싱글플레이에서 벽에 구멍을 뚫고 메쉬를 파괴하고 떨어트리는 건 쉽습니다.
하지만 멀티플레이어에서는 다른 문제가 생기게 되는데요

앞서 말씀 드린거 처럼 Boolean Operation은 고비용
- Hardware에 따른 비결정성
- 고비용 Boolean Operation
- 메시 데이터 동기화 불가
그래서 RealtimeDestructibleMesh플러그인에서 적용한 Cell 기반 상태 동기화,Box Collision 시스템,네트워크 패킷 최적화에 대해서 설명하도록 하겠습니다.
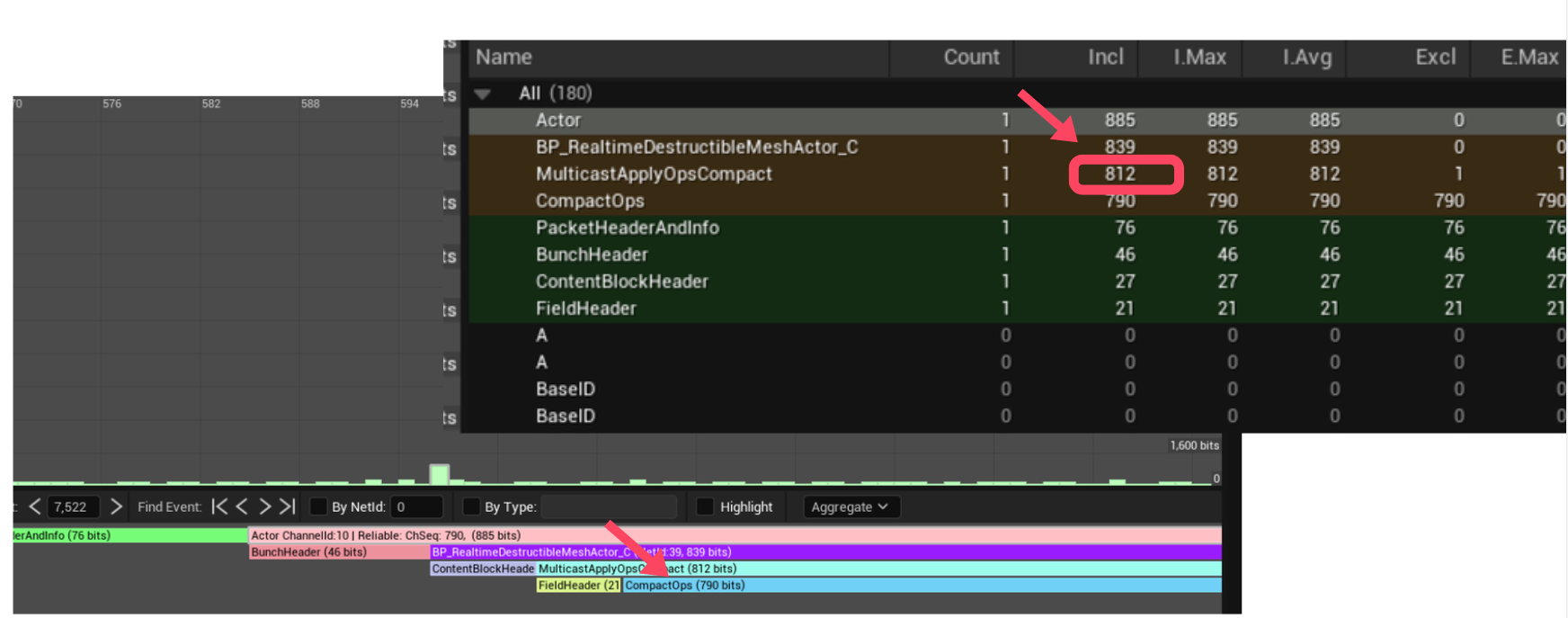
1. 네트워크 패킷 최적화 - 파괴 데이터 압축
첫번째 문제: 파괴 요청 하나에 60바이트?
총알이 벽에 맞으면 서버로 파괴 요청을 보내야 합니다.
FRealtimeDestructionRequest 구조체를 그대로 보내면 약 60바이트가 듭니다.
FRealtimeDestructionRequest (원본):
├─ ImpactPoint FVector 12바이트 (float x3)
├─ ImpactNormal FVector 12바이트
├─ ToolForwardVector FVector 12바이트
├─ ToolOriginWorld FVector 12바이트
├─ ToolShape enum 1바이트
├─ ShapeParams struct ~40바이트
├─ ChunkIndex int32 4바이트
├─ DecalSize FVector 12바이트
├─ DecalConfigID FName 8바이트
└─ ...
