스트림 프로세싱 (Stream Processing) 이란?
스트림 프로세싱이란, 연속적인 이벤트 스트림이 들어올때마다 그때그때 처리하고 분석하여 의미있는 정보를 추출하고 실시간으로 작업을 처리하는 애플리케이션을 가리킵니다.
이벤트를 소비해서 다른 이벤트 포맷으로 변환하는 무상태 서비스부터, 낮은 지연 시간과 높은 신뢰성을 보장하기 위해 메모리에 상태 데이터를 저장하고 처리하는 복잡한 서비스가 이에 해당합니다.
Stateless 또는 Stateful
스트림 프로세싱 애플리케이션을 만들 때 애플리케이션의 무상태 또는 상태적인 특성이 설계에 아주 큰 영향을 미칩니다.
Stateless 처리란, 어느 이벤트 레코드가 도착했을 때, 그 레코드만으로 처리가 완료되는 처리를 말합니다.
레코드 A를 레코드 B로 변환하여 다른 토픽이나 다른 데이터 스토어로 전송하는 처리 등이 일반적입니다.
Stateful 한 처리란, 도착한 이벤트 레코드나 그것을 기초로 생성한 데이터를 일정 기간 보관 유지해 두고, 그것과 조합하여 결과를 생성하는 처리를 말합니다. 즉, 이전 이벤트들을 기억해 두고 의사결정에 이들을 활용하는 것입니다.
일반적으로 이벤트 수를 집계하여 합계, 평균 및 히스토그램을 산출하거나, 처리 효율성을 위해 버퍼링하여 처리한다거나, 다른 스트림과 데이터 스토어의 데이터를 결합하여 데이터의 질을 높일 수 있게 하는 것을 생각할 수 있습니다.
예를 들어, 주식 가격이 이전 5분 동안 계속 상승했는지를 알고 싶다면 스트림 처리 시스템은 실시간으로 이전 이벤트들을 전부 기억하고 순서대로 처리해야 합니다.
Stateful 애플리케이션의 State Store
Stateful 처리를 하려면, 애플리케이션에서 각각의 이벤트를 처리하고 그 결과를 저장할 상태 저장소(state store)가 필요합니다.
스트림 처리 애플리케이션이 이 저장소를 관리하면 내부 상태 저장소라고 하고, 스트림 처리 애플리케이션이 DB와 같이 별도의 상태 저장소를 이용하는 것을 외부 상태 저장소라고 합니다.
일반적으로, 상태 저장소는 낮은 latency를 갖는게 중요하기 때문에, 스트림 프로세싱에서는 기본적으로 각 처리 노드의 로컬에 데이터 스토어를 보관 유지하고 latency를 낮게 유지하는 방법을 채택합니다.
이후에 설명할 Kafka Streams나 Apache Flink 등의 스트림 프로세싱 프레임워크에서는 RocksDB 가 사용되고 있는데요, RockDB는 애플리케이션에 통합되는 KVS 유형으로 각 노드의 로컬로 RocksDB를 이동시켜 낮은 대기 시간 상태를 유지합니다.
각 노드의 로컬로 이동한다는 것은, 노드에 장애가 발생하면 데이터가 손실될 위험이 있음을 의미합니다. 이를 피하기 위해 노드 독립적인 데이터 지속성 메커니즘도 별도로 필요합니다.
이 구조에서는 네트워크 통신의 오버헤드가 불가피하기 때문에 어느정도 버퍼링이 필요합니다.
이부분에 대해서는 따로 포스팅을 하도록 하겠습니다.
Kafka Streams 란?
Kafka Streams는 입력 및 출력 데이터가 Kafka 클러스터에 저장되는 애플리케이션 및 마이크로 서비스를 구축하기 위한 클라이언트 라이브러리입니다. 클라이언트 측에서 표준 Java 및 Scala 애플리케이션을 작성하고 배포하는 단순성과 Kafka의 서버 측 클러스터 기술의 이점을 결합합니다. (https://kafka.apache.org/35/documentation/streams/)
간단히 말하면, 카프카 스트림즈는 Apache Kafka 개발 프로젝트에서 공식적으로 제공되는 스트림 프로세싱 프레임워크입니다.
Stateful 한 애플리케이션의 복잡한 상태관리를 Kafka Streams를 이용하여 간소화 시킬 수 있습니다.
Stateless 한 애플리케이션도 대폭으로 코드의 양을 줄일 수 있습니다.
