Kafka Connect 란?
Kafka Connect는 데이터베이스, 키-값 저장소, 검색 인덱스 및 파일 시스템 간의 간단한 데이터 통합을 위한 중앙 집중식 데이터 허브 역할을 하는 Apache Kafka의 무료 오픈소스 구성요소이다.
Kafka Connect를 사용하여 Kafka와 다른 데이터 시스템 간에 데이터를 스트리밍하고 Kafka 안팎으로 대규모 데이터 셋을 이동시켜주는 커넥터를 빠르게 생성할 수 있다. (Confluent)
즉, 카프카를 사용하여 외부 시스템과 데이터를 주고 받기 위한 오픈소스 프레임워크입니다.
프로듀서와 컨슈머를 직접 개발해 원하는 동작을 실행하고 처리할 수 있지만, 때로는 이런 애플리케이션을 개발하고 운영하는데 들어가는 리소스나 비용이 부담이 되는 경우가 있습니다. 이런 경우 카프카 커넥트를 사용하면 좀 더 효율적이고 빠르게 클라이언트를 구성하고 적용할 수 있습니다.
운영자는 카프카 커넥트에서 제공하는 REST API를 통해 빠르고 간단하게 커넥트의 설정을 조정하며 상황에 맞게 유연하게 대응할 수 있습니다.
장점
- 데이터 중심 파이프라인
- 커넥트를 이용해 카프카로부터 데이터를 보내거나, 카프카로부터 데이터를 가져올 수 있다.
- 유연성과 확장성
- 커넥트는 테스트 및 일회성 작업을 위한 단독 모드 (standalone mode) 로 실행할 수 있고, 대규모 운영 환경을 위한 분산 모드 (distributed mode(클러스터형))로 실행할 수 있다.
- 재사용성과 기능 확장
- 커넥트는 이미 만들어진 기존 커넥트들을 활용할 수도 있고, 운영 환경에서의 요구사항에 맞춰 빠르게 확장이 가능하다.
- 장애 및 복구
- 카프카 커넥트를 분산 모드로 실행하면, 워커 노드(worker node)의 장애 상황에도 유연하게 대응 가능하므로 고가용성이 보장된다.
Kafka Connect 의 핵심 개념
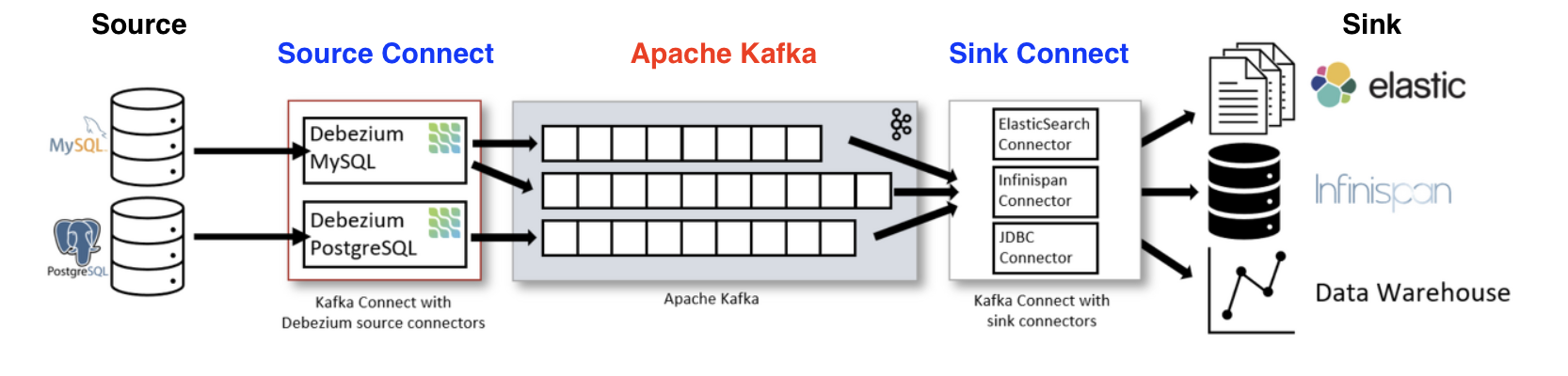
카프카 커넥트는 위 그림과 같이 카프카 클러스터를 먼저 구성한 후, 카프카 클러스터의 양쪽 옆에 배치할 수 있습니다.
카프카를 기준으로 들어오고 나가는 양방향에 커넥트가 존재하게 되는데, 동일한 두 커넥트를 서로 구분하기 위해 소스(source) 방향에 있는 커넥트를 소스 커넥트(Source Connect), 나가는 방향에 있는 커넥트를 싱크 커넥트 (Sink Connect) 라고 합니다.
