
4. 엘라스틱 서치 : 검색
엘라스틱 스택에서 핵심을 차지하는 엘라스틱서치는 전문 검색 기능이며,
텍스트, 숫자, 정형, 비정형 데이터를 저장 → 인덱싱 → 쿼리실행 → 결과
쿼리 종류
- 전문쿼리
- 매치쿼리
- 용어쿼리
- 멀티 매치 쿼리
- 범위쿼리
- 논리쿼리
- 패턴검색
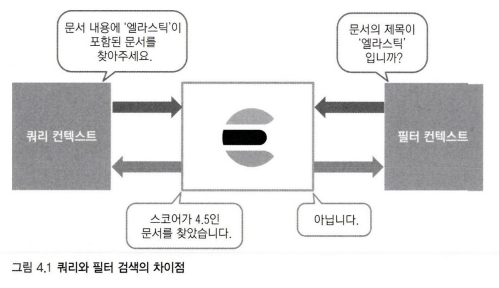
4.1 쿼리 컨텍스트와 필터 컨텍스트
엘라스틱의 검색은 2가지로 분류된다.
- 쿼리 컨텍스트
- 필터 컨텍스트
쿼리 컨텍스트는 질의에 대한 유사도를 계산해 이를 기준으로 더 정확한 결과를 먼저 보여준다.
필터 컨텍스트는 유사도를 계산하지 않고 일치 여부에 따른 결과만을 반환한다. (True/False)
※ 부연설명
도큐먼트에서 '엘라스틱'이 포함되어 있는지 찾을 때는 쿼리 컨텍스트를 이용하는데, 연관성을 계산해 최대한 비슷한 도큐먼트들을 찾아준다.
반면, 도큐먼트 제목이 정확하게 엘라스틱인 문서를 찾기 위해서는 필터 컨텍스트를 이용한다.
get kibana_sample_data_ecommerce/_search
{
"query":{
"match":{
"category":"clothing"
}
}
}hist.total = 3927개 검색된다.
해당쿼리를 사용하면 _score 값은 요청한 검색과 유사도를 나타내는 지표로 오름차순으로 나열되며 clothing과 유사한것 위주로 검색된다.
필터 컨텍스트와 쿼리 컨텍스트를 구분하는 특별한 API가 있는 것은 아니며 모두 search API를 사용한다.
get kibana_sample_data_ecommerce/_search
{
"query":{
"bool": {
"filter": {
"term": {
"day_of_week": "Friday"
}
}
}
}
}hist.total = 770개
해당 쿼리는 필터 컨텍스트 논리 쿼리 내부의 filter 타입이 적용된다.
kibana_sample_data_ecommerce 인덱스의 day_of_week 필드가 friday인 도큐먼트를 찾아달라는 요청이다.
용어 검색과 용어 필터처럼 쿼리 컨텍스트와 필터 컨텍스트가 명확하게 구분되어 문법상 쿼리와 필터 컨텍스트를 구분할 수 있었다.
4.2 쿼리 스트링과 쿼리 DSL
엘라스틱 서치에서 쿼리를 사용하는 방법은 2가지가 존재한다.
- 쿼리스트링
- 쿼리 DSL(Domain Specific Language)
쿼리스트링 : 한 줄 정도의 간단한 쿼리에 사용한다.
쿼리 DSL : 한 줄에 넣기 힘든 복잡한 쿼리에 사용한다.
쿼리 DSL은 엘라스틱서치에서 제공하는 쿼리 전용 언어로, JSON 기반의 직관적인 언어다.
간단한 조건에 대한 검색은 쿼리 스트링으로도 충분하지만, 복잡한 논리 조건이나 코드 수준에서 쿼리를 제어하기 위해서는 쿼리 DSL을 사용하는 것이 좋다.
4.2.1 쿼리 스트링
쿼리 스트링은 REST API의 URL 주소에 쿼리문을 작성하는 방식으로 실행해볼 수 있어 사용하기 쉽다.
하지만 복잡한 논리 조건의 경우 괄호를 이용해야 하는데, 조건이 복잡해지면 가독성도 좋지 않고 오류를 범하기가 쉽다.
GET kibana_sample_data_ecommerce/_search?q=customer_full_name:Mary4.2.2 쿼리 DSL
쿼리 DSL은 REST API의 요청 본문 안에 JSON 형태로 쿼리를 작성한다. 쿼리 DSL은 엘라스틱 서치의 모든 쿼리 스펙을 지원하기 때문에 매우 강력하며 복잡한 쿼리를 구현할 수 있다는 장점이 있다.
