[OS] 메모리 관리(2)-메모리 추상화 : 주소공간
운영체제
물리 메모리를 직접 사용하는 것의 주요 단점
- No protection
-프로그램이 물리 메모리의 모든 주소를 접근할 수 있다면 운영체제를 파괴할 수도 있음 - Relocation is needed (재배치 필요)
-한번에 여러개의 프로그램들을 실행시키기 어려움
1. 주소 공간 개념
여러 프로그램들이 동시에 메모리에 적재되고 서로 간섭없이 실행되기 위해서는 보호(protection) 과 재배치(relocation) 방법이 제공되어야 한다.
IBM360에서는 메모리 공간마다 보호 키를 연결하고, 프로세스가 메모리를 접근할 때 키를 비교하는 방법으로 보호를 제공한다. 한편, 이것만으로는 재배치를 제공하지 못하기 때문에 IBM360에서는 프로그램을 적재할 때 프로그램이 참조하는 주소를 직접 바꾸는 방법으로 재배치를 제공하였다. 하지만 이 방법은 느리고 복잡하다.
보호와 잽재치를 제공하는데 더 효과적인 방법은 주소공간(address space) 라는 새로운 메모리 추상화를 사용하는 것이다.
프로세스가 프로그램이 실행될 수 있는 추상화된 CPU를 생성하는 것 처럼, 주소 공간은 프로그램이 적재될 수 있는 추상화된 메모리 공간을 생성한다.
주소 공간이란 프로세스가 메모리를 접근할 때 사용하는 주소들의 집합 으로, 각 프로세스는 자신만의 주소공간을 갖는다.
물리 주소 공간 - 하드웨어에 의해 정해진 주소 공간
논리/가상 주소 공간 - 메모리 안에서 프로세스의 독립적인 공간
일반적으로 한 프로세스가 갖는 주소공간은 다른 프로세스가 갖는 주소공간과 독립되어 있지만, 예외적으로 프로세스들이 공유 메모리를 원할 경우 주소 공간의 일부를 서로 공유할 수도 있다.
이제 남은 문제는, 어떻게 각 프로세스들에게 서로 다른 주소 공간을 제공하는가 이다.
즉, 한 프로그램에서 사용하는 28주소가 다른 프로그램에서 사용하는 28주소와는 서로 다른 물리 주소를 가리키도록 해야한다.
1) BASE와 LIMIT 레지스터
Dynamic relocation (동적 재배치)
이 방법은 초기 컴퓨터에서 많이 사용되었으나 최근에는 CPU가 제공하는 보다 복잡하고 효율적인 방법으로 교체되어 거의 사용되고 있지는 않다.
여기서 논의할 방법은 동적 재배치(dynamic relocation) 방법 중의 한가지로 상당히 단순하다.
이 방법의 기본 원리는 각 프로세스의 주소 공간을 물리 메모리의 서로 다른 공간으로 연속적으로 매핑하는 것이다.
이 방법을 위해 CPU는 base와 limit라는 이름의 특별한 하드웨어 레지스터를 사용한다.
