AudioBERT: Audio Knowledge Augmented Language Model 논문 리뷰
최근 관심이 생긴 교수님의 연구실에서 발표된 논문을 리뷰해보고자 합니다. 오디오 데이터 분야는 아직 많이 부족하지만 내가 지금까지 배웠던 지식과 이전에 리뷰하였던 BERT, 그리고 이 논문을 통해 새롭게 배운 지식들을 바탕으로 논문을 정리해보고자 합니다.
Abstract
AudioBERT는 텍스트와 오디오 데이터를 결합하여 언어 이해 및 생성 능력을 향상시키는 새로운 언어 모델입니다. 기존의 언어 모델은 텍스트 데이터만을 학습하여 음성적 맥락이나 음향적 정보를 놓치는 한계를 가지고 있었습니다. 이를 해결하기 위해 AudioBERT는 텍스트와 오디오 쌍 데이터를 학습하여 언어의 Linguistic(언어적) 및 Acoustic(음향적) 특성을 모두 포괄하는 표현을 학습합니다.
1. Introduction
연구 배경
최근 연구에 따르면, Text 전용 데이터셋으로 pretrained language model은 시각적 정보뿐만 아니라 음향적 정보도 부족하다는 한계가 밝혀졌습니다.
예를 들어, 일상적인 소리(동물 울음소리, 음조 등)에 대한 이해가 제한적입니다. 이러한 문제를 해결하기 위해 AudioBERT는 BERT 기반의 언어 모델에 오디오 지식을 주입하여 Text와 Audio 간의 상호작용을 학습하도록 설계되었습니다.
AudioBERT의 주요 목표
- Text와 Audio 데이터를 결합하여 멀티모달 표현 학습.
- 기존 text-only(텍스트 전용) 모델 대비 멀티모달 작업에서 성능 개선.
- AuditoryBench라는 새로운 벤치마크를 통해 음향 지식 평가.
2. Method
AuditoryBench
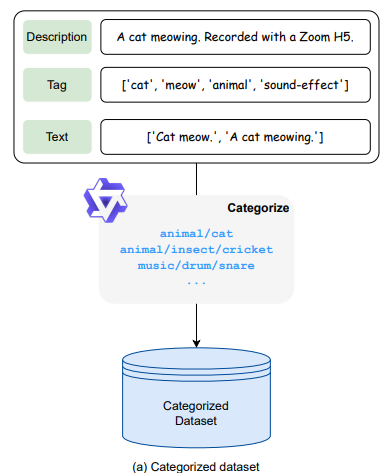
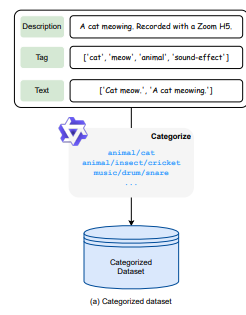
AuditoryBench는 AudioBERT의 성능 평가를 위해 개발된 데이터셋으로, 두 가지 주요 과제를 포함합니다:
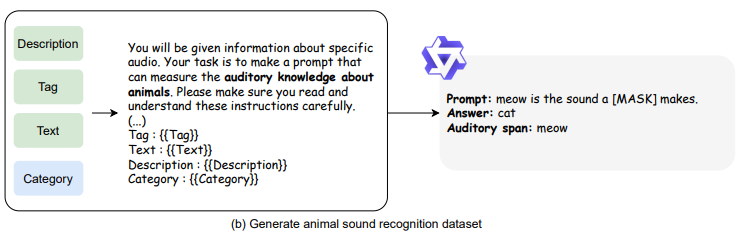
- Animal Sound Recognition(동물 소리 인식): 언어 모델이 특정 의성어(예: “meow”)에 해당하는 소리를 낼 가능성이 있는 동물을 예측하여 동물을 예측.