하지만 지금처럼 단순한 쿼리라면 굳이 쿼리 DSL을 사용하지 않고 쿼리 스트링을 사용하는 편이 효율적일 수 있다.
쿼리 DSL을 실행해보자.
GET kibana_sample_data_ecommerce/_search
{
"query": {
"match": {
"customer_first_name": "Mary"
}
}
}4.2.1 쿼리스트링과 같은 결과이다.
4.3 유사도 스코어
쿼리 컨텍스트는 엘라스틱에서 지원하는 다양한 스코어 알고리즘을 사용할 수 있는데 기본적으로 BM25 알고리즘을 이용해 유사도 스코어를 계산한다.
유사도 스코어는 질의문과 도큐먼트의 유사도를 표현하는 값으로, 스코어가 높을수록 찾고자 하는 도큐먼트에 가깝다는 사실을 의미한다.
스코어 계산을 위한 기본적인 알고리즘의 동작 방식을 이해하고 있다면 쿼리 요청 시 더 똑똑한 쿼리를 작성할 수 있고 인덱스를 효율적으로 디자인 할 수 있다.
그럼 쿼리를 요청하고 스코어가 어떤 식으로 계산되었는지 알아보기 위해 쿼리에 explain 옵션을 추가하자.
get kibana_sample_data_ecommerce/_search
{
"query":{
"match":{
"products.product_name":"Pants"
}
},
"explain":true
}
검색 시 explain : true 를 추가하면 쿼리 내부적인 최적화 방법과 어떤 경로를 통해 검색 되었으며 어떤 기준으로 스코어가 계산되었는지 알 수 있다.
4.3.1 스코어 알고리즘(BM25) 이해하기
쿼리 컨텍스트로 요청한 응답값을 보면 히트된 도큐먼트는 모두 스코어 값을 갖고 있다.
스코어는 도큐먼트와 쿼리 간의 연관성 수치로, 값이 클수록 연관성이 높다는 것을 의미한다.
엘라스틱 5.X 버전 이하 : TF-IDF
엘라스틱 5.X 버전 이상 : BM25로 변경
TF-IDF(정보검색과 텍스트마이닝에서 이용하는 가중치로, 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치다.)
BM25 → IDF와 TF값을 알면 스코어를 구할수 있다.
4.3.2 IDF 계산
IDF : inverse(역수) document frequency
문서 빈도 : document frequency
문서 빈도는 특정 용어가 얼마나 자주 등장했는지를 의미하는 지표다.
문서의 빈도가 많으면 많을 수록 가중치가 낮다고 판단한다. 즉 중요하지 않는 단어라고 생각한다.
그에 대한 이유 : 불용어 같은 경우에 자주 등장하는 단어라서 중요하지 않는 단어라고 판단한다.
위 식에서 log를 사용한 이유는 문서에 대한 순서가 중요하고 단순 숫자를 비교할 뿐이니 범주화의 상한값과 하한값을 수정해준것이다. log를 사용해서
결론 : 가중치값이 크면 클수록 중요한 단어라고 판단, 가중치값이 작을수록 중요하지않는단어
가중치 : 그러므로 역수를 취한다.

- y = log(1 + (N - n + 0.5) / (n + 0.5))
- n = 3
- N = 4657
4.3.3 TF 계산
TF : term frequency
특정 용어가 하나의 도큐먼트에 얼마나 많이 등장했는지를 의미하는 지표다.
일반적으로 용어가 도큐먼트에서 많이 반복되었다면 그 용어는 도큐먼트의 주제와 연관되어 있을 확률이 높다.
예를들어, 엘라스틱을 주제로 글을 썻다면 엘라스틱이라는 용어가 도큐먼트에서 많이 나오는 이치와 같다.
하나의 도큐먼트에서 특정 용어가 많이 나오면 중요한 용어로 인식하고 가중치를 높인다.
y = ferq/ (freq + k1 (1 - b + bdl) avg dl)
dl 은 필드 길이이고, avgdl 은 전체 도큐먼트에서 평균 필드길이로, dl이 작고 avgdl이 클수록 TF 값이 크게 나온다.
이는 짧은 글에서 찾고자 하는 용어가 포함될수록 가중치가 높다는 뜻이다.
4.4 쿼리
엘라스틱 서치는 검색을 위해 쿼리를 지원하는데, 크게 리프쿼리와 복합쿼리로 나눌수 있다.