프로그램이 시작될 때,
- base 레지스터 : 프로그램이 적재된 메모리의 시작 위치
- limit 레지스터 : 프로그램의 크기
가 저장된다. (os만이 이 값을 변경할 수 있도록 보호됨)
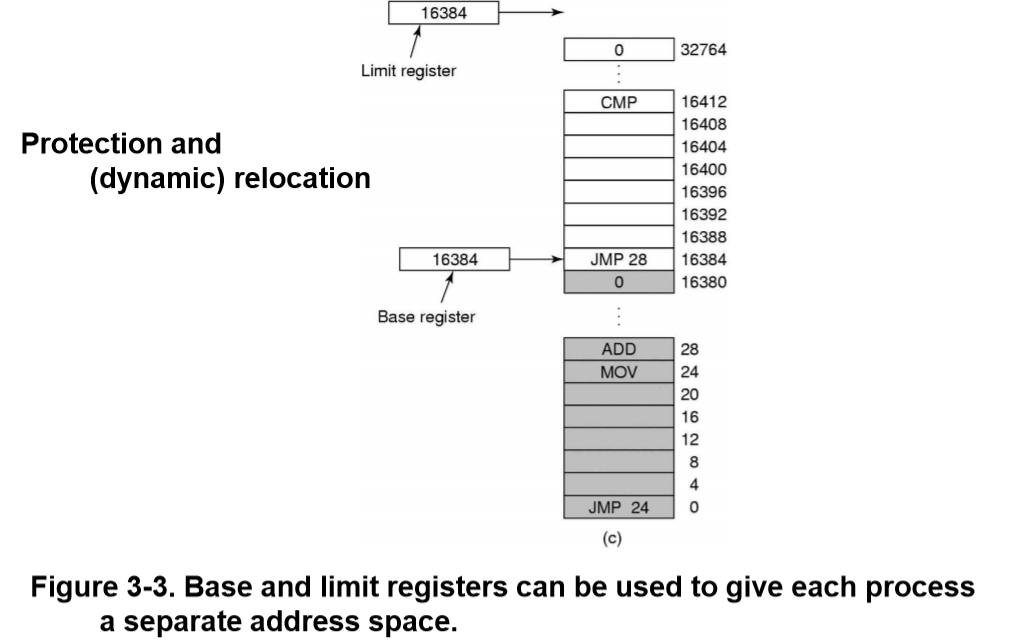
프로세스가 명령어 반입이나 데이터를 읽고 쓰기 위해 메모리를 참조하면,
1. CPU 하드웨어는 자동으로 프로세스가 참조하려는 메모리 주소에 base 레지스터 값을 더한다.
2. 또한 프로세스가 참조하려는 주소가 limit 레지스터의 값과 동일한지 혹은 큰지를 확인한다.
만일 그렇다면, 메모리 참조는 중단되고 Fault가 발생한다.
아니라면, 더한 값을 참조하려는 메모리 주소 값을 메모리 버스에 보낸다.
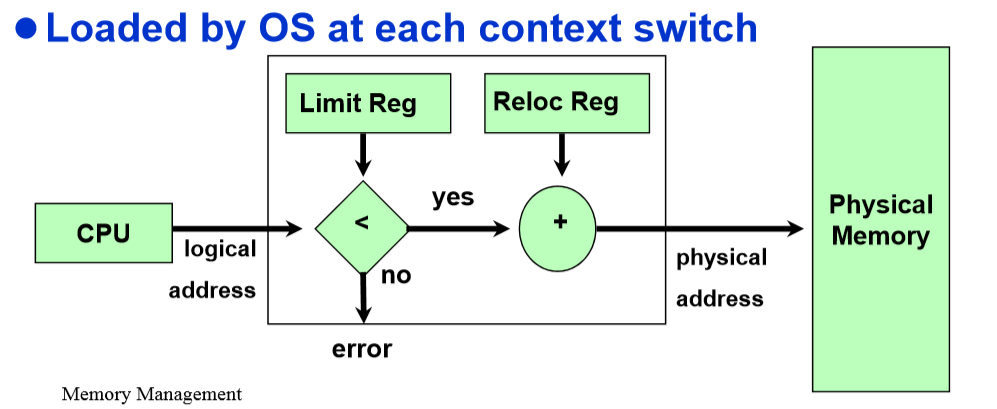
단점은, 모든 메모리 참조마다 덧셈과 비교 연산이 요구된다는 것이다. 비교 연산은 상대적으로 빠르게 처리될 수 있지만, 덧셈은 특별한 하드웨어 로직을 사용하지 않으면 캐리 전파 때문에 시간이 많이 걸린다.
