
7) 변수
변수(variable)
변수(variable)란 데이터(data)를 저장하기 위해 프로그램에의해 이름을 할당받은 메모리 공간을 의미합니다.
즉, 변수란 데이터(data)를 저장할 수 있는 메모리 공간을 의미하며, 이렇게 저장된 값은 변경될 수 있습니다.
변수의 이름 생성 규칙
자바에서는 변수뿐만 아니라 클래스, 메소드 등의 이름을 짓는데 반드시 지켜야 하는 공통된 규칙이 있습니다.
자바에서 이름을 생성할 때에 반드시 지켜야 하는 규칙은 다음과 같습니다.
-
변수의 이름은 영문자(대소문자), 숫자, 언더스코어(_), 달러($)로만 구성할 수 있습니다.
-
변수의 이름은 숫자로 시작할 수 없습니다.
-
변수의 이름 사이에는 공백을 포함할 수 없습니다.
-
변수의 이름으로 자바에서 미리 정의된 키워드(Keyword)는 사용할 수 없습니다.
변수의 이름은 해당 변수에 저장될 데이터의 의미를 잘 나타내도록 짓는 것이 좋습니다.
변수의 종류
자바에서 변수는 타입에 따라 크게 다음과 같이 구분할 수 있습니다.
- 기본형(primitive type)변수
- 참조형(reference type)변수
기본형(primitive type)변수는 실제 연산에 사용되는 변수 입니다.
자바에서는 다음과 같이 8가지 종류의 기본형 변수를 제공하고 있습니다.
- 정수형 : byte, short, int, long
- 실수형 : float, double
- 문자형 : char
- 논리형 : boolean
자바에서 제공하는 기본 타입에 대한 더 자세한 사항은 자바 기본 타입 수업에서 확인할 수 있습니다.
참조형 변수는 8개의 기본형 변수를 사용하여 사용자가 직접 만들어 사용하는 변수를 의미합니다.
변수의 선언
자바에서는 변수를 사용하기 전에 반드시 먼저 변수를 선언하고 초기화해야 합니다.
변수를 선언하는 방법에는 다음과 같이 두가지 방법이 있습니다.
- 변수의 선언만 하는 방법
- 변수의 선언과 동시에 초기화 하는 방법
변수의 선언만 하는 방법
이 방법은 먼저 변수를 선언하여 메모리 공간을 할당받고, 나중에 변수를 초기화하는 방법입니다.
하지만 이렇게 선언만 된 변수는 초기화 되지 않았으므로, 해당 메모리 공간에는 알 수 없는 쓰레기 값만이 들어가 있습니다.
따라서 선언만 된 변수는 반드시 초기화한 후에 사용해야만 합니다.
자바에서는 프로그램의 안전성을 위해 초기화하지 않은 변수는 사용할 수 없도록 하고 있습니다.
만약 초기화되지 않은 변수를 사용하려고 하면, 자바 컴파일러는 오류를 발생시킬 것 입니다.
<문법>
타입 변수이름;
<예제>
int num; // 변수선언
System.out.printIn(num); // 오류발생
num = 20; // 변수의 초기화
System.out.printIn(num); // 20
위의 예제처럼 정수를 저장하기 위한 메모리 공간을 할당 받으면, 반드시 해당 타입의 데이터만을 저장해야 합니다.
만약 다른 타입의 데이터를 저장하려고 하면, 자바 컴파일러는 오류를 발생시킬 것 입니다.
변수의 선언과 동시에 초기화 하는 방법
자바에서는 변수의 선언과 동시에 그 값을 초기화 할 수 있습니다.
또한, 선언하고자 하는 변수들의 타입이 같다면 이를 동시에 선언할 수도 있습니다.
<문법>
1. 타입 변수 이름[, 변수이름];
2. 타입 변수 이름 = 초깃값[, 변수이름 = 초깃값];
<예제>
int num1, num2; // 같은 타입의 변수를 동시에 선언함
double num3 = 3.14; // 선언과 동시에 초기화 함
double num4 = 1.23, num5 = 4.56 // 같은 타입의 변수를 동시에 선언하면서 초기화 함
선언하고자 하는 변수의 타입이 서로 다르면 동시에 선언할 수 없습니다.
