
데이터 전처리
- 결측값
- 중복된값
- 이상값
- 9999,99999 Missing data
결측값
- 결측치를 처리 하는 방법
1) 제거하기& 삭제하기
2) 채우기& 보간하기
1) 제거하기
결측치의 특성이 '무작위로(랜덤하게) 손실'되지 않았다면, 대부분의 경우 가장 좋은 방법은 삭제하는 것이다.
제거하는 방식은 목록 삭제(Listwise)방식과 쌍 삭제(Pairsiwe)방식으로 다시 구분된다.
1-1) 목록삭제(Listwise)
결측치가 존재하는 전체 행을 삭제하는 방식이다.
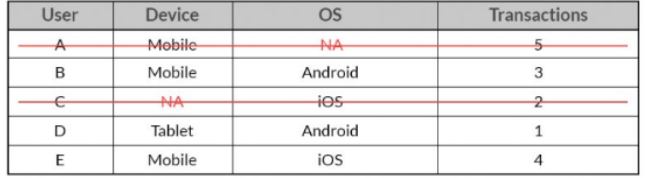
위의 경우 사용자가 A 및 C에 대한 전체 관측치가 데이터셋 목록에서 삭제되면서 무시된다.
1-2) 단일값 삭제(Pairwise)
단일값 삭제의 경우 손실된 관측치 자체만 삭제하고, 다른 변수가 존재하는 경우에는 그대로 유지한채로 분석이 수행된다.
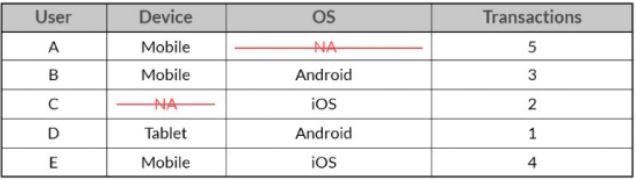
위의 테이블의 경우 NA가 2개 존재하기 때문에 2개의 개별 샘플 데이터가 분석된다. 1개는 유저, 디바이스 및 트랜잭션의 조합으로, 다른 1개는 유저, OS 및 트랜잭션의 조합으로이다. 이 경우 관측치를 삭제하지않고, 각 샘플은 결측값이 있는 변수를 무시한다.
위의 두 가지 방법 모두 정보가 손실된다. 두가지 중 특히 목록삭제는 단일값 삭제와 비교해볼 때 최대치의 정보 손실이 발생하게 된다. 그러나 단일값 삭제의 문제점은 항상 사용할수 있는 것이 아니고,
매번 샘플이 다르기 때문에 분석을 비교할 수 없다는 점이다.
2) 채우기
이번에는 삭제하는 방식이 아닌 결측치를 채우는(보간하는) 방식이다.
자주 사용되는 평균화 기법
- 평균
- 중앙값
- 모드
가장 널리 사용되는 평균화 기술이며 결측치를 유추하는데 사용된다.
장점
결측치를 빠르게 채울 수 있는 장점이 있다.
단점
결측칙들이 동일한 값도 가질 수 있기 때문에 데이터셋의 변동을 인위적으로 줄여줘야 한다.
왜냐하면, 손실된 결측치의 백분율에 따라 평균, 중앙값, 상관 관계 등과 같은 메트릭스가 영향을 받을 수 있으므로 데이터 셋의 통계 분석에 영향을 줄 수도 있기 때문이다.
데이터분석 pandas 에서 결측값 처리
제거하기(drop)
해당하는 데이터의 행을지움 디폴트 일때
df.dropna()
해당하는 데이터의 행을지움 axis = 0
df.dropna(axis = 0)
해당하는 데이터의 열을지움 axis = 1
df.dropna(axis = 1)
- 이와같은경우 칼럼 자체가 통째로 날라감
그래서 세부적으로 조건을 줄수 있음
na가 들어간 행을 날림
df.dropna(axis=0, how='any')
na가 행에 모두 들어가 있을경우만 날림
df.dropna(axis=0, how='all')
채우기
1. 데이터 불러오기
import pandas as pd
df = pd.read_csv("~~~")
2. 결측값 확인
-
step1
데이터를 불러오고 df.info() 를 활용하여 데이터의 결측값이 있는지 확인 -
step2
원본데이터를 손상시킬수 있기 때문에 data.copy()로 데이터를 따로 저장해준다
ex) df2 = df.copy()
- step3
- 평균
- 중앙값
- 모드
ex)
df = pd.read_csv('https://bit.ly/ds-korean-idol')
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 15 entries, 0 to 14
Data columns (total 8 columns):
Column Non-Null Count Dtype
0 이름 15 non-null object
1 그룹 14 non-null object
2 소속사 15 non-null object
3 성별 15 non-null object
4 생년월일 15 non-null object
5 키 13 non-null float64
6 혈액형 15 non-null object
7 브랜드평판지수 15 non-null int64
dtypes: float64(1), int64(1), object(6)
memory usage: 1.1+ KB
- 여기서 보면 나머지는 15개의 데이터를 확인할수 있고 키 같은 경우 데이터가 2개의 결측값이 되어있는 것을 확인 할 수 있다.
ex)
df['키']
0 173.6
1 177.0
2 180.0
3 178.0
4 162.1
5 178.0
6 182.3
7 NaN
8 179.2
9 167.1
10 NaN
11 183.0
12 175.0
13 176.0
14 174.0
Name: 키, dtype: float64
ex)
df['키'].fillna(-1)
0 173.6
1 177.0
2 180.0
3 178.0
4 162.1
5 178.0
6 182.3
7 -1.0
8 179.2
9 167.1
10 -1.0
11 183.0
12 175.0
13 176.0
14 174.0
Name: 키, dtype: float64
fillna() 란 함수를 사용하여 해당하는 결측값에 -1로 처리된것을 알수 있다.
따라서, 1,2,3 에 해당하는 것을 적용시키려면
df를 위에 데이터라고 한다면
최빈값
x = df2['키'].mode()
평균값
x = df2['키'].mean()
중앙값
x = df2['키'].media()
data = df2['키'].fillna(x)
등의 함수를 사용하여 결측값을 처리할 수 있다.
데이터분석 pandas 에서 중복값 처리
df['키']
0 173.6
1 177.0
2 180.0
3 178.0
4 162.1
5 178.0
6 182.3
7 NaN
8 179.2
9 167.1
10 NaN
11 183.0
12 175.0
13 176.0
14 174.0
Name: 키, dtype: float64
df['키'].drop_duplicates()
0 173.6
1 177.0
2 180.0
3 178.0
4 162.1
6 182.3
7 NaN
8 179.2
9 167.1
11 183.0
12 175.0
13 176.0
14 174.0
Name: 키, dtype: float64
drop_duplicates()란 결과를 보면 5번쨰와 10번째가 사라진것을 알수있다.
defult 상태일때,
처음에 나온값은 그대로 유지를 하고 그 다음 똑같은 결과를 같는 값은 제거하는 형태이다
즉,
3번째 178이 송출 -> 5번째 178 제거
7번째 Nan이 송출 -> 10번째 Nan 제거
drop_duplicates() 조건
df['키'].drop_duplicates(keep='last')
df['키'].drop_duplicates(keep='first')
행 전체를 중복 제거
df.drop_duplicates('키',keep='first')
df.drop_duplicates('키',keep='last')