2. 스와핑(Swapping)
지금까지 논의는 시스템에 존재하는 물리 메모리의 용량이 모든 프로세스를 적재할 만큼 충분히 많은 경우에 대한 것이었다. 하지만 실제 시스템에서 모든 프로세스들이 필요로 하는 메모리의 전체 크기는 시스템에 존재하는 실제 RAM 용량보다 크다.
그리고, 실제 사용자가 자신이 원하는 application을 시작하기도 전에 이미 시스템에는 여러 프로세스들이 적재되어 있다. 그리고 사용자가 실행한 application도 50~200mb 정도 크기를 갖는다.
따라서, 모든 프로세스들을 계속 메모리에 적재하기에는 충분하지 못하다.
이러한 문제를 해결하기 위한 방법으로 두가지가 제안되었다.
1. 스와핑 (Swapping)
- 한 프로세스의 모든 이미지가 메모리로 적재되어 실행되다가 더 이상 실행되지 않을 경우 다시 디스크로 내려 보낸다. (현재 실행되고 있지 않은 프로세스는 메모리를 차지하지 않고 디스크에 존재)
2. 가상 메모리(Virtaul memory)
- 한 프로세스의 전체 이미지가 아닌 일부만 메모리에 있어도 프로세스의 실행이 가능하다. (부분적으로 메모리 할당)
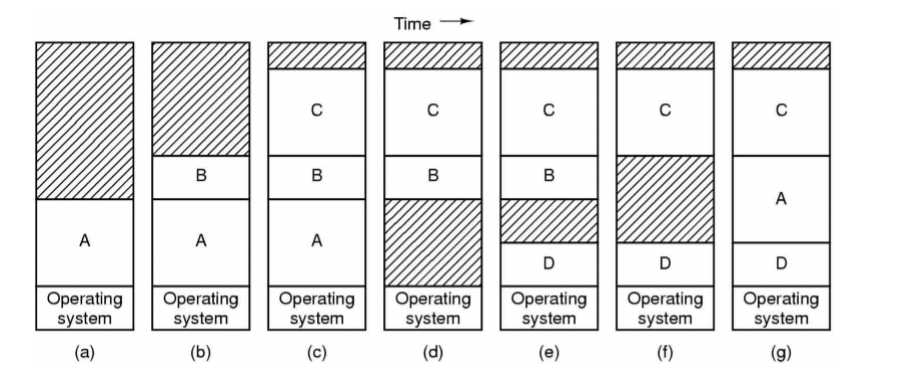
위 그림은 스와핑 시스템의 동작을 예시한 것이다.
초기에는 메모리에 프로세스 A만 존재한다. 그러다가 프로세스 B,C가 새로 생성되었거나 디스크에서 스왑 인(swap in) 되었다. 단계(d)는 프로세스 A가 스왑 아웃(swap out) 된 것을 보여주며, 그 이후에 프로세스 D가 적재되었고, 프로세스 B가 스왑 아웃 되었다. 마지막으로 프로세스 A가 스왑 인 되었다.
스와핑 결과 메모리에 여러 개의 분리된 빈 공간들이 만들어지며 프로세스들의 위치를 이동하여 빈 공간들을 모아 하나의 큰 공간으로 합칠 수 있다.
이것을 메모리 조각(Memory Compaction) 이라고 한다.
사실 이것은 시간이 많이 걸리기 때문에 자주 실행되지는 않는다.
이제부터 프로세스가 생성되거나 스왑 인 될때 얼마만큼의 메모리 공간을 할당해야 하는지 논의해보자.
만일, 프로세스가 고정된 크기를 가지며 실행 중에 크기가 변하지 않는다면 이 문제는 쉽다. 운영체제는 프로세스의 크기에 맞도록 메모리를 할당해 주면 된다.
하지만 많은 프로그램 언어에서는 힙(heap)공간에서 동적 메모리 할당과 같은 기능을 제공하며 결국 프로세스의 크기가 실행 중에 증가하게 된다. 프로세스의 크기가 증가하려면 이를 위한 공간을 할당해 줘야 한다.