주요 특징
- 단순하고 가벼운 클라이언트 라이브러리이기 때문에 기존 애플리케이션이나 자바 애플리케이션에서 쉽게 사용 가능
- 내부 메세징 계층으로 Kafka 이외의 외부 종속성이 없음
- 내결함성 로컬 상태를 지원
- 정확히 한번 처리 (Exactly-once) 지원
- 밀리초 단위의 처리 지연을 보장하기 위해 한 번에 한 레코드만 처리
- 고수준의 Stream DSL, 저수준의 프로세싱 API 지원
- 윈도우, 조인, 집계를 사용한 이벤트 시간 프로세싱
Kafka Streams 핵심 개념
스트림 처리 토폴로지
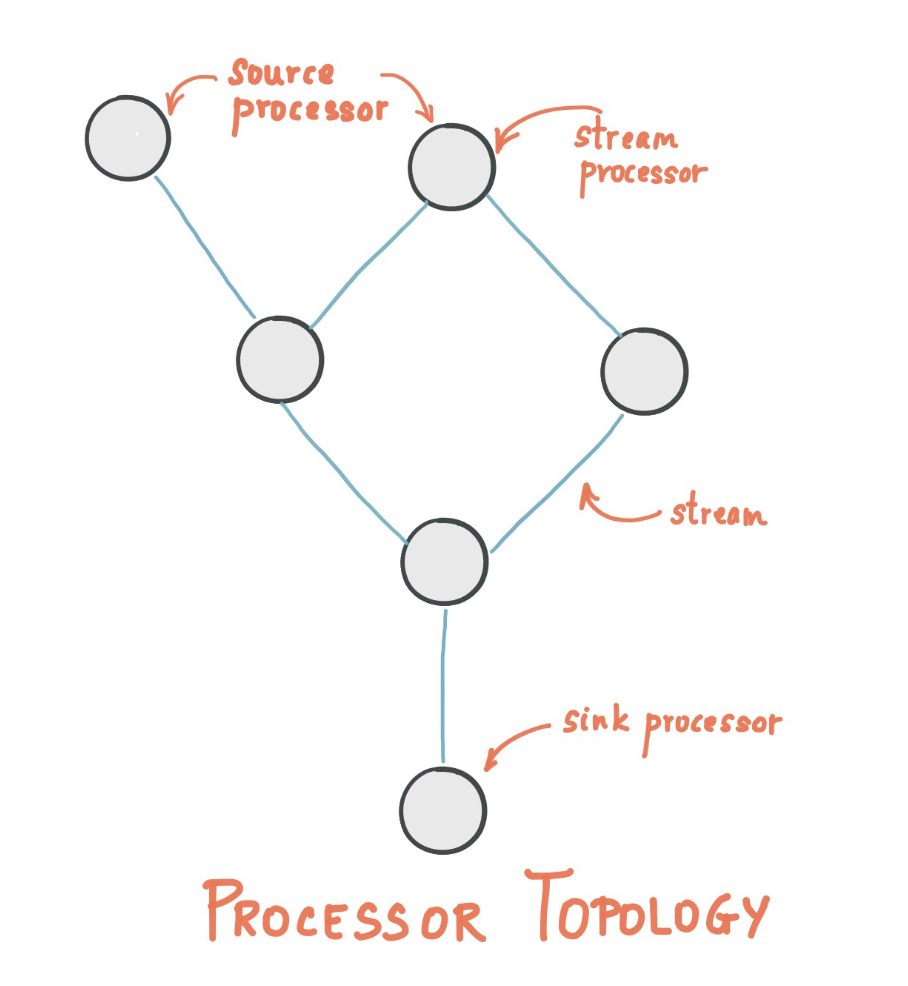
카프카 스트림즈는 스트림 처리를 하는 프로세서들이 서로 연결되어 형상, 즉 토폴로지(topology)를 만들어서 처리하는 API입니다.
여기서 프로세스 토폴로지는 스트림(Edge)으로 연결된 스트림 프로세서(node)의 그래프입니다.
스트림 프로세서는 프로세서 토폴로지의 Node 인데, 이는 토폴로지의 업스트림 프로세서에서 한 번에 하나의 입력 레코드를 수신하고, 스트림의 데이터를 처리하는 단계를 나타내며, 이후에 다운 스트림 프로세서에 하나 이상의 출력 레코드를 생성할 수 있습니다.
용어 정리
- 스트림 (stream) : 카프카 스트림즈 API를 사용해 생성된 토폴로지로, 끊임없이 전달되는 데이터 셋을 의미합니다. 스트림에 기록되는 단위는 키-값 형태입니다.