리프쿼리는 특정 필드에서 용어를 찾는 쿼리로, 매치, 용어, 범위쿼리등이 있다.
복합쿼리는 쿼리를 조합해 사용되는 쿼리로, 대표적으로 논리쿼리 등이 있다.
4.4.1 전문 쿼리와 용어 수준 쿼리
전문쿼리는 전문 검색을 하기위해 사용되며, 전문 검색을 할 필드는 인덱스 매핑 시 텍스트 타입으로 매핑해야 한다.
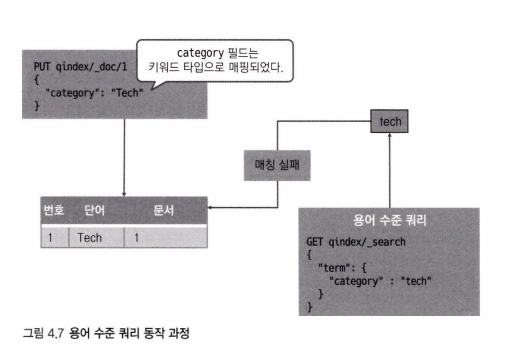
반면, 용어 수준 쿼리는 정확히 일치하는 용어를 찾기 위해 사용되며, 인덱스 매핑 시 필드를 키워드 타입으로 매핑해야한다.
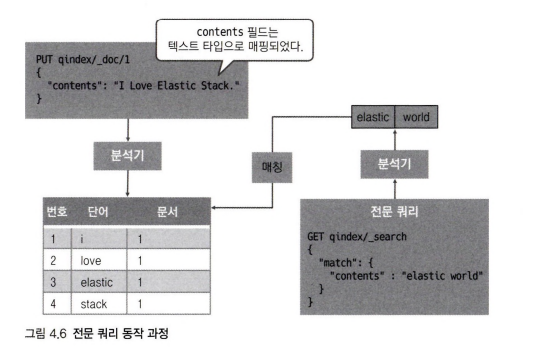
전문 쿼리 : contents token → 서로 match → 검색
ex) 구글, 네이버 검색 시스템
전문 쿼리의 종류 : 매치쿼리, 매치 프레이즈 쿼리, 멀티 매치 쿼리, 쿼리 스트링 쿼리
용어 수준 쿼리는 전문 쿼리와 동작 방식이 조금 다르다.
검색은 용어 쿼리를 사용하는데 검색어 "" 분석기를 거치지 않고 그대로 사용한다.
정확한 용어를 매핑할때만 사용한다.
일반적으로 숫자, 날짜, 범주형 데이터를 정확하게 검색할 때 사용되며 관계형 데이터베이스 where 절과 비슷한 역활을 한다. 용어 수준 쿼리에는 용어 쿼리, 용어들 쿼리,. 퍼지쿼리등이 있다.
4.4.2 매치 쿼리
매치 쿼리는 대표적인 전문 쿼리다. 전문 쿼리는 가장 기본이 되는 쿼리로, 전체 텍스트 중에서 특정 용어나 용어들을 검색할 때 사용한다.
'용어'가 아직 어색하다면 용어를 '단어'로 바꿔서 생각해도 좋다. 매치 쿼리를 사용하기 위해서는 검색하고 싶은 필드를 알아야한다. 필드명을 모르면 쿼리를 진행할 수 없으므로 필드명을 모를경우 GET kibana_sample_data_ecommerce/_mapping으로 인덱스에 포함된 필드가 어떤 것들이 있는지 확인해야 한다.
매치 쿼리를 이용해 전문 검색을 진행해보자.
get kibana_sample_data_ecommerce/_search
{
"_source" : ["customer_full_name"],
"query" : {
"match" : {
"customer_full_name" : "Mary"
}
}
}
customer_full_name 필드에서 Mary 라는 용어가 있는 도큐먼트를 찾아달라는 요청이다.
전문쿼리의 경우 검색어도 토큰화 되기 때문에 검색어는 "Mary"는 [mary]로 토큰화 된다.
분석기 종류에 따라 다르지만 일반적인 분석기를 사용했다면 대문자를 소문자로 변경하기 때문이다.
키바나 콘솔에서 직접 실행해보고 결과를 확인해보자.
customer_full_name 필드에 'mary'가 포함된 모든 도큐먼트를 검색할 것이다.
다음은 복수 개의 용어를 검색해보자.
네이버나 구글에서 여러개의 검색어를 이용해 검색하는 것을 생각하면 된다.
