Disjoint Set의 개념
Disjoint Set이란
서로 중복되지 않는 부분 집합들로 나눠진 원소들에 대한 정보를 저장하고 조작하는 자료구조
- 즉, 공통 원소가 없는, 즉 "상호 배타적"인 부분 집합들로 나눠진 원소들에 대한 자료구조이다.
- Disjoint Set = 서로소 집합 자료구조
Union-Find의 개념
Union-Find 란
Disjoint Set을 표현할 때 사용하는 알고리즘
- 집합을 구현하는 데는 비트 벡터, 배열, 연결 리스트를 이용할 수 있으나 그 중 가장 효율적인 트리구조를 이용하여 구현한다.
- 아래의 세 가지 연산을 이용하여 Disjoint Set을 표현한다.
Union-Find의 연산
- make-set(x)
- 초기화- x를 유일한 원소로 하는 새로운 집합을 만든다.
- union(x,y)
- 합하기- x가 속한 집합과 y가 속한 집합을 합친다. 즉, x와 y가 속한 두 집합을 합치는 연산.
- find(x)
- 찾기- x가 속한 집합의 대표값(루트 노드 값)을 반환한다. 즉, x가 어떤 집합에 속해 있는지 찾는 연산
[Union-Find 알고리즘을 트리 구조로 구현하는 이유?]
1. 배열
- Array[i] : i번 원소가 속하는 집합의 번호(즉, 루트 노드의 번호)
- make-set(x)
- Array[i] = i와 같이 각자 다른 집합 번호로 초기화한다.
- union(x,y)
- 배열의 모든 원소를 순회하면서 y의 집합번호를 x의 집합번호로 변경한다.
- 시간 복잡도 : O(N)
- find(x)
- 한 번만에 x가 속한 집합 번호로 찾는다.
- 시간 복잡도 : O(1)
2. 트리
- 같은 집합 = 하나의 트리, 즉 집합 번호 = 루트 노드
- make-set(x)
- 각 노드는 루트 노드이므로 N개의 루트 노드 생성 및 자기 자신으로 초기화 한다
- union(x,y)
- x,y의 루트 노드를 찾고 다르면 y를 x의 자손으로 넣어 두 트리를 합친다.
- 시간복잡도 : O(N) 보다 작으므로 find 연산이 전체 수행시간을 지배한다.
- find(x)
- 노드의 집합 번호는 루트 노드이므로, 루트 노드를 확인하여 같은 집합인지 확인한다.
- 시간 복잡도 : 트리의 높이와 시간 복잡도가 동일하다. (최악:O(N-1))Union-Find의 과정과 사용 예시
Union-Find의 과정
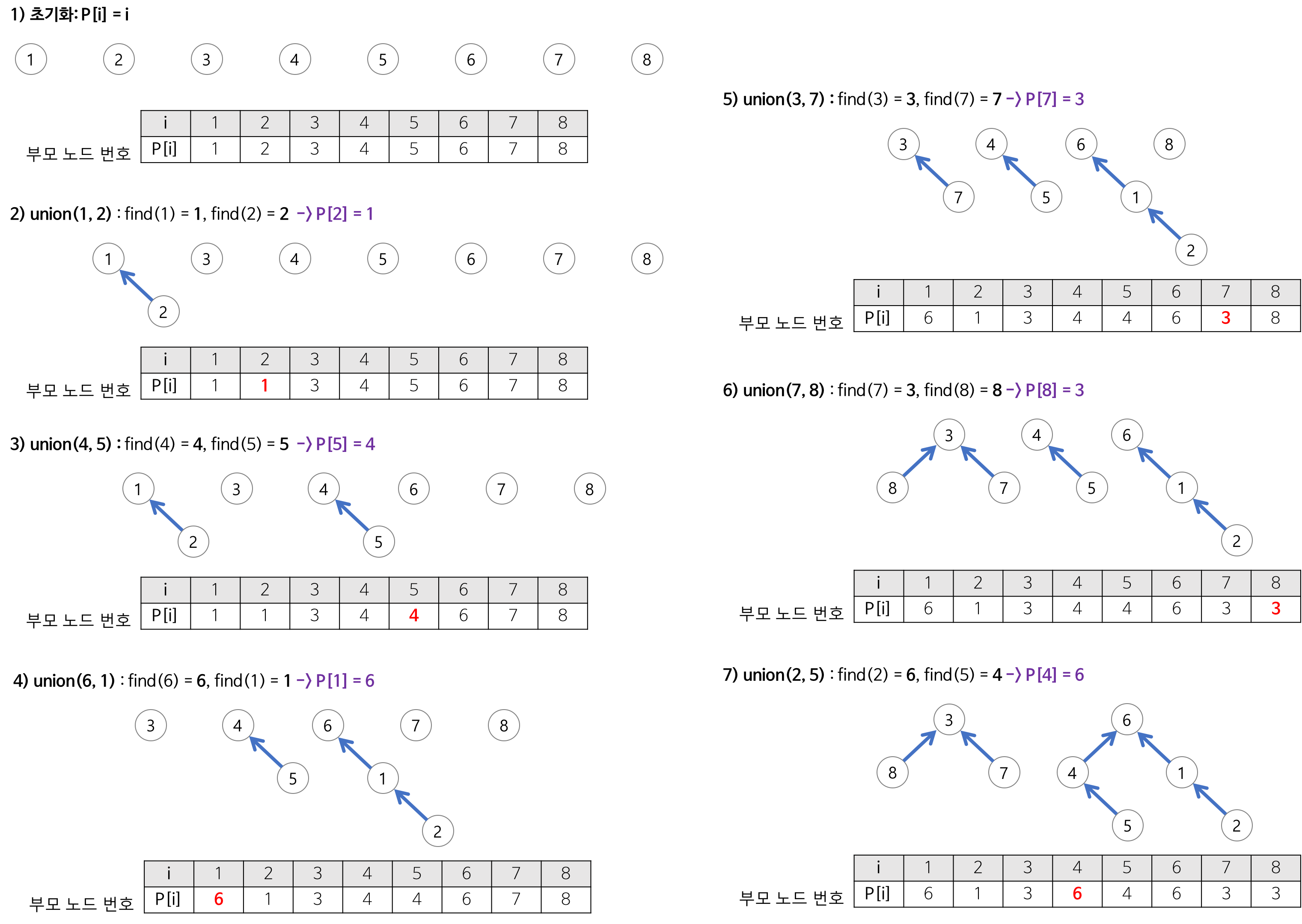
Union-Find의 사용 예시