- 만일 프로세스가 이미 할당 받은 공간 주변에 사용 가능한 빈 공간이 있다면?
-> 프로세스에게 이 공간 할당 - 사용 가능한 빈 공간이 없다면?
-> 증가하려는 프로세스를 메모리의 다른 위치로 이동
-> 아니면, 다른 프로세스들을 스왑 아웃하여 주변에 빈 공간 생성 - 이것이 불가능 하다면 증가하려는 프로세스를 잠시 중단(suspend)시키거나 강제 종료(kill) 시키기
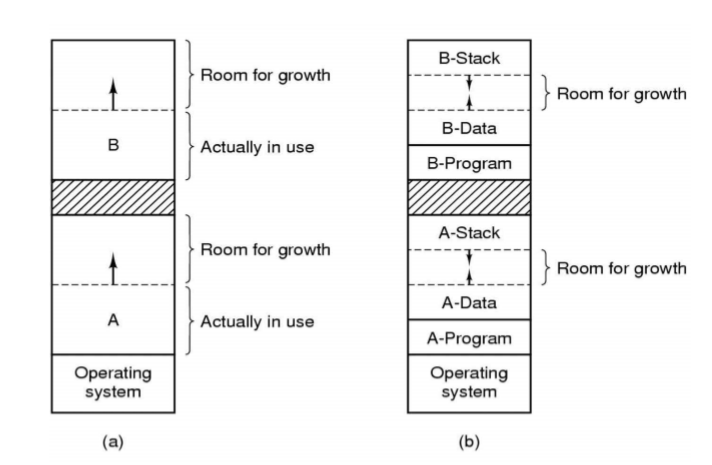
만일 프로세스의 크기가 실행 중에 증가할 것으로 예상되면 프로세스가 생성되거나 스왑 인 될 때 여분의 빈 공간을 더 할당해 주는 것도 좋은 생각이다.(스왑 아웃시에는 실제 사용하는 메모리 공간만 스왑 아웃)
만일 프로세스가 증가될 수 있는 두개의 세그먼트를 갖는다면, (메모리 동적 할당이 가능한 heap을 위한 data segement와 지역변수 및 복귀주소가 저장되는 stack segement) (b)와 같은 배치가 가능하다.
4. 가용 메모리 공간 관리
메모리가 동적으로 할당된다면 운영체제는 메모리 공간의 어떤 부분이 사용 중인지 관리하여야 한다.
메모리 사용량을 관리 할 때 사용하는 대표적인 두가지 자료구조, 비트맵(Bit map)과 리스트(list)를 살펴보도록 하자.
1) 비트맵(bit map)을 이용한 메모리 관리
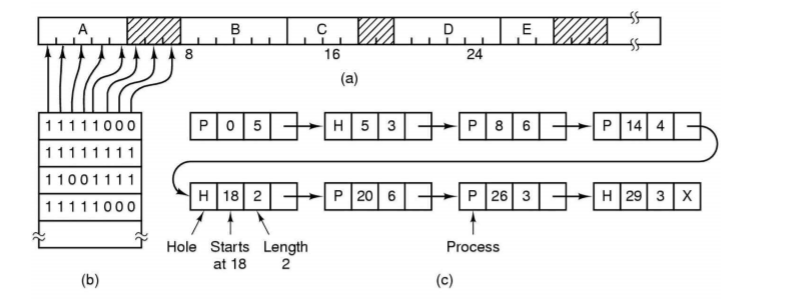
비트맵을 이용한 관리 방법은 메모리를 여러개의 할당 단위(allocation unit) 으로 나누어 관리한다.
할당 단위는 몇 워드 크기를 갖는 작은 단위에서부터 몇 KB 크기를 갖는 큰 단위까지 가능하다.
각 할당 단위마다 비트가 하나씩 대응되는데, 이 비트가 0이면 해당 할당 단위가 가용하고 1이면 이미 사용중임을 의미한다.
