BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문 리뷰
Transformer와 ViT에 이어 BERT 논문을 리뷰하고자 합니다.
BERT(Bidirectional Encoder Representations from Transformers)는 Google AI에서 개발한 언어 표현 모델로, Transformer 아키텍처를 기반으로 합니다. Transformer는 self-attention 메커니즘을 통해 문맥 정보를 효과적으로 학습할 수 있으며, 이를 확장한 BERT는 양방향(bidirectional) 학습을 통해 문맥의 좌우 정보를 동시에 고려합니다. 이는 기존의 단방향(unidirectional) 언어 모델(OpenAI GPT 등)과 차별화되는 점으로, NLP 작업에서 뛰어난 성능을 발휘합니다.
1. Introduction
PLM(Pre-trained Language Model; 언어 모델 사전 학습)은 NLP 작업의 성능을 크게 향상시키는 것으로 알려져 있습니다. 기존 접근 방식은 크게 두 가지로 나뉩니다:
- Feature-based 접근: ELMo와 같은 모델이 사전 학습된 표현을 추가적인 특징(feature)으로 사용.
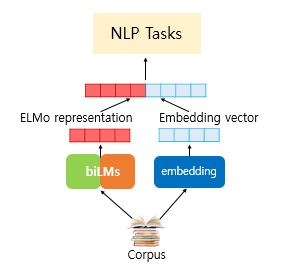
ELMo는 pre-trained representations을 하나의 추가적인 feature로 활용해 (down stream) task-specific architecture를 사용합니다.
쉽게 말해 bidirectional language model를 통해 얻은 representation을 embedding vector과 단순히 concat해준다고 생각하시면 됩니다..
- Fine-tuning 접근: OpenAI GPT처럼 사전 학습된 모델 전체를 미세 조정(fine-tune).
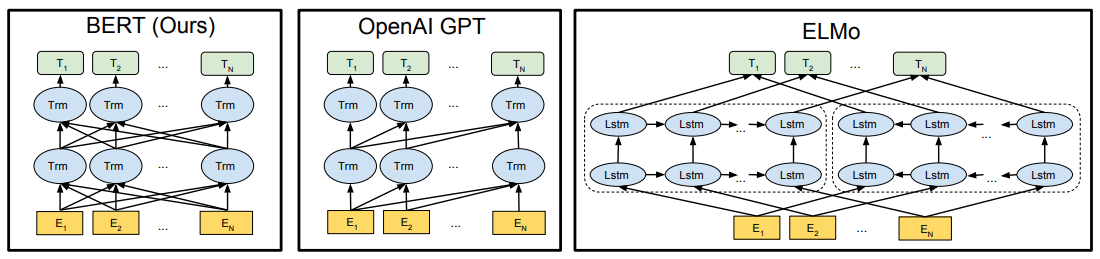
GPT(Generative Pre-trained Transformer)는 task-specific(fine-tuned) parameters 수 는 최소화하고, 모든 pre-trained 파라미터를 조금만 바꿔서 down stream task를 학습합니다.
그러나 기존 방법들은 주로 단방향 학습(left-to-right 또는 right-to-left)에 의존하여 문맥 정보를 제한적으로 활용했습니다. BERT는 이를 개선하기 위해 다음과 같은 혁신적인 방법론을 도입했습니다:
- Masked Language Model(MLM): 입력 텍스트에서 일부 단어를 마스킹(masking)하고 이를 예측하도록 훈련.
- Next Sentence Prediction(NSP): 두 문장이 연속적인지 여부를 판단하는 이진 분류 작업.
이를 통해 BERT는 깊은 양방향 표현을 학습하며, 다양한 NLP 작업에 적합한 범용 언어 모델로 자리 잡았습니다.
2. Related work
Unsupervised Feature-based Approaches
단어 혹은 문장의 representation 학습은 수십년 동안 진행되어 왔는데, 대표적으로 non-neural method와 neural method로 나뉩니다.
