
사용자가 많은 서비스를 개발하다보면 우리는 필연적으로 동시성이라는 이슈를 마주칠 수 밖에 없는데요, 이번에는 Jmeter를 활용해 테스트해보는 그런 시간을 가져보도록 하겠습니다~!
📌 1. Jmeter를 설치
우선 Jmeter를 설치해야 합니다.
mac을 사용하는 분들은 간단하게 "brew install jmeter"를 사용해서 설치하시면 되구요, window 환경에서 개발하시는 분들은 이 Apahce Jmeter 링크에서 다운받아 사용하시면 될것 같습니다.
자 설치를 완료하고 터미널에서 Jmeter라고 치시면 이래 사진처럼 이제 GUI로 Jmeter를 사용할 수 있게 됩니다.

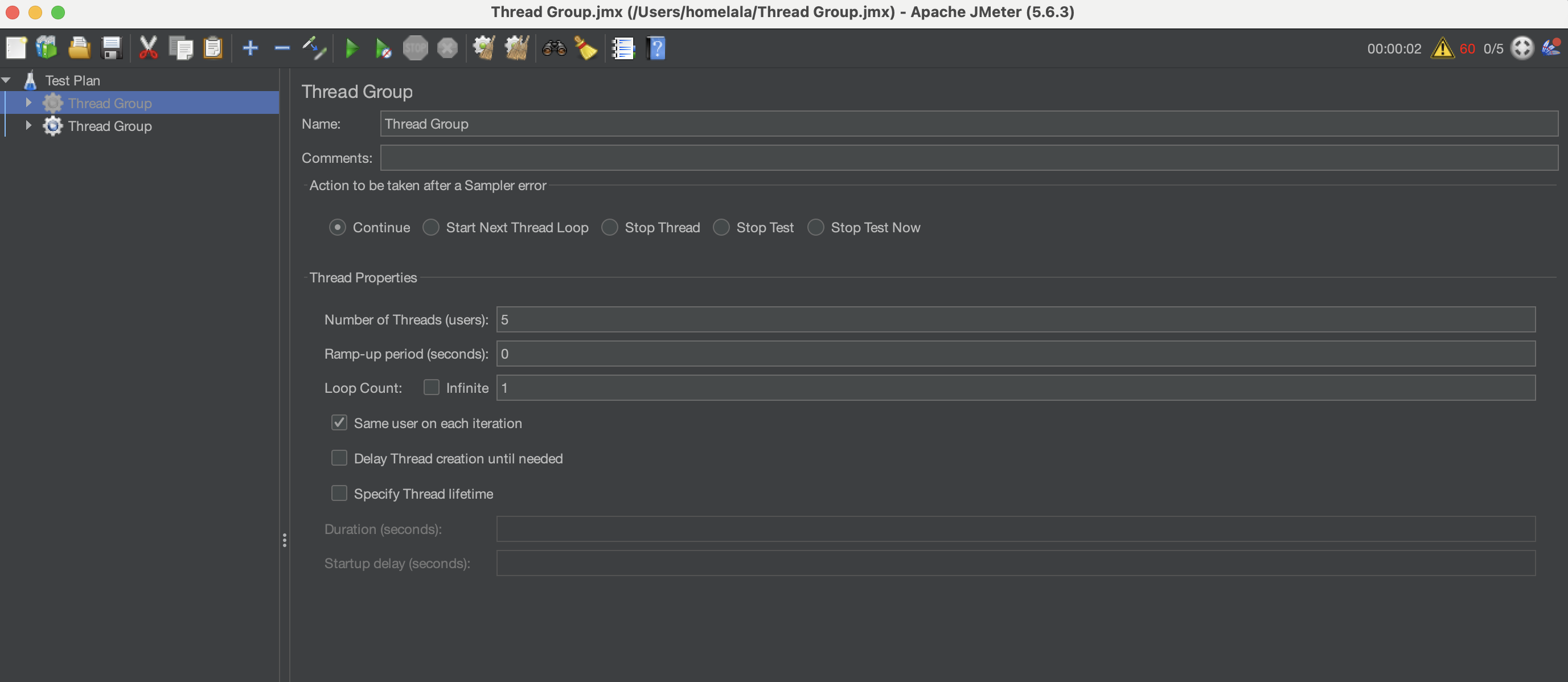
이렇게 됬으면 사용준비 끝입니다. 저기서 중요한건 Thread Properties 부분인데요.
Number of Thread: 쓰레드의 수
Ramp-up Period: 하나의 쓰레드 실행 후 다음 쓰레드까지 대기 시간
Loop Count: 반복 횟수
이렇게 설정할 수 있는데 우리는 우선 동시성 이슈를 테스트 할 것이기에 위의 사진처럼 쓰레드의 개수는 5개 대기시간은 0그리고 반복 횟수를 0으로 설정하시면 될 것같습니다!
📌 2. 서비스 코드
이제 동시성을 테스트할 서비서 코드가 필요한데요! 간단한 Rest API만 필요하기 때문에 따로 작성하실 분들은 작성하셔도 좋고 귀찮다! 하시는 분들은 아래 GitHub 링크에서 pull 받아서 테스트 해보시면 될 것같습니다.
잠깐 코드에 대해 설명을 드리자면
Language: Python
Framework: Flask
DB: Mysql
etc: Redis, Docker
위의 라이브러리를 사용했습니다!
