DiT : Scalable Diffusion Models with Transformers 논문 리뷰
논문: https://arxiv.org/abs/2212.09748
github: https://www.wpeebles.com/DiT
이번에 OminiControl이라는 새로운 Image-to-Image, Text-to-Image 논문을 바탕으로 효율을 발전시키는 연구를 준비중이다. OminiControl를 공부하기에 앞서 DiT model이라는 개념을 숙지하는 것이 중요하여 DiT 논문을 리뷰하고자한다.
DiT: Scalable Diffusion Models with Transformers는 제목에서 알 수 있다시피 Transformer architecture에 Diffusion을 접목하는 새로운 개념이다.
1. Introduction
DiT(Diffusion Transformer)는 기존의 diffusion model에서 주로 사용되던 U-Net backbone을 Transformer로 대체한 새로운 접근법을 제시합니다.
이 논문은 Latent Diffusion Model(LDM) 프레임워크를 기반으로 하며, Transformer 아키텍처의 확장성(scalability)과 성능 향상 가능성을 탐구합니다. 특히, 네트워크 복잡도(계산량, GFlops)와 샘플 품질(FID: Fréchet Inception Distance) 간의 상관관계를 분석하여, 계산량을 증가시킬수록 성능이 개선된다는 점을 확인했습니다.
기존 U-Net 기반 모델의 inductive bias가 필수적이지 않음을 보이며, Transformer를 활용하여 더 간단하면서도 강력한 구조를 설계할 수 있음을 입증했습니다.
실제로 DiT는 ImageNet (256×256 및 512×512 클래스) 조건 생성 작업에서 SOTA성능을 달성했습니다고 합니다.
2. Diffusion Transformers
Patchify
Patchify는 Vision Transformer (ViT)에서 나오는 개념인데,
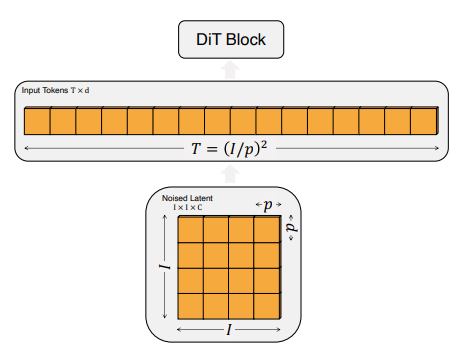
위의 그림과 같이 sine-cosine 값의 positional embeddings를 모든 입력 토큰에 적용시키면 로 T는 p에 의해 결정된니다.
(여기서 p는 패치 사이즈).
그리고 위 그림처럼 패치 사이즈 p를 절반으로 줄이면 T는 4배 커져 최종적으로 Gflops 또한 4배 커지게 됩니다. 하지만 전체 파라미터 수에는 큰 영향을 끼치지 않는다고 합니다.
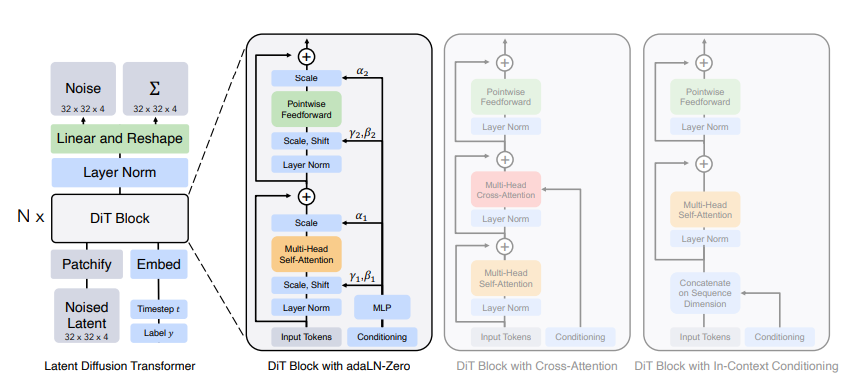
DiT block design

Diffusion 모델은 latent 외에도 noise timestep , class label , text embedding 등을 입력으로 받게된다. 이를 활용하여 조건부 정보를 처리하기 위해 다양한 입력을 받는 DiT block을 총 4가지 설계하였습니다.
- In-context conditioning: 벡터 임베딩 t와 c를 두 개의 추가적인 토큰으로 입력 시퀀스에 추가하여 이미지 토큰과 다르지 않도록 하였습니다. 이를 통해 ViT block을 사용할 수 있습니다. 마지막 block 후에는 입력 시퀀스로부터 conditioning 토큰을 제거하였습니다. 이를 통해 모델에 무시할만한 대한 새로운 Gflops를 도입합니다.