할당 단위의 크기 설정은 중요햔 설계 이슈이다.
- 할당 단위가 작으면?
- 비트맵 공간이 커진다. (비트가 많이 필요하므로)
- 하지만, 심지어 4byte로 할당 단위를 설정한다 하더라도 4바이트마다 1비트만 존재하면 된다. 즉, 32비트마다 1비트가 필요한 것이므로 32n비트에 n크기의 비트맵이 필요하게 되며, 결국 전체 메모리의 1/33이 비트맵으로 사용된다.
- 할당 단위가 커지면?
- 비트맵 공간이 작아진다.
- 하지만 이 경우에는 프로세스의 크기가 할당 단위의 정수배가 아니면 마지막 할당 단위의 일부 공간이 낭비된다.
비트맵 크기는 메모리 크기와 할당 단위의 크기에 의해 결정되며, 따라서 고정된 크기의 공간으로 메모리의 사용량을 관리하는 간단하면서도 효과적인 방법이다.
이 방법의 문제는, 프로세스가 k개의 할당 단위를 요구했을 때, 메모리 관리자가 비트맵에서 연속적인 k개의 0비트를 찾아야 한다는 것이다.
이러한 검색은 시간이 많이 걸린다. (검색이 맵에서 워드 경계를 넘어 실행될 수도 있기 때문)
2) 연결리스트(linked list)를 이용한 관리
위 그림에 (c)가 연결리스트로 관리하는 것을 보여준다.
리스트의 각 엔트리는 빈 공간(H,hole) 이거나 프로세스의 내용(P)을 담고 있음을 나타내는 정보, 시작하는 주소, 길이, 그리고 다음 엔트리를 가리키는 포인터로 구성된다.
이 예에서 리스트의 각 엔트리들은 시작 주소를 키로 정렬되어 있다.
이러한 방식의 정렬은 프로세스가 종료되거나 스왑 아웃 될 때, 리스트의 관리를 쉽게 한다.
종료되는 프로세스는 일반적으로 2개의 이웃을 갖는다.(메모리의 가장 끝에 존재하는 프로세스를 제외하면)
이웃은 다른 프로세스가 차지한 공간이거나 빈 공간이며, 그림 3-7에 보이는 4가지 조합이 가능하다.
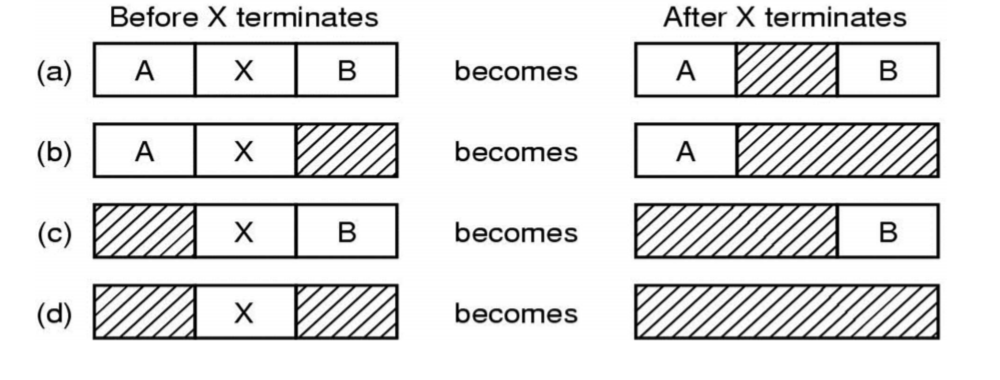
프로세스 X를 제거해보자.
(a)의 경우, 리스트의 변경은 해당 엔트리를 H로 바꾸는 것 만으로 완료도니다.
(b),(c)의 경우, 두 개의 엔트리가 통홥되어 하나로 되며, 결국 리스트 전체적으로 1개의 엔트리가 줄어든다.