하지만 다음 예제처럼 여러 변수를 동시에 초기화 할 수는 없습니다.
만약 다음 예제처럼 변수의 초기화를 동시에 하려고 하면, 자바컴파일러는 오류를 발생시킬 것 입니다.
<잘못된 예제>
double num1, num2; // 같은 타입의 변수를 동시에 선언함
....
num1 = 1.23, num2 = 4.56; // 하지만 이미 선언된 여러 변수를 동시에 초기화 할 수 는 없음
참고 Intialization (초기화)의 사전적 의미
영어로는 "Intialization" 입니다.
구글 사전 결과 : "작업을 시작하기 위해서 값을 설정하거나 넣는 것, 포맷(컴퓨터 디스크)" 이라는 뜻 이라고 합니다.
뭔가... 되돌리는 느낌이랑 완전 반대입니다. (우리의 상식에서는 포맷이라는 느낌)
애초에 아무것도 없기 때문에 뭔가 넣어주는 느낌입니다.
위키피디아 검색 결과 : "컴퓨터 프로그래밍에서 초기화는 데이터 객체 혹은 변수를 위해서 초기값을 지정해주는 것 "이라고 나와있습니다.
즉, 값으 지정해주는것 -> 초기화를 하게 되면 JVM(자바가상서버)이 Heap 메모리에 주소를 할당을 하게 됩니다.
8) 상수
상수(constant)
상수(constant)란 변수와 마찬가지로 데이터를 저장할 수 있는 메모리 공간을 의미합니다.
하지만 상수가 변수와 다른 점은 프로그램이 실행되는 동안 메모리에 저장된 데이터를 변경할 수 없다는 점 입니다.
상수(constant)
상수는 변수와 마찬가지로 이름을 가지고 있는 메모리 공간으로, 이러한 상수는 선언과 동시에 반드시 초기화해야 합니다.
C++ 에서는 const 키워드를 사용하여 상수를 선언하지만, 자바에서는 final 키워드를 사용하여 선언합니다.
자바에서 상수를 만드는 일반적인 방식은 다음과 같습니다.
<예제>
final int AGES = 30;
위의 예제처럼 final 키워드를 사용한 상수는 선언과 함께 반드시 초기화 해야합니다.
자바에서 상수의 이름은 일반적으로 모두 대문자를 사용하여 선언합니다.
또한, 여러 단어로 이루어진 이름의 경우에는 언더스코어(_)를 사용하여 구분합니다.
리터럴(literal)
리터럴(literal)이란 그 자체로 값을 의미하는 것입니다. -> 약간 value랑 비슷한 개념?
즉, 변수와 상수와는 달리 데이터가 저장된 메모리 공간을 가르키는 이름을 가지고 있지 않습니다.
<예제>
int var = 30; // 30이 바로 리터럴임
final int AGES = 100; // 100이 바로 리터럴임
타입에 따른 리터럴
자바에서 리터럴은 타입에 따라 다음과 같이 구분할 수 있습니다.
-
정수형 리터럴(Integer literals)은 123, -456과 같이 아라비아 숫자와 부호로 직접 표현됩니다.
-
실수형 리터럴(floating-point literals)은 3.
14, -45.6과 같이 소수 부분을 가지는 아라비아 숫자로 표현됩니다. -
논리형 리터럴(boolean literals)은 true나 false로 표현 됩니다.
-
문자형 리터럴(character literals)은 'a', 'Z'와 같이 작은 따옴표('')로 감싸진 문자로 표현됩니다.
-
문자열 리터럴(string literals)은 "자바", "홍길동"과 같이 큰 따옴표("")로 감싸진 문자열로 표현됩니다.