- 스트림 처리 애플리케이션 (Stream Processing Application) : 카프카 스트림 클라이언트를 사용하는 애플리케이션으로서, 하나 이상의 프로세서 토폴로지(Processor Topology) 에서 처리되는 로직을 의미하기도 합니다. 프로세서 토폴로지는 스트림 프로세서가 서로 연결된 그래프를 의미합니다.
- 스트림 프로세서 (Stream Processor) : 프로세서 토폴로지를 이루는 하나의 노드를 말하며, 여기서 노드들은 프로세서 형상에 의해 연결된 하나의 입력 스트림으로부터 데이터를 받아서 변환한 다음 다시 연결된 프로세서에 보내는 역할을 합니다.
토폴로지에는 두 개의 특수 프로세서가 있습니다.
- 소스 프로세서 (Source Processor)
- 위쪽으로 연결된 프로세서, 즉 업스트림 프로세서가 없는 프로세서를 말합니다.
- 하나 이상의 카프카 토픽에서 데이터 레코드를 읽어서 아래쪽 프로세서, 즉 다운스트림 프로세서로 전달합니다.
- 싱크 프로세서 (Sink Processor)
- 토폴로지 아래쪽에 프로세서가 없는 것을 말합니다. 즉, 다운스트림 프로세서가 없는 스트림 프로세서 입니다.
- 업스트림 프로세서로부터 받은 데이터 레코드를 카프카의 특정 토픽으로 보냅니다.
카프카 스트림즈는 이와 같은 스트림 처리 토폴로지를 정의하는 두가지 방법을 제공합니다.
- 카프카 스트림즈 DSL에서 데이터를 처리할 때 공통적으로 필요한 map, filter, join, aggregations 와 같은 데이터 프로세싱 메소드를 제공
- 하위 수준의 프로세서 API를 통해 개발자가 저수준의 처리를 직접 할 수 있게 하는 것
프로세서 토폴로지는 스트림 처리 코드에 대한 논리적 추상화일 뿐입니다.
런타임에 논리 토폴로지는 인스턴스화 되고, 병렬 처리를 위해 응용 프로그램 내에서 복제됩니다.
시간
스트림의 일반적인 시간 개념은 다음과 같습니다.
- 이벤트 시간 (Event time)
- 이벤트 또는 데이터 레코드가 발생한 시점, 즉 원래 소스에서 생성된 시점입니다.
- ex) 이벤트가 자동차의 GPS 센서에서 수집된 지리적 위치 변경 데이터 일 경우, 연결된 이벤트 시간은 GPS 센서가 위치 변경을 감지한 시간이 됩니다.
- 처리 시간 (Processing time)
- 이벤트 또는 데이터 레코드가 스트림 처리 애플리케이션에 의해 처리되는 시점, 즉 레코드가 소비되는 시점입니다.
- 처리 시간은 원래 이벤트 시간보다 밀리초(실시간), 시간 또는 일 등 더 늦을 수 있습니다. (배치)
- ex) 자동차 센서에서 수집된 지리적 위치 데이터를 읽고, 실제 분석 애플리케이션이 처리하는 시간.
- 수집 시간 (Ingestion time)
- 이벤트 또는 데이터 레코드가 Kafka 브로커에 의해 토픽 파티션에 저장되는 시점입니다.
- 이벤트 시간과의 차이점은 레코드가 "소스에서" 생성될 때가 아니라, Kafka 브로커에 의해 대상 토픽에 레코드가 추가될 때, 이 수집 타임스탬프가 생성된다는 것입니다.
- 레코드가 처리되지 않은 경우, 처리 시간에 대한 개념은 없지만 여전히 수집 시간은 있습니다.
이벤트 시간과 수집 시간 중 어떤 것을 사용할 것인지의 선택은 실제로 Kafka(Kafka Streams가 아님) 구성을 통해 수행됩니다.
Kafka 0.10.x 부터는 Timestamp가 자동으로 Kafka 메세지에 포함됩니다. Kafka의 구성에 따라 이러한 타임스탬프는 이벤트 시간 또는 수집 시간을 나타냅니다. 각 Kafka 구성 설정은 브로커 수준, 혹은 토픽 별로 지정할 수 있습니다.
Kafka Streams의 기본 타임스탬프 추출기는 이러한 카프카의 타임스탬프를 있는 그대로 검색합니다.