(d)의 경우, 3개의 엔트리가 하나로 통합되며, 결국 리스트 전체적으로 2개의 엔트리가 줄어든다.
(이중 연결 리스트로 구현하는 것이 더 편리)
프로세스가 사용 중인 메모리 공간과 빈 공간들이 주소 값을 키로 정렬되어 있으면, 새로 생성되는 프로세스를 위한 메모리 공간을 할당할 때 다양한 알고리즘을 적용할 수 있다.
(일단 메모리 관리자가 얼마 크기의 메모리 공간을 할당해야 하는지 이미 알고 있다고 가정해보자.)
- 최초 적합(First Fit)
- 리스트를 순서대로 스캔하며 요청한 공간을 담을 수 있는 크기의 빈 공간이 발견되면 그 공간을 할당한다.
- 프로세스가 요청한 크기에 해당하는 부분은 프로세스에게 할당되고 남은 부분은 빈 공간으로 관리
- 검색을 최소한으로 하기 떄문에 빠른 할당 가능
- 다음 적합(Next Fit) - worse than first fit
- 자신이 빈 공간을 할당해 주었을 때 그 위치를 기억해둠
- 새로운 할당을 위해 이 알고리즘이 다시 호출되면, 지난 번에 기억해 두었던 위치부터 검색을 시작
- 최적 적합(Best Fit) - not good
- 리스트의 처음부터 끝까지 모든 엔트리들을 검색하여 요청한 크기에 가장 근접하게 큰 빈 공간을 할당
- 큰 빈 공간을 잘라서 할당하는게 아니라, 가능한 요청한 크기를 최적으로 만족할 수 있는 빈 공간을 찾는것.
- 리스트 전체를 검색해야 하기 때문에 최초적합에 비해 느리다. 그리고 낭비하는 메모리가 위에 두개 보다 더 많음 -> 작게 조각난 많은 빈 공간들을 생성하므로
- 최악 적합(Worst Fit) - not good
- 항상 가장 큰 빈 공간을 할당.
- 그 결과 할당되고 남은 빈 공간이 가능한 큰 공간이 될 수 있도록 하는 것
- 빠른 적합(Quick Fit)
- 자주 요청되는 공통 크기의 메모리 공간들을 서로 다른 리스트로 관리.
- 요청한 크기를 만족하는 빈 공간을 검색하는 것은 매우 빠르다. 요청한 크기를 만족하는 엔트리가 가리키는 리스트에 있는 빈 공간을 할당하면 되므로.
- 그러나, 프로세스가 종료하거나 스왑 아웃 될 때 이웃 엔트리를 찾고 통합이 가능 한지 확인하는 작업이 복잡해짐.
프로세스들이 차지하고 있는 공간과 빈 공간들을 서로 다른 리스트로 관리하면 1~4의 알고리즘은 모두 검색 속도 향상을 얻을 수 있다. 왜냐하면 검색 시 빈 공간만을 검색하게 되기 때문이다. 이 성능 향상이 야기하는 피할 수 없는 비용은 메모리를 회수할 때 추가적인 복잡도와 성능 저하이다. 즉, 반납된 공간을 프로세스 리스트에서 제거하여 빈 공간 리스트로 추가하는 부하가 필요하다.
또, 서로 다른 리스트로 관리한다면 빈 공간 리스트는 주소로 정렬하는 것 보다 크기로 정렬하는 것이 최적적합을 더 빠르게 만들 수 있다. (다음 적합은 의미 없어짐)
또, 서로 다른 리스트로 관리한다면 빈 공간 리스트를 관리하기 위해 별도의 자료구조를 사용하는 대신 빈 공간에 필요한 정보를 직접 저장하면 최적화 가능성이 있음.
빈 공간의 첫 번째 워드에는 빈 공간의 크기를 저장하고 두 번째 워드에는 다음 엔트리를 위한 포인터를 유지하는 것이다.