소스와 카프카 사이에 위치해서 프로듀서 역할을 하는 것이 소스 커넥트이며, 카프카와 싱크 사이에 위치해서 컨슈머 역할을 하는 것이 싱크 커넥트입니다.
용어 정리
- Connect : Connector를 동작하게 하는 프로세서 (서버)
- Connector : Data Source의 데이터를 처리하는 소스가 들어있는 jar 파일 (위 Connector 목록 참조)
- Source Connector : Data Source의 데이터를 카프카 토픽에 보내는 역할을 하는 커넥터 (Producer)
- Sink Connector : 카프카 토픽에 담긴 데이터를 특정 Data Source로 보내는 역할을 하는 커넥터 (Consumer)
- 단일 모드 (Standalone Mode) : 하나의 Connect만 사용하는 모드
- 분산 모드 (Distributed Mode) : 여러개의 Connect를 한개의 클러스터로 묶어서 사용하는 모드. 특정 Connect에 장애가 발생해도 나머지 Connect가 대신 처리할 수 있음
커넥트에 대해 간략히 개념을 파악했으니, 이제 커넥트 내부를 상세하게 살펴보도록 하겠습니다.
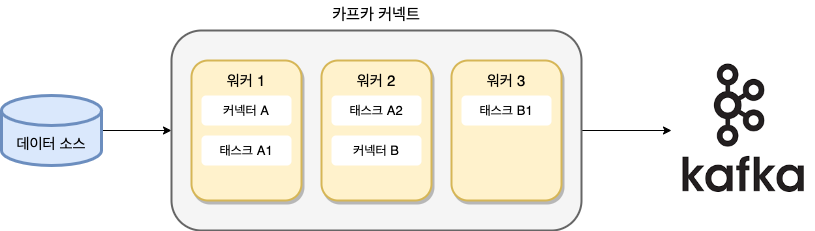
위 그림은 총 3대의 워커(인스턴스)를 실행한 분산 모드 소스 커넥트(Distributed mode Source Connect)를 나타낸 것입니다.
만약 단독 모드(Standalone Mode)로 실행했다면, 위 그림에서는 단 하나의 워커인 워커 1만 동작할 것입니다.
워커는 카프카 커넥트 프로세스가 실행되는 서버 또는 인스턴스 등을 의미하며, 커넥터나 태스크들이 워커에서 실행됩니다.
분산 모드는 특정 워커에 장애가 발생하더라도, 해당 워커에서 동작 중인 커넥터나 태스크들이 다른 위치로 이동해 연속해서 동작할 수 있다는 장점이 있지만, 단독모드는 그렇지 않습지다.
커넥터(Connector) 는 직접 데이터를 복사하지 않고, 데이터를 어디에서 어디로 복사해야 하는지의 작업을 정의하고 관리하는 역할을 합니다.
커넥터도 커넥트와 동일하게 소스에서 카프카로 전송하는 역할을 하는 소스 커넥터와 카프카에서 저장소로 싱크하는 싱크 커넥터가 있습니다.
예를 들어, RDBMS의 데이터를 카프카로 전송하고 싶다면 JDBC 소스 커넥터가 필요하고, 카프카에 적재된 데이터를 HDFS로 적재하고자 한다면, HDFS 싱크 커넥터가 필요합니다. (RDBMS -> Kafka -> HDFS)
Kafka Connect 의 내부 동작
분산 배치된 각 태스크들은 메세지들을 소스에서 카프카로, 혹은 카프카에서 싱크로 이동시킵니다.
이때 커넥트는 파티셔닝 개념을 적용해 데이터들을 하위집합으로 나눈니다.
카프카에서도 병렬 처리를 위해 토픽을 파티션으로 나누는데, 커넥트도 이와 동일합니다.
다만 커넥트에서 나눈 파티션과 토픽의 파티션은 용어만 같을 뿐 서로 아무런 관계가 없습니다.
여기에서 나뉜 파티션들에는 오프셋과 같이 순차적으로 레코드들이 정렬됩니다.
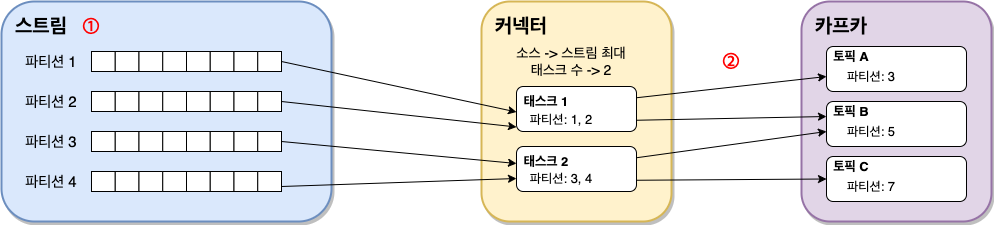
커넥터에서 복사돼야 하는 데이터들은 레코드들의 순서에 맞추어 파티셔닝되어야 하며, 위 그림에서 ① 스트림 영역으로 표시된 부분이 바로 데이터가 파티셔닝 된 것을 나타냅니다.