-
null 리터럴(null literals)은 단 하나의 값인 null로 표현됩니다.
null 이란 아무런 값도 가지고 있지 않은 빈 값을 의미합니다.
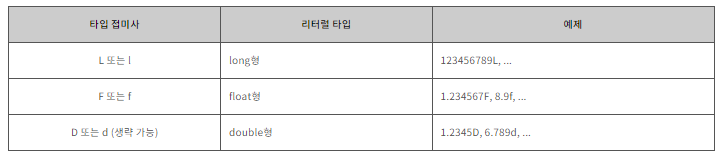
리터럴 타입 접미사(literals type suffix)
자바에서 3.14와 같은 실수형 리터럴을 그대로 사용하면, 해당 리터럴은 실수형 타입 중에서도 double형으로 인식할 것입니다.
하지만 실수형 리터럴 맨 뒤에 F나 f를 추가하면, 자바는 해당 실수형 리터럴을 float형으로 인식할 것 입니다.
이처럼 리터럴 뒤에 추가되어 해당 리터럴의 타입을 명시해주는 접미사를 리터럴 타입 접미사(literal type suffix)라고 합니다.
자바에서 사용할 수 있는 리터럴 타입 접미사는 다음과 같습니다.
9)기본타입
기본타입(primitive type)
타입(data type)은 해당 데이터가 메모리에 어떻게 저장되고, 프로그램에서 어떻게 처리되어야 하는지를 명시적으로 알려주는 역활을 합니다.
자바에서는 여러 형태의 타입을 미리 정의하여 제공하고 있는데, 이것을 기본 타입(primitive type)이라고 합니다.
자바의 기본 타입은 모두 8종류가 제공되며, 크게는 정수형, 실수형, 문자형 그리고 논리형 타입으로 나눌수 있습니다.
정수형 타입
자바에서 정수란 부호를 가지고 있으며, 소수 부분이 없는 수를 의미합니다.
자바의 기본 타입 중 정수를 나타내는 타입은 다음과 같습니다.
- byte
- short
- int
- long
다음 표는 각각읭 정수형 타입에 따른 메모리의 크기 및 데이터의 표현 범위를 나타냅니다.
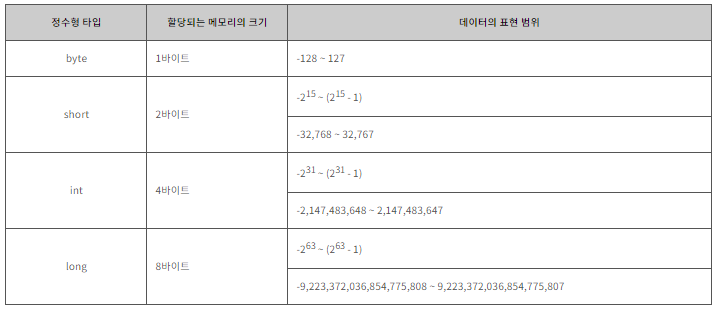
정수형 데이터의 타입을 결정할 때에는 반드시 자신이 사용하고자 하는 데이터의 최대 크기를 고려해야 합니다.
오버플로우(overflow)란 해당 타입이 표현할 수 있는 최대 범위 보다 큰수를 저장할 때 발생하는 현상을 가리킵니다.
오버플로우가 발생하면 최상위 비트(MSB)를 벗어난 데이터가 인접 비트를 덮어쓰므로, 잘못된 결과를 얻을 수 있습니다.
또한, 언더플로우(underflow)란 해당 타입이 표현할 수 있는 최소 범위보다 작은 수를 저장할 때 발생하는 현상을 가리킵니다.
다음 예제는 오버플로우나 언더플로우가 발생하면 결과에 어떠한 영향을 주는지를 보여주는 예제입니다.
