연료 효율 데이터
- year : 차량 측정 연도
- Make : 회사
- Model : 어떤 모델 인지
- class : 옵션 정보
- engine size : 엔진의 크기
- Cylinders : 실린더의 개수
- Transmission : 변속기
- Fuel Type : 연료 타입
- Fuel Comsumption : 연료 효율 (종속 변수)
- Comb (L/100 km)
- Comb (mpg)
- CO2 Emissions (g/km) : 이산화 탄소 배출량
- CO2 Rating : 이산화 탄소 발생 비율
- Smog Rating : 스모그 발생 비율
데이터 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('/content/drive/MyDrive/연료 효율 예측/Fuel Consumption Ratings 2023.csv',encoding='latin-1')
df.shape- 저번이랑 마찬가지로 드라이브 안에있는 차량 데이터 를 가지고 연료 효율을 예측하는 모델을 만드는 것이다.
필요없는 데이터 삭제
df.drop('Year' , axis = 1 , inplace = True)- 연도 데이터는 전부다 2023 년 데이터기 떄문에 딱히 필요 없다고 생각해서 지웠다.
결측치 확인 및 제거
df.isnull().sum()
df.dropna(axis = 0 , inplace=True)EDA
# case1 = 범주형 변수
case1 = df.select_dtypes(include=('object')).columns.to_list()
# case2 = 연속형 변수
case2 = df.select_dtypes(exclude=('object')).columns.to_list()
- 데이터 분석을 위해 column 이 object 인것과 아닌것을 나누어 분석
def fuel_box_plot(targets,df,n,x,y):
plt.figure(figsize=(x,y))
plt.subplots_adjust(wspace=1, hspace=1)
for i in range(n):
plt.subplot(n,1,i+1)
sns.boxplot(x = targets[i] , data = df)
plt.title(f'boxplot of {targets[i]}')
plt.show()
def fuel_hist_plot(targets,df,n,x,y):
plt.figure(figsize = (x,y))
plt.subplots_adjust(wspace=1, hspace=1)
for i in range(n):
plt.subplot(n,1,i+1)