하나의 용어를 검색하는 매치 쿼리
GET kibana_sample_data_ecommerce/_search
{
"_source" : ["customer_full_name"],
"query" : {
"match" : {
"customer_full_name" : "Mary"
}
}
}
복수 개의 용어를 검색하는 매치 쿼리 or
GET kibana_sample_data_ecommerce/_search
{
"_source" : ["customer_full_name"],
"query" : {
"match" : {
"customer_full_name" : "mary bailey"
}
}
}
operator를 and로 설정한 매치 검색
GET kibana_sample_data_ecommerce/_search
{
"_source" : ["customer_full_name"],
"query" : {
"match" : {
"customer_full_name" : {
"query" : "mary bailey",
"operator" : "and"
}
}
}
}
※ 정리
-
하나의 단어를 입력해서 쿼리를 작성하면 그 단어 명사에대한 토큰아이즈를 한후 검색된 결과가 산출된다.
-
두개의 토큰아이즈가 이루어진이후에 쿼리를 작성하면 or 조건을 만족하여 쿼리가 생성된다.
-
and를 사용하고싶으면 원하는 source에 {} 이후 query와 operator를 사용해 and조건을 주어야한다.
- 부연설명으로 아무런 조건을 주지않고 operator를 생성시에는 or값이 default로 된다.
4.4.3 매치 프레이즈 쿼리
매치 쿼리와 마찬가지로 전문 쿼리의 한 종류인 매치 프레이즈 쿼리는 구를 검색할 때 사용한다.
구는 동사가 아닌 2개 이상의 단어가 연결되어 만들어지는 단어다.
여러 단어가 모여서 뜻을 이루는 단어다.
검색하려는 모든 단어가 있어야 하며 단어 순서도 중요하다.
위에서는 하나의 단어를 사용하는 방법을 알았다면 두개의 단어를 합쳐서 검색하는 방법
get kibana_sample_data_ecommerce/_search
{
"_source":["customer_full_name"],
"query":{
"match_phrase" : {
"customer_full_name" : "mary baily"
}
}
}
4.4.4 용어 쿼리
용어 쿼리는 용어 수준 쿼리의 대표적인 쿼리다. 사용 방법은 매치 쿼리와 비슷하지만 큰 차이점이 있다.
매치 쿼리는 전문 쿼리에 속하기 때문에 검색어인 mary bailey 가 분석기에 의해 [mary, bailey]로 토큰화 되고 mary나 bailey가 있는 경우 매칭이 되었다.
반면 용어 검색은 용어 수준 쿼리에 속하기 때문에 검색어인 mary bailey가 분석기에 의해 토큰화되지 않는다.
즉 'mary bailey'라고 정확한 용어가 있는 경우만 매칭이 된다. 분석기를 거치지 않았기 때문에 대소문자도 정확히 맞아야한다.
get kibana_sample_data_ecommerce/_search
{
"_source" :["customer_full_name"],
"query" : {
"term" : {
"customer_full_name" : "Mary Bailey"
}
}
}
해당되는 용어 쿼리의 Mary Bailey는 [mary, bailey]라는 2개로 토큰화 되었는데 용어쿼리는 [Mary Bailey]를 찾기 때문에 매칭되지 않는다.
이번에는 'Mary'로 검색을 해보자
get kibana_sample_data_ecommerce/_search
{
"_source" : ["customer_full_name"],
"query" : {
"term" : {
"customer_full_name" : "Mary"
}
}
}
해당되는 쿼리 역시 도큐먼트를 하나도 찾지 못할 것이다. custommer_full_name은 분석기에 의해 대문자가 소문자로 변경되어 [mary, bailey]로 매핑되어 있지만 용어 쿼리는 [Mary]를 찾기 때문에 매칭이 되지 않는다.
※ 현업에서 가끔 용어 쿼리와 매치쿼리를 구분하지 않고 사용하는 경우가 있는데 용도를 명확히 하는 것이 좋다.
용어 쿼리를 포함한
용어 수준 쿼리 : 키워드 타입으로 매핑된 필드를 대상으로 주로 키워드 검색이나 범주형 데이터를 검색하는 용도로 사용하자.
매치 쿼리를 포함한 전문쿼리 : 텍스트 타입으로 매핑된 필드를 대상으로 전문 검색에 사용해야 한다.
4.4.5 용어들 쿼리
용어들 쿼리는 용어 수준 쿼리의 일종이며 여러 용어들을 검색해준다. 키워드 타입으로 매핑된 필드에서 사용해야 하며, 분석기를 거치지 않았기 때문에 대소문자도 신경 써야 한다.
