메모리 관리의 목적
1. 프로그래밍을 위한 편리한 추상화
2. 경쟁하는 프로세스들 사이에서 scarce한 메모리 자원 할당, 성능 최대화(오버헤드 최소화)
3. 메커니즘
- physical vs. virtual address spaces
- page table management, segmentation policies
- page replacement policies
모든 프로그래머가 원하는 것은 무한히 크고, 빠르며, 자신이 혼자 사용할 수 있는 메모리이다. 또한 비휘발성(nonvolatile) 메모리를 원한다. 이때 비휘발성이란 전원이 공급되지 않아도 그 내용이 유지되는 메모리이다. 또, 가격이 비싸지 않아야한다.
하지만 현재 기술로는 위의 모든 요구 조건을 만족시킬 수 있는 메모리를 만들어낼 수 없다.
아무튼, 다른 방법은 뭐가 있을까?
바로 메모리 계층구조(memory hierarchy) 라는 방법이다.
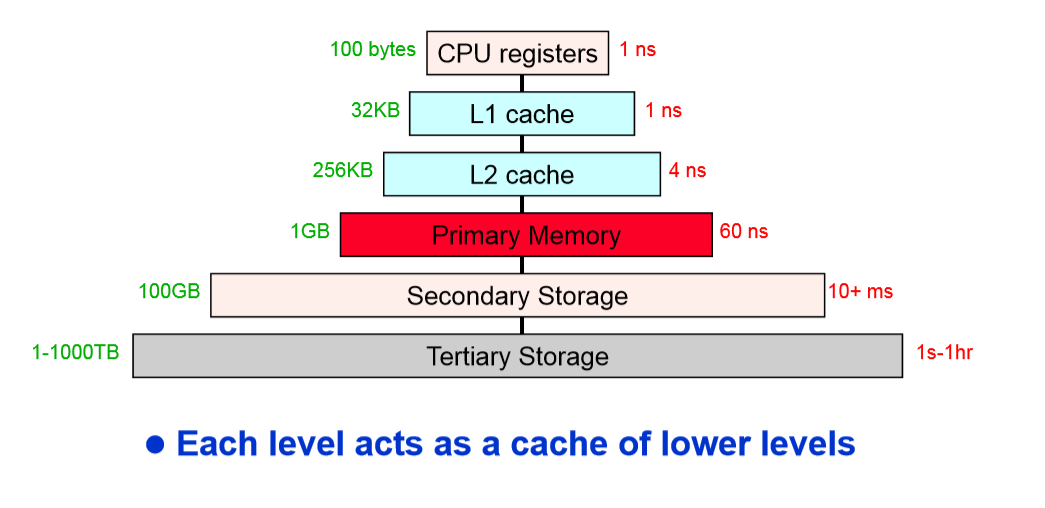
메모리 계층구조
-
캐시 메모리(cache memory), 메인 메모리(main memory), 디스크 스토리지(storage)등의 서로 다른 특성을 갖는 메모리들을 층 구조로 구성
-
캐시 메모리 : 보통 Mbyte의 크기, 빠르고 휘발성이며 비싸다.
-
메인 메모리 : Gbyte의 크기, 중간 속도이고 휘발성이며 중간 가격.
-
디스크 스토리지 : terabyte의 크기, 느리고 비휘발성이며 싸다.
- 디스크 스토리지에는 DVD, USB등의 모바일 스토리지도 포함이러한 계층 구조를 사용하기 좋은 모델로 추상화 시키고 이 추상화된 객체를 관리하는 것이 운영체제의 역할이다.
운영체제 중에서 메모리 계층 구조 관리를 담당하는 부분을 메모리 관리자(Memory manager) 라고 한다.
현재 사용 중인 메모리 부분을 파악하고, 프로세스들이 메모리를 필요로 하면 할당해주고, 더 이상 사용하지 않으면 해제하는 작업을 실행한다.우리는 이 장에서 메모리 관리 기법에 대해 배운다.
캐시 메모리 관리는 일반적으로 하드웨어가 담당하며, 따라서 이 장에서는 주로 메인 메모리에 대한 프로그램 모델과 관리 기법을 배운다. 디스크와 같은 영속적인 저장 장치의 추상화의 관리는 다음 장에서 다룬다. (파일 시스템에서)
1. 메모리 추상화가 없는 컴퓨터
메모리 추상화의 가장 단순한 형태는 추상화를 사용하지 않는 것이다.
(초기 컴퓨터)
즉, 모든 프로그램은 물리 메모리를 직접 사용하였다.
MOV REGISTER1, 1000
이 명령어는 물리 메모리 1000 위치에 있는 내용을 REGISTER1로 이동시킨다.
결국 프로그래머에게 제공되는 메모리 모델은 물리 메모리 그 자체이며, 이 모델은 0부터 실제 물리 메모리 크기까지 주소를 갖는다.