- Cross-attention block: t와 c 임베딩을 이미지 토큰 시퀀스와 별도로 길이가 2인 시퀀스로 concat하였습니다. Transformer block은 multi-head self-attention block에 이어 추가적으로 multi-head cross-attention을 포함하도록 수정하는데, 이는 class label에 대한 컨디셔닝을 위해 LDM에서 사용하는 것과 유사합니다. Cross-attention은 모델에 가장 많은 Gflops를 추가하게 되며, 거의 15%의 오버헤드를 갖습니다.
- Adaptive layer norm (adaLN) block: GAN이나 U-Net을 사용하는 diffusion 모델들에서 폭넓게 사용되는 adaptive normalization layer를 기존 Transformer의 layer norm 대신에 넣어 실험하였습니다. 이를 통해 얻은 block adaLN block은 최소한의 Gflops를 추가하였으며 가장 계산 효율적이었다고 합니다. 또한, 모든 토큰에 동일한 기능을 적용하도록 제한되는 유일한 컨디셔닝 메커니즘입니다.
- adaLN-Zero block: adaLN은 각 2개의 shift와 scale factor가 필요합니. 즉, 총 4개의 embedding vector가 MLP로 출력되는 것입니다. 그러나 adaLN-Zero는 scale factor a를 추가하여서 총 6개의 output이 나오도록 모델 구조를 설계하였습니다. 또한 이 scale factor 의 초깃값을 zero로 두고 시작하기 때문에, adaLN-Zero라고 이름이 붙였습니다.
또한 가 0이기 때문에 input_tokens 값만 살아남게 되므로, 처음 DiT block은 identity function이다.
Model size
DiT block 안에 있는 MLP들은 SiLU와 linear layer를 적용하는데, adaLN 또는 adaLN-Zero인지에 따라서 output 차원이 달라집니다. adaLN-Zero일 경우에는 transformer's hidden size의 6배에 해당하는 vector를 출력하게 됩니다.
추가로 Timesteps과 layer 정보에 대하여 embedding으로 들어오면 서로 dim-256 사이즈의 vector인데, 두 개의 vector를 더한 상태로 MLP에 넣어주게 됩니다.
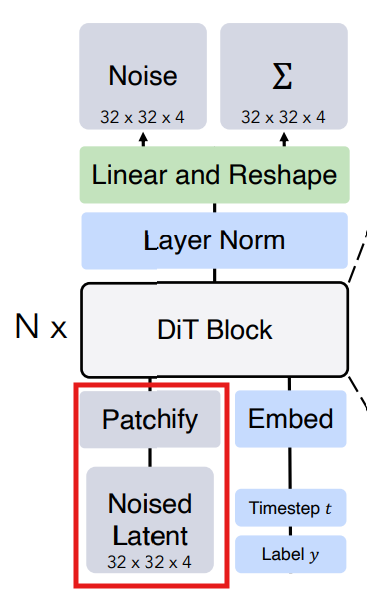
Transformer Decoder

마지막 DiT block 이후에는 이미지 토큰 시퀀스를 output noise prediction과 output diagonal covariance prediction으로 디코드해야합니다. 따라서 LayerNorm 적용하고, linear와 reshape을 적용한 다음에 각 patch size (pxp)마다 기존 channel size의 2배가 되는 output을 출력합니다.
그 결과 output은 위에서 보는 것처럼, 예측된 noise 값과 covariance 값입니다.
그 이후, VAE decoder에 noise 값을 넣어서 실제 이미지를 생성합니다
5. Experiment
모델 크기:
DiT-S, DiT-B, DiT-L, DiT-XL

Gflops ( Giga floating-point operations per second)
컴퓨터가 초당 수행할 수 있는 부동 소수점 연산의 수를 기가 단위로 나타낸 것으로, 숫자가 클수록 더 많은 연산을 빠르게 처리할 수 있다고 합니다.
6. Result
DiT block design
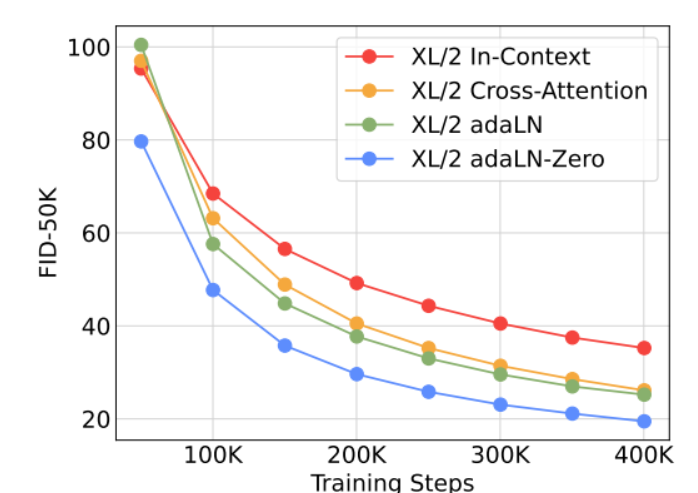
가장 큰 Gflops를 가지는 DiT-XL/2 모델에 대해 각기 다른 block 디자인을 적용해보았다.
