ViT ; AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 논문 리뷰
현 시점 경량화, 최적화 등을 포함해 ML/DL 분야에서 가장 많이 쓰이고 있는 방법론 중 하나인 Transformer를 다루고, 다음으로 내가 공부하고 있는 이미지와 텍스트와 결합된 ViT(Visual Transformer)에 대해 다루고자 합니다.
1. Introduction
Vision Transformer(ViT)는 컴퓨터 비전 분야에서 Transformer 모델을 적용한 혁신적인 접근법으로, 기존의 Convolutional Neural Networks(CNN, 합성곱 신경망) 기반 모델과는 다른 특징을 가지고 있습니다. ViT는 이미지를 여러 고정 크기의 패치로 분할하고, 이를 단어처럼 처리하여 Transformer 구조에 입력합니다. 이 모델은 특히 이미지 분류와 같은 작업에서 뛰어난 성능을 보이며, 대규모 데이터셋에서 CNN을 능가하는 결과를 보여주었습니다.
2. RELATED WORK
NLP
Transformer: 현재 많은 NLP Task에서 가장 좋은 성능을 보여주는 구조.
BERT: 노이즈를 제거하는 자기지도 사전학습을 수행 ; 양방향 언어 모델링
GPT: 언어 모델을 사전학습 태스크로 선정하여 수행 ; 일방향 언어 모델링
기존 연구와 ViT의 차별점
표준 ImageNet 데이터셋보다 더 큰 크기의 데이터셋에서 image recognition 실험을 진행하여 더 큰 크기의 데이터셋에서 학습시킴으로써 기존의 ResNets 기반 CNN보다 더 좋은 성능을 낼 수 있었습니다.
3. Method
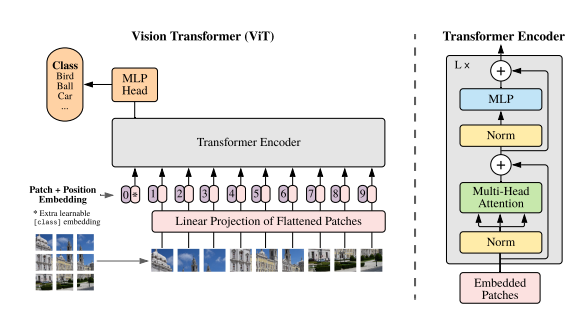
Vision Transformer(ViT)
위의 그림은 ViT의 구조입니다.
Transformer Encoder는 Transformer와 비슷한 역할을 하고, Multi Head Attention의 구조는 기본적으로 Transformer의 형식을 따릅니다.
Patch Embedding
기존의 Transformer는 1차원의 토큰 Embedding들의 Sequence를 입력으로 받습니다. 하지만 이미지는 2차원이기 때문에 2D이미지를 1차원으로 변환하기 위한 작업(Patch Embedding)을 합니다.