이때, 각 주소는 몇개의 비트로 구성된 셀(cell)로 정의된다.
(대부분의 경우 셀은 8bits)
메모리 추상화가 없는 환경에서는 두 개의 프로그램이 동시에 메모리에서 실행된다는 것은 불가능하다.
만일 한 프로그램이 2000주소에 새로운 값을 기록했을 때, 이것은 다른 프로그램이 그 위치에 저장해 두었던 데이터를 변경하는 결과를 야기할 수도 있다. 결국 두 프로그램 모두 제대로 실행될 수 없으며, 대부분 즉시 서로의 실행을 방해하여 crash 된다.
1) 메모리 추상화가 없는 환경에서 여러 프로그램 실행
물론, 메모리 추상화가 없는 시스템에서도 여러 프로그램을 동시에 실행하는 방법이 가능하긴 하다.
운영체제가 해야하는 일은 우선 메모리에 존재하던 프로그램 이미지를 디스크에 저장하고, 다음에 실행할 프로그램을 메모리로 올리는 것이다.
사실상 한 순간에 하나의 프로그램만 메모리에 존재한다면 충돌을 방지할 수 있다. (swapping)
특별한 하드웨어의 도움이 있으면 스와핑을 사용하지 않더라도 여러 프로그램을 동시에 실행하는 것이 가능하다.
예를들어, IBM360 시스템 초기 모델은 다음과 같은 하드웨어 기능을 제공하였다.
- 메모리를 2KB(2^11) 크기의 블록들로 구분
- 각 블록은 4bits의 보호키를 가짐
- CPU 내부에는 특별한 Register가 있어서 이 보호키들 저장
- 예를 들어, 시스템에 1MB 메모리가 있다면 각 블록마다 존재하는 보호 키를 위한 4비트를 512개(2^20/2^11), 즉 256byte(0.5byte*512) 크기의 키 저장 공간이 필요하다.
- 한편, CPU의 PSW(Program Status Word)에는 4비트 키가 유지된다.
- 프로세스가 현재 PSW의 키와 다른 보호 키를 갖는 메모리 블록을 접근하려고 하면 360 시스템은 트랩을 발생 시킨다. 키의 변경은 OS만 가능하다. 이를 통해 사용자 프로세스들은 서로 간섭하는 것을 예방할 수 있으며, 운영체제 역시 프로세스들로부터 간섭을 막아 보호할 수 있다.
하지만 이런 방법은 다음과 같은 단점이 있다.

이 두 프로그램이 메모리에 연속적으로 적재되었다고 가정해보자.
프로그램 (a)와 (b)는 다른 색으로 표현되어 있는데, 이것은 서로 다른 보호키를 가지고 있음을 의미한다. 이 두 프로그램이 실행되면 서로 다른 보호 키를 가지고 있기 떄문에 서로 간섭할 수 없고, 서로 보호된다.
하지만 다른 종류의 문제가 발생한다.
첫번째 프로그램이 실행되면 JMP 24 명령을 실행하여 24번지로 분기하게 된다. 이 프로그램은 정상적으로 동작한다.
반면, 두번째 프로그램이 실행되면 문제가 발생한다.
두번째 프로그램은 16384번지에 적재되어있다. 이 프로그램은 JMP 28을 실행한다. 즉 28번지로 분기하게 되는데, 현재 28번지에는 첫번째 프로그램의 ADD 명령이 존재한다. 결국, 원래 실행되어야 할 CMP명령이 아닌 다른 명령을 실행하게 되며 결과적으로 프로그램은 정상적으로 작동하지 않는다.
두 프로그램들이 모두 절대 물리 주소(absolute physical address) 를 사용할 경우 발생하는 문제를 보여준다.
IBM 360은 정적 재배치(static relocation) 라는 기법을 사용하였다.
정적 재배치란?
프로그램이 메모리에 적재될 때 프로그램의 내용을 수정하는 것
위의 예에서는 두 번째 프로그램이 16384 주소에 적재될 때 참조하는 모든 주소에 16384를 더한다.
하지만 이 기법은 일반적인 방법은 아니며, 또한 적재하는 시간을 증가시킨다. 이 기법은 프로그램의 어느 위치에 주소가 있는지 부가적인 정보를 요구한다.
프로그램(b)에서 28은 주소이기 때문에 16384를 더해서 재배치해야한다.
반면,
mov register1, 28
명령에서는 28이 주소가 아니라 상수라면(즉, 28 주소에 있는 값을 레지스터에 이동시키는 것이 아니라 상수 28을 이동시키는 것이라면), 여기에는 16384가 더해져서는 안된다.
결국 로더는 프로그램을 구성하는 숫자가 주소인지 상수인지 구분할 수 있는 방법이 필요하다.