In-context : 119.4 Gflops
Cross-attention : 137.6 Gflops
Adaptive layer norm (adaLN) or adaLN-zero : 118.6 Gflops
실험 결과는 adaLN-zero가 가장 좋은 성능을 보였습니다. 이를 통해 똑같은 adaLN이라도 zero-initialization을 사용하는 것에 대한 중요성을 알 수 있습니다.
Scaling model size and patch size
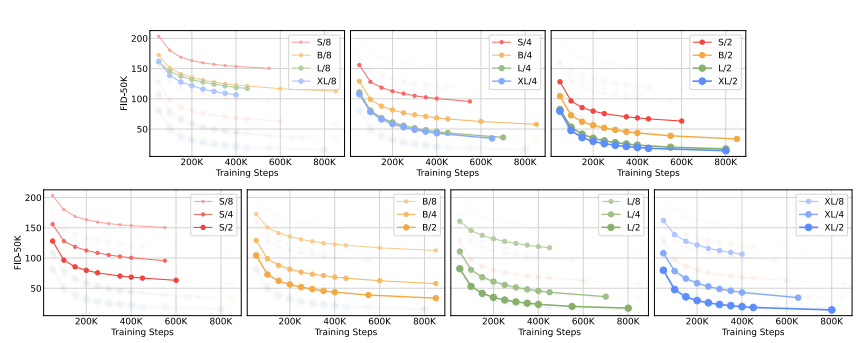
모델 규모 및 패치사이즈를 변화시키면서 실험해보았습니다. 큰 모델 규모와 작은 패치 사이즈를 갖는 것이 성능이 가장 우수합니다.
DiT Gflops are critical to improving performance
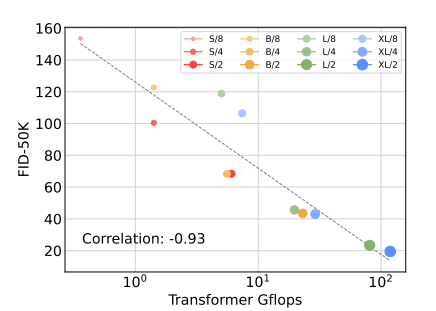
모델 규모 보다는 패치 사이즈의 변화가 성능 향상에 크게 기여하는 것을 알 수 있습니다. 패치 사이즈를 변화할 경우, 전체 파라미터 수는 변화가 거의 없으며 오직 Gflops만 증가합니다. 즉, Gflops가 증가함에 따라 성능이 감소한다는 것을 알 수 있습니다.
Larger DiT models are more compute-efficient

전체 학습 연산량 별 FID-50k 성능을 나타낸 것입니다. 학습 연산량은 Gflips x batch size x training steps x 3으로 추정하였다고 합니다. 이 때 3이 곱해지는 이유는 backward pass가 forward pass보다 2배 복잡한 연산을 가져 다음과 같이 3을 곱한다고 합니다. 실험 결과, 더 오래 학습된 작은 모델보다 적게 학습된 큰 모델이 더 높은 계산 효율성을 갖는다고 합니다.
더불어 패치 사이즈를 제외하고는 동일한 모델이라도 다른 Gflops를 제어할 때에도 성능 프로필이 다르다는 것을 알 수 있습니다.
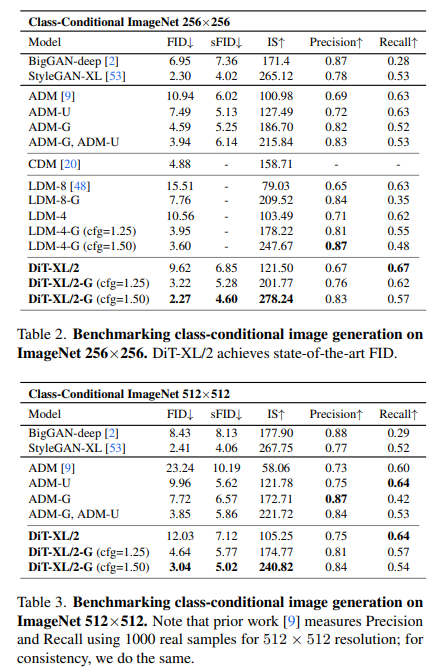
마지막으로 위의 표는 각 256x256, 512x512 ImageNet에 대한 결과로, 대부분의 평가지표에서 본 모델이 SOTA를 달성한 것을 알 수 있습니다.
마지막으로
ViT를 계승한 DiT가 scalability을 통해 대규모 데이터 처리 및 고품질 샘플 생성하는 방법이 재미었다. DiT 아키텍처를 다양한 도메인으로 확장하여 공부해보고 싶다.