<예제>
public class DataType04{
public static void main(string[] args){
byte num1 = 127;
byte num2 = -128;
num1 ++;
num2 --;
System.out.printIn(num1);
System.out.printIn(num2);
}
}
-128
127
자바에서 byte 타입이 표현할수 있는 범위는 -128 부터 127까지 입니다. 하지만 위의 예제에서 변수 num1은 127에 1을 더해 128을 저장하려고 합니다. 이렇게 해당 타입이 표현 할수 있는 최대 범위보다 더 큰수를 저장하려고 하면, 오버플로우가 발생하여 잘못된 결과가 저장됩니다. 따라서 이때도 언더플로우가 발생하여 잘못된 결과값이 저장됩니다.
위의 예제에서 사용된 증감 연산자(++, --) 에 대한 더 자세한 사항은 자바 증감 연산자 수업에서 확인할 수 있습니다.
자바에서 정수형 타입중 기본이되는 타입은 int형 입니다.
따라서 컴퓨터는 내부적으로 정수형 중에서도 int형의 데이터를 가장 빠르게 처리합니다.
실수형 타입
자바에서 실수란 소수부나 지수부가 있는 수를 가르키며, 정수보다 훨씬 더 넓은 표현 범위를 가집니다.
자바의 기본 타입 중 실수를 나타내는 타입은 다음과 같습니다.
- float
- double
과거에는 실수를 표현할때 float형을 많이 사용했지만, 하드웨어의 발달로 인한 메모리 공간의 증가로 현재는 double형을 가장 많이 사용합니다. 따라서 실수형 타입 중 기본이 되는 타입은 double형 입니다.
실수형 데이터의 타입을 결정할 때에는 표현 범위 이외에도 반드시 유효 자릿수를 고려해야 합니다.
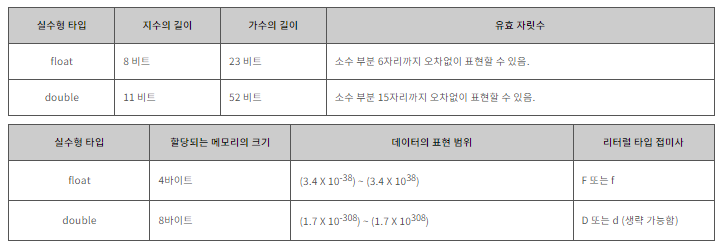
컴퓨터에서 실수를 표현하는 방식은 오차가 발생할 수 밖에 없는 태생적 한계를 지닙니다.
이러한 실수형 데이터의 오차는 자바뿐만 아니라 모든 프로그래밍 언어에서 발생하는 공통된 문제입니다.
문자형 타입
자바에서 문자형 데이터란 작은 정수나 문자 하나를 표현할 수 있는 타입을 의미합니다.
자바의 기본 타입 중 문자를 나타내는 타입은 다음과 같습니다.
- char
컴퓨터는 2진수 밖에 인식하지 못하므로 문자도 숫자로 표현해야 인식할 수 있습니다.
따라서 어떤 문자를 어떤 숫자에 대응시킬것인가에 대한 약속이 필요해집니다.
C언어와 C++에서는 아스키코드(ASCII)를 사용하여 문자를 표현합니다.
아스키코드(ASCII)는 영문 대소문자를 사용하는 7비트 문자 인코딩 방식입니다.
아스키코드는 문자 하나를 7비트로 표현하므로, 총 128개의 문자를 표현할 수 있습니다.
하지만 자바에서는 유니코드(unicode)를 사용하여 문자를 표현합니다.
아스키코드는 영문자와 숫자밖에 표현 못하지만, 유니코드는 각 나라의 모든 언어를 표현할 수 있습니다.
유니코드는 문자 하나를 16비트로 표현하므로, 총65,536개의 문자를 표현할 수 있습니다.

논리형 타입
논리형은 참(true)이나 거짓(false)중 한 가지 값만을 가질수 있는 불리언 타입을 의미합니다.
자바의 기본 타입 중 논리형 타입은 다음과 같습니다.
1.boolean
boolean형의 기본값은 false이며, 기본타입중 가장 작은 크기인 1바이트의 크기를 가집니다.

