LoRA: Low-Rank Adaptation of Large Language Models 논문 리뷰
논문: https://arxiv.org/abs/2106.09685
github: https://github.com/microsoft/LoRA
SVD(Stable Video Diffusion) 논문을 공부하면서 간단하게 공부하였던 LoRA에 대한 논문 리뷰를 한다고 하였다. 미루고 미루다 이제서야 제대로 LoRA를 다뤄보고자 합니다.
LoRA(Low-Rank Adaptation) 논문은 대규모 언어 모델(LLM)의 효율적인 파인튜닝(fine-tuning)을 위한 새로운 접근법을 제안합니다. 이 논문은 특히 GPT와 같은 Large Language Models(LLM)을 특정 task에 fine-tuning(adaptation)하는 데 있어서 time, resource cost가 너무 크다는 단점을 해결하기 위한 방법 모델에서 파라미터 효율성을 극대화하면서도 성능을 유지하거나 향상시키는 방법론을 다룹니다.
1. Introduction
LLM은 기본적으로 pre-trained model(대규모 사전 학습된 언어 모델)로부터 특정 task(e.g. summarization, question and answering, ...)에 adaptation하기 위해 파인튜닝을 해야 합니다. 대규모 사전 학습된 언어 모델의 파인튜닝은 자연어 처리(NLP)에서 필수적인 작업입니다. 하지만 모델 크기가 커질수록 모든 파라미터를 재학습하는 풀 파인튜닝(full fine-tuning) 방식은 비효율적이며, LLM모델의 weight parameters를 모두 다시 학습하게 되는데 이게 엄청난 cost를 가집니다.
LoRA는 이러한 문제를 해결하기 위해 저랭크 적응(Low-Rank Adaptation) 방식을 제안합니다. 핵심 아이디어는:
- 사전 학습된 가중치(pre-trained weights)를 고정하고,
- 각 Transformer 계층에 학습 가능한 저랭크(low rankdecomposition) 행렬을 삽입하여 필요한 파라미터 수를 줄이는 것입니다.
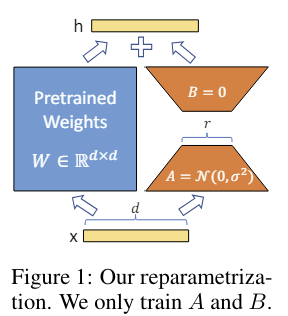
그래서 위 그림과 같이 fine-tuning시에 pre-trained weights W는 고정해두고 low rank decomposition된 weights A, B만 학습하고 W에 더하게 됩니다. Low rank로 decomposition된 weights는 기존 W보다 훨씬 작은 크기의 weight이기 때문에 time, resource cost를 줄일 수 있게 됩니다.
또한 pre-trained model을 가지고 있는 상태에서 특정 task에 adaptation하기 위해서 A와 B만 storage에 저장하고, 다른 task에 adaptation하기 위해 또 다른 만 갈아 끼우면 되기 때문에 storage, task switching면에서 매우 효율적입니다.
Terminologies and Conventions
Wq, Wk, Wv, Wo는 각각 query/key/value/output을 의미합니다.
또한 W와 W0는 pretrained weight이고 ΔW는 adapation을 할 때 축적되는 기울기 업데이트에 대한 값입니다.
2. PROBLEM STATEMENT
LoRA는 training objective에 상관없이 모두 사용가능하지만 해당 논문에서는 LLM에 맞추어 설명합니다.
1. 기존의 LLM모델(e.g. GPT)를 하나의 확률함수 PΦ(y|x)입니다.
이 때, y와 x는 context-target pair쌍이라고 할 수 있습니다.
2. 그리고 fine-tuning과정에서 LLM이 튜닝되는 Φ가 최적화 되는 식은 다음의 식(1)으로 표현됩니다.
이 때, Log-likelihood function으로 문제를 해결할 때 가장 적합한 파라미터 Φ의 나올 확률을 최대화 하는 것입니다.
직관적으로 backpropagation할 때의 모델을 나타내면, 이 됩니다.