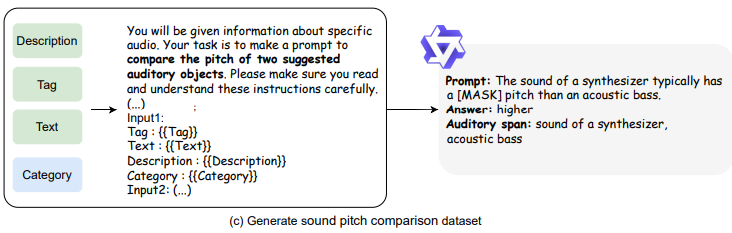
- Sound Pitch Comparison(음조 비교): 언어 모델이 어떤 소리 출처(예: 악기, 물체, 환경)가 더 높은 음높이의 소리를 낼 가능성이 있는
지 예측.
벤치마크 구축 및 결과
• 벤치마크 데이터셋의 확장성을 위해 LLM 기반 데이터 처리 파이프라인을 제안함.
• BERT, Gemma, LLaMA 세 가지 언어 모델을 테스트한 결과, 모든 모델이 두 벤치마크 작업에서 낮은 예측 정확도를 보임.
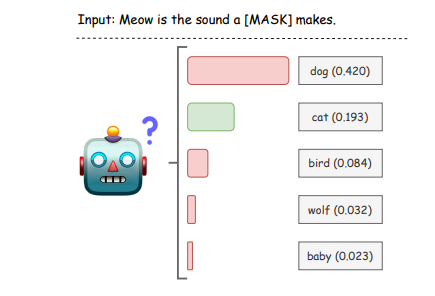
BERT 모델이 “meow”를 듣고, 마스킹된 단어에 대해 예측한 확률 분포
=> 놀랍게도 '강아지'가 가장 높은 확률을 보였다.
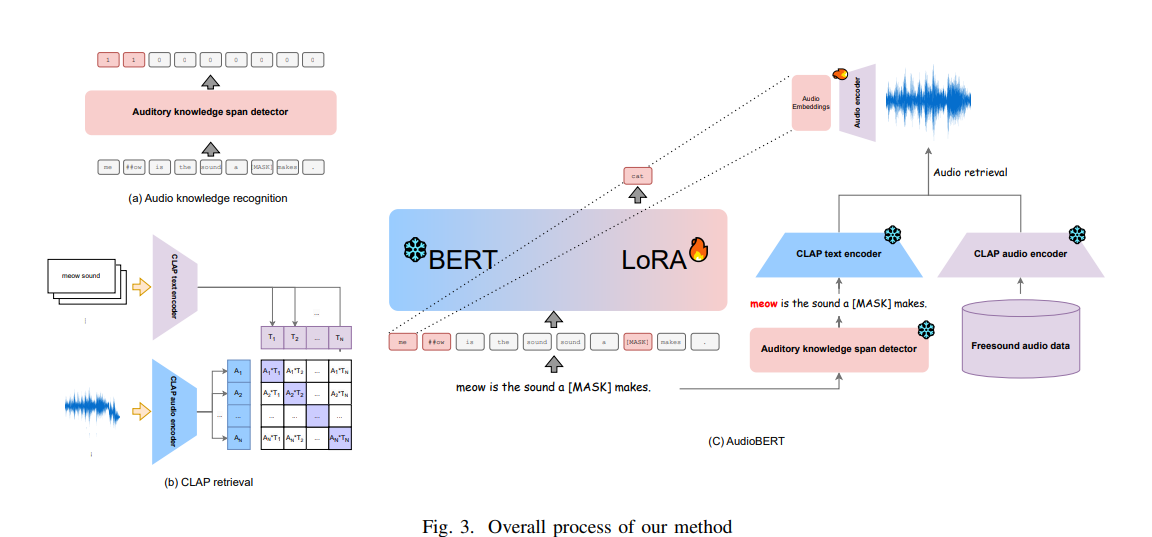
AudioBERT의 접근방식
- 청각적 지식이 필요한 text span을 감지합니다.
