
엘라스틱 서치 : 집계
엘라스틱서치에서 집계는 데이터를 그룹핑 하고 통계값을 얻는 기능으로 SQL의 GROUP BY와 통계 함수를 포함하는 개념이다.
이를테면 데이터를 날짜별로 묶거나 특정 카테고리별로 묶어 그룹별로 통계를 내는 식이다.
이런 집계 기능은 강력한 검색 성능과 맞물려 엘라스틱 서치를 고성능 집계 엔진으로 활용할 수 있게 해주는데, 대표적인 활용 사례로 키바나를 들 수 있다.
키바나의 주 기능인 데이터 시각화와 대시보드는 대부분 집계 기느을 기반으로 동작하며, 집계를 제대로 이해 할수록 키바나라는 툴을 더 잘 사용할 수 있다.
- 메트릭 집계
- 버킷 집계
- 파이프라인 집계
5.1 집계의 요청 - 응답 형태
집계를 위한 특별한 API를 제공되는 것은 아니며, search API의 요청 본문에 aggs 파라미터를 이용하면 쿼리 결고에 대한 집계를 생성할 수 있다.
집계를 위한 기본 형태
get <인덱스>/_search
{
"aggs" : {
"my_aggs" : {
"agg_type" : {
....
}
}
}
}
aggs : 는 집계 요청을 하겠다는 의미다.
my_aggs : 사용자가 지정하는 집계 이름이다.
agg_type : 집계 타입이다.
- 메트릭 집계
- 통계나 계산
- 버킷 집계
- 도큐먼트를 그룹핑하는데 사용한다.
집계 응답 기본 형태
{
"hist" : {
"total" : {
....
},
"aggregations" : {
"my_aggs" : {
"value" :
}
}
}
}aggregations는 이 응답 메시지가 집계 요청에 대한 결과임을 알려준다.
my_agg는 리스트 5.1는 집계 이름으로 사용자가 지정한 이름이다.
value는 실제 집계 결과다.
요청한 집계의 계층, 타입, 구성에 따라 결과의 형태는 변할 수 있다.
복잡하지 않으므로, 긴 설명보다 앞으로 나오는 예시들을 따라 해보면서 집계 요청-응답 형태를 이해해보자.
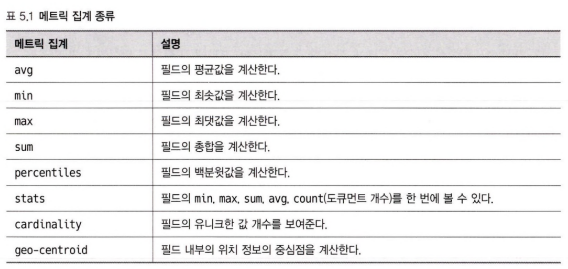
5.2 메트릭 집계
메트릭 집계는 필드의 최소/최대/합계/평균/중간값 같은 통계 결과를 보여준다.
필드의 타입에 따라서 사용 가능한 집계 타입에 제한이 있다.
대표적으로 텍스트 타입 필드는 합계나 평균과 같은 수치 연산을 계산할 수 없다.
지리 정보가 있는 필드를 위한 집계도 존재한다.
5.2.1 평균값/중간값 구하기
메트릭 집계의 가장 기본은 통계 작업이다. 그중 최소/최대/합계/평균/중간값 등을 구하는 매트릭 집계는 기본이면서도 많이 사용된다.
먼저 특정 필드의 평균값을 구하는 집계 요청을 작성하면
get kibana_sample_data_ecommerce/_search
{
"size" : 0,
"aggs" : {
"stats_aggs" : {
"avg" : {
"field" : "products.base_price"
}
}
}
}
백분위를 구하는 집계 요청
get kibana_sample_data_ecommerce/_search
{
"size" : 0,
"aggs" : {
"stats_aggs" : {
"percetiles" : {
}
}
}
}
5.2.2 필드의 유니크한 값 개수 확인하기
필드의 유니크한 값들의 개수를 확인하는 집계도 있다.
카디널리티 집계 : 필드의 중복된 값들은 제외하고 유니크한 데이터의 개수만 보여준다.
SQL : distinct count 와 동일하다.