전체 집합이 있을 때 구성 원소들이 겹치지 않도록 분할하는데 자주 사용된다.
- Kruskal MST 알고리즘에서 새로 추가할 간선의 양 끝 정점이 같은 집합에 속해 있는지(사이클 형성 여부)에 대해 검사하는 경우
- 초기에 {0},{1},{2},...{N}이 각각 n+1개의 집합을 이루고 있다. 여기에 합집합 연산과, 두 원소가 같은 집합에 포함되어 있는지를 확인하는 연산을 수행하려는 경우
- 집합의 표현 - 백준 1717 번 - 어떤 사이트의 친구 관계가 생긴 순서대로 주어졌을 때, 가입한 두 사람의 친구 네트워크에 몇 명이 있는지 구하는 프로그램을 작성하는 경우.
- 친구 네트워크- 백준 4195번
[분할(partiotion) 이란?]
- 임의의 집합을 분할한다는 것은 각 부분 집합이 아래의 두 조건을 만족하는 Disjoint Set이 되도록 쪼개는 것이다.
1) 분할된 부분 집합을 합치면 원래의 전체 집합이 된다.
2) 분할된 부분 집합끼리는 겹치는 원소가 없다.
- 예를 들어, S = {1, 2, 3, 4}, A = {1, 2}, B = {3, 4}, C = {2, 3, 4}, D = {4}라면
A와 B는 S의 분할 O. A와 B는 Disjoint Set
A와 C는 S의 분할 X. 겹치는 원소가 존재
A와 D는 S의 분할 X. 두 집합을 합해도 S가 되지 않음Union-Find의 기본적인 구현 방법
/* 초기화 */
int root[MAX_SIZE];
for(int i = 0; i < MAX_SIZE; i++)
root[i] = i;
/* find(x) : 재귀이용 */
int find(int x){
// 루트 노드는 부모 노드 번호로 자기 자신을 가진다.
if(root[x] == x) {
return x;
}
else {
// 각 노드의 부모 노드를 찾아 올라간다.
return find(root[x]);
}
}
/* union(x,y) */
void union(int x,int y){
// 각 원소가 속한 트리의 루트 노드를 찾는다.
x = find(x);
y = find(y);
root[y] = x;
}Union-Find의 최적화한 구현 방법
최악의 상황

- 트리 구조가 완전 비대칭 인 경우
- 연결 리스트 형태
- 트리 높이가 최대가 된다
- 원소의 개수가 N일때, 트리의 높이가 N-1 이므로 union과 find(x)의 시간 복잡도가 모두 O(N)이 된다.
- 배열로 구현하는 것 보다 비효율 적이다.
