신용카드 거래 사기 데이터
- id : 거래 식별자 id
- V1 ~ V28 : 시간 , 위치를 나타내는 거래 익명화 데이터
- Amount : 거래 금액 데이터
- class : 사기 당했는지 안당했는지 여부 (1/0)
데이터 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('/content/drive/MyDrive/신용카드 사기 탐지 서비스/creditcard_2023.csv')- 구글 드라이브 에 있는 신용카드 데이터를 올리고 read_csv 로 데이터 읽어오기

V1 ~ V28 까지의 데이터 분석
remove_columns = ['id' , 'Amount' , 'Class']
target_columns = list(df.columns)
for re in remove_columns:
target_columns.remove(re)
def continous_variable_histplot(targets , n,df,x,y):
plt.figure(figsize=(x,y))
for i in range(n):
plt.subplot(4,7,i+1)
sns.histplot(x = targets[i] , data=df)
plt.title(f'hisplot of {targets[i]}')
plt.show()
def continous_variable_boxplot(targets , n , df , x , y):
plt.figure(figsize=(x,y))
for i in range(n):
# target 통계량의 범위
plt.subplot(4,7,i+1)
sns.boxplot(x = df[targets[i]])
plt.title(f'Boxplot of {targets[i]}')
plt.show()
- 익명화 데이터 기 때문에 데이터 분석을 위해 컬럼명을 리스트화 시켜야 한다.
- 익명화 된 데이터는 전부 연속형 변수 이기 때문에 histplot 과 boxplot 을 함수화 시켜서 실행 했다.
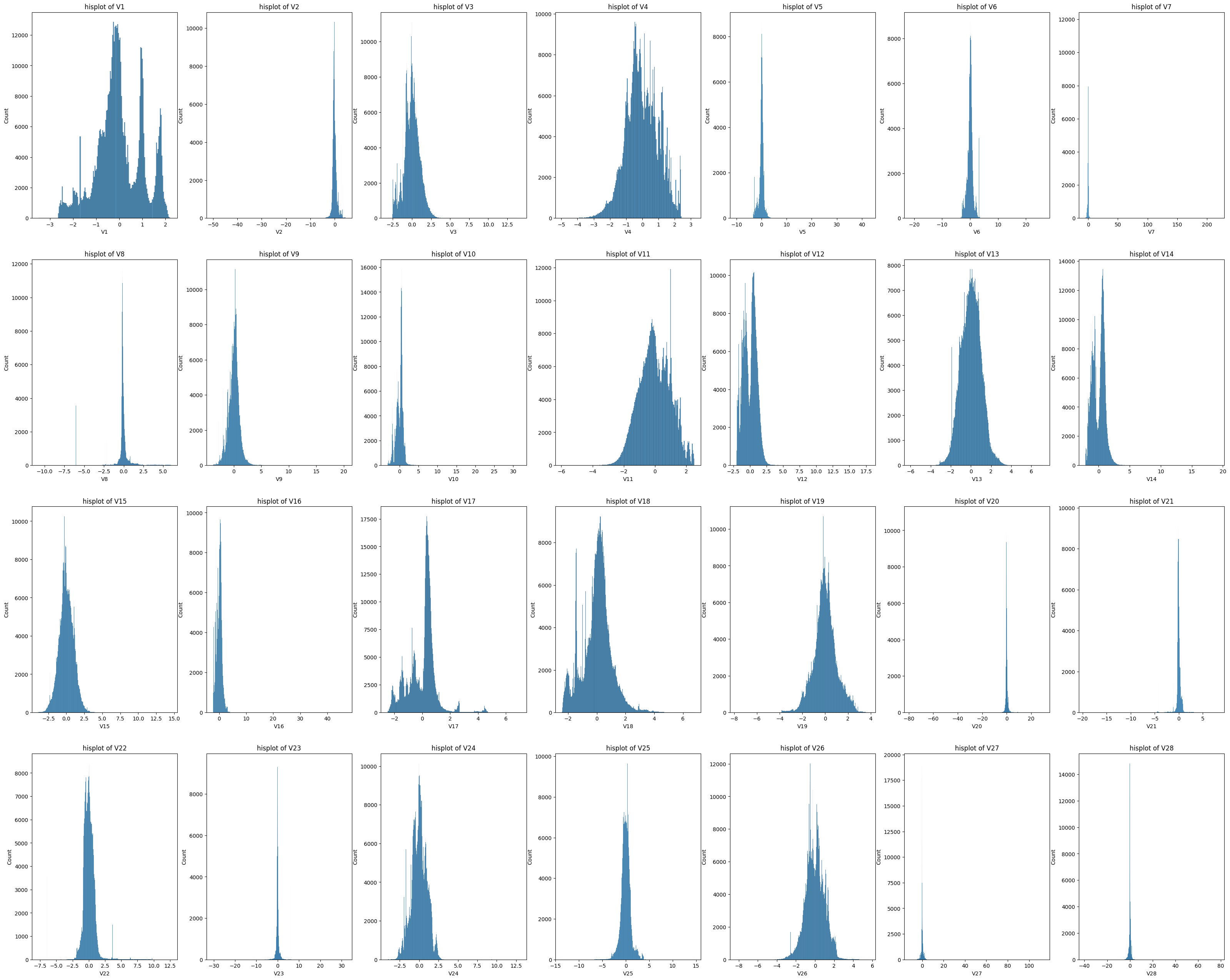