커넥터에 정의된 값을 살펴보면, ② 최대 태스크 수는 2로 정의되어 있습니다.
스트림에서 나뉜 각 파티션들은 2개의 태스크에 나뉘어서 할당되고, 태스크들은 실제로 데이터를 이동하는 동작을 처리합니다.
그 결과, 태스크 1은 토픽A, 토픽B에 데이터를 전송하고, 태스크 2는 토픽B와 토픽C에 데이터를 전송합니다.
각 파티션들에는 오프셋도 함께 포함되어 있어서 커넥트의 장애나 실패가 발생할 경우 지정된 위치부터 데이터를 이동할 수 있습니다.
커넥터에 따라 오프셋의 기준이 달라질 수 있는데, 일반적인 파일을 전송하는 커넥터일 경우에는 오프셋이 파일의 위치를 나타내며 데이터베이스의 경우에는 타임스탬프나 시퀀스ID를 나타냅니다.
커넥터 기반의 미러 메이커 2.0
미러메이커는 서로 다른 두개의 카프카 클러스터 간 토픽을 복제하는 애플리케이션입니다.
엔터프라이즈 환경에서 간혹 카프카 클러스터를 하나만 사용하는 경우도 있겠지만, 여러 개의 다중 클러스터를 활용하는 경우가 더 흔할 것 입니다.
기업에서 다중 클러스터를 활용하는 몇가지 예를 들어보겠습니다.
- 장애 복구 차원에서 다중 데이터 센터를 운영하는 경우 각 데이터 센터에 카프카 클러스터를 배치하고, 카프카와 카프카 간에 리플리케이션(미러링)을 구성해야 합니다.
- 최근 가장 흔한 사례로서, 온프레미스에서의 데이터를 클라우드로 마이그레이션하려는 경우에 온프레미스에 카프카를 하나 두고 클라우드에 또 다른 카프카를 두어서 온프레미스에서 클라우드로 리플리케이션을 하기도 합니다.
- 데이터 분석을 위한 용도로 카프카와 카프카 간의 리플리케이션이 필요합니다. 카프카를 용도별로 구분하는 경우가 있는데, 예를 들어 업스트림(Upstream) 카프카는 실시간 용도이고, 다운스트림(DownStream) 카프카는 배치를 위한 용도로 쓰입니다. 업스트림 카프카에서 다운스트림 카프카로 리플리케이션 구성을 하여 데이터를 전송합니다.
- 그 외에도 데이터 센터가 원거리에 위치하는 경우, 양 종단에 카프카를 설치한 후 데이터를 리플리케이션 할 수 있습니다.
이렇게, 카프카와 카프카 간 리플리케이션을 하기 위한 도구 중 하나가 바로 미러 메이커(Mirror Maker)이고, 아파치 카프카에서는 미러 메이커를 기본 도구로 제공합니다.
하지만, 초기 1.0 버전의 미러 메이커는 간단한 컨슈머와 프로듀서가 내장된 도구일 뿐이어서, 다양한 옵션이 필요한 엔터프라이즈 환경에 알맞은 추가적인 기능들이 제공되지 않았습니다.
예를 들어, 원격 토픽(리플리케이션 대상 토픽) 생성 시 기본 옵션으로 생성되거나, 소스 토픽의 옵션을 원격 토픽에 적용하지 못하거나, 한 번 적용한 미러 메이커의 설정을 변경하려면 미러 메이커를 재시작해야 하는 등 엔터프라이즈 환경에서 미러 메이커를 운영하기에는 불편한 점이 많았습니다.
이에 아파치 카프카 오픈소스 진영에서는 이러한 미러 메이커의 불편한 점을 개선하고자 프로젝트를 진행해 2019년 12월 16일 아파치 카프카 2.4 버전과 함께 미러 메이커 2.0이 드디어 세상에 공개되었습니다.
미러메이커 2.0 에서 제공하는 기능
1. 원격 토픽과 에일리어스 기능

미러메이커 1.0 에서는 미러링하는 대상의 토픽명이 소스 카프카와 원격 카프카(타깃 카프카) 둘다 동일했습니다.
단방향의 미러링에서는 동일한 토픽명에서 비롯되는 문제가 없었지만, 양방향 미러링의 경우는 동일한 토픽명으로 인해 무한루프 또는 순서가 뒤섞이는 경우가 발생하게 됩니다.