find 연산 최적화
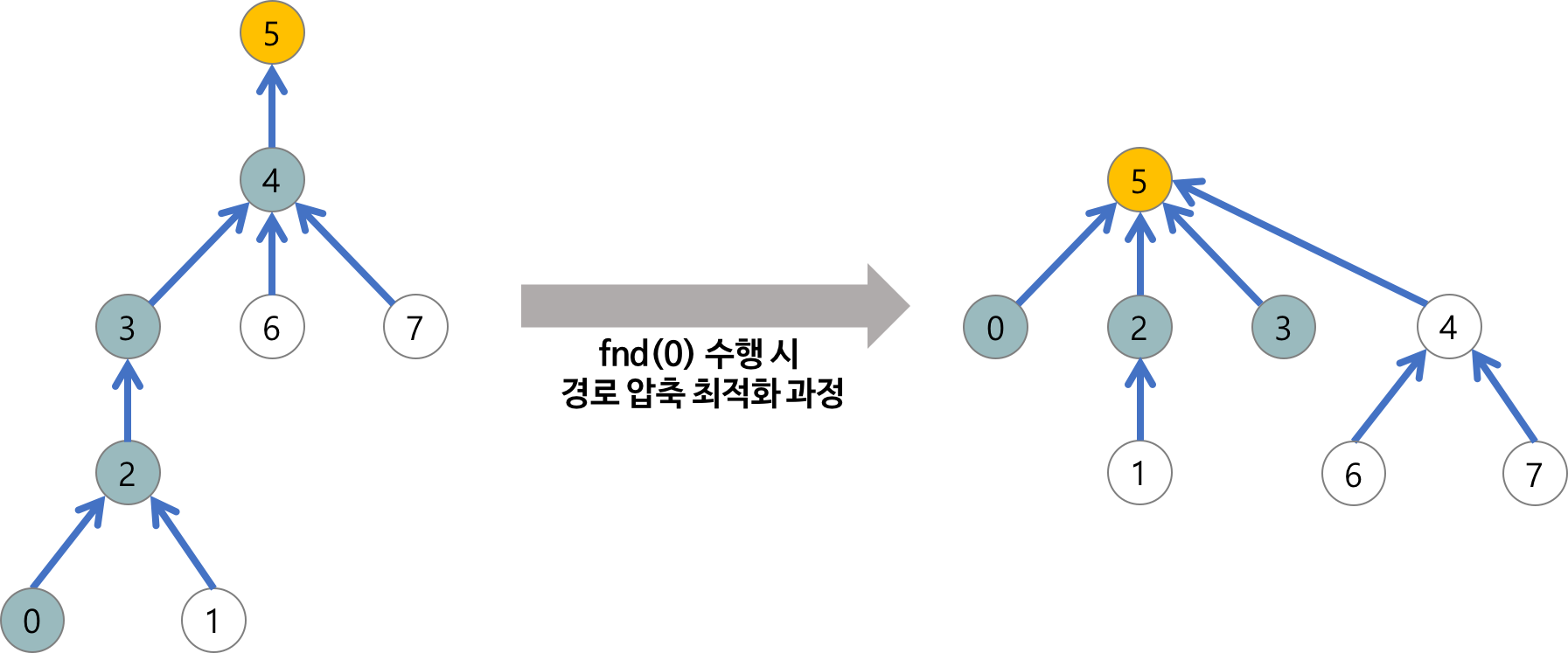
- 경로 압축
- 시간 복잡도 : O(logN)
/* 초기화 */
int root[MAX_SIZE];
for (int i = 0; i < MAX_SIZE; i++) {
root[i] = i;
}
/* find(x): 재귀 이용 */
int find(int x) {
if (root[x] == x) {
return x;
} else {
// "경로 압축(Path Compression)"
// find 하면서 만난 모든 값의 부모 노드를 root로 만든다.
return root[x] = find(root[x]);
}
}
union 연산 최적화
- union-by-rank(union-by-height)
- rank에 트리의 높이를 저장한다
- 항상 높이가 더 낮은 트리를 높은 트리 밑에 넣는다.
/* 초기화 */
int root[MAX_SIZE];
int rank[MAX_SIZE]; // 트리의 높이를 저장할 배열
for (int i = 0; i < MAX_SIZE; i++) {
root[i] = i;
rank[i] = 0; // 트리의 높이 초기화
}
/* find(x): 재귀 이용 */
int find(int x) { // 동일
}
/* union1(x, y): union-by-rank 최적화 */
void union(int x, int y){
x = find(x);
y = find(y);
// 두 값의 root가 같으면(이미 같은 트리) 합치지 않는다.
if(x == y)
return;
// "union-by-rank 최적화"
// 항상 높이가 더 낮은 트리를 높이가 높은 트리 밑에 넣는다. 즉, 높이가 더 높은 쪽을 root로 삼음
if(rank[x] < rank[y]) {
root[x] = y; // x의 root를 y로 변경
} else {
root[y] = x; // y의 root를 x로 변경
if(rank[x] == rank[y])
rank[x]++; // 만약 높이가 같다면 합친 후 (x의 높이 + 1)
}
}- 두 원소가 속한 트리의 전체 노드 수를 구하는 경우
/* union2(x, y): 두 원소가 속한 트리의 전체 노드의 수 구하기 */
int nodeCount[MAX_SIZE];
for (int i = 0; i < MAX_SIZE; i++)
nodeCount[i] = 1;
int union2(int x, int y){
x = find(x);
y = find(y);
// 두 값의 root가 같지 않으면
if(x != y) {
root[y] = x; // y의 root를 x로 변경
nodeCount[x] += nodeCount[y]; // x의 node 수에 y의 node 수를 더한다.
nodeCount[y] = 1; // x에 붙은 y의 node 수는 1로 초기화
}
return nodeCount[x]; // 가장 root의 node 수 반환
}
안녕하세요 :) 제 개인 공부 정리 블로그입니다. 틀린 내용 수정, 피드백 환영합니다.