3. 위의 식에 근거하여 만약 accmulated gradient values(ΔΦ)를 기존보다 훨씬 적은 파라미터인 Θ로 치환하여 ΔΦ(Θ)로 나타내면 다음의 식(2)으로 바뀌게 됩니다.
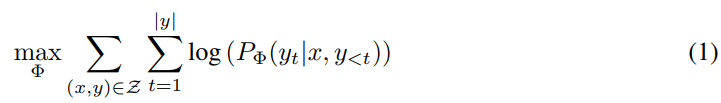
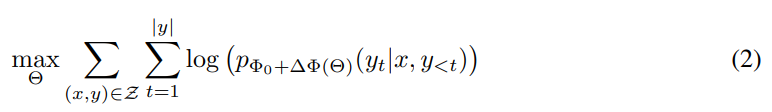
4. Our Method
4.1 LOW-RANK-PARAMETRIZED UPDATE MATRICES
Transformer 모델의 Dense Layer는 일반적으로 다음과 같은 행렬 곱셈으로 표현됩니다:
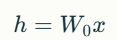
여기서 는 사전 학습된 가중치입니다. LoRA는 가중치 업데이트 를 다음과 같이 저랭크 분해합니다:
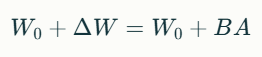
여기서:
- ,
- : 저랭크 조건.
그리고 훈련과정에서 는 gradient update를 하지 않고, 오히려 를 학습하는 과정으로 이루어집니다.
따라서 수정된 forward pass는 다음과 같습니다:
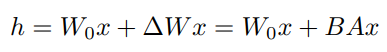
A는 random Gaussian initialization되고 B는 0으로 initialization됩니다. 그래서 training 시작 시에 도 0으로 initailization됩니다.
No additional Inference Latency
LoRA를 사용하여 inference하려고 할 때는 기존 pre-trained weight 에 학습한 를 더해주면 되기 때문에 inference latency 성능 하락은 전혀 없습니다. 그리고 0을 기반으로 또 다른 task로 학습한가 있을 경우 대신 을 더해주어 사용하면 됩니다.
4.2 APPLYING LORA TO TRANSFORMER
Trainable weight를 최소화하기 위해 오직 LoRA를 Transformer의 attention weights인 Wq, Wk, Wv에만 적용하였고 나머지 MLP module에는 적용하지 않았습니다.
그 결과 1,750억개의 parameter를 가진 GPT-3에 대해 fine-tuning시에 원래 VRAM를 1.2TB사용하던 것이 LoRA를 통해 350GB로 줄어들었습니다. 또한 training speed또한 25%가량 줄었다고 합니다.
5. EMPIRICAL EXPERIMENTS
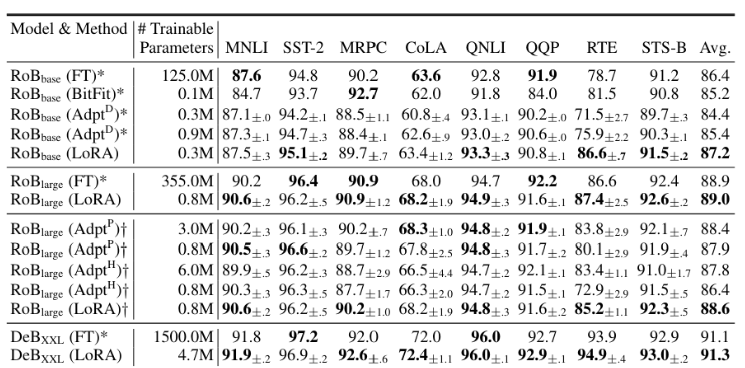
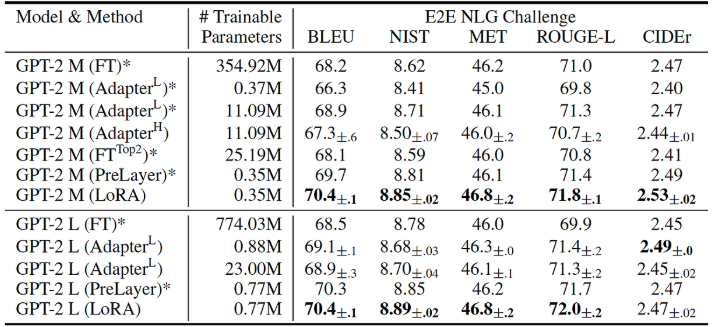
BERT계열 모델 실험 결과을 보면 NLU에서 좋은 성능을 보였고, GPT-2기준 성능비교 시 기존 방법들보다 trainable weight도 적으며 다양한 데이터셋에 대해 성능도 잘 나왔습니다.