10) 실수의 표현
실수의 표현 방식
컴퓨터에서 실수를 표현하는 방법은 정수에 비해 훨씬 복잡합니다.
왜냐하면, 컴퓨터에서는 실수를 정수와 마찬가지로 2진수로만 표현해야 하기 때문입니다.
따라서 실수를 표현하기 위한 다양한 방법들이 연구 되었으며, 현재에는 다음과 같은 방식이 사용되고 있습니다.
- 고정 소수점(fixed point)방식
- 부동 소수점(floating point)방식
고정소수점(fixed point)방식
실수는 보통 정소부와 소수부로 나눌 수 있습니다.
따라서 실수를 표현하는 가장 간단한 방식은 소수부의 자릿수를 미리 정하여, 고정된 자릿수의 소수를 표현하는 것입니다.
32비트 실수를 고정 소수점 방식으로 표현하면 다음과 같습니다.

하지만 이 방식은 정수부와 소수부의 자릿수가 크지 않으므로, 표현할 수 있는 범위가 매우 적다는 단점이 있습니다.
부동 소수점(floating point)방식
실수는 보통 정수부와 소수부로 나누지만, 가수부와 지수부로 나누어 표현할 수도 있습니다.
부동 소수점 방식은 이렇게 하나의 실수를 가수부와 지수부로 나누어 표현하는 방식입니다.
앞서 살펴본 고정 소수점 방식은 제한된 자릿수로 인해 표현할 수 있는 범위가 매우 작습니다.
하지만 부동 소수점 방식은 다음 수식을 이용하여 매우 큰 실수까지도 표현 할 수 있습니다.
<수식>
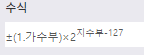
현재 대부분의 시스템에서는 부동 소수점 방식으로 실수를 표현 하고 있습니다.
IEEE 부동 소수점 방식
현재 사용되고 있는 부동 소수점 방식은 대부분 IEEE754 표준을 따르고 있습니다.
32비트의 float형 실수를 IEEE 부동 소수점 방식으로 표현하면 다음과 같습니다.
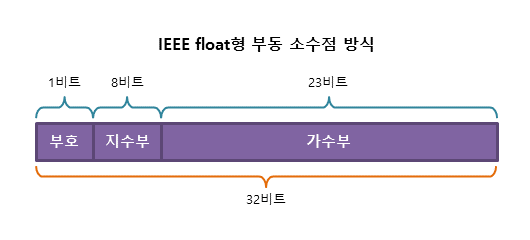
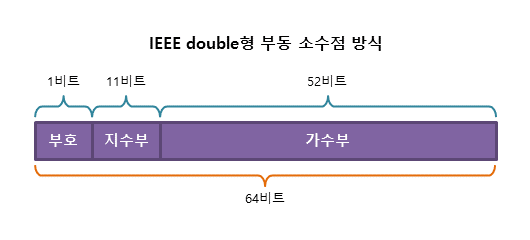
64비트의 double 형 실수를 IEEE 부동 소수점 방식으로 표현하면 다음과 같습니다.
부동 소수점 방식의 오차
부동 소수점 방식을 사용하면 고정 소수점 방식보다 훨씬 더 많은 범위까지 표현할 수 있습니다.
하지만 부동 소수점 방식에 의한 실수의 표현은 항상 오차가 존재한다는 단점을 가지고 있습니다.
부동 소수점방식에서의 오차는 앞서 살펴본 공식에 의해 발생합니다.
이 공식을 사용하면 표현할 수 있는 범위는 늘어나지만, 10진수를 정확하게 표현할 수는 없게 됩니다.
따라서 컴퓨터에서 실수를 표현하는 방법은 정확한 표현이 아닌 언제나 근사치를 표현할 뿐임을 항상 명심해야 합니다.
다음 예제는 부동 소수점 방식으로 실수를 표현할 때 발생할 수 있는 오차를 보여주는 예제입니다.