이러한 발전에 더불어, word embedding의 Pre-training은 오늘날 NLP 분야에서 굉장히 중요한 문제가 되었습니다.
또한 word embedding을 통한 접근 방식은 자연스레 sentence embedding 혹은 paragraph embedding으로 이어졌습니다.
sentence representations 학습의 경우 BERT 이전에는
- 다음 문장의 후보들을 순위 메기는 방법
- 이전 문장이 주어졌을때, 다음 문장의 left - to - right generation 방법
- denoising auto-encoder에서 파생된 방법
이 대표적으로 사용되었습니다.
이 후 ELMo와 그 후속 모델들은, 전통적인 word embedding 연구에서 한 층 더 발전하였는데, 바로 left-to-right와 right-to-left 언어 모델을 통해 context-sensitive feature들을 뽑아내는 방식입니다.
이렇게 생성된 토큰 별 contextual representation은 left-to-right, right-to-left representation의 단순 concat입니다.
left-to-right, right-to-left language model을 단순히 concat한 ELMo
그리고 BERT는 ELMo의 단순 concat하는것만을 넘어서 deep bidirectional를 하게 됩니다.
Unsupervised Fine-tuning Approaches
초기 feature-based approaches에 대한 연구는 unlabeled text로 부터 word embedding parameter를 pre-training하는 방향으로 진행되었습니다.
최근에는, contextual token representation을 만들어내는 (문장 혹은 문서)인코더가 pre-training되고, supervised downstream task에 맞춰 fine-tuning하게 됩니다. 이렇게 되면 scratch로(처음부터) 학습하는데 적은 파라미터로 충분하게 됩니다.
Transfer Learning from Supervised Data
기계번역(Machine Translation)과 자연어추론(NLI) 대규모 데이터셋으로부터의 효과적인 전이학습(Transfer Learning)을 보여주는 연구도 있다고 합니다.
전이학습은 자연어처리 뿐만 아니라 CV(Computer Vision) 연구에서도 그 중요성이 강조되는데, ImageNet 등을 활용해 사전학습을 한 모델이 성능이 좋다고 한다고 합니다.
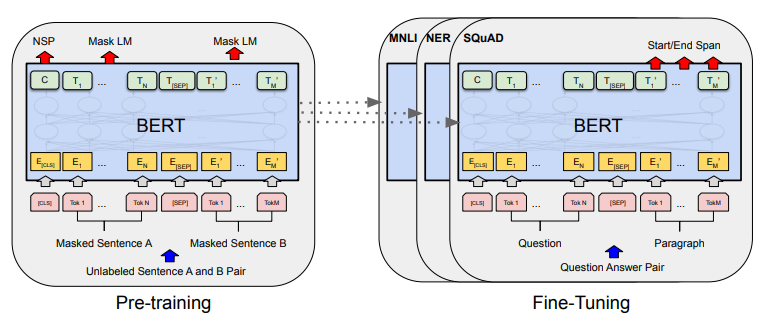
BERT
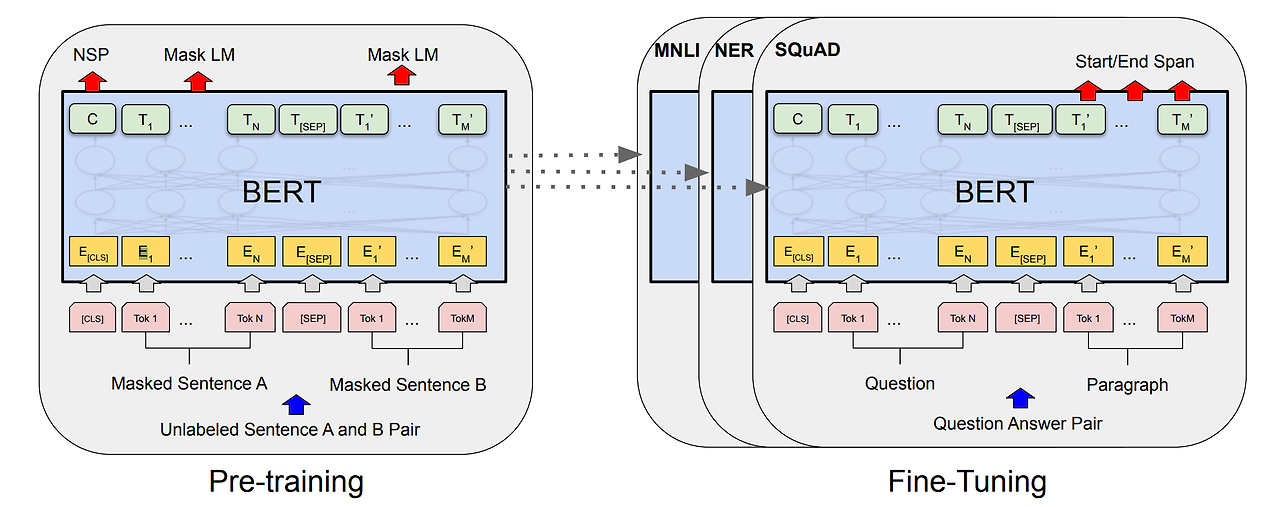