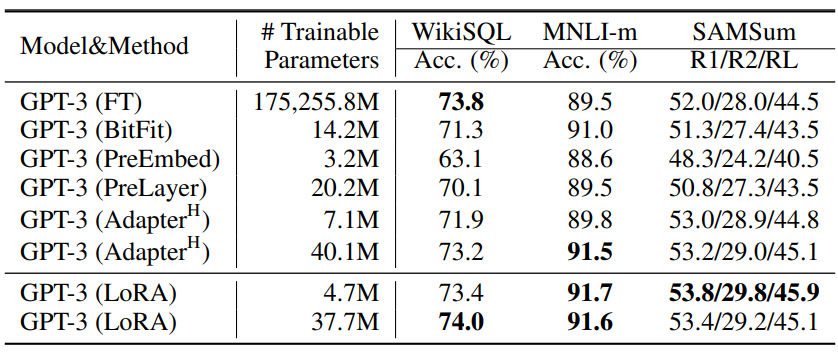
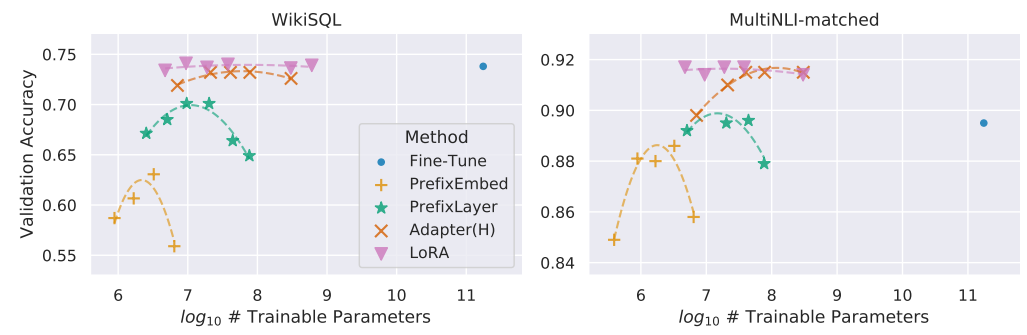
LoRA를 이용하였을 때 해당 fields에서 SOTA를 달성할 뿐만 아니라, 특히 GPT-3 175B에서는 LoRA가 학습 가능한 파라미터 수를 약 10,000배 줄이는 데 성공했을 정도로 효율성이 좋습니다.
6. Analysis
Rank Deficiency
실험 결과, 대부분의 태스크에서 매우 낮은 랭크(r=1 또는 r=2)만으로도 높은 성능을 달성할 수 있음이 확인되었습니다.
Hyperparameter Sensitivity
LoRA는 하이퍼파라미터 조정에 민감하지 않으며, 초기값 설정만으로도 안정적인 결과를 얻을 수 있었습니다.
7. Discussion
LoRA는 다음과 같은 면에서 기존 방법론보다 우수합니다:
- Efficiency(효율성): 적은 자원으로도 높은 성능 달성합니다.
- Scalability(확장성): 하나의 사전 학습된 모델로 여러 태스크에 쉽게 적응 가능합니.
- No inference latency(추론 지연 없음): 어댑터 기반 방법론과 달리 추가적인 계산 비용이 없습니다.
마지막으로
SVD를 공부하는 과정에서 알게된 LoRA에 대해 리뷰를 해보았습니다. SVD에서 언급된 CLIP 임베딩과 LoRA에서 발전된 QLoRA에 대해서도 공부하여 리뷰를 작성하고자 합니다.