- 필요할 때마다 감지된 text span을 CLAP에 쿼리하여 관련 오디오를 검색합니다. CLAP는 텍스트-오디오 유사성을 측정하는 모델입니다.
- 검색된 오디오 샘플의 임베딩을 언어 모델에 주입합니다.
- 감지기가 청각적 span을 식별하면 언어 모델은 Low-Rank Adaptation (LoRA) 가중치를 활성화합니다. 이 가중치는 AudiotoryBench로 미세 조정되어 있습니다.
- 이 방식은 모델의 사전 학습된 지식을 유지하며, 다른 작업에서도 모델이 잘 수행할 수 있게 합니다.
AudioBench와 AudioBERT를 다시 한 번 정리해보겠습니다.
A. AuditoryBench
: AuditoryBench는 언어 모델의 청각적 지식을 평가하기 위한 최초의 benchmark 데이터셋입니다.
-
LAION-Audio-630K 데이터셋을 기반으로 구축
-
LLM을 활용한 데이터 처리 파이프라인 사용
-
두 가지 주요 작업으로 구성:
1. 동물 소리 인식: 의성어를 듣고 해당 동물 예측
2. 소리 음높이 비교: 두 소리 출처의 음높이 비교
-
데이터셋 구성:
• 훈련/개발/테스트 세트로 70%/10%/20% 분할
• Wikipedia에서 추가 테스트 데이터 수집 -
데이터 품질 보장을 위한 조치:
• pitch(음높이) 차이가 10% 이상인 쌍만 선택
• LLM이 높은 pitch를 정확히 분류할 수 있는 데이터만 포함
• Wikipedia에서 악기의 pitch 범위를 수집하여 테스트 세트로 사용
B. AudioBERT
: AudioBERT는 언어 모델에 청각적 지식을 주입하기 위한 검색-기반 framework입니다.
1. 청각적 지식 span 감지기:
• Text에서 청각 관련 span 추출
• Transformer Encoder 기반, 교차 엔트로피 손실 사용
2. CLAP (Contrastive Language-Audio Pretraining):
• Audio-Text 유사도 측정 모델
• 대조 학습 방식으로 훈련 ( cos ( · , · ) 이용해 비교)
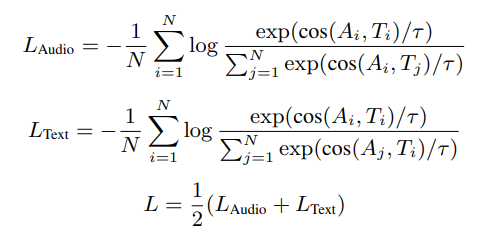
여기서 와 는 각각 Audio 임베딩과 Text 임베딩을 나타내며, cos( · , · )는 코사인 유사도를 의미하고, 는 온도 파라미터입니다.
3. AudioBERT Framework:
• 청각 지식 스팬 감지 → CLAP으로 관련 오디오 검색 → 오디오 임베딩 생성 → 언어 모델에 주입
• LoRA를 활용한 동적 적용: 청각 지식 필요 시 LoRA 가중치 활성화
• 마스크 언어 모델링 손실 사용
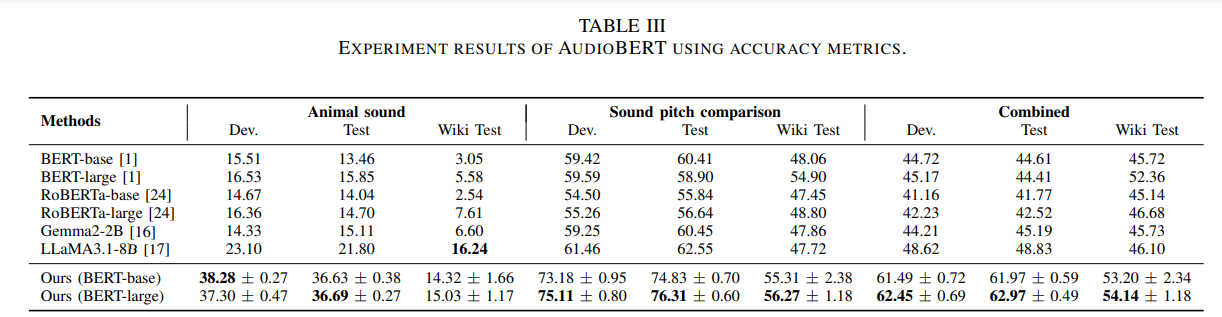
- 성능:
• AuditoryBench 테스트 세트에서 40% 이상의 정확도 향상
• 기존 언어 모델(BERT, RoBERTa, Gemma2-2B, LLaMA3.1-8B)보다 우수한 성능
3. Experiment
평가 지표
• 정확도(accuracy)와 F1 score 사용
• 높은 점수일수록 더 나은 성능 의미
F1 score
F1 score는 머신러닝 모델의 성능을 평가하는 데 사용되는 중요한 지표 중 하나로, 정밀도(Precision)와 재현율(Recall)의 조화 평균을 계산하여 모델의 정확성과 감지 능력을 균형 있게 평가합니다.