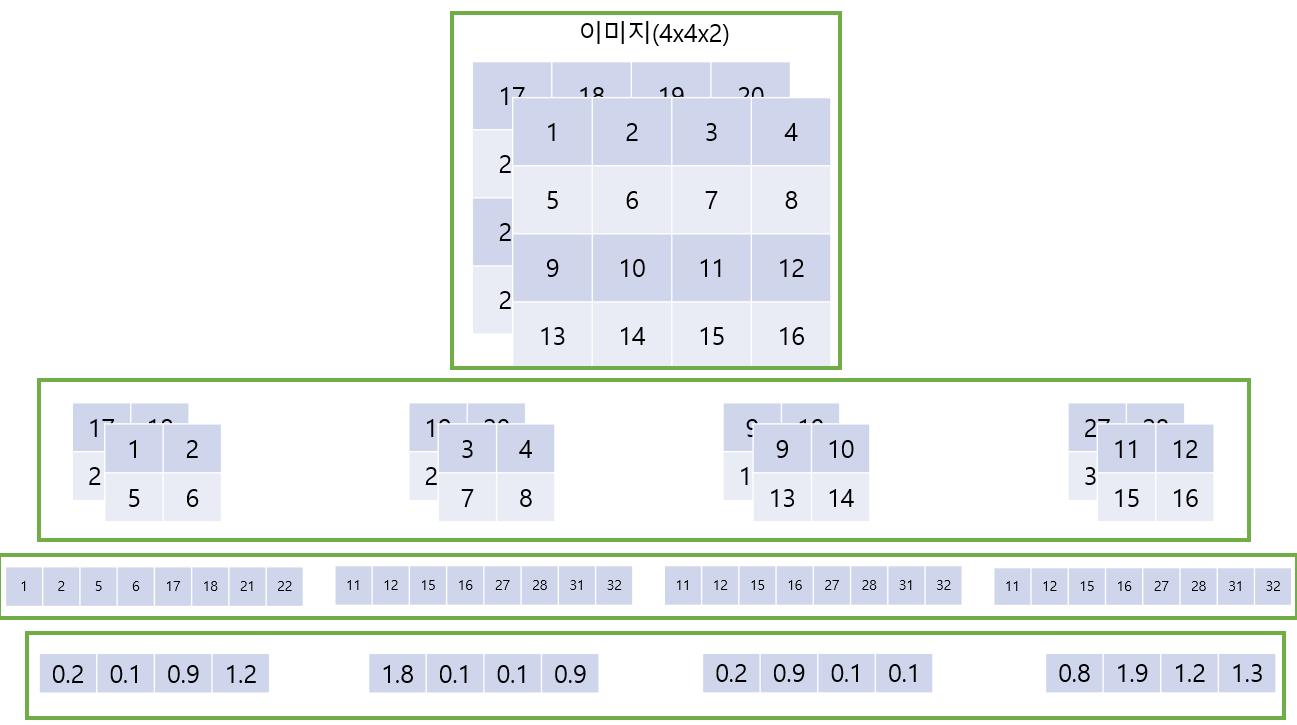
다음은 Patch Embedding에 대해 잘 표현한 그림이 있어 가져와봤습니다. (출처:https://velog.io/@pre_f_86/Vision-TransformerViT-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0)
위의 예시는 4×4×2의 이미지를 2×2 크기의 패치로 나누는 것으로 4크기의 벡터로 임베딩하는 것입니다. 그 과정을 정리해보면
-
(H 높이,W 너비,C 채널) 에 해당하는 이미지를 P×P크기의 패치로 나누어 줍니다.
-
Flatten 작업을 해주어 로 만들어줍니다. (N=HW/P^2)
-
각 패치의 크기를 D크기의 벡터로 임베딩 하도록 합니다.
-
각 출력을 (n=1,…,N) 이라고 정의한다.
-
자연어 처리 분야에서 BERT라는 모델에서 사용되는 [Class] 토큰과 비슷하게 Input Embedding 맨 앞에 [Class] Patch를 넣어 줍니다.
여기서 BERT에서의 [Class] 토큰은 입력할 때 의미를 가지고 있지 않은 토큰으로 모델 내부에서 다른 토큰들과의 정보를 주고받게되고 최종적으로 해당 문장에 대한 문맥 정보를 담는 토큰이 되어 이를 글 내에서의 감정 Classification과 같은 문제에 사용됩니다.
동일하게 [Class] Patch는 이후 Transformer Encoder의 출력() 중 맨 앞()에 대응되며 이는 Classification Head(MLP Head)에 입력으로 들어가 Classification 작업에 사용됩니다.
그 후 각 Embedding된 Patch들이 Encoder에 들어가기 전에 학습 가능한 Position Embedding을 더하여 각 Patch Embedding들에 위치에 대한 정보를 추가해줍니다.