이번에는 키워드 타입의 필드인 day_of_week 를 이용해 용어들 쿼리를 진행해보자.
get kibana_sample_data_ecommerce/_search
{
"_source" : ["day_of_week"],
"query" : {
"terms" : {
"day_of_week" : ["Monday", "Sunday"]
}
}
}day_of_week 필드는 요일을 표현하는 범주형 필드로, 키워드 타입으로 매핑되어 있는 필드다.
4.4.6 멀티 매치 쿼리
지금까지 쿼리를 이용해 검색할 때는 반드시 필드명을 적어야 했다. 왜냐하면 엘라스틱 서치는 필드를 기준으로 찾으려는 용어나 구절을 검색하기 때문이다. 하지만 가끔 우리는 검색하고자 하는 용어나 구절이 정확히 어떤 필드에 있는지 모르는 경우가 있다. 특히 전문 검색 서비스의 경우라면 더욱 자주 직면하는 문제다.
구글 서치를 생각해보자. 우리는 '트럼프'를 검색할 때 '트럼프'가 어떤 필드에 저장되어 있는지 정확히 알 수 있나. 이럴 경우 하나의 필드가 아닌 여러 개의 필드에서 검색을 해야한다. 여러 개의 필드에서 검색하기 위한 멀티 매치 쿼리는 전문 검색 쿼리의 일종으로, 텍스트 타입으로 매핑된 필드에서 사용하는 것이 좋다.
get kibana_sample_data_ecommerce/_search?explain=true
{
"_source" : ["customer_first_name","customer_last_name", "customer_full_name"],
"query" : {
"multi_match" : {
"query" : "mary",
"fields" : [
"customer_full_name",
"customer_first_name",
"customer_last_name"
]
}
}
}3개 필드에 대해 'mary'라는 용어로 매치 쿼리 → 3개의 필드에서 개별 스코어 추출 → 그중 가장 큰 값을 대표 스코어 산출
4.4.6.1 필드에 가중치 두기
여러 개의 필드 중 특정 필드에 가중치를 두는 방법을 부스팅 기법이라고 하는데 멀티 매치 쿼리에서 자주 사용된다.
부스팅 기법이 필요한 예를 들어보자. '엘라스틱'을 블로그에서 검색한다고 했을 때 '엘라스틱' 이라는 용어가 본문에 있는 것과 제목에 있는 것은 무게가 다르다.
일반적으로 제목에 '엘라스틱' 이라는 용어가 있는 도큐먼트가 더 중요할 가능성이 높은데 이럴 경우 제목 필드에 가중치를 준다. 검색하려는 여러 개의 필드 중 중요한 필드를 알고 있다면 그 필드에 가중치를 줄 수 있다.
get kibana_sample_data_ecommerce/_search
{
"query":{
"multi_match": {
"query" : "mary",
"fields" : [
"customer_full_name^2",
"customer_first_name",
"customer_last_name"
]
}
}
}
특정 필드에 가중치를 줘서 특정 필드의 스코어 값을 n배 해주는 효과를 준다.
customer_full_name^2 와 같이 가중치를 부여하고자 하는 특정 필드에 ^ 기호와 숫자를 적어주면 된다.
위의 경우 customer_first_name 이나 customer_last_name에서 얻은 스코어보다 customer_full_name에서 얻은 스코어가 2배 더 높게 책정된다.
대표 스코어는 각각의 필드에서 얻은 스코어 중에서 가장 큰 스코어로 정한다고 했는데, 이럴 경우 최종 대표 스코언은 customer_full_name에서 얻은 결과를 채택할 확률이 높아진다.
get kibana_sample_data_flights/_search
{
"query" : {
"range" : {
"timestamp":{
"gte" : "2020-12-15",
"lt" : "2020-12-16",
}
}
}
}잘못된 날짜/시간 포맷을 사용하는 경우
get kibana_sample_data_flights/_search
{
"query" : {
"range" : {
"timestamp" : {
"gte" : "2020/12/15"
"lt" : "2020/12/16"
}
}
}
}
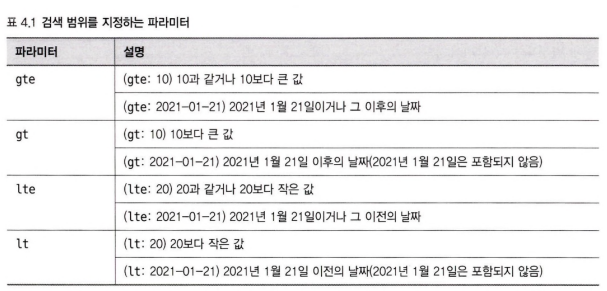
kibana_sample_data_filghts 인덱스의 timestamp 필드는 yyyy-mm-dd 형식의 날짜/시간 포맷을 사용하는데 범위 쿼리에서 날짜/시간 포맷을 yyyy/mm/dd 같은 형식으로 작성하면 날짜 포맷이 맞지 않아서 parse_exception 오류가 발생한다. 그리고 리스트 4.26에서 파라미터로 gte, lt 가 보이는데 이 파라미터는 범위를 지정하는 방식이다. 엘라스틱 서치 범위 쿼리는 네 가지 파라미터를 지원한다.