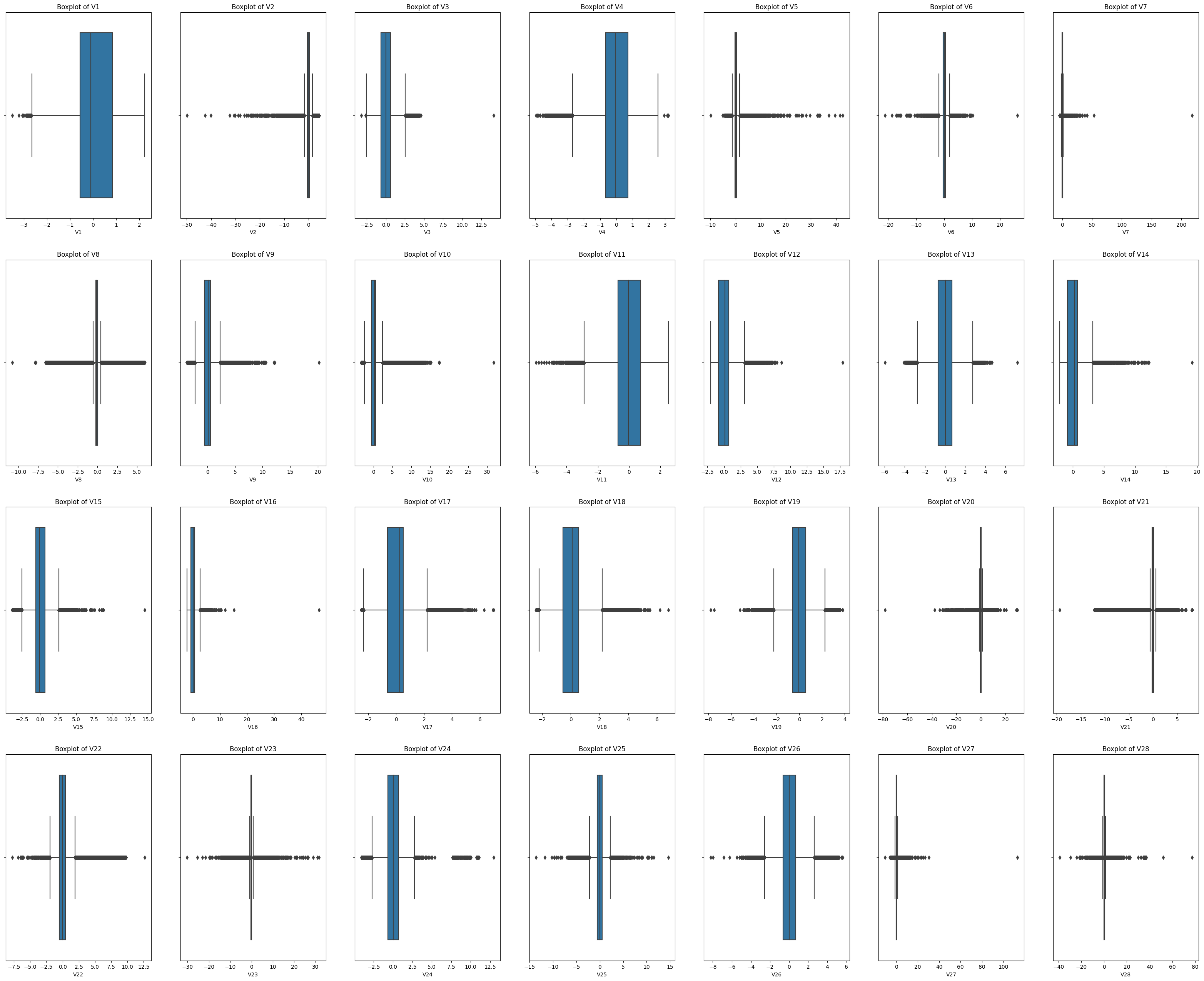
- 예측 되는 값은 대부분 0주위에 있는 소수점 데이터 지만 이상치가 많은 column 들이 종종 발견되는것을 확인 할수 있었다. -> 이상치 제거 or 대처 가 필요함
필요없는 열 삭제
- id 열은 사용자의 개인거래 id 기 떄문에 모델을 학습 하는데에는 영향이 없을거라고 생각해서 id column 은 삭제 했다.
# id 는 사용자 의 개인정보라 종속 변수를 예측하는데에는 별로 도움이 안된다.
df_temp = df.copy()
df_temp.drop('id' , axis = 1 , inplace = True)- 혹시 몰라서 df 를 df_temp 로 깊은 복사하여 작업을 수행했다.
train_test_split
from sklearn.model_selection import train_test_split
target = 'Class'
y = df_temp[target]
x = df_temp.drop(target , axis=1 , inplace = False)
display(x.head())
display(y.head())- target 은 Class 이기 때문에 데이터 프레임의 drop 함수를 이용해서 분리
from sklearn.model_selection import train_test_split
train_x , test_x , train_y,test_y = train_test_split(x,y,random_state=42,shuffle=True,test_size=0.2)- train test split 함수로 train test 를 분리 한다.
정규화
from sklearn.preprocessing import StandardScaler
ss = StandardScaler().fit(train_x)
train_x_scaled = ss.transform(train_x)
test_x_scaled = ss.transform(test_x)
- 이상치 데이터가 많이 감지되었기 때문에 데이터 를 다 변환 시켜줬다.
model

개발자 되고 싶어요