BERT를 학습시키는 과정에는 두 단계가 있는데, 바로 pre-training과 fine-tuning입니다..
- Pre-training 단계에서는 model이 unlabeled data를 통해 학습합니다.
- fine-tuning 단계에서는 pre-training으로 초기화된 parameter를 가지고 labeled data를 이용하여 downstream task에 대한 paramter를 학습합니다.
이때, 각각의 downstream task에 대한 pre-trained parameter가 같더라도 각 task는 각각의 fine-tuned model을 가진게 됩니다.
또한, pre-trained architecture와 fine-tuned 된 downstream architecture에는 큰 구조적 차이가 없으며, 항상 동일한 Pre-trained model의 파라미터가 서로 다른 downstream tasks(QA, 번역 등)의 초기 값으로 사용됩니다. 이러한 초기값들은 fine-tuning 과정에서 downstream task에 맞게 조정됩니다.
Model Architecture
Bert의 모델 아키텍처는 multi-layer bidirectional Transformer encoder, 즉, 양방향 Transformer encoder를 여러 층 쌓은 모습입니다.
두 가지의 모델을 제시합니다.:
- BERTBASE: 12개 레이어, hidden size 768, self-attention 헤드 12개, 총 매개변수 약 1억 1천만 개.
- BERTLARGE: 24개 레이어, hidden size 1024, self-attention 헤드 16개, 총 매개변수 약 3억 4천만 개.
BERT base모델은 OpenAI의 GPT와의 비교를 위해 파라미터 수를 동일하게 만들어 진행하였습니다..
여기서 다시한번 GPT의 단점이 언급되는데, GPT는 모든 토큰이 왼쪽 토큰들과만 어텐션을 계산하는 constrained(제한된) self-attention이 사용되는 반면, BERT는 bidirectional(양방향) self-attention이 사용됩니다.
Input/Output Representation
BERT가 다양한 down-stream tasks에 잘 적용되기 위해선 input representation이 애매하지 않아야 합니다. 따라서 하나의 문장 혹은 한 쌍의 문장을 하나의 토큰 시퀀스로 분명하게 표현해야합니다.
'sentence'는, 언어학적인 sentence 즉 문장의 의미 뿐만 아니라 인접한 텍스트들의 임의의 범위라는 뜻도 포함합니다.
이를 위해 BERT에서는 총 3가지의 Embedding vector를 합쳐서 input으로 사용합니다.