총합: ~100+ 바이트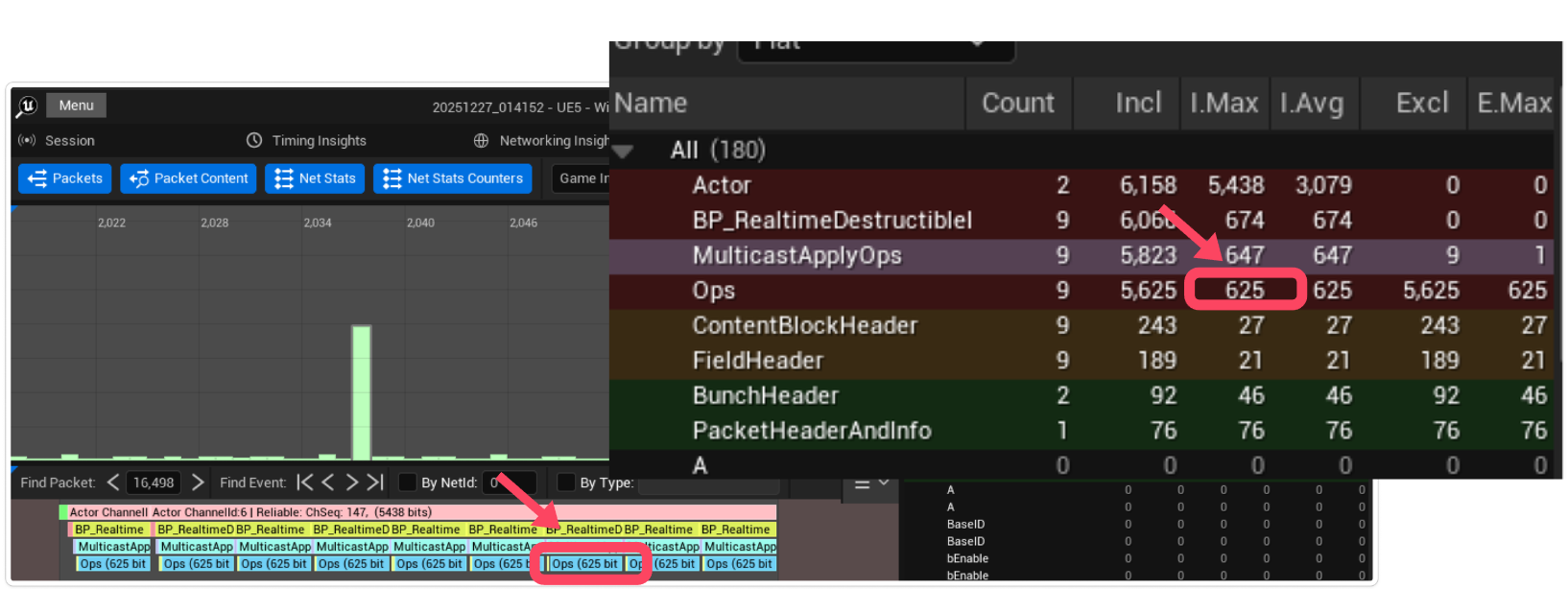
10명이 동시에 연사하면 초당 수백 개의 요청이 날아갑니다.
이거는 네트워크에게 부담을 주는 정도는 아니라고 생각하지만 최대한 최적화를 해야 네트워크 비용도 감소시킬 수 있고 AWS나 공용 서버를 사용한다면 그만큼 비용을 아낄 수 있으니 최대한 줄여야 된다고 생각을 합니다.
해결: FCompactDestructionOp - 압축 구조체
USTRUCT()
struct FCompactDestructionOp
{
// FVector(12B) → FVector_NetQuantize(~6B): 1cm 정밀도
FVector_NetQuantize ImpactPoint;
// FVector(12B) → FVector_NetQuantize10(~6B): 0.1cm 정밀도
FVector_NetQuantize10 ImpactNormal;
FVector_NetQuantize10 ToolOriginWorld;
FVector_NetQuantize10 ToolForwardVector;
// float(4B) → uint8(1B): 반지름 1~255cm
uint8 Radius;
// int32(4B) → uint16(2B): 시퀀스 번호
uint16 Sequence;
// int32(4B) → uint8(1B): 청크 인덱스 0~255
uint8 ChunkIndex;
// 나머지 그대로
EDestructionToolShape ToolShape;
FDestructionToolShapeParams ShapeParams;
...
};어떻게 압축해야하나?
언리얼에는 FVector_NetQuantize - 언리얼 내장 네트워크 양자화 타입이 있습니다.
원본 FVector: (123.456, 78.912, 345.678) → 12바이트 (float x3)
NetQuantize: (123, 79, 346) → ~6바이트 (정수 변환)
1cm 미만의 차이는 총알 구멍에서 눈에 보이지 않기 때문에 진행해줄 수 있었습니다.반지름 uint8 압축:
원본: float Radius = 10.5f → 4바이트
압축: uint8 Radius = 10 → 1바이트 (1~255cm, 소수점 버림)
총알 구멍 반지름이 0.5cm 차이나는 걸 눈치채는 사람은 없을 것 입니다..Compress / Decompress
// 서버로 보낼 때: 압축
FCompactDestructionOp Compact = FCompactDestructionOp::Compress(Request, Sequence++);
// 수신 측에서: 복원
FRealtimeDestructionRequest Request = CompactOp.Decompress();Decompress 시 ToolOriginWorld는 ToolShape에 따라 재계산한다:
// Cylinder: 충돌점에서 SurfaceMargin만큼 뒤로
Request.ToolOriginWorld = ImpactPoint - (ForwardVector * SurfaceMargin);
// Sphere: 저장된 값 그대로 복원
Request.ToolOriginWorld = ToolOriginWorld;수신 측에서 계산 가능한 값은 아예 보내지 않거나 최소한으로 보낸다.