미러메이커 2.0은 Alias를 추가해 서로의 토픽명을 구분할 수 있게 했습니다.
A 카프카 클러스터의 topic1.part0 토픽이 B 카프카 클러스터의 A.topic1.part0 토픽으로 미러링되있고, 반대로 B 카프카 클러스터의 topic1.part0 토픽은 A 카프카 클러스터의 B.topic1.part0으로 미러링되고 있습니다.
미러메이커 2.0에서는 이렇게 Alias 기능이 추가되어 토픽명 구분이 가능해졌으며, 마침내 액티브/액티브 리플리케이션도 가능합니다.
카프카 클러스터 A와 B의 토픽 이름이 동일해도 서로의 토픽 이름을 구분할 수 이썽서 완벽하게 양방향 미러링이 가능합니다.
2. 카프카 클러스터 통합
다중 클러스터로부터 미러링된 토픽들을 다운스트림(DownStream) 컨슈머가 통합할 수 있습니다.
예를 들어, us-west의 카프카에서 미러링된 us-west.topic1 이라는 이름의 토픽과, us-east의 카프카에서 미러링된 us-esat.topic1 이라는 이름의 토픽, 그리고 로컬에 있는 topic1이라는 이름의 토픽, 총 3개의 토픽을 다운스트림 컨슈머가 통함해 컨슘할 수 있습니다.
3개의 토픽의 이름이 모두 제각기 다르므로 원본 토픽의 내용과 정확하게 일치하며, 관리자는 데이터를 처리함에 있어 원하는 형태로 토픽을 consume 할 수 있습니다.
경우에 따라 단 하나의 토픽만 Consume 할 수도, 3개의 토픽을 통합해서 Consume 할 수도 있으므로, 굳이 통합을 목적으로 하는 별도의 카프카 클러스터를 구성하지 않아도 됩니다.
3. 무한 루프 방지
미러 메이커 2.0에서는 관리자가 동시에 2개의 클러스터를 서로 리플리케이션할 수 있도록 구성할 수 있습니다.
만약 구 버전의 미러 메이커를 이용해 양방향 미러링 설정을 하면, 동일한 토픽명을 서로 미러링하면서 무한 루프를 도는 경우가 발생할 수 있습니다.
2.0 에서는 토픽의 이름 앞에 Alias를 추가함으로써 이렇게 접두어가 추가된 토픽은 리플리케이션하지 않으므로 무한 루프를 방지할 수 있습니다.
이러한 규칙은 모든 토픽에 적용되어 더 많은 클러스터와도 리플리케이션이 가능합니다.
3. 토픽 설정 동기화
미러 메이커 2.0은 소스 토픽을 모니터링하고 토픽의 설정 변경사항을 원격으로 대상 토픽으로 전파합니다.
이러한 기능으로 원격 토픽의 설정을 실수로 누락해도 자동으로 적용됩니다.
예를 들어, 소스 토픽의 파티션 수를 증가시키면 원격 대상 토픽의 파티션 수도 증가합니다.
4. 안전한 저장소로 내부 토픽 활용
미러 메이커 2.0은 내부적으로 미러 메이커가 잘 동작하는지 Health Check를 하며, 주기적으로 미러링 관련 토픽, 파티션, 오프셋 정보 등을 저장하기 위해 가장 안전한 저장소인 카프카의 내부 토픽을 사용합니다.
내부 토픽에는 정상상태 점검을 위한 heart beat, 컨슈머 그룹의 오프셋 정보를 위한 체크포인트, 각 토픽의 파티션 리플리케이션 체크를 위한 오프셋 싱크 등이 저장됩니다.
5. 카프카 커넥트 지원
미러 메이커 2.0은 카프카 커넥트 프레임워크를 기반으로 성능, 신뢰성과 확장성을 높였습니다.
카프카 커넥트를 통해 동작 가능한 소스 커넥터와 싱크 커넥터를 지원함으로써 카프카 커넥트 기반으로도 미러 메이커 2.0을 동작할 수 있습니다.
미러메이커 2.0을 실행하는 방법은 다음과 같은 네 가지가 있습니다.
- 전용(dedicated) 미러 메이커 클러스터
- 분산 커넥트 클러스터에서 미러 메이커 커넥터 이용
- 독립적인 커넥트 워커
- 레거시 방식인 스크립트 사용
결론
대규모 데이터를 카프카로 처리할 일이 생겨서, 사전 학습으로 커넥트와 미러 메이커에 대해 조사해보았습니다.
실습은 다음번에 다른 포스팅으로 게시하도록 하겠습니다.
읽어주셔서 감사합니다.

좋은 글 감사합니다. 자주 올게요 :)