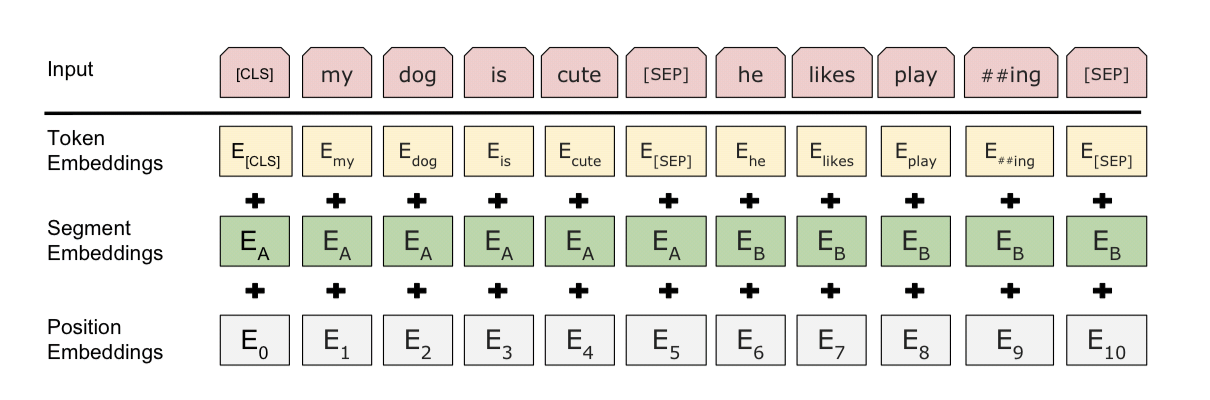
모든 sequence의 시작 부분에 [CLS] token를 추가한다. 해당 [CLS] token은 transformer 전체층을 다 거치고 나면 token sequence의 결합된 의미를 가지게 되는데, 여기에 classifier(feed-forward network와 softmax 함수를 이용)를 붙이면 단일 문장, 또는 연속된 문장의 classification을 할 수 있다. 이러한 특성 때문에 이는 곧 classification task에서 사용된다.
- [CLS] 토큰: 분류 작업에서 전체 시퀀스를 대표하는 특별 토큰.
- [SEP] 토큰: 문장 구분자 역할.
- WordPiece 임베딩(30,000개 어휘): 토큰화된 입력 텍스트를 임베딩 벡터로 변환.
앞서 pair of sentence도 하나의 token sequence로 표현된다고 했습니다. 이를 위해, [SEP] token을 활용합니다. 모든 sentence의 끝에 [SEP] token을 추가해주는데 예를 들면, (<Question, Answer>)와 같은 pair of sentence는 ([CLS], Question, [SEP], Answer, [SEP])과 같은 sequence로 변환하는 것입니다. 그런 다음 각 token에 대해 embedding을 진행합니다.
정리하면 모든 Input 시퀀스의 첫번째 토큰은 [CLS] 토큰인데, [CLS] 토큰과 대응된는 최종 hidden state는 분류 문제를 해결하기 위해 sequence representation들을 종합한다.
또한, Input 시퀀스는 문장의 한 쌍으로 구성된다. 문장 쌍의 각 문장들은 [SEP] 토큰으로 분리됩니다. 이 때, 각 문장이 A문장인지, B문장인지 구분하기 위한 임베딩(Segment Embeddings)이 진행됩니다.
Token Embeddings는 WordPiece embedding을 사용하고, Position Embeddings는 Transformer에서 사용한 방식과 동일합니다.
Input representation은 segment + token + position을 전부 합치면 됩니다.
Pre-training Bert
위에서 잠깐 언급한 것처럼, BERT는 ELMo와 GPT와는 달리 전통적인 left-to-right 혹은 right-to-left language model을 통해 pre-train하지 않습는다. 대신 2개의 unsupervised task, MLM(Masked Language Model)와 NSP(next sentence prediction)를 통해 BERT를 pre-training 합니다.
Task #1: Masked LM
기존의 Language model을 bidirectional 하게 학습할 경우, 해당 timestep에서 예측하고자 하는 단어를 간접적으로 참조할 수 있기 때문에, 예측이 무의미해질 수 있습니다.
Masked LM(MLM)은 이러한 문제를 해결하고 deep bidirectional representation을 학습하기 위해 도입된 개념입니다.
BERT에서는 오직 [MASK] token만을 예측합니다.
