분리할 때 토큰의 순서나 시작, 끝 위치도 기록한다.
토큰 필터 : 분리된 토큰들의 필터 작업을 한다. 대소문자 구분, 형태소 분석 등의 작업이 가능하다.
캐릭터 필터
- 예를 들면 캐릭터 필터는 문자열의 전처리 작업을한다. 문자열의 토큰 분리는 [가위 바위 보]라는 하나의 문자열을 [가위, 바위, 보]와 같이 3개의 문자로 구분하는 것과 같다.
토큰나이저
-
분리된 토큰은 필터를 거쳐 최종적으로 용어가 되며, 이를 인덱싱해서 전문 검색에 활용하게 된다.
-
이를 테면 [가위]라는 용어부터 [가위 바위 보]를 찾는 것이다.
토큰필터
- 토큰필터는 토크나이저에서 분리된 토큰들에 후처리 작업을 한다.
3.8.1.1 역인덱싱
분석기를 이해하려면 우선 역인덱싱에 대해 알아야한다.
분석기는 문자열을 토큰화하고 이를 인덱싱하는데 이를 역인덱싱이라고 한다.
책의 앞면에 있던 목차와 달리 책의 뒷면에 있던 색인을 기억하는가?
많이쓰는 단어들을 선별해 그 단어가 몇 페이지에 나와 있는지 알려주는것을 색이라고 한다.
즉, 엘라스틱서치는 이와 비슷한 방법으로 단어들을 역인덱싱하여 도큐먼트를 손쉽게 찾을 수 있다.
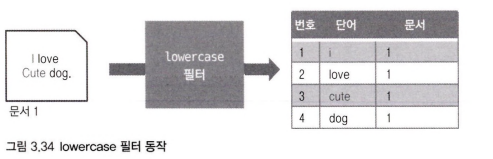
2개의 문서가 분석기를 거치면서 역인덱싱되고 있다. 분석기는 여러 필터와 토크나이저로 이뤄져 있는데 여기서는 스탠다드 토크나이저와 스톱필터, 소문자 변경필터, 스테머필터가 조합된 분석기를 사용했다.
- 스탠다드 토큰나이저
- 스톱필터
- 소문자 변경필터
- 스테머필터
세부적인 토크나이저와 필터는 뒤에서 다시설명한다.
우선 도큐먼트의 문자열이 분석기를 거치면서 토큰화되고 각 토큰들이 어떤 식으로 역인덱싱 되는지 살펴보자.
역인덱스 테이블은 용어가 어떤 문서에 속해 있는지 기록되어 있어서 손쉽게 문서를 찾을 수 있다.
예를들어 'dog'를 검색하면 그림 3.32의 역인덱스를 테이블을 참고하여 문서 1,2번에 dog라는 용어가 있음을 찾아낼수 있다.
3.8.1.2 분석기 API
엘라스틱 서치는 필터와 토크나이저를 테스트해볼 수 있는 analyze라는 이름의 REST API를 제공하고 있다.
analyze API는 온라인 문서에 자세히 나와 있으니 책에서 사용하는 analyzer, text, tokenizer 파라미터 외에 책에 설명하지 못한 explain, attributes 같은 파라미터는 온라인 문서를 참고하자, 키바나 콘솔에서 간단히 분석기를 사용해보자.
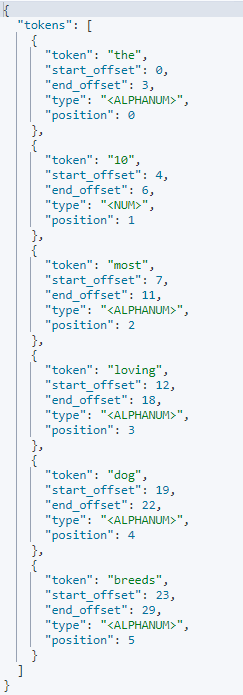
POST _analyze
{
"analyzer" : "stop",
"text" : "The 10 most loving dog breeds."
}
analyze API 사용법은 간단하다. analyzer에 원하는 분석기를 선택하고, text에 분석할 문자열을 입력하면 된다.
참고로, 스톱 분석기는 소문자 변경 토큰나이저와 스톱 토큰 필터로 구성되어 있다. 결과를 확인해보자.
{
"tokens":[
{"token":"most",....},
{"token":"loving",....},
{"token":"dog",....},
{"token":"breeds",....},
]
}