카디널리티 집계 요청
get kibana_sample_data_ecommerce/_search
{
"size" : 0,
"aggs" : {
"cardi_aggs" : {
"cardinality" : {
"field" : "day_of_week",
"percision_threshold" : 100
}
}
}
}
day_of_week 필드의 유니크한 데이터 개수를 요청한다.
카디널리티 집계에서 사용하는 precsion_threshold 파라미터는 정확도 수치라고 이해하자.
값이 크면 정확도가 올라가는 대신 시스템 리소스를 많이 소모하고,
값이 작으면 정확도는 떨어지는 대신 시스템 리소스를 덜 소모한다.
percision_threshold : 5로 변경시에 잘못된 결과(value)를 알려준다.
해당되는 정확도를 높이면서 적은리소스를 갖는 값을 찾아야한다.
즉, percision_threshold 값을 변경해보면서 값이 변경되지 않는 임계점을 찾는것도 방법이다.
기본값은 3000이며, 최대 40000까지 값을 설정할 수 있다.
버킷 집계의 일종인 용어집계를 사용하면 유니크한 필드 개수와 함께 필드값들을 확인할 수 있다.
용어 집계 요청
get kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"cardi_aggs":{
"terms":{
"field":"day_of_week"
}
}
}
}
day_of_week 필드의 유니크한 값들을 보여준다.
필드 내부의 유니크한 값을 표현해주면서 유니크한 각 값의 도큐먼트 개수도 보여준다.
예상했던 것처럼 day_of_week 필드의 유니크한 값은 요일명이다.
doc_count는 각각의 유니크한 필드를 가진 도큐먼트의 개수다.
용어 집계를 이용하면 필드의 유니크한 데이터 개수와 데이터 종류를 확인할 수 있다.
5.2.3 검색 결과 내에서의 집계
검색쿼리와 함께 집계를 사용하는 방법을 알아보자.
day_of_week가 Monday인 도큐먼트만으로 메트릭 집계를 수행한다고 생각해보자.
집계 작업을 하기전에 특정 도큐먼트만 선별하고 그 결과를 토대로 집계 작업을 수행해야 할 것이다.
쿼리를 이용해 집계 범위 지정
get kibana_sample_data_ecommerce/_search
{
"size":0,
"query":{
"term":{
"day_of_week":"Monday"
}
},
"aggs":{
"query_aggs":{
"sum":{
"field":"products.base_price"
}
}
}
}
집계를 하기 전에 쿼리를 통해 도큐먼트 범위를 제한했다.
용어 수준 쿼리인 용어 쿼리를 이용해 day_of_week 필드 값이 "Monday"인 도큐먼트만을 일차적으로 골라내고 이 도큐먼트만을 가지고 query_aggs라는 이름으로 products.base_price 필드의 합을 집계한다.
get kibana_sample_data_ecommerce/_search
{
"size":0,
"query":{
"term" : {
"day_of_week":"Monday"
}
},
"aggs":{
"query_aggs":{
"sum":{
"field":"product.base_price"
}
}
}
}
5.3 버킷 집계
메트릭 집계가 특정 필드를 기준으로 통계값을 계산하려는 목적
버킷 집계는 특정 기준에 맞춰 도큐먼트를 그룹핑하는 역할
버킷은 도큐먼트가 분할되는 단위로 나뉜 각 그룹을 의미한다.

5.3.1 히스토그램 집계
히스토그램 집계는 숫자 타입 필드를 일정 간격 기준으로 구분해주는 집계다.
히스토그램 집계 요청
get kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"histogram_aggs":{
"histogram":{
"field":"products.base_price",
"interval":100
}
}
}
}
histogram_aggs 집계 이름을 지정했고, 집계 타입은 히스토그램 집계이며 파라미터로 집계를 진행할 대상 필드명과 간격을 설정하는데 products.base_price 필드값을 100간격으로 구분했다.
key가 0은 필드값이 0~99 사이의 값임을 의미한다.
doc_count는 버킷에 속한 도큐먼트가 하나 있음을 알 수 있다.
히스토그램 집계와 비슷한 날짜 히스토그램 집계도 있다.