• 정밀도(precision) =
• 재현율(recall) =
• : 참 양성, : 거짓 양성, : 거짓 음성
(참 양성, True Positive)
• 모델이 양성으로 예측했고, 실제로도 양성인 경우
• 예: 고양이 소리를 고양이로 정확히 분류한 경우
(거짓 양성, False Positive)
• 모델이 양성으로 예측했지만, 실제로는 음성인 경우
• 예: 개 소리를 고양이로 잘못 분류한 경우
(거짓 음성, False Negative)
• 모델이 음성으로 예측했지만, 실제로는 양성인 경우
• 예: 고양이 소리를 다른 동물로 잘못 분류한 경우

-
Auditory knowledge span detector(청각적 지식 범위 탐지기)로 BERT-base 모델을 사용. 이 모델은 다음과 같은 설정으로 학습:
에폭 수: 5
배치 크기: 16
학습률:
Optimizer: AdamW -
AudioBERT의 훈련에서는 언어 모델로 BERT를 사용하고, 청각적 지식 임베딩 삽입을 위해 AST 인코더를 실험. AudioBERT의 학습 설정:
에폭 수: 20
배치 크기: 32
학습률:
Optimizer: AdamW
4. Results
Auditory knowledge span detector(청각적 지식 스팬 감지기)
- 단일 데이터로 훈련 시 성능이 좋지 않을 수 있음
- 결합 데이터셋 사용 시 소리 음높이 비교에서 성능 향상
AudioBERT
- 기존 언어 모델(BERT, RoBERTa, Gemma2-2B, LLaMA3.1-8B)과 비교
- 기존 모델들은 청각적 지식 부족 보임
- AudioBERT는 경쟁력 있는 성능 보여 청각적 지식 증강 효과 입증
Data quality assessment(데이터 품질 평가)
- AuditoryBench 구축 시 데이터 필터링 과정:
• 동물 소리 인식: 인간 주석자가 부적절한 레이블 제거
• 소리 음높이 비교: 각 오디오 샘플 음높이 측정, 올바르게 레이블된 것만 유지 - 위키피디아 정보로 테스트 세트 보강하여 일반화 및 견고성 측정
- 인간 평가 실시:
• 3명의 평가자가 정확성(100점 만점)과 유창성(3점 만점) 평가

위의 표와 같이 Animal sound recognition(동물 소리 인식), Sound pitch comparison(소리 음높이 비교)에서 모두 준수한 성능
마지막으로
AudioBERT의 음향적 정보의 중요성을 강조하면서 Text와 Audio 데이터를 결합하여 학습하는 접근 방식이 흥미로웠다. 이를 바탕으로 Audio분야뿐만 아니라 LLM 혹은 Image-to-Text 분야 등에서도 이러한 접근 방식을 적용하여 멀티모달 작업에 응용, 공부해볼 예정이다.