4.4.7.1 날짜/시간 데이터 타입
범위 쿼리에서 날짜/시간을 표현하는 몇 가지 방식을 더 알아보자. 특히 날짜/시간 검색은 현재 시간을 기준으로 하는 경우가 많다.
일주일 전 도큐먼트들이나 하루 전 도큐먼트들을 골라내서 쿼리를 진행하고 싶을 경우 더 편리하게 검색할 수 있는 표현식이 존재한다.
get kibana_sample_data_flights/_search
{
"query" : {
"range" : {
"timestamp" : {
"gte" : "now-1M"
}
}
}
}
해당되는 쿼리는 timestamp 필드에서 현재 시각 기준으로 한 달 전까지의 모든 데이터를 가져오는데, 현재 시각을 기준으로 날짜/시간 범위를 직관적으로 이해할 수 있다.
또한 오늘 날짜/시간을 직접 입력하지 않기 때문에 시스템 운영 시 유연하게 대처할 수 있다.
날짜/시간 관련 표현식이 몇 가지 있는데, 현재 시각을 2021-01-21T15:20:33 이라고 가정하고 표현식에 따라 시간이 어떻게 변경되는지 살펴보자.

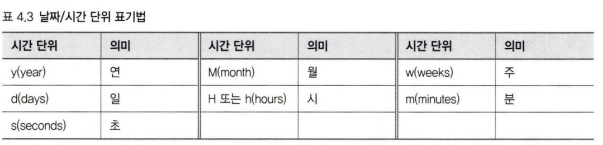
4.4.7.2 범위 데이터 타입
엘라스틱 서치 데이터 타입 중 범위 데이터 타입이 있다. 말 그대로 범위 데이터를 저장할 수 있는 타입이다.
범위 데이터 타입은 integer_range, float_range, long_range, double_range, ip_range 총 여섯 가지 타입을 지원한다.
키바나에서 제공하는 샘플 인덱스에는 범위 데이터 타입이 없기 때문에 간단한 예제를 만들어서 확인해야한다.
put range_test_index
{
"mappings" : {
"properties" : {
"test_date" : {
"type" : "date_range"
}
}
}
}
test_date 필드는 날짜/시간 타입이 아니고 날짜/시간 범위 타입인데 헷갈리지 않아야 한다.
relation에 들어 갈 수 있는 값들

날짜/시간 범위가 아닌 숫자 범위를 이용해 설명한다.
4.4.8 논리쿼리
논리쿼리는 복합쿼리로, 앞에서 배웠던 쿼리를 조합할 수 있다. 예를 들어보자. 2021년 1월 21일 에 생성된 로그 중에서 상태가 불량인 것들을 검색하거나, 서울 지역에서 발생한 데이터이면서 제주도 지역에서 발생하지 않은 데이터를 검색해야하는 경우 앞에서 배웠던 매치 쿼리나 용어 쿼리 단독으로는 검색할 수 없고 쿼리들을 조합해야한다.
논리 쿼리는 쿼리를 조합할 수 있도록 4개의 타입을 지원한다.
논리쿼리 작성 포맷과 지원하는 타입들
get <index>/_search
{
"query" : {
"bool" : {
"must" : [
{쿼리문}, ....
],
"must_not" : [
{쿼리문}, ....
],
"should" : [
{쿼리문}, ....
],
"filter" : [
{쿼리문}, ....
],
}
}
}
4개 타입 아래에서 전문 쿼리나 용어 수준 쿼리, 범위 쿼리, 지역 쿼리 등을 사용할 수 있다.