즉, MLM에서는 각각의 sequence에 존재하는 WordPiece token들 중에서 15%를 random 하게 masking 합니다. 이러한 방법은 bidirectional pre-trained model을 얻을 수 있지만, pre-training에 존재하는 [MASK] token이 fine-tuning에는 존재하지 않기 때문에 pre-training과 fine-tuning 사이에 불일치를 일으킬 수 있다는 문제가 있습니다.
이러한 문제를 해결하고자, 본 연구에서는 masking 되는 sequence tokens의 15%를 전부 [MASK] token으로 바꾸지 않습니다.
그리고 15%의 [MASK] token에서 추가적인 처리를 더 해줍니다.
- 80%의 경우 : token을 [MASK] token으로 바꾼다.
ex) my dog is hairy -> my dog is [MASK]- 10%의 경우 : token을 random word로 바꾼다.
ex) my dog is hairy -> my dog is apple- 10%의 경우 : token을 원래 단어 그대로 놔둔다.
ex) my dog is hairy -> my dog is hairy
이 때,
-
10%의 경우 (random word): 무작위 단어로 바꾸면 모델의 성능이 떨어지지 않을까 생각할 수 있지만, 15%의 token 중에서 10%만을 바꾸는 것이므로 실제 비율은 1.5% 밖에 되지 않아 모델의 성능과는 상관없다고 합니다.
-
10%의 경우 (원래 단어): 단어를 그대로 두는 것은 실제 관측 단어에 대한 representation을 bias해주기 위함이라고 합니다.
Task # 2: Next Sentence Prediction (NSP)
많은 NLP의 downstream task는 두 문장 사이의 관계를 이해하는것이 핵심입니다. 이러한 문장 사이의 관계는 language modeling으로는 알아 낼 수 없는데, 이를 학습하기 위해 BERT모델은 binarized next sentence prediction(NSP)을 이용합니다.
NSP를 이용하면, pre-training example로 문장A와 B를 선택할때, 50퍼센트는 실제 A의 다음 문장인 B를(IsNext), 나머지 50퍼센트는 랜덤 문장 B를(NotNext) 고르는 것입니다.
Pretraing data
Pretraining 과정은 많은 데이터를 필요로 하는데, 본 연구에서는 pretraining을 위해 800M 개의 words로 구성된 BookCorpus dataset과 2500개의 words로 이루어진 English Wikipedia dataset에서 text passage 만 사용했고, 목록이나 표 등은 제외하여 사용하였습니다.
또한, 긴 문맥을 학습하기 위해 Billion Word Benchmark와 같이 섞인 문장으로 구성된 데이터는 사용하지 않았다고 합니다.
Fine-tuning BERT
Fine-tuning에서도 pretraining과 마찬가지로 single sentence와 pair of sentence(<Question, Answer>)를 하나의 token sequence로 바꿔주는 작업을 진행한다.
이후, 이렇게 만들어진 BERT의 input representation을 통해 parameter를 각각의 downstream task에 맞게 end-to-end로 fine-tune 한다.
이때, Sequence tagging이나 question answering 같이 token-level task 들의 경우, 마지막 transformer layer의 token들의 hidden state로부터 나오는 output을 이용하여 fine-tuning 합니다.
이 후 Sentence Classification, sentiment analysis 등의 sentence-level classification task들은 마지막 layer의 [CLS] token의 hidden state로부터 나오는 output을 통해 fine-tuning을 진행한다.