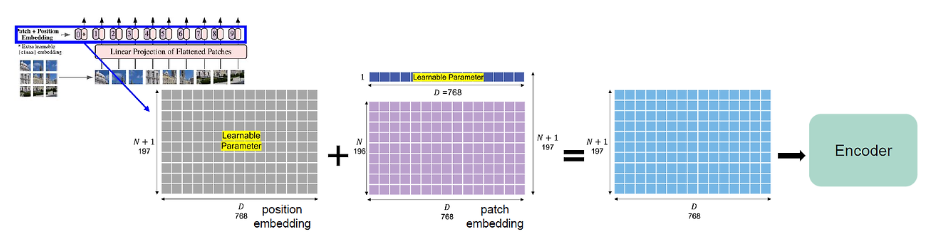
위의 동작들을 식으로 나타내면 다음과 같습니다.
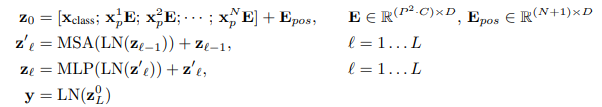
Inductive Bias
Inductive Bias는 학습에 사용되지 않은 데이터에 대해서 어떤 것에 대해 예측할 때 정확한 예측을 위해 사용하는 추가적인 가정입니다. CNN이나 RNN의 경우, Inductive Bias가 있어, Global한 영역에서의 처리가 어렵다는 단점이 있습니다.
하지만 ViT의 경우 Inductive Bias가 적습니다.
그렇다면 ViT는 왜 Inductive Bias가 적은지 알아보겠습니다.
우선 CNN의 경우 필터가 Sliding Window처럼 이미지의 모든 영역을 스캔하는 방식과 비슷하게 작동하는 것과는 다르게 ViT는 이미지를 패치로 나누어 작동하며 MLP는 한 패치 내부에서만 Fully Conneted형식으로 작동합니다.
Fully Connected형식은 픽셀에 대한 가중치로 연산을 하기 때문에 Convolution 연산과는 달리 MLP Layer에서만 Local 및 Translation Equivariance을 합니다.
이로 인해 전역에서 Local 및 Translation Equivariance하는 Convolution과 달리 Inductive Bias가 적다는 특징을 갖게 됩니다.
Translation Equivariance : Computer Vision에서 어떠한 객체를 검출하고자 할 때 해당 객체의 위치가 달라져도 동일하게 검출할 수 있도록 합니다. 즉, 입력의 위치가 달라져도 출력은 동일하다라는 것입니다.
Locality : 말 그대로 지역성이라는 개념으로 이미지 내에서 정보는 특정 지역에 담겨져 있으며 이 지역적인 특징을 담기 위해서 CNN에서는 여러 크기의 필터를 통해 지역적인 정보를 담습니다.
Hybrid Architecture
Raw image patch에 대한 대안으로, 입력 시퀀스는 CNN의 특성 맵에서 형성될 수 있습니다. Hybrid Architecture에서, 패치 임베딩 projection E는 CNN으로부터 추출된 Feature Map에 Patch Embedding 벡터 E를 적용시킨다.
특정한 경우에, 패치는 공간 크기 1x1을 가질 수 있는데, 이는 단순히 특성 맵의 공간적 차원을 flattening하고 트랜스포머 차원으로 projecting함으로써 입력 시퀀스를 얻을 수 있다는 것이다.