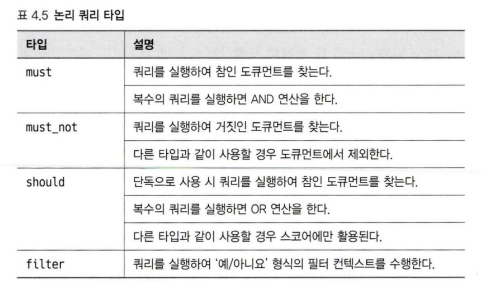
4.4.8.1 must 타입
must 타입은 쿼리를 실행하고 참인 도큐먼트를 찾는다. 먼저 아래 쿼리를 살펴보자.
get kibana_sample_data_ecommerce/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {"customer_first_name" : "mary"}
}
}
}
}customer_first_name 필드에서 mary가 들어간 도큐먼트를 검색한다. match 쿼리는 전문 검색을 위한 쿼리로, customer_first_name 에 mary 가 들어 있는 모든 도큐먼트를 찾는다. must 타입에 복수 개의 쿼리를 실행하면 AND 효과를 얻을 수 있다.
복수 개의 쿼리를 사용한다면 대괄호를 이용한다.
get kibana_sample_data_ecommerce/_search
{
"_source" : ["day_of_week", "customer_full_name"],
"query" : {
"bool" : {
"must" : [
{"term" : { "day_of_week" : "Sunday"}},
{"match" : {"customer_full_name" : "mary" }}
]
}
}
}
AND 조건에 의해 day_of_week 가 sunday이면서 customer_full_name에 mary가 들어간 도큐먼트들만 검색된다.
손쉽게 용어 쿼리와 전문쿼리를 AND 연산으로 조합할 수 있다.
4.4.8.2 must_not 타입
must_not 타입은 도큐먼트에서 제외할 쿼리를 실행한다. 직접 쿼리를 실행해서 확인해보자.
get kibana_sample_data_ecommerce/_search
{
"query" : {
"bool" : {
"must_not" : {
"match" : {"customer_full_name" : "mary"}
}
}
}
}
다른 타입과 must_not 타입을 함께 사용하는 경우
get kibana_sample_data_ecommerce/_search
{
"_source":["customer_full_name"],
"query" : {
"bool" : {
"must" : {
"match" : {"customer_first_name" : "mary"}
},
"must_not" : {
"term" : {"customer_last_name" : "bailey"}
}
}
}
}4.4.8.3 should 타입
shold 타입에 하나의 쿼리를 사용한다며 must 타입과 같은 결과를 얻는다.
하나의 쿼리를 사용하는 sholud 타입
get kibana_sample_data_ecommerce/_search
{
"query" : {
"bool" : {
"should" : {
"match" : { "customer_first_name" : "mary" }
}
}
}
}
복수 개의 쿼리를 사용하는 should 타입
get kibana_sample_data_ecommerce/_search
{
"_source":["day_of_week", "customer_full_name"],
"query" : {
"should" : [
{"term" : {"day_of_week" : "sunday"}},
{"match" : {"customer_full_name" : "mary"}}
]
}
}day_of_week 가 sunday 이거나 customer_full_name에 mary가 들어가 있는 도큐먼트를 찾는 다
즉 and 조건을 진행한다.
must 타입만 단독으로 사용하는 쿼리
get kibana_sample_data_ecommerce/_search
{
"_source" : ["customer_full_name", "day_of_week"],
"query" : {
"bool" : {
"must" : {
"match" : {"customer_full_name" : "mary"}
}
}
}
}
customer_full_name 에 mary 가 들어간 모든 도큐먼트를 검색한다.
must와 should 타입을 같이 사용하는 쿼리
get kibana_sample_data_ecommerce/_search
{
"_source" : ["customer_full_name", "day_of_week"],
"query" : {
"bool" : {
"must" : {
"match" : {"customer_full_name" : "mary"}
},
"should" : {
"term" : {"day_of_week" : "Monday"}
}
}
}
}customer_full_name 에 mary가 들어간 모든 도큐먼트를 검색하는데
day_of_week가 Monday인 도큐먼트들의 우선순위를 높인다.
4.4.8.4 fillter 타입
fillter는 must와 같은 동작을 하지만 필터 컨텍스트로 동작하기 때문에 유사도 스코어에 영향을 미치지 않는다. 즉, 예/아니오 두 가지 결과만 제공할 뿐 아니라 유사도를 고려하지 않는다.