날짜 / 시간 필드를 사용한다는 점과 간격이 숫자가 아닌 날짜/시간이라는 점이 다르다.
5.3.2 범위 집계
히스토그램 집계는 설정이 간단하지만 각 버킷의 범위를 동일하게 지정할 수 밖에 없다는 단점이 있다.
범위 집계를 이용하면 각 버킷의 범위를 사용자가 직접 설정할 수 있다.
범위 집계 요청
get kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"range_aggs":{
"range":{
"field":"products.base_price",
"ranges":[
{"from":0,"to":50},
{"from":50,"to":100},
{"from":100,"to":200},
{"from":200,"to":1000}
]
}
}
}
}5.3.3 용어 집계
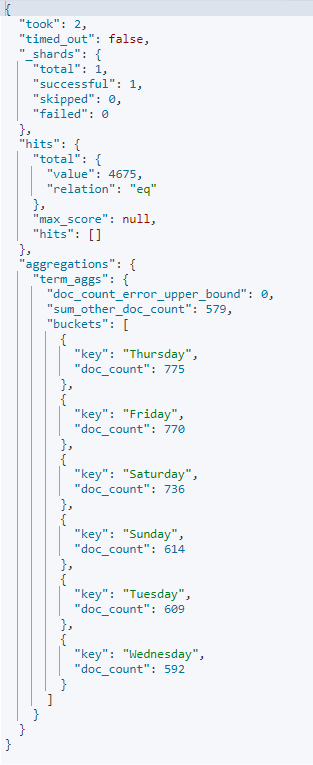
용어 집계는 필드의 유니크한 값을 기준으로 버킷을 나눌 때 사용된다.
용어 집계 요청
get kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"term_aggs":{
"terms":{
"field":"day_of_week",
"size":6
}
}
}
}
-
doc_count_error_upper_bound 는 버킷이 잠재적으로 카운트 하지 못할 도큐먼트의 수이다.
-
sum_other_doc_count 는 버킷이 있지만 size 때문에 보이지 않는 도큐먼트의 수이다.
5.3.3.2 용어 집계 정확성 높이기
용어 집계에서 오류가 발생할 수 있다는 제약 사항을 이해했다면, 정확성을 높이기 위한 방법을 알아보자.
앞서 용어 집계는 분산 시스템 환경에서 오류가 발생할 수 있다고 이야기했다.
고속 처리를 위한 리소스와 속도 간 트레이드오프의 일환으로 리소스 소비량을 늘리면 정확도를 높일 수 있다.
용어 집계 오류 확인 요청
get kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"term_aggs":{
"terms":{
"field": "day_of_week",
"size":6,
"show_term_doc_count_error":true
}
}
}
}각 버킷마다 doc_count_error_upper_bound 값이 나오고 0이 나오면 오류가 없다는 뜻이다.
우리는 샤드를 하나만 사용하고 있고 대용량 작업이 아니므로 현재 특별한 오류는 찾을 수 없지만,버킷마다 잠재적인 오류 가능성을 확인할 수 있다.
만약 확인 결과 이상값이 나올 경우에는 이를 해결하기 위해 다음과 같이 샤드 크기 파라미터를 늘릴 필요가 있다.
용어 집계 시 샤드 크기를 늘린 요청
get kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"term_agss":{
"terms":{
"field":"day_of_week",
"size":6,
"shard_size":100
}
}
}
}
5.4 집계의 조합
메트릭 집계로 특정 필드들의 통계를 구할 수 있고 버킷 집계를 이용해 도큐먼트를 그룹핑할 수 있음을 배웠다.
관계형 데이터베이스에서 GROUP BY로 그룹핑한 다음에 통계 함수를 사용하는 것 처럼 버킷 집계와 메트릭 집계를 조합하면 다양한 그룹별 통계를 계산할 수 있다.
집계를 조합하는 방법을 배워보자.
5.4.1 버킷 집계와 메트릭 집계
집계의 가장 기본적인 형태는 버킷 집계로 도큐먼트를 그룹핑한 후에 각 버킷 집계별 메트릭 집계를 사용하는 것이다.
버킷 집계와 메트릭 집계를 동시에 요청해보자.