Fine-tuning and higher-resolution
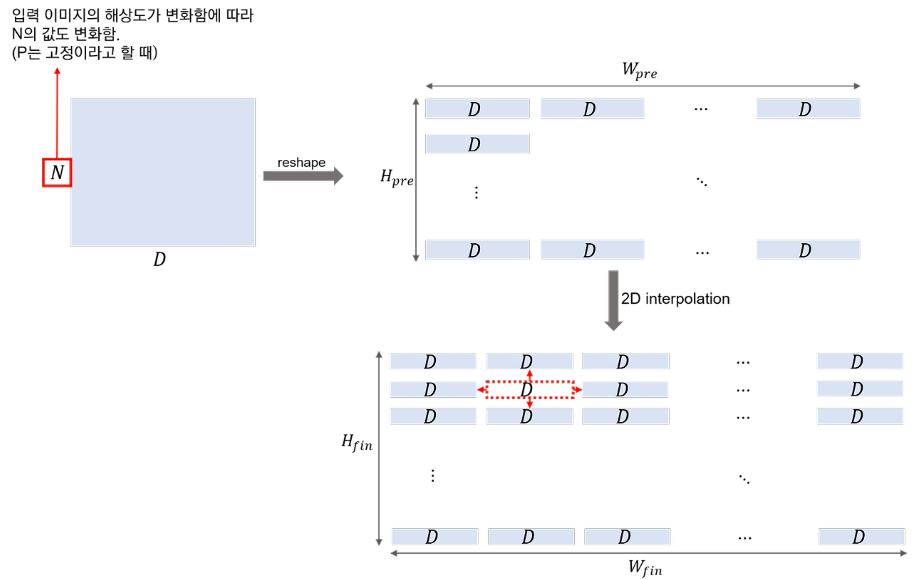
(이미지 출처: https://daebaq27.tistory.com/108)
사전 훈련 때보다 더 높은 해상도로 Fine-Tune 하는 것이 성능에 도움이 됩니다.
더 높은 해상도 및 Patch Size 동일하고 → Sequence 길이 증가하게 됩니다.
하지만 Fine-Tuning 시 Pre-trained Position Embedding은 더 이상 의미가 없어지게 된다는 단점이 있습니다.
이에 Pre-Trained Position Embedding을 통해 2D 보간(Interpolation)하여 값을 채워주게 됩니다.
3. Experiments
Model Variants
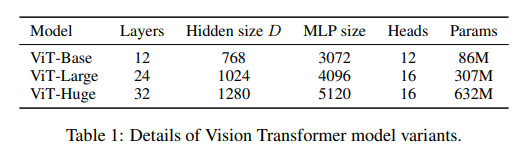
BERT에서 제안된 모델과 동일하게 ViT-Base,ViT-Large 모델을 구성하고 따로 ViT-Huge 모델을 구성합니다.
- ViT-L/16 : "Large" 매개변수 크기 및 16x16 Input Patch 사용
Data Requirements
ViT는 JFT-300M Dataset으로 사전학습시켰을 때 성능이 가장 좋았습니다.
그만큼 데이터 셋이 많으면 성능이 좋다는 것인데, 그럼 얼마나 많은 데이터셋이 필요한지에 대한 실험입니다.
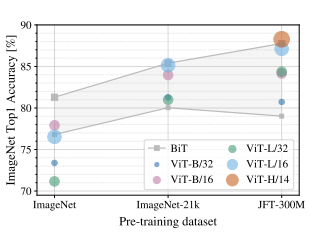
위 그림은 사전학습 시킨 데이터셋 별로 이후 같은 데이터셋(ImageNet)으로 Fine-Tuning한 성능 비교표입니다.
X축의 좌측부터 우측으로 데이터셋의 크기가 증가합니다.
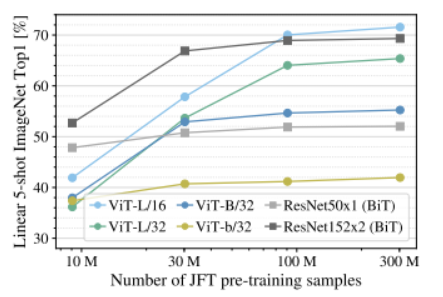
위 그림은 데이터셋의 크기에 따른 사전 학습 후 전이 학습 성능 비교입니다.
ResNet에 비해 데이터의 크기가 커지면 커질 수록 ViT의 성능 향상이 급격하게 증가됨을 알 수 있습니다.