<예제>
double num = 0.1;
for(int i = 0; i < 1000; i++){
num += 0.1;
}
System.out.print(num);
결과
100.09999999999859
위의 예제에서 0.1을 1000번 더한 합계는 100이 되어야 하지만, 실제로는 100.09999999999859가 출력됩니다. 이처럼 컴퓨터에서 실수를 가지고 수행하는 모든 연산에는 언제나 작은 오차가 존재하게 됩니다.
이것은 자바 뿐만 아니라 모든 프로그래밍 언어에서 발생하는 기본적인 문제입니다.
다음 예제는 자바의 실수형 타입인 double형과 float형이 표현할 수 있는 정밀도를 보여주는 예제입니다.
<예제>
float num3 = 1.23456789f;
double num4 = 1.23456789;
System.out.printIn("float형 변수 num3 :" + num3);
System.out.printIn("double형 변수 num4 :" + num4);
결과
float형 변수 num3 : 1.2345679
double형 변수 num4 : 1.23456789
위의 예제는 float형 타입이 소수 6자리까지는 정확하게 표현할 수 있으나, 그 이상은 정확하게 표현하지 못함을 보여줍니다. 8이없음
자바의 double형 타입은 소수 부분 15자리까지 오차없이 표현할 수 있습니다.
하지만 그 이상의 소수 부분을 표현할 때는 언제나 작은 오차가 발생하게 됩니다.
11) 타입 변환
타입변환(type conversion)
하나의 타입을 다른 타입으로 바꾸는 것을 타입변환(type conversion)이라고 합니다.
자바에서는 boolean형을 제외한 나머지 기본 타입 간의 타입변환을 자유롭게 수행 할 수 있습니다.
자바에서 다른 타입끼리의 연산은 우선 피연산자들을 모두 같은 타입으로 만든후에 수행합니다.
메모리에 할당받은 바이트의 크기가 상대적으로 작은 타입에서 큰 타입으로의 타입변환은 생략할 수 있습니다.
하지만 메모리에 할당받은 바이트의 크기가 큰 타입에서 작은타입으로의 타입변환은 데이터의 손실이 발생합니다.
따라서 상대적으로 바이트의 크기가 작은 타입으로 타입변환을 할 경구 자바 컴파일러는 오류를 발생시킵니다.
타입 변환의 종류
자바에서 타입변환은 크게 다음과 같이 두가지 방식으로 나뉩니다.
- 묵시적 타입 변환(자동 타입 변환)
- 명시적 타입 변환(강제 타입 변환)
묵시적 타입변환(자동 타입 변환, implicit conversion)
묵시적 타입 변환이란 대입 연산이나 산술 연산에서 컴파일러가 자동으로 수행해주는 타입변환을 가리킵니다.
자바에서는 데이터의 손실이 발생하지 않거나, 데이터의 손실이 최소화되는 방향으로 묵시적 타입 변환을 진행합니다.
또한, 자바에서는 데이터의 손실이 발생하는 대입 연산은 허용하지 않습니다.
① double num1 = 10;
② // int num2 = 3.14;
③ double num3 = 7.0f + 3.14;
System.out.println(num1);
System.out.println(num3);
결과
10.0
10.14
위 예제의 ①번 라인에서는 double형 변수에 int형 데이터를 대입하므로, int형 데이터가 double형으로 자동 타입 변환 됩니다.
하지만 주석 처리된 ②번 라인에서는 int형 변수가 표현할수 있는 범위보다 더 큰 double형 데이터를 대입하므로, 데이터의 손실이 발생합니다.
따라서 이 대입연산에 대해서는 자바 컴파일러가 오류를 발생시킬 것입니다.
③번 라인에서는 float형 데이터와 double형 데이터의 산술 연산을 수행합니다.
이때에도 데이터의 손실이 최소화 하도록 float형 데이터가 double형 으로 자동 타입 변환 됩니다.
이렇게 자바 컴파일러가 자동으로 수행하는 타입변환은 언제나 데이터의 손실이 최소화되는 방향으로 이루어집니다.