text에 적었던 문자열이 [most, loving, dog, breeds] 4개의 토큰으로 분리되었고 "the", "10"등은 스톱 분석기에 의해 토큰으로 지정되지 않는다는 것만 이해하자.
스톱 분석기는 불용어를 처리한다.
3.8.1.3 분석기 종류
엘라스틱 서치는 다양한 분석기를 제공한다. 엘라스틱서치는 성장이 빠른 오픈소스로, 버전에 따라 변경이 많은데 분석기도 버전에 따라 변화가 많다.
- stop
- standard
- simple
- whitespace

stop

standard
simple

whitespace

3.8.2 토크나이저
토크나이저는 문자열을 분리해 토크화하는 역할을 한다.
토크나이저는 문자열을 분리해 토큰화하는 역할을 한다.
분석기에 반드시 포함돼야 하기 때문에 형태에 맞는 토크나이저 선택이 중요하다.
standard
- 스탠다드 분석기가 사용하는 토크나이저로, 특별한 설정이 없으면 기본 토크나이저로 사용된다. 쉼표(,)나 점(.)같은 기호를 제거하며 텍스트 기반으로 토큰화한다.
lowercase
- 텍스트 기반으로 토큰화하며 모든 문자를 소문자로 변경해 토큰화한다.
ngram
-
원문으로부터 N개의 연속된 글자 단위를 모두 토큰화한다. 예를 들어, '엘라스틱서치'라는 원문을 2gram으로 토큰화한다면[엘라, 라스, 스틱, 틱서, 서치] 와 같이 연속된 두글자를 모두 추출한다.
-
장점 : 사실상 원문으로 부터 검색할 수 있는 모든 조합을 얻어낼 수 있기 때문에 정밀한 부분 검색에 강점이다.
-
단점 : 토크나이징을 수행한 N개 이하의 글자 수로는 검색이 불가능하며 모든 조합을 추출하기 때문에 저장공간을 많이 차지한다는 단점이 있다.
-
uax_url_email
- 스탠다드 분석기와 비슷하지만 URL이나 이메일을 토큰화하는 데 강점이 있다.
3.8.3 필터
분석기는 하나의 토크나이저와 다수의 필터로 조합된다고 했다.
분석기에서 필터는 옵션으로 하나 이상을 포함할 수 있지만, 없어도 분석기를 돌리는데 문제는 없다.
필터가 없는 분석기는 토크나이저만 이용해 토큰화 작업을 진행하는데, 대부분 엘라스틱에서 제공하는 분석기들은 하나 이상의 필터를 포함하고 있다.
필터를 통해 더 세부적인 작업이 가능하기 때문이다.
필터 역시 analyze API를 이용해 테스트해볼 수 있다.
필터는 단독으로 사용할 수 없고 반드시 토크나이저가 있어야 한다.
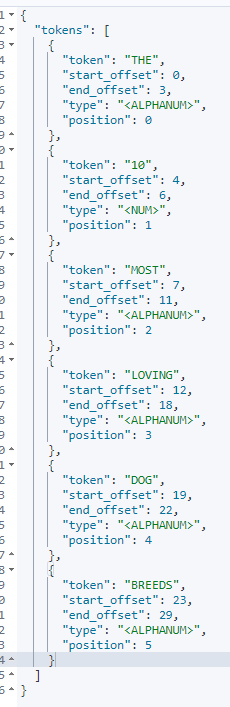
uppercase 필터 테스트
POST _analyze
{
"tokenize":"standard",
"filter" : ["uppercase"],
"text" : "The 10 most loving dog breeds."
}
3.8.3.1 캐릭터 필터
캐릭터 필터는 토크나이저 전에 위치하며 문자들을 전처리하는 역할을 하는데, HTML 문법을 제거/변경하거나 특정 문자가 왔을 때 다른 문자로 대체하는 일들을 한다.
예를들어 같은 문자 ( 는 웹에서 공백을 의미하는 문자를 뜻함)가 오면 공백으로 바꾸는 작업등을 캐릭터 필터에서 진행하면 편하다.
엘라스틱서치가 제공하는 대부분의 분석기는 캐릭터 필터가 포함되어 있지 않다.
캐릭터 필터는 사용하기 위해서는 커스텀 분석기를 만들어 사용하는 것이 좋다.
3.8.3.2 토큰 필터
토큰 필터는 토크나이저에 의해 토큰화되어 있는 문자들에 필터를 적용한다.
토큰들을 변경하거나 삭제하고 추가하는 작업들이 가능하다. 토큰 필터 역시 종류가 많고 자주 변경되기 때문에 여기서는 자주 사용하는 토큰 필터들 위주로 소개하고, 전체 토큰 필터는 온라인 문서를 확인하자.
lowercase