Scaling Study
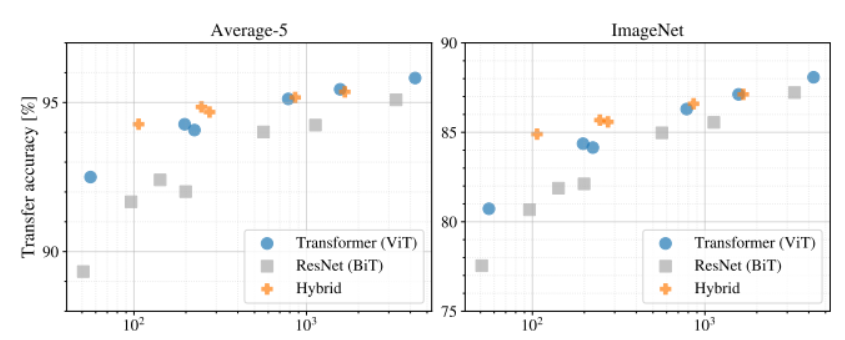
위 그림의 두 표를 비교해보면 모두 비슷한 양상을 보이며 같은 성능을 내기 위해 ViT가 BiT에 비해 약 2~4배정도의 적은 FLOPs를 소비한다는 것을 알 수 있습니다.
Hybrid 모델에서는 적은 Computational Cost에서는 ViT보다 성능이 좋지만 이후 차이는 점점 줄어들게 됩니다.
SOTA와의 비교실험
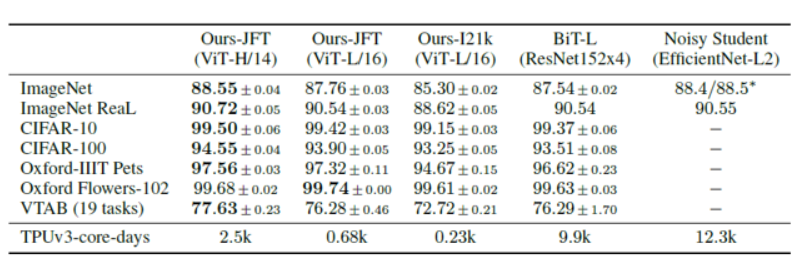
- 전이학습 평가를 위한 각 데이터셋 별 ViT 모델과 기존 전이학습 SOTA CNN 모델과의 (BiT-L / NoisyStudent) 성능 비교합니다.
- Fine-tuning을 각각 3번 진행하고 정확도의 평균과 표준편차를 계산하여 정확성을 평가합니다.
- TPUv3-core-days = 사전학습 시 사용된 코어 수 X 소요 일수 (효율성을 평가하는 지표)
- 중간 사이즈의 데이터셋: Baseline > ViT ; 큰 사이즈의 데이터셋: ViT > Baseline
- ViT의 경우 모델 파라미터(모델 규모)가 증가하고, 데이터셋의 크기가 증가할수록 지속적으로 성능이 증가합니다.
5. Conclusion
본 연구는 Transformer를 이미지 인식 태스크에 직접적으로 적용하는 과정을 탐구합니다. Computer Vision 분야에 self-attention을 사용한 선행 연구들과는 달리, 본 논문에서는 initial patch와 extraction step을 제외하면 image-specific한 귀납 편향을 네트워크 구조에 반영하지 않습니다.
그대신, 이미지를 패치 시퀀스로 해석하여, NLP에서처럼 표준 트랜스포머 인코더를 통해 처리한다. 이러한 단순하면서도 확장성 있는 방법은 대규모의 데이터셋에서 사전학습과 더불어 사용되었을 때 상당히 잘 작용한다.
이로인해, 비전 트랜스포머가 많은 이미지 분류 데이터셋의 SOTA 모델들과 필적하거나 그들을 뛰어넘으면서도, 사전학습 비용을 상대적으로 절감할 수 있다는 장점이 있습니다.
마지막으로
Transformer에 이어 ViT 논문을 리뷰해보았습니다. ViT 논문을 리뷰하면서 Vision Task관련 이해도가 조금은 증가할 수 있었고, 앞으로 BERT, GPT, LoRA와 같은 주제도 얼른 리뷰하고자 합니다.