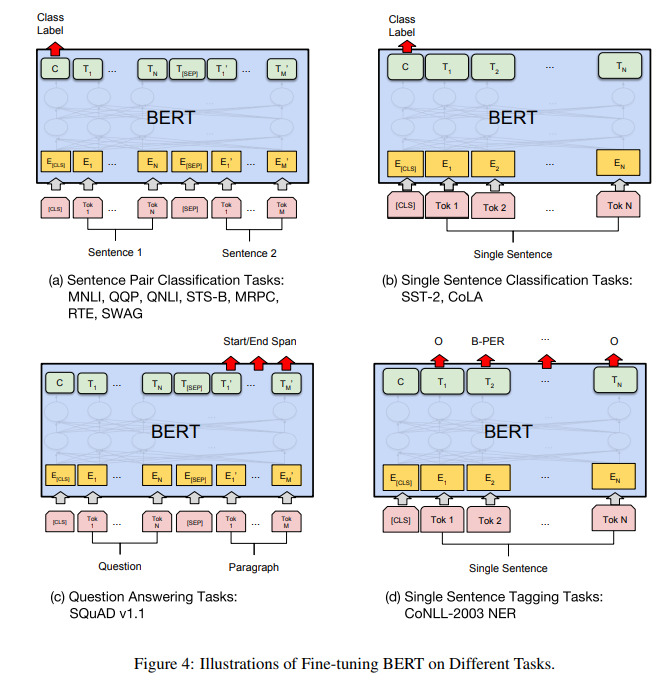
위 그림은 task별 fine-tuning에 대해 시각화한 자료이다.
Pretraining과 비교했을 때, fine-tuning은 빠르게 학습이 가능합니다.
Experiments
BERT는 다양한 NLP 벤치마크에서 최첨단 성능을 기록했습니다:
- GLUE 벤치마크: 평균 정확도 82.1%(BERTLARGE 기준).
- SQuAD v1.1: F1 점수 93.2, 정확도(EM) 87.4.
- SQuAD v2.0: F1 점수 83.1로 이전 최고 성능 대비 +5.1% 향상.
GLUE 벤치마크
GLUE는 NLP 모델의 전반적인 언어 이해 능력을 평가하기 위해 설계된 벤치마크입니다. 다양한 언어 이해 작업을 포함하며, 모델이 여러 작업에서 얼마나 잘 일반화할 수 있는지를 측정합니다.
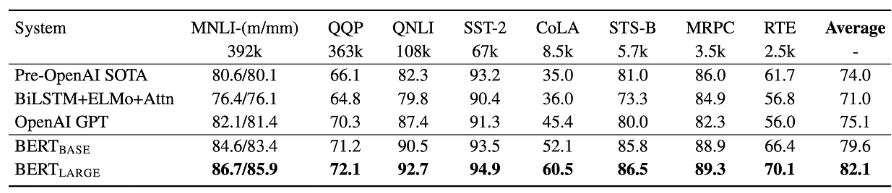
GLUE에 대한 자세한 리뷰: https://gbdai.tistory.com/51
SQuAD v1.1 (Stanford Question Answering Dataset v1.1)
SQuAD v1.1은 Stanford University에서 개발한 질의응답(QA) 데이터셋으로, 기계 독해(Machine Reading Comprehension) 능력을 평가하는 데 사용됩니다.
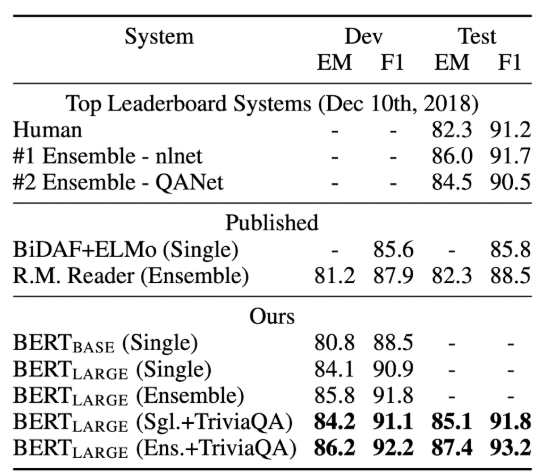
SQuAD v1.1은 NLP 모델이 텍스트 내에서 특정 정보를 정확히 찾아내는 능력을 측정하며, BERT와 같은 Transformer 기반 모델들이 이 데이터셋에서 뛰어난 성능을 기록했습니다.