하나의 쿼리를 사용하는 fillter 타입
get kibana_sample_data_ecommerce/_search
{
"_source" : ["products.base_price"],
"query" : {
"bool" : {
"fillter" : {
"range" : {
"products.base_price" : {
"get" : 30,
"lte" : 60
}
}
}
}
}
}
해당 로직은 스코어가 계산되지 않아서 0.0 으로 표시되었고 products.base_price 가 30이상 60이하인 모든 도큐먼트가 검색되었다.
fillter와 must 타입을 같이 사용하는 쿼리
get kibana_sample_data_ecommerce/_search
{
"_source" : ["day_of_week", "customer_full_name"],
"query" : {
"bool" : {
"filter" : {
"term" : {"day_of_week" : "Sunday"}
},
"must" : {
"match" : {"customer_full_name" : "mary"}
}
}
}
}
day_of_week가 sunday 인 도큐먼트를 먼저 필터링하고 다음으로 customer_full_name이 mary인 도큐먼트를 검색한다.
day_of_week는 필터 절에 포함되었는 필터를 통해 불필요한 스코어 계산을 줄여 검색 성능을 높일 수 있다.
4.4.9 패턴검색
검색하려는 검색어가 길거나 검색어를 정확히 알지 못하는 경우가 있다. 검색어의 대략적인 키워드나 몇개의 알파벳만 알고 있다면 패턴을 이용해 검색을 할 수 있다. 패턴을 이용한 검색은 와일드 카드를 사용하는 와일드카드 쿼리와 정규표현식을 사용하는 정규식 쿼리, 두 가지 방법이 존재한다.
- 검색하려는 검색어가 길거나 정확히 알지 못할때
- 패턴을 이용한 검색
- 와일드카드 쿼리
- 정규식 쿼리
- 패턴을 이용한 검색
4.4.9.1 와일드카드 쿼리
와일드 카드는 용어를 검색 할 때 *, ? 라는 두 가지 기호를 사용할 수 있다
- : 는 공백까지 포함하여 글자수에 상관없이 모든 문자를 매칭할 수 있고
- ? : 는 오직 한문자만 매칭할 수 있다.
※ 두가지 기호를 사용할 경우 속도가 매우 느려지기 때문에 검색어 앞에는 사용하지 않아야 한다.
와일드카드 패턴 검색 양식
GET kibana_sample_data_ecommerce/_search
{
"_source" : "customer_full_name",
"query" : {
"wildcard" : {
"customer_full_name.keyword" : "M?r*"
}
}
}
customer_full_name 은 텍스트 타입과 키워드 타입을 갖는 멀티 필드로
우리는 customer_full_name.keyword 라는 키워드 타입의 필드에서 와일드 카드 패턴을 적용할 것이다.
첫번째 : M
두번째 : (반드시) 하나의 문자
세번쨰 : r
마지막 : 글자수에 상관없이 공백이나 어떤 문자가 와도된다.
ex) 'Mary', "Mar", "Mora dory" 같은 용어가 매칭된다.
4.4.9.2 정규식 쿼리
정규식은 특정한 매턴을 가진 문자열을 표현하기 위한 형식 언어다.
와일드 카드를 사용한 *, ? 기호가 정규식에서는 쓰임이 다르다는 것이다.
여기서 자주 사용하는 몇가지 표현식만 간단히 소개하겠다.
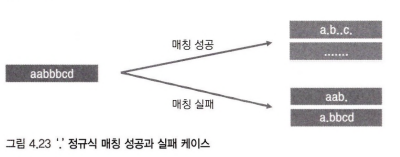
점(.) 기호 정규식의 매칭 성공과 실패 케이스다. 점(.)은 하나의 문자를 의미하고 어떤 문자가 와도 상관없이 매칭되었다고 판단한다.
첫번째, 두번째 케이스는 성공 케이스다.
세번쨰, 네 번쨰는 문자 길이가 맞지 않아서 실패한 케이스이다.
사용벙법
get kibana_sample_data_ecommerce/_search
{
"query" : {
"regexp" : {
"customer_first_name.keyword" : "Mar."
}
}
}
4.5 정리
엘라스틱 서치의 기본적인 검색방법
- 쿼리/필터 컨텍스트
- 쿼리 : 검색어와 연관성이 높은 도큐먼트들을 매칭
- 필터 : 검색어의 참/거짓 형태로 매칭
- 검색 효율을 높이기 위해서는, 필터와 쿼리를 잘 조합해야한다.
- 쿼리의 속도를 높이고 싶다면 필터 컨텍스트를 적극 활용
- BM25라는 스코어 계산 알고리즘
- DSL
- 전문 쿼리와 용어 수준 쿼리의 차이점