버킷 집계 후 메트릭 집계 요청
get kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"term_aggs":{
"terms":{
"field":"day_of_week",
"size":5
},
"aggs":{
"avg_aggs":{
"avg":{
"field":"products.base_price"
}
}
}
}
}
}
버킷 집계와 매트릭 집계를 조합했다.
먼저 term_aggs 라는 용어 집계를 사용해 요일별로 버킷을 나누는데 상위 5개의 버킷만 사용한다.
그리고 들여쓰기를 확인해보면 메트릭 집계인 평균 집계(avg_aggs)는 용어 집계(term_aggs)내부에서 호출된다.
즉 용어 집계로 상위 5개의 버킷을 만들고 각각의 버킷 내부에서 products.base_price 필드의 평균값을 구한다.
버킷 내부에서 평균 외에 총합, 최소, 최대 같은 다양한 통계 데이터를 보고 싶은 경우가 있다.
버킷 집계 후 다수의 메트릭 집계 요청
get kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"term_aggs":{
"field":"day_of_week",
"size":5
},
"aggs":{
"avg_aggs":{
"avg":{
"field":"products.base_price"
},
"sum_aggs":{
"sum":{
"field":"products.base_price"
}
}
}
}
}
}
버킷마다 메트릭 집계의 평균과 합계가 보이는 것을 알수 있다.
5.4.2 서브 버킷 집계
서브 버킷은 버킷 안에서 다시 버킷 집게를 요청하는 집계다.
버킷 집계로 버킷을 생성한 다음 버킷 내부에서 다시 버킷 집계를 하는데, 트리 구조를 떠올리면 된다.
간단한 서브 버킷을 만들어보자.
서브 버킷 생성 요청
get kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"histogram_aggs":{
"histogram":{
"field":"products.base_price",
"interval":100
},
"aggs":{
"term_aggs":{
"terms":{
"field":"day_of_week",
"size":2
}
}
}
}
}
}
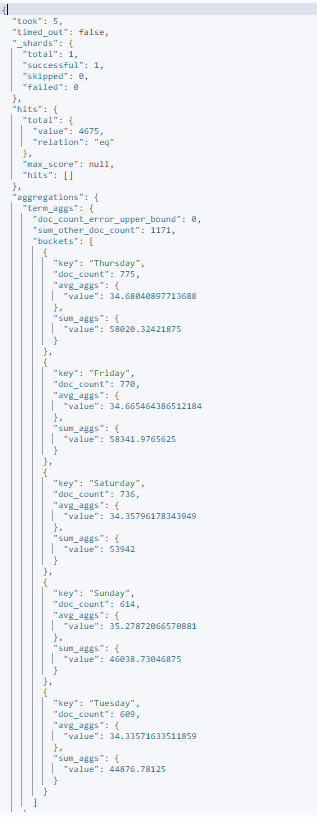
products.base_price를 100단위 버킷으로 나눈 다음 그 안에서 다시 요일별 버킷으로 나누었다.
서브 버킷은 2단계를 초과해서 만들지 않는 편이 좋다.
서브 버킷을 많이 만들수록 버킷의 수는 기하급수적으로 늘어 날 수 있으므로 주의하자.
집계의 성능이 느려질 뿐만 아니라 클러스터에 과도한 부하를 가하게 될 수 있다.
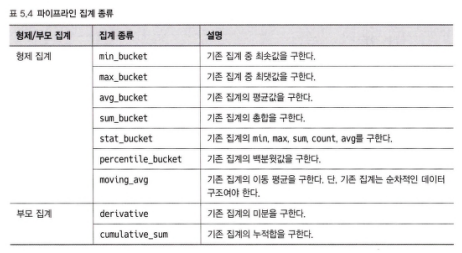
5.5 파이프라인 집계
파이프라인 집계는 이전 결과를 다음 단계에서 이용하는 파이프라인 개념을 차용한다.
엘라스틱 파이프라인 집계는 이전 집계로 만들어진 결과를 입력으로 삼아 다시 집계하는 방식이다.
부모집계와 형제 집계라는 두가지 유형이 있다.
두 집계의 가장 큰 차이점은 집계가 작성되는 위치다.

