NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 논문 리뷰
논문: https://arxiv.org/abs/2003.08934
github: https://github.com/yenchenlin/nerf-pytorch
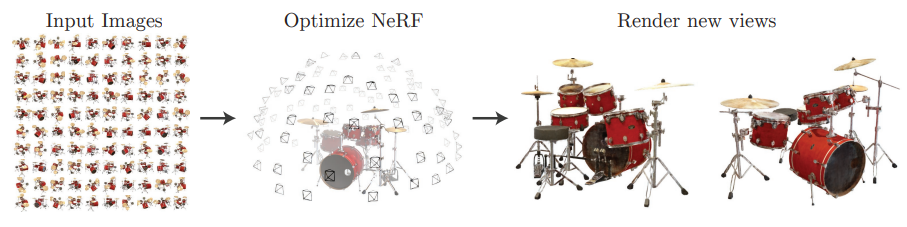
오늘 리뷰할 논문은 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis이다. 3D Image 생성을 공부하면서 NeRF에 대한 개념이 자주 나와 NeRF를 공부해야겠다라는 생각을 하게 되었고, 논문을 리뷰하고자 한다.
1. Introduction
View Synthesis(뷰 합성)은 주어진 이미지 세트에서 관찰되지 않은 시점의 이미지를 생성하는 작업으로, 기존 방법들은 복잡한 3D 장면의 기하학적 구조와 광학적 특성을 제대로 표현하지 못하는 한계가 있었습니다.
NeRF는 이러한 문제점들을 해결하여, 적은 메모리로도 높은 성능의 3D rendering을 할 수 있는 방법입니다.
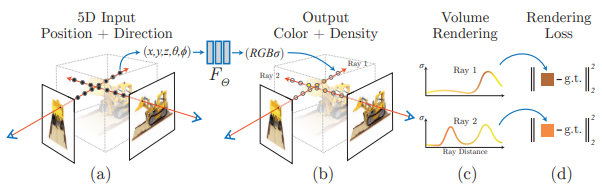
NeRF는 연속적인 5D 좌표(공간 위치 와 시점 방향 )를 입력으로 받아 해당 위치의 볼륨 밀도(density)와 시점 의존적 방출 복사율(emitted radiance)을 출력하는 신경망을 사용합니다.
이 내용을 정리하자면
- 2D Image와 카메라 시점 정보로 ‘2D Pixel 좌표’ 1개 점에 맵핑되는 ‘3D Voxel 좌표’위치를 계산 할 수 있고, 반대로 3D Voxel 좌표들의 Color값과 Density값의 SUM으로 각 2D Pixel의 RGBA을 표현 할 수 있습니다.
- Train시, 카메라 시점(𝜃,𝜙)와 voxel 좌표(x,y,z)를 입력으로 하고, RGB와 Volume Density(𝜎)를 출력으로 하는 함수F를 정의하여, FCN(Fully Connected Network)으로 함수F 모델을 학습합니다.
- Inference시, 새로운 카메라 시점(𝜃,𝜙)이 입력으로 주어지면, Train한 모델로 3D Voxel 좌표에서의 RGB𝜎값을 계산한 후, 대응되는 2D Pixel 좌표로 Summation함으로써 색상 값을 Prediction합니다.
그 결과:
- 복잡한 장면의 세부 기하학 및 광학적 특성을 고해상도로 표현 가능.
- 기존 뷰 합성 방법보다 더 높은 품질의 결과 제공.
2. Related Work
NeRF는 기존의 3D 장면 표현 및 뷰 합성 연구를 기반으로 발전했습니다. 관련 연구는 크게 세 가지로 나뉩니다:
Explcit Representation(명시적 표현):
- 메쉬(mesh)나 보텍스(voxel) 기반의 3D 표현 방식.
- 제한된 해상도와 복잡한 장면 처리에 어려움이 있음.
Implicit Representation(암묵적 표현):
- 신경망을 활용하여 연속적인 장면 표현.
- NeRF는 이러한 접근 방식을 확장하여 고해상도 뷰 합성을 가능하게 함.