SQuAD v2.0
SQuAD v2.0은 제공된 passage에 answer이 존재하지 않을 가능성을 허용함으로써 SQuAD v1.1에서의 문제 정의를 확장한 버전입니다. 이를 BERT에 적용하기 위해, answer가 존재하는지에 대한 여부를 CLS token을 이용해 분류하는 과정을 추가합니다.
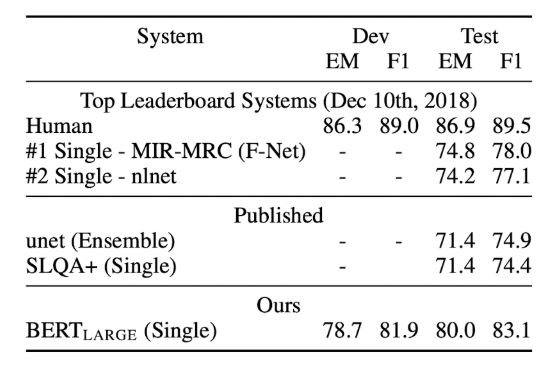
SQuAD v2.0은 기존보다 더 현실적인 QA 시나리오를 반영하며, BERT와 같은 고성능 모델들이 이 데이터셋에서도 우수한 결과를 보였습니다.
SWAG
SWAG(The Situations With Adversarial Generations)은 앞 문장이 주어졌을 때, 보기로 주어진 4 문장 중 가장 잘 어울리는 문장을 찾는 task입니다.
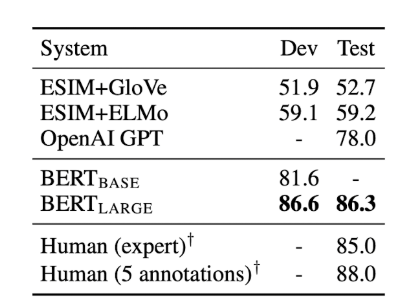
BERT는 압도적인 성능을 보여주며, 사람의 능력과 비슷한 성능을 보여주었습니다.
5. Ablation Studies
Effect of Pre-training Tasks
BERT의 deep bidirectionality의 중요성을 역설하기 위해 BERT의 핵심 요소들이었던 MLM과 NSP를 하나씩 제거하면서 실험을 진행하였습니다. BERT-BASE를 기반으로 한 두 가지 model을 추가적으로 실험하는데 다음과 같습니다.
- MLM은 사용, NSP 미사용 (No NSP)
- MLM을 사용하지 않고 대신 left-to-right을 사용, NSP 미사용 (LTR & No NSP)
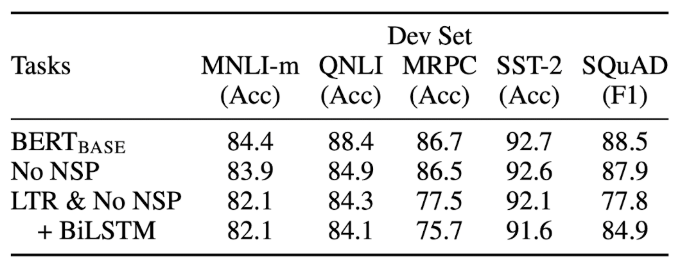
위의 그림을 통해 MLM과 NSP가 제거될 때마다 성능이 하락하는 것을 확인할 수 있다.
NSP를 미적용한 model의 경우 NLI task(MNLI, QNLI, SQuAD)에서의 성능이 BERT-BASE에 비해 매우 저조함을 확인할 수 있습니다. 즉, NSP가 두 문장 사이의 관계를 매우 잘 이해하도록 도와주는 것을 알 수 있습니다.
No NSP와 LTR & No NSP를 비교하여 MLM이 model에 미치는 영향을 확인해보면 MLM 대신 LTR을 사용하게 되면 전반적으로 성능이 크게 하락하는 것을 확인할 수 있습니다.
Effect of Model Size
모델의 크기를 다르게 하면서 성능을 측정해보았습니다.