5.5.1 부모집계
파이프라인 집계는 이전 집계 결과를 입력으로 사용하는 집계라고 이야기 했다.
즉 부모 집계는 단독으로 사용할 수 없고 반드시 먼저 다른 집계가 있어야 하며, 그 집계 결과를 부모 집계가 사용한다.
그리고 부모 집계는 이전 집계 내부에서 실행한다.
그리고 결괏값도 기존 집계 내부에서 나타난다.
누적합을 구하는 부모 집계를 만들어보면서 이해해보자.
누적합을 구하는 부모 집계 요청
get kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"histogram_aggs":{
"histogram" :{
"field" : "products.base_price",
"interval":100
},
"aggs":{
"sum_aggs":{
"sum" :{
"field":"taxful_total_price"
}
},
"cun_sum":{
"cumulative_sum":{
"buckets_path":"sum_aggs"
}
}
}
}
}
}
해당 되는 로직은 누적합을 구하는 부모집계이다.
-
부모집계를 사용하기 위해서는 입력으로 다른 집계가 필요한데, 여기서는 히스토그램 집계와 합계 집계를 사용한다.
-
먼저 products.base_price를 100 기준으로 버킷을 나누고 각 버킷에서 texful_total_price의 합을 구하는 집계가 있다.
-
부모 집게는 합계 집계를 입력으로 받아 최종적으로 각 버킷의 누적합을 계산한다.
-
파이프라인 집계는 반드시 버킷 경로를 입력해야하는데, 입력으로 사용했던 sum_aggs 집계를 적으면된다.
5.5.2 형제 집계
부모 집계는 기존 집계 내부에서 집계 작업을 한다고 했다.
반면 형제 집계는 기존 집계 내부가 아닌 외부에서 기존 집계를 이용해 집계 작업을 한다.
형제 집게 중 총합 버킷을 실제로 요청해보면서 형제 집계를 이해해보자.
get kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"term_aggs":{
"terms" :{
"field":"day_of_week",
"size":2
},
"aggs":{
"sum_aggs":{
"sum":{
"field":"products.base_price"
}
}
}
},
"sum_total_price":{
"sum_bucket":{
"buckets_path":"term_aggs>sum_aggs"
}
}
}
}
먼저 term_aggs는 용어 집계로 day_of_week 필드를 기준으로 요일별 버킷을 나눈다.
size가 2이기 때문에 상위 2개의 버킷을 생성하고 sum_aggs에서 products.base_price 필드의 총합을 구한다.
다음으로 sum_backet 형제 집계를 이용해 기존 버킷별 합을 구한 집계를 다시 합친다.
파이프라인 집계는 버킷 경로를 입력해야 하는데, 누적합 집계와 다르기 '>'기호가 들어간다.
버킷 경로에서 '>'는 하위 집계 경로를 나타낼 때 사용된다.
5.6 정리
엘라스틱 집계에 대하여 알아봤다.
집계는 검색과 함께 엘라스틱 서치에서 자주 사용되는 기능 중 하나 이며 키바나 시각화에서는 반드시 필요하다.
집계는 크게 메트릭 집게와 버킷 집계로 나눌수 있다.
메트릭 집게는 수치 계산이나 통계 작업을 수행하며, 버킷 집계는 특정 기준으로 도큐먼트를 그룹핑한다.
버킷으로 그룹핑하기 위해서는 범주형 필드를 이용해야 하며, 버킷 집게 중 용어 버킷은 분산 시스템에서 오류 발생 가능성이 높은데 이를 해결하는 방법도 알아봤다.
그리고 메트릭 집계와 버킷 집게를 조합하는 방법
집계 작업 전에 쿼리를 이용해 불필요한 도큐먼트는 제외하고 서브 버킷을 두어 효율적으로 그룹핑하는 법도 익혔다.
마지막으로 파이프라인 집계를 배웠다.
파이프라인 집계는 부모 집계와 형제 집게로 나뉘는데, 부모 집계는 기존 집계 내부에서 작업해야 하는 누적합,
분산 계산 같은 작업에 쓰이며 형제 집게는 기존 집게 외부에서 전체 버킷의 총합/평균/최소/최대 계산 같은 작업에 쓰인다.