따라서 자바에서는 타입의 표현 법위에 따라 다음과 같은 방향으로 자동 타입변환이 이루어 집니다.
byte형 → short형 → int형 → long형 → float형 → double형
char형 ↗
① byte num1 = 100; // OK
② byte num2 = 200; // Type mismatch
③ int num3 = 9876543210; // Out of range
④ long num4 = 9876543210; // Out of range
⑤ float num5 = 3.14; // Type mismatch 위 예제의 ①번 라인에서는 byte형 변수에 표현 범위가 더 큰 int형 데이터를 대입하고 있습니다.
하지만 정수 100은 byte형 변수가 표현할 수 있는 범위 내에 있으므로, 자동으로 타입 변환이 이루어져 있습니다.
그러나 ②번 라인처럼 byte 형 변수가 표현할 수 있는 범위를 벗어난 int형 데이터는 타입 변환되지 못하고, 오류를 발생시킬 것 입니다.
⑤번 라인도 마찬가지로 float형 변수가 표현할 수 있는 범위를 벗어난 double형 데이터를 대입하므로, 오류를 발생시킵니다.
③번 라인과 ④번 라인에서는 모두 Out of range 오류가 발생할 것입니다.
이것은 int형 리터럴이 표현할 수 있는 최대 범위인 2,147,483,647을 초과하는 정수형 리터럴을 사용했기 때문입니다.
이렇게 int형 리터럴보다 더 큰 정수를 사용하기 위해서는 다음 예제처럼 리터럴의 마지막에 L이나 l 접미사를 추가하여 long형 리터럴로 명시해야만 합니다.
<예제>
⑥ int num3 = 9876543210L; // Type mismatch
long num4 = 9876543210L; // OK
하지만 ⑥번 라인에서는 int형 변수가 표현할 수 있는 범위를 벗어난 long형 데이터를 대입하므로, 오류를 발생시킬 것 입니다.
명시적 타입 변환(강제 타입 변환, explicit conversion)
명시적 타입 변환이란 사용자가 타입 캐스트 연산자(())를 사용하여 강제적으로 수행하는 타입 변환을 가리킵니다.
자바에서는 다음과 같이 명시적 타입 변환을 수행할 수 있습니다.
문법
(변환할 타입) 변환할 데이터
변환시키고자 하는 데이터의 앞에 괄호(())를 넣고, 그 괄호 안에 변환할 타입을 적으면 됩니다.
자바에서는 이 괄호를 타입 캐스트(type cast)연산자라고 합니다.
다음 예제는 명시적 타입 변환을 보여주는 예제입니다.
int num1 = 1, num2 = 4;
① double result1 = num1 / num2;
② double result2 = (double) num1 / num2;
System.out.println(result1);
System.out.println(result2);
0.0
0.25
위 예제의 ①번 라인에서 나눗셈 연산의 결과로는 0이 반환 됩니다.
자바에서 산술 연산을 수행하고 얻은 결괏값의 타입은 언제나 피연산자의 타입과 일치해야 합니다.
즉, int 형 데이터 끼리의 산술 연산에 대한 결괏값은 언제나 int형 데이터의 결과로 나오게 됩니다.
따라서 1 나누기 4의 결과로는 0.25가 반환되지만, int형으로 자동 타입 변환되어 0이 반환되게 됩니다.
그리고서 double형 변수에 그 결과가 대입될 때, double형 으로 자동 타입변환되어 0.0이라는 결과가 출력되게 됩니다.
따라서 정확한 결과를 얻고자 한다면 ②번 라인처럼 피연산자 중 하나의 타입을 double형으로 강제 타입 변환해야 합니다.
이렇게 피연산자 중 하나의 double형이 되면, 나눗셈 연산을 위해 나머지 하나의 피연산자도 double형으로 자동 타입 변환 됩니다.
따라서 그 결과 또한 double형인 0.25가 될 것이며, 이결과가 double형 변수에 제대로 대입될 것 입니다.