sns.histplot(x = df[targets[i]])
plt.title(f'histplot of {targets[i]}')
plt.show()- 연속형 데이터는 boxplot 과 histplot 을 사용한다.
def fuel_count_plot(targets , df ,n, x,y):
plt.figure(figsize= (x,y))
plt.subplots_adjust(wspace=5, hspace=5)
for i in range(n):
plt.subplot(n,1,i+1)
sns.countplot(x = targets[i] , data = df)
plt.xticks(rotation = 90)
plt.title(f'countplot of {targets[i]}')
plt.show()
def fuel_bar_plot(targets , df , n,x,y):
plt.figure(figsize = (x,y))
plt.subplots_adjust(wspace=5, hspace=5)
for i in range(n):
plt.subplot(n,1,i+1)
sns.barplot(x = targets[i] ,y = 'Fuel Consumption (L/100Km)', data = df)
plt.xticks(rotation= 90)
plt.title(f'barplot of {targets[i]}')
plt.show()
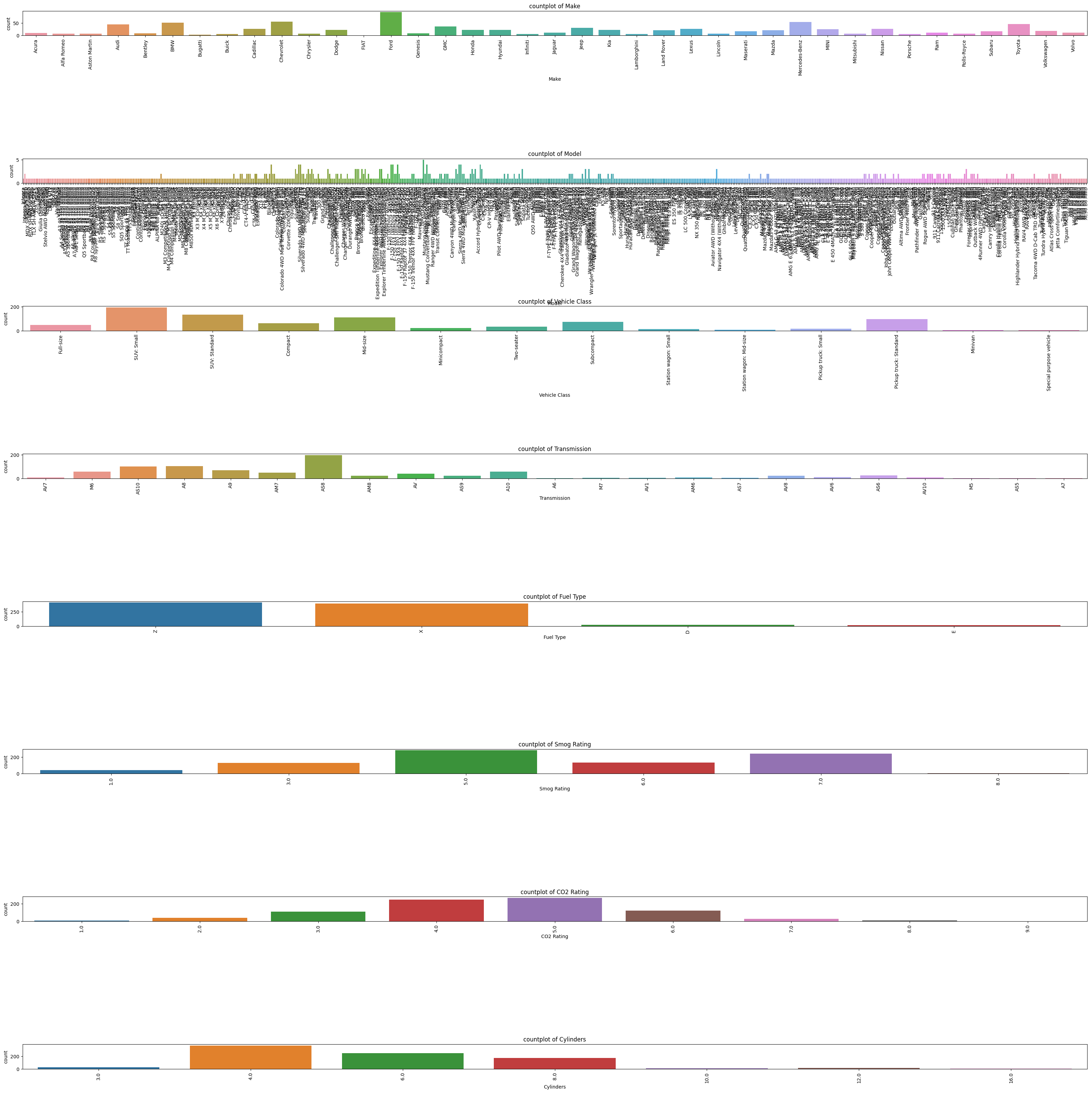
- 확인해보면 model 개수가 650종류 넘게 나오는것을 확인할수 있다.
- 따라서 해당 칼럼은 삭제를 했다.
상관성 분석
df_temp[case2].corr()
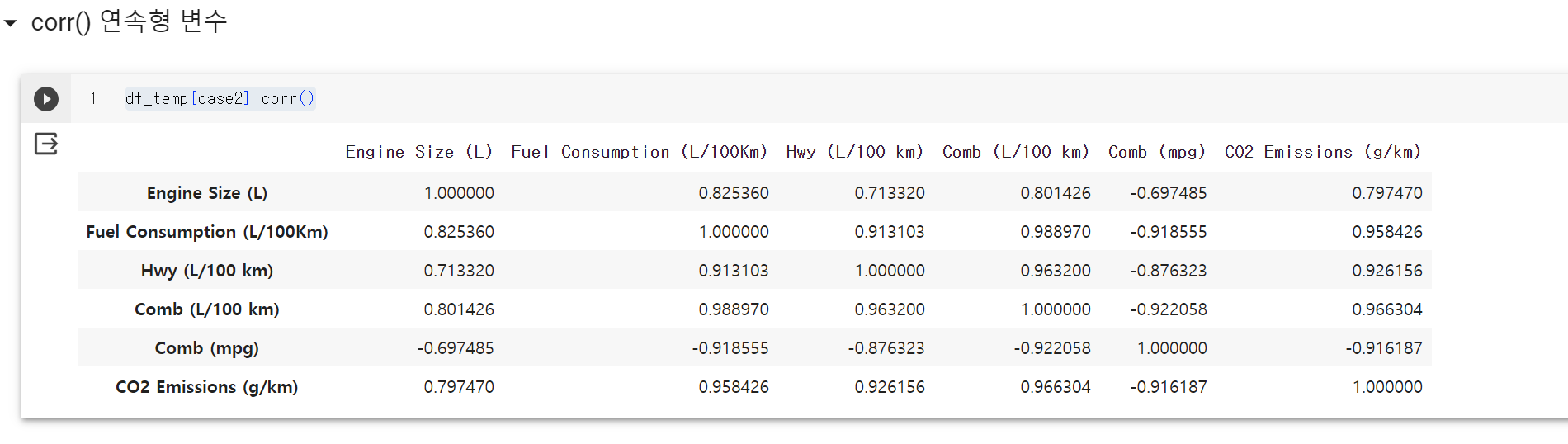
- 보시면 연속형 변수끼리 상관성이 큰것을 확인할수 있다.
train test split
target = 'Fuel Consumption (L/100Km)'
y = df_temp[target]
x = df_temp.drop(target , axis = 1 ,inplace = False)
from sklearn.model_selection import train_test_split
train_x , test_x ,train_y , test_y = train_test_split(x,y , test_size=0.2 , random_state = 42)
모델링
https://colab.research.google.com/drive/1sltQsDvKb4Xo7U8m2mGzyP1tj7tHWyzY?usp=sharing

개발자 되고 싶어요