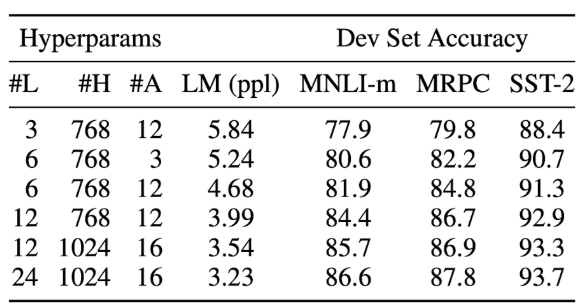
모든 task에 대해 model size가 커질수록, 성능도 함께 향상되는 것을 확인할 수 있습니다.
또한, MRPC dataset과 같이, downstream task를 수행하는 dataset의 크기가 작고 pre-training task와 상당히 다른 downstream task에서도 충분히 좋은 성능을 내는 것을 확인할 수 있습니다.
Feature-based Approach with BERT
앞서 BERT의 결과들은 pretraining된 model에 simple classification layer를 추가하고, downstream task에서 모든 parameter가 공동으로 fine-tuned되는 fine-tuning approach를 사용하였다.
이번에는 fine-tuning approach대신 feature-based approach을 보았습니다.
feature-based approach의 경우, transformer의 encoder로 쉽게 표현되지 않는 task가 존재하기에, 이런 경우에는 task-specific architecure를 추가합니다. 또한, feature-based approach는 training data의 expensive representation을 사전에 구해놓은 뒤, representation 위에서 cheaper model을 통해 여러 번 실험을 진행하기에 computational benefit가 있습니다.
그래서, 논문에서는 BERT에서 두 방법론을 비교하고자 Named Entity Recognition(NER) task에 fine-tuning approach와 feature-based approach 모두 적용하여 실험을 진행하였습니다. feature-based approach의 경우, fine-tuning을 거치지 않은 BERT의 hidden layer들 중, 추출하는 layer의 개수를 다르게 하여 bidirectional LSTM의 input embedding으로 사용하였다.
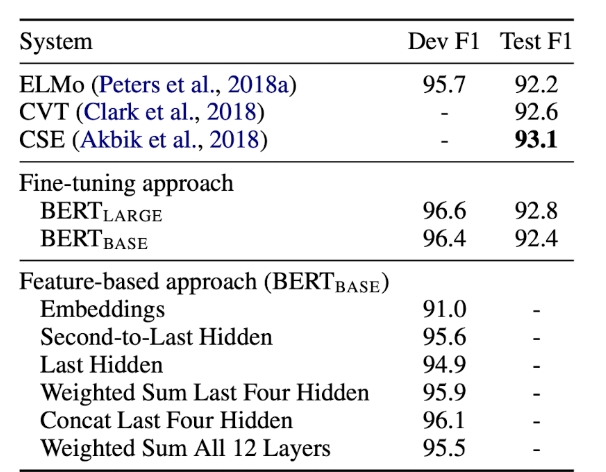
fine-tuning approach를 적용했을 때가 성능이 좋지만, pretraining 된 BERT의 마지막 4개의 hidden layer의 concat을 feature-based approach로 적용한 성능이 fine-tuning approach를 적용했을 때와 큰 차이가 없음을 알 수 있습니다.
즉, BERT는 fine-tuning approach와 feature-based approach 모두 효과적임을 알 수 있습니다.
6. Conclusion
BERT는 양방향 Transformer 기반 언어 모델로, 사전 학습과 미세 조정을 통해 다양한 NLP 작업에서 뛰어난 성능을 발휘합니다:
- Masked Language Model과 Next Sentence Prediction 목표를 통해 깊은 양방향 표현 학습 가능.
- Task-specific 아키텍처 수정 없이 간단한 fine-tuning으로 적용 가능.
- NLP 연구 및 응용 분야에서 SOTA를 달성.
마지막으로
이번에는 BERT 논문을 다루어 보았습니다. BERT를 공부하고 찾아보면서, Text, Image 분야에서도 연관되어 사용되고, 사용될 수 있을 것 같아 보입니다.