Volume Rendering(볼륨 렌더링):
- 고전적인 볼륨 렌더링 기술을 활용하여 NeRF가 자연스럽게 미분 가능하도록 설계됨.
3. Neural Radiance Field Scene Representation
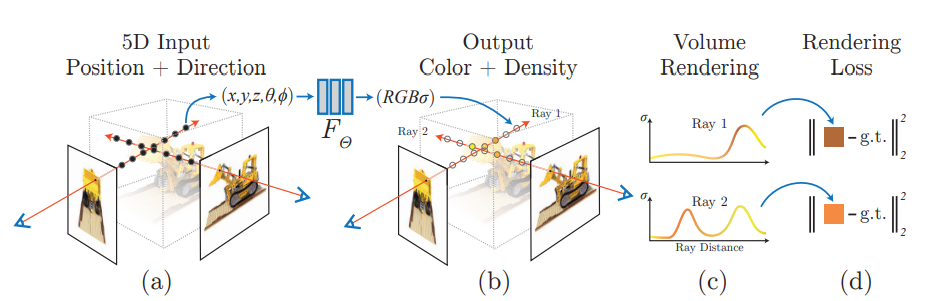
위에서 언급했던 것처럼 위 그림은 NeRF의 구조 입니다.
가 입력으로 MLP인 에 들어가게 됩니다. 그리고 는 ray 상의 RGB값과 density를 반환해줍니다.
그 후 는 위치 정보를 받고 density(𝜎)를 예측하도록 하면서 여러 방향에서도 일관성이 있는 이미지를 생성할 수 있게 합니다.
MLP인 의 구조는 먼저 3D를 ReLU 포함 8개의 FC layer를 통과하여 density(𝜎)와 256 차원의 특징 벡터를 얻습니다. 256 차원의 특징 벡터에 아까 사용하지 않았던 를 붙여서 FC+ReLU 한 층을 통과시켜 128 차원의 RGB 값을 얻어냅니다.
이 방식은 물체의 같은 위치라도 바라보는 방향에 따라 다른 RGB값을 가질 수 있으며 입력 값으로 viewing direction이 들어가지 않으면 이미지의 질이 떨어지는 것도 확인할 수 있습니다.
결과로 얻어진 RGB𝜎는 volume rendeing을 통해 하나의 픽셀 값으로 적분됩니다.

위 그림은 물체(배)를 같은 위치라도 바라보는 방향에 따라 픽셀 값이 달라질 수 있음을 보여줍니다.

다음 그림은 viewing direction을 학습에 사용하지 않은 경우, 생성된 이미지의 선명도가 떨어지는 것을 볼 수 있습니다. 특히, 바퀴를 보면 빛이 비침에 따라 검정색 바퀴가 다르게 보이는 것을 확인할 수 있습니다.
4. Volume Rendering with Radiance Fields
MLP를 통해 얻어진 RGB𝜎는 ray 상에 존재하는 density(𝜎)와 RGB 값을 의미합니다. 이게 이미지 상에서는 어떤 색으로 보일지 계산하기 위해서 volume rendering이라는 과정을 거치게 되고 아래의 식으로 나타냅니다.
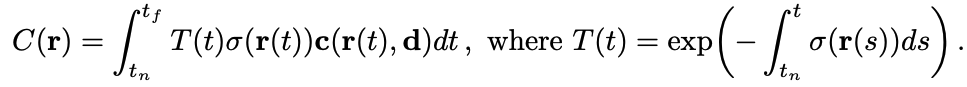
Ray 상에서 계산이 시작되는 부터 까지 연속적으로 적분을 하게 됩니다.
여기서 는 ray 정보, 𝜎는 density 정보, 는부터 까지 빛이 투사되는 정도, 는 최종적으로 예측된 픽셀 값입니다.
하지만 위의 식은 범위가 연속적이라는 가정이 있어 실제로 컴퓨터 상에서 이런 연속적인 계산을 하기가 힘듭니다. 그래서 부터 를 이산적인 범위로 나누어서 적분을 진행하게 됩니다.