Kafka Streams는 TimestampExtractor 인터페이스를 통해 모든 데이터 레코드에 타임스탬프를 할당합니다.
이러한 레코드 별 타임스탬프는 시간과 관련된 스트림의 진행 상황을 설명할 수 있고, 윈도우 연산과 같은 시간에 의존하는 작업들에서 활용됩니다.
결과적으로, 이 시간은 새로운 레코드가 프로세서에 도착할때만 진행됩니다.
우리는 데이터 기반 시간을 Stream Time이라고 부르며, 이 애플리케이션이 실제로 실행되는 Wall-clock Time과 구별합니다.
개발자는 비즈니스 요구 사항에 따라 다양한 시간 개념을 적용할 수 있습니다.
집계 (Aggregation)
집계 작업은 하나의 입력 스트림 또는 테이블을 사용하고, 여러 입력 레코드를 단일 출력 레코드로 결합하여 새 테이블을 생성합니다. 예를 들어 계산 횟수 또는 합계 등을 들 수 있습니다.
Kafka Streams DSL에서의 집계 입력 스트림은 KStream이거나 KTable 일 수 있지만, 출력 스트림은 항상 KTable 입니다.
이를 통해 Kafka Streams 는 값이 생성되고 내보낸 후에, 순서에 어긋난 레코드가 도착하면 집계 값을 업데이트 할 수 있습니다.
윈도잉 (Windowing)
Windowing을 사용하면, 소위 windows 라고 불리는 aggregation이나 joins와 같은 stateful한 연산들을 수행할 때, 동일한 키가 있는 레코드를 그룹화하여 수행할 수 있습니다.
윈도우는 레코드 키 별로 추적됩니다.
Windowing operations은 Kafka Streams DSL 에서 사용 가능합니다.
윈도우 작업 시, 윈도우에 대한 유예 기간(grace period)를 지정할 수 있습니다. 이 기간은, Kafka Streams가 지정된 기간 동안 순서가 잘못된 데이터 레코드를 기다리는 시간을 나타냅니다.
기간의 유예 기간이 지난 후에 레코드가 도착하면 레코드가 삭제되고 처리되지 않습니다. 특히 타임스탬프가 윈도우에 속한다 하더라도, 현재 스트림 시간이 윈도우의 끝과 유에 기간을 더한 것 보다 큰 경우 레코드가 삭제됩니다.
상태
Kafka Streams는 스트림 처리 애플리케이션에서 데이터를 저장하고 쿼리하는 데 사용할 수 있는 상태 저장소(state store)를 제공합니다.
Kafka Streams의 모든 작업에는 처리에 필요한 데이터를 저장하고 쿼리하기 위해 API를 통해 액세스할 수 있는 하나 이상의 상태 저장소가 포함되어 있습니다. 이러한 상태 저장소는 영구 키-값 저장소, 메모리 내 해시맵 또는 다른 데이터 구조일 수 있습니다. Kafka Streams는 로컬 상태 저장소에 대한 내결함성 및 자동 복구를 제공합니다.
정확히 한 번 처리
https://kafka.apache.org/documentation/#semantics
원본 Kafka 토픽에서 읽은 모든 레코드에 대해 처리 결과가 출력 Kafka 토픽과 상태 저장소에 정확히 한번 반영되도록 보장합니다.
Kafak Stream 애플리케이션을 실행할 때 정확히 1회 시맨틱을 활성화하려면 processing.guarantee 를 (기본값은 at_least_once) exact_once로 설정합니다.
버전에 따라 다르니 자세한 내용은 링크 를 참조합니다.
KStream, KTable, GlobalKTable
Kafka Streams의 DSL에는 토픽에서 데이터를 받아오는 방법으로 세가지 패턴을 제공합니다.
KStream
- 레코드 스트림의 추상화입니다. 즉 Kafka 토픽의 입력 스트림을 가리킵니다.
- 레코드 스트림 안에 있는 모든 레코드들은 INSERT로 해석됩니다. KStream에서 레코드를 추가하는 것만 가능하고, 삭제나 업데이트 개념이 없습니다.
- 레코드의 키가 같다 하더라도 같은 키를 가진 기존 행을 대체할 수 없습니다.
예를 들어 다음 두 개의 데이터 레코드가 스트림으로 보내지고 있다고 가정해봅시다.
("alice", 1) --> ("alice", 3)
어플리케이션이 사용자 당 값을 합한다면 alice에 대해 4를 반환합니다. 왜냐하면 두 번째 데이터 레코드가 이전 레코드의 업데이트로 간주되지 않기 때문입니다.