- 모든 문자를 소문자로 변환한다. 반대로 모든 문자를 대문자로 변환하는 uppercase 필터가 있다.
stemmer
- 영어 문법을 분석하는 필터다. 언어마다 고유한 문법이 있어서 필터 하나로 모든 언어에 대응하기는 힘들다.
- 한글의 경우 아리랑, 노리 같은 오픈소스가 있다.
stop
- 기본 필터에서 제거하지 못하는 특정한 단어를 제거할 수 있다.
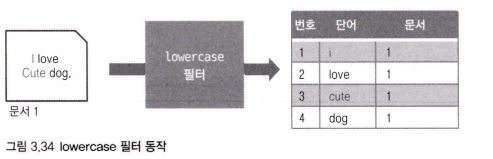
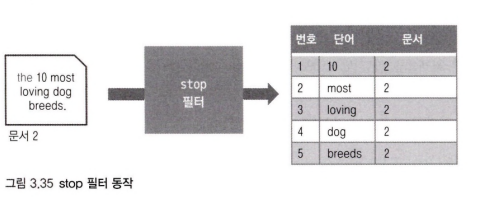
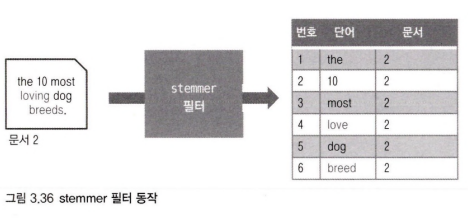
stemmer 필터는 형태소를 분석해 어간을 분석하는 필터다. 각 언어마다 문법이 다르기 때문에 자기가 사용하는 언어에 맞는 필터를 사용해야 한다.
기본적으로 stemmer 필터는 영어를 기반으로 하기 때문에 한글 텍스트의 경우 동작하지 않는다.
loving, loved 는 love와 같은 어간이며
breeds는 breed 와 같은 어간으로 인식한다.
3.8.4 커스텀 분석기
커스텀 분석기에 대해 알아보자. 커스텀 분석기는 엘라스틱 서치에서 제공하는 내장 분석기들 중 원하는 기능을 만족하는 분석기가 없을 때 사용자가 직접 토크나이저, 필터 등을 조합해 사용할 수 있는 분석기다.
필터들의 조합이나 순서에 따라 특별한 형태의 분석기를 만들 수 있다.
3.8.4.1 커스텀 분석기 설정
customer_analyzer라는 인덱스를 하나 만들어보자.
customer_analyzer 인덱스는 my_alalyzer라는 커스텀 분석기를 갖고 있다.
커스텀 분석기에 우리가 원하는 토크나이저와 캐릭터 필터, 토큰 필터를 적용해보자.
3.8.4.2 필터 적용 순서
커스텀 분석기에서 필터를 여러 개 사용한다면 필터의 순서에도 주의해야 한다.
필터 배열의 첫번째 순서 부터 필터가 적용된다.
가끔 이 순서가 잘못되면 원하지 않는 결과가 나오기도 한다.
예제를 실행해보면서 필터 순서에 따라 결과가 어떻게 바뀌는지 확인해보자.
customer_analyzer 인덱스에서 스탠다드 토크나이저를 쓰고 필터를 lowercase, my_stopwords 순으로 진행해보자.
PUT customer_analyzer
{
"settings":{
"analysis": {
"filter": {
"my_stopwords" :{
"type": "stop",
"stopwords" : ["lions"]
}
},
"analyzer": {
"my_analyzer":{
"type":"custom",
"char_filter":[],
"tokenizer" : "standard",
"filter" : ["lowercase", "my_stopwords"]
}
}
}
}
}
# my_analyzer 커스텀 분석기 테스트
get customer_analyzer/_analyze
{
"analyzer":"my_analyzer",
"text":"Cats Lions Dogs"
}
get customer_analyzer/_analyze
{
"tokenizer":"standard",
"filter":["my_stopwords","lowercase"],
"text":"Cats Lions Dogs"
}
다음과 같이 진행하게 되면
- [Cats, Lions, Dogs]로 분리된후
- [lions]의 불용어를 제거
- 대문자이므로 lions의 불용어 제거가 되지않음
- 그러므로 결과는 다음과 같다

3.9 정리
- 인덱스와 도큐먼트의 정의
- 도큐먼트의 CRUD
- 벌크로 데이터를 저장하는 방법
- REST API 형태로 요청하고 응답하는 방법
- 도큐먼트를 인덱싱하기 위해 인덱스 매핑이 중요하다는 점