Deterministic quadrature를 사용하여 적분하면 고정적인 위치를 쿼리로 주게 되어 성능이 저하된다고 합니다. 그렇기에 그래서 부터 를 같은 길이로 나눈 stratified sampling을 하였다고 합니다.
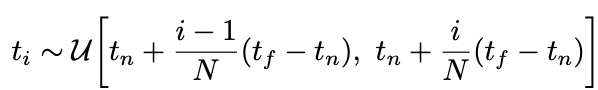
위의 식을 해석하자면 (n=near) 좌표부터 (f=far)까지의 구간을 N개로 균일하게 나누고, i번째 좌표에 대한 U(집합)을 로 표현하였습니다.
stratified sampling한 값에 추가적으로 이산개의 균일하게 구간(bin)을 아래처럼 계산을 하여 픽셀 값을 계산한다고 합니다.
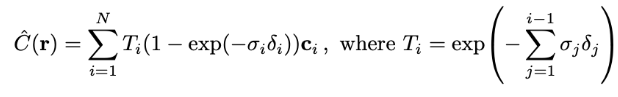
여기서 는 나뉘어진 bin의 길이입니다.
5. Optimizing a Neural Radiance Field
Positional Encoding
네트워크 입력 차원이 총 5개로 설계 되었습니다.
입력 차원이 다차원일수록 잘 학습되기 때문에 Positional encoding을 사용하여 token에 더해주면서 모델이 token의 위치를 파악하게 할 수 있게끔하는 사용합니다.
Positional encoding은 learnable parameter가 따로 없고, 아래처럼 sinusoidal 함수를 사용합니다.
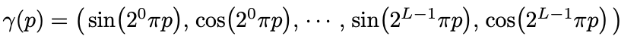
논문에서 Positional encoding을 할때, 위치 정보와 방향 정보를 따로따로 나누어서 encoding해주었다고 합니다
Hierarchical volume sampling
앞에서 말했 듯이 volume rendering에서 적분을 할 때 ray 상의 구간을 이산적으로 나누어 적분합니다. 이 과정을 더 효과적이고 효율적으로 하기 위해 sampling 과정을 거치게 됩니다. 이미지를 렌더링할 때 사실상 물체에 가려진 뒷 부분이나 아무 것도 없는 허공은 크게 계산을 하는데 의미가 없습니다. 이러한 점 때무에 NeRF에서는 를 coarse network과 fine network로 두 개를 사용합니다.
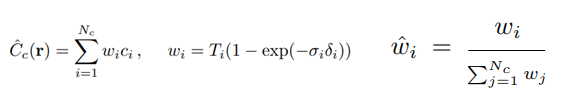
Coarse network에서는 앞에서 나온 stratified sampling 방법대로 구간을 균일하게 나눈 뒤 렌더링을 합니다. 이 때 나왔던 좌표들에 대해 Color값들을 계산 한 후에, 앞서 설명한 Color을 계산하기 위해 사용한 불투명도인 를 사용하여, Ray에 대한 PDF(확률밀도)을 계산합니다.
PDF를 적분하여 CDF(누적분포)를 계산한 후, 난수값으로 Sampling을 합니다. 그렇게 되면, 가 큰 구간에 대해서, 좀 더 많은 좌표들을 Sampling 할 수 있습니다.
Implementation details
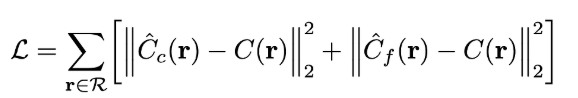
이 식은 NeRF의 Loss 함수입니다.
여기서 는 ground truth, 는 coarse volume, 는 fine volume을 나타냅니다.
학습을 할 때는 위 식과 같은 Loss를 흘려주면서 모델 학습을 진행합니다. Coarse prediction과 fine prediction 모두에 대해 GT view에 대한 MSE를 계산하여 Loss를 계산을 합니다.
그리고 의 loss도 최소화하는데, coarse network로부터의 weight distribution이 fine network에서 샘플들을 할당하는데 사용되기 때문이라고 합니다.