KTable
- KTable은 changelog 스트림의 추상화입니다.
- 여기서 각 데이터 record는 업데이트를 나타냅니다.
- 더 정확하게 말하면, record의 value는 동일한 키에 대한 마지막 값의 “UPDATE”로 해석됩니다. 만약에 키가 아직 존재하지 않는면 업데이트는 INSERT로 간주됩니다.
- changelog 스트림에서 데이터 record는 UPSERT(INSERT / UPDATE)로 해석된다. 왜냐하면 동일한 키에 대한 기존 행을 덮어쓰기 때문입니다.
- 또한 널값은 특별하게 해석됩니다. value가 널인 record는 해당 키에 대한 DELETE 혹은 삭제 표시를 나타냅니다.
- KTable은 키을 사용하여 데이터 Record의 현재 값을 조회할 수 있습니다. 테이블 조회 기능은 join operation과 Interactive Queries를 통해서 할 수 있습니다.
GlobalKTable
- KTable과 같이 GlobalKTabble은 changelog 스트림의 추상화입니다.
- 여기서 각 데이터 record는 업데이트를 나타냅니다.
- GlobalKTable과 KTable은 채워지는 데이터가 다른데, 각 GlobalKTable은 카프카 토픽의 데이터을 읽습니다.
- 간단한 예를 들어 설명을 하면 input 토픽이 5개의 파티션을 가지고 있고, 해당 토픽을 테이블로 읽는 5개의 어플리케이션을 실행시킨다고 합시다.
- Input 토픽을 KTable을 이용해서 읽는 경우, 각 어플리케이션의 로컬 KTable 객체는 5개의 파티션 중에서 1개의 파티션 데이터로만 채워질 것입니다.
- Input 토픽을 GlobalKTable을 이용해서 읽는 경우, 각 어플리케이션의 로컬 GlobalKTable 객체는 해당 토픽의 모든 파티션의 데이터로 채워질 것입니다.
- GlobalKTable은 키를 사용해서 record의 현재값을 조회하는게 가능합니다. 테이블 조회 기능은 join operations와 interactive Queries를 통해 사용할 수 있습니다.
GlobalKTable의 장점은 아래와 같습니다.
- 보다 편리하고 효율적으로 join할 수 있습니다.
- GlobalKTable을 사용하면 star join을 할 수 있으며 외래키 조회를 지원합니다. (즉 Record의 키로 조회하는 것 뿐만 아니라 Record의 value에 있는 데이터를 사용해서 조회할 수도 있습니다)
- 또한 여러 조인을 chaining하는 경우 더욱 효율적이며 GlobalKTable을 조인할 때는 input 데이터가 co-partitioned일 필요가 없습니다.
- 실행중인 모든 어플리케이션의 정보를 브로드 캐스팅하는데 사용할 수 있습니다.
GlobalKTable의 단점은 아래와 같습니다.
- 모든 토픽의 데이터를 읽어오기 때문에 KTable에 비해서 로컬 스토리지를 더 많이 사용합니다.
- 모든 토픽의 데이터를 읽어오기 떄문에 KTable에 비해서 네트워크 부하 및 카프카 브로커 부하가 증가합니다.
Kafka Streams 아키텍처
https://kafka.apache.org/35/documentation/streams/architecture
카프카 스트림즈에 들어오는 데이터는 카프카 토픽의 메세지입니다. 스트림과 카프카 토픽의 관계는 다음과 같습니다.
- 각 스트림 파티션은 카프카의 토픽 파티션에 저장된 정렬된 메세지입니다.
- 스트림의 데이터 레코드는 카프카 해당 토픽의 메세지(키+값) 입니다.
- 데이터 레코드의 키를 통해 다음 스트림(=카프카 토픽)으로 전달됩니다.
카프카 스트림즈는 입력 스트림의 파티션 개수만큼 태스크를 생성합니다.
각 태스크에는 입력 스트림(즉 카프카 토픽) 파티션들이 할당되고, 이것은 한번 정해지면 입력 토픽의 파티션에 변화가 생기지 않는 한 변하지 않습니다.
태스크는 사용자가 지정한 토폴로지를 자신에게 할당된 파티션을 기반으로 실행합니다.