대역폭 절감 효과
비압축 RPC: ~60+ 바이트/요청
압축 RPC: ~22 바이트/요청 (RPC 오버헤드 포함)
절감률: 약 65%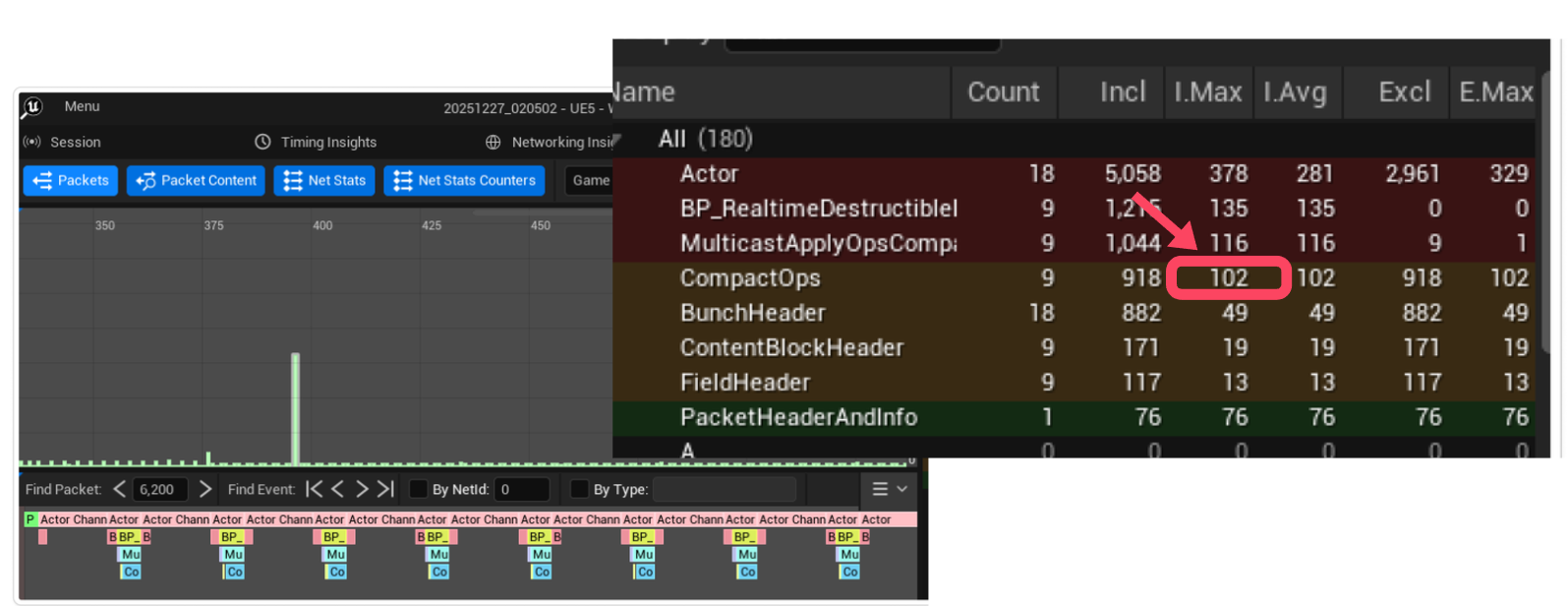
2. 서버 배칭 - RPC 횟수 줄이기
문제: RPC 하나하나가 비싸다
하지만 문제가 하나 더 있습니다. 위에 네트워크 인사이트 사진을 보면은 중간중간 ActorChannel사이가 비어있는 것을 확인 해볼 수 있을 것입니다.
네트워크에서 진짜 비싼 건 데이터 크기보다 패킷 수인데요.
RPC 하나마다 헤더, 오브젝트 참조, 신뢰성 보장 등의 오버헤드가 붙기 때문입니다.
총알 10발을 따로따로 보내면:
패킷 1: [RPC 헤더 20B] + [파괴 데이터 22B] = 42B
패킷 2: [RPC 헤더 20B] + [파괴 데이터 22B] = 42B
...
패킷10: [RPC 헤더 20B] + [파괴 데이터 22B] = 42B
총합: 420B (헤더만 200B)해결: 배치 Multicast
서버에서 일정 시간(16ms) 또는 일정 개수(20개)만큼 모아서 한 번에 보내도록 배칭을 진행해주었습니다.:
// 설정값
float ServerBatchInterval = 0.016f; // 16ms (60fps 한 프레임)
int32 MaxServerBatchSize = 20; // 최대 20개까지 모음
// 한 번에 전송
UFUNCTION(NetMulticast, Reliable)
void MulticastApplyOpsCompact(const TArray<FCompactDestructionOp>& CompactOps);배치 전송:
[RPC 헤더 20B] + [파괴 데이터 22B x 10] = 240B
절감: 420B → 240B (43% 추가 절감)