SHAP
SHapley Value
아파트 집값을 예측하는 모델
- Y: 집값
- X: 공원 근처 , 면적 ,층 , 반려동물 허용
예측
- 아파트 한건에 대해 30만 유로 예측
- 모든 아파트의 평균 예측은 31만 유로
기여도
- -1만 유로 차이는 어떤 기여를 했을 것인가.
-
각 컬럼에 대한 기여도를 측정하여 계산을 한다
-
예를 들어 공원 근처 = 1 , 면적 = 50 , 층 = 2 , 반려동물 허용 = 0
-
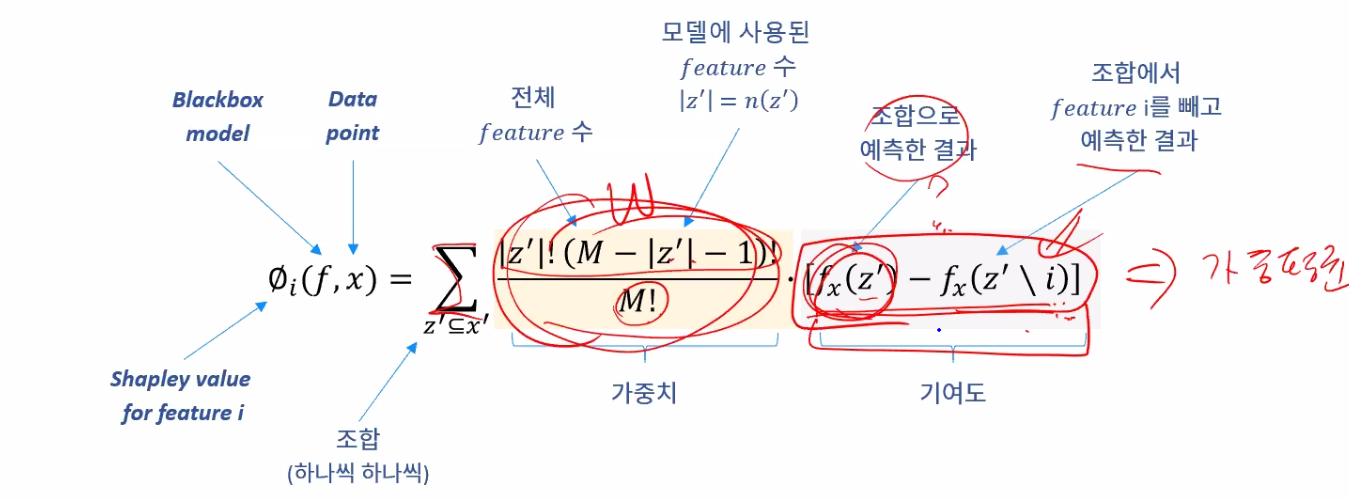
모든 가능한 조합에서 하나의 feature 에 대한 평균 기여도를 계산하는 값
기여도 계산
-
하나의 컬럼을 고정 시킨다.
-
나머지 컬럼에 대한 모든 조합을 구한다
-
(n 은 변수의수) -> 포함/불포함으로 계산을 한다.
-
Case 각각의 기여도를 계산한다.
-
가중 평균은 사용된 feature 의 수의 영향을 받는다
-
변수를 많이 쓰면 가중치가 올라가고 적게 쓰면 떨어진다.
-
예측값의 전체 평균을 기준으로 예측된 값이 어떠한 영향을 주었는지 변수 별 확인
-
이때 상승요인과 하락요인이 있다.
-
각각의 변수의 기여도의 합은 예측값과 예측값의 평균의 차이 가 나온다
실습
import shapmodel1 = RandomForestRegressor()
model1.fit(x_train,y_train)- 사용할 모델을 선언하고 학습
# SHAP 값으로 모델의 예측 설명하기
explainer1 = shap.TreeExplainer(model1)
shap_values1 = explainer1.shap_values(x_train)
- 해당 모델을 기준으로 shapely value 를 뽑아낸다.
shap.initjs() # javascript 시각화 라이브러리 --> colab에서는 모든 셀에 포함시켜야 함.
# force_plot(전체평균, shapley_values, input)
shap.force_plot(explainer1.expected_value, shap_values1[0, :], x_train.iloc[0,:])- 그래프를 그리기 위해서는 initjs() 함수와 force_plot() 을 불러야 한다.
- expected_value = 전체 평균 , shap_values1 = 해당 행 밸류 값 , input = 입력값

- 빨간색은 상승 기여도 , 파란색은 하락 기여도 이다 폭이 넓을수록 해당 색깔의 기여도를 높인것이다.
- best_value 는 y예측값의 평균이다. / 진한 글씨는 해당 열의 예측값이다.

개발자 되고 싶어요