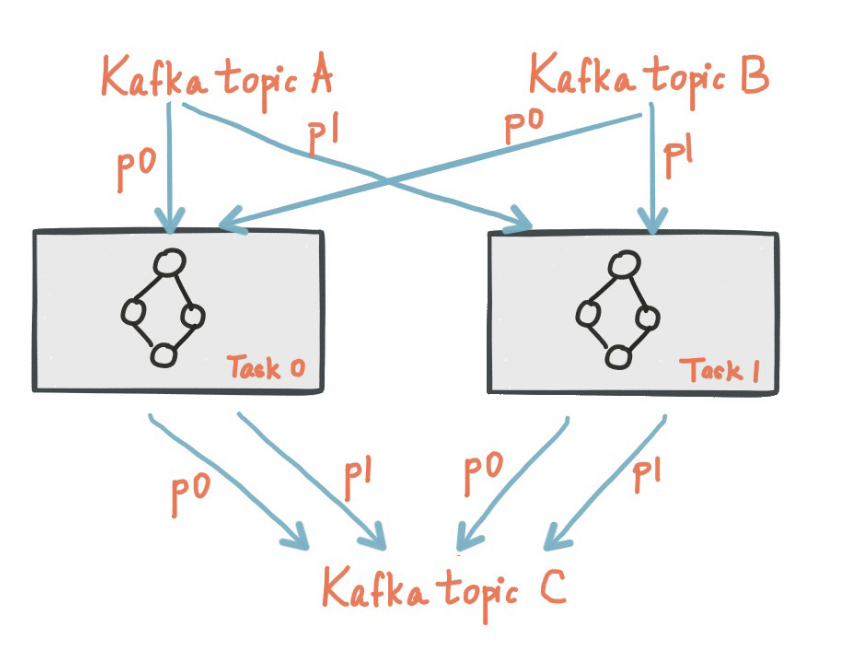
위 그림은 2개의 태스크가 입력 스트림(카프카 토픽)으로 부터 각각 1개의 파티션을 할당받아 처리하는 토폴로지를 보여줍니다.
카프카 스트림즈는 사용자가 스레드 개수를 지정할 수 있게 해주며, 1개의 스레드는 1개 이상의 태스크를 처리할 수 있습니다.
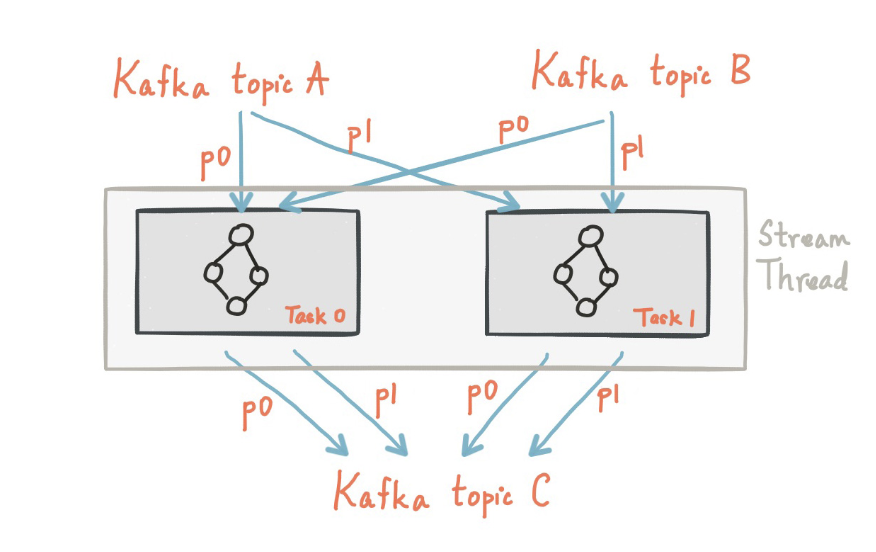
위 그림의 경우 1개의 스레드에서 2개의 스트림 태스크가 수행되는 모습을 보여줍니다.
카프카 스트림즈는 더 많은 스레드를 띄우거나 인스턴스를 생성하는 것 만으로도, 토폴로지를 복제해서 카프카 파티션을 서로 나눈 다음에 효과적으로 병렬 처리를 수행할 수 있습니다.
이 경우 여러개의 스트림에 대해 각 파티션을 나누는 것은 별도의 스트림즈 코디네이션 없이 카프카 코디네이션 방식을 사용합니다.
결론
어렵네요.... 아파치 카프카 공식 문서에 있는 내용을 거의 번역하다 시피 정리했습니다.
스트림 관련한 다음 포스팅은 실제 실습한 내용으로 작성하도록 하겠습니다.
읽어주셔서 감사합니다.