6. Results
- Diffuse Synthetic : DeepVoxels Dataset에서는 Lambertian Reflectance(겉보기 밝기)를 갖는 4개의 Object에 대해 512x512이미지를 사용하였고, 각각 Object에 대해 79개를 input 이미지, 1000개를 Test 이미지로 두었습니다.
- Realistic Synthetic : 논문에서는 추가로, non-Lambertian Reflectance를 갖는 8개 Object에 대해 800x800이미지를 사용하였고, 각 Object에 대해 100개를 input이미지, 200개를 Test 이미지로 두었습니다.
- Real Forward-Facing : 정면에서 촬영한 Real Scene 8장면에 대해 1008x756 이미지를 사용하였고, 각 Scene마다 20~62개의 이미지를 사용하여, input이미지로 7/8, Test이미지로 1/8을 사용하였습니다.

위 표를 통해 NeRF가 다른 모델에 비해 복잡한 이미지도 선명하게 잘 만들어내는 것을 알 수 있다.
그리고 각 평가 지표에 대해 간단히 설명하면,
- PSNR(Peak Signal-to-Noise Ratio) : 두 이미지 간의 픽셀 오차가 적을 수록 PSNR값이 높습니다.
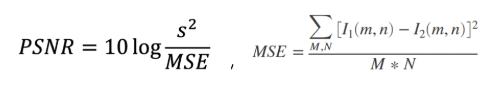
- SSIM(Structural Similarity Index Map) : 두 이미지간의 상관계수를 Luminance(휘도), Contrast(대비), structural(구조) 총 3가지 측면에서 평가합니다. 이 때 픽셀의 평균, 분산으로 평가값이 높을 수록 유사도가 높습니다.
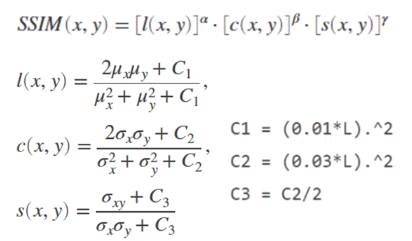
- LPIPS(Learned Perceptual Image Patch Similarity) : Pretrained Alexnet을 활용하여 Image Feature를 추출하고 distance를 계산값이 작을 수록 유사도가 높습니다.
Ablations
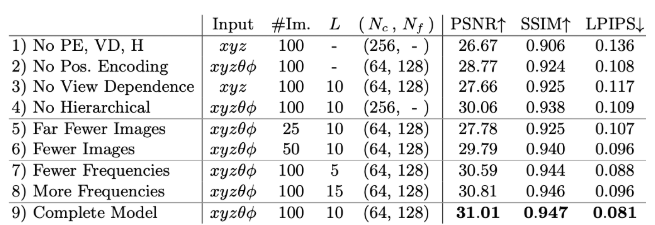
- 입력 이미지 수(#Im)의 영향:
훈련 입력 이미지의 개수가 증가할수록 모델의 성능이 향상됩니다 - Positional Encoding:
L 값은 위치 인코딩의 복잡도를 나타냅니다3.
적절한 L 값 선택이 모델 성능에 중요한 영향을 미칩니다. - 샘플링 포인트 수:
N_c는 Coarse 모델에서, N_f는 Fine 모델에서 각 광선(Ray)당 샘플링되는 포인트의 개수를 의미합니다
샘플링 포인트 수 증가는 일반적으로 성능 향상으로 이어집니다. - 계층적 샘플링의 중요성:
Coarse 네트워크와 Fine 네트워크를 사용한 계층적 샘플링 방식이 성능 향상에 크게 기여합니다 - 위치 인코딩의 효과:
고주파 정보를 더 잘 포착하여 전반적인 렌더링 품질을 개선합니다.
마지막으로
NeRF가 무려 5년전(2020년)에 출시된 논문이다보니 Transformer처럼 NeRF에서 발전되고 개선된 연구들이 많이 나왔다. NeRF 후속 여러 논문들에 대해 공부하고 리뷰하고자한다.