API
GET /test - Test API
GET /user/<user_id> - 유저 조회 API
POST /user - 유저 등록 API
PUT /user/<user_id> 유저 수정 API
POST /order - 주문 API
DB
User - 유저 DB
Product - 제품 DB
Order - 주문 DB
OrderDetail - 주문 상세 DB
API와 DB는 위와 같이 되어있는데요 참고하시면 될 것 같습니다!
📌 3. 동시성 테스트 사전 Setting
우리가 테스트할 시나리오는 이렇게 이루어집니다.
- 5개의 쓰레드가 동일한 제품에 대해 주문을 동시에 실행
- 남은 재고는 1개
- 이때 한 개의 쓰레드만 성공해야 하고 나머지 쓰레드에서는 재고 부족으로 인해 예외처리가 되어야한다.
위의 시나리오를 바탕으로 우선 Jmeter를 설정할건데요, 우선 Http Request를 만들어야 합니다. 그러면 각 쓰레드가 요청할 API가 만들어지게 되는데요, 아래 사진처럼 설정하시면 될 것 같습니다.
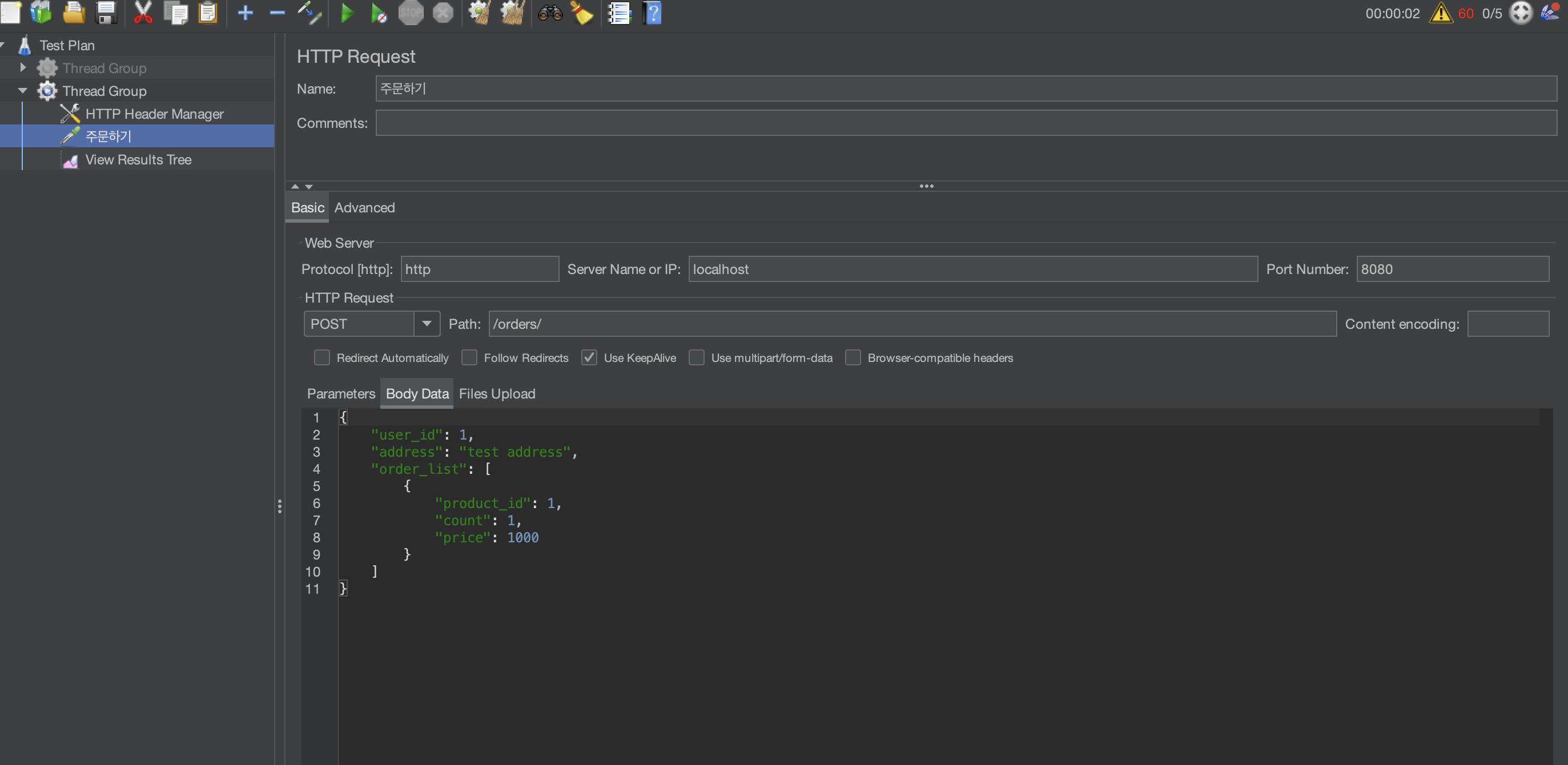
name은 취향 껏 작성하시면 되고 protocol, port, ip와 Body Data를 작성하시면 될 것 같습니다.
그리고 그 다음에는 Http Header Manager를 통해 Content-Type을 추가해주셔야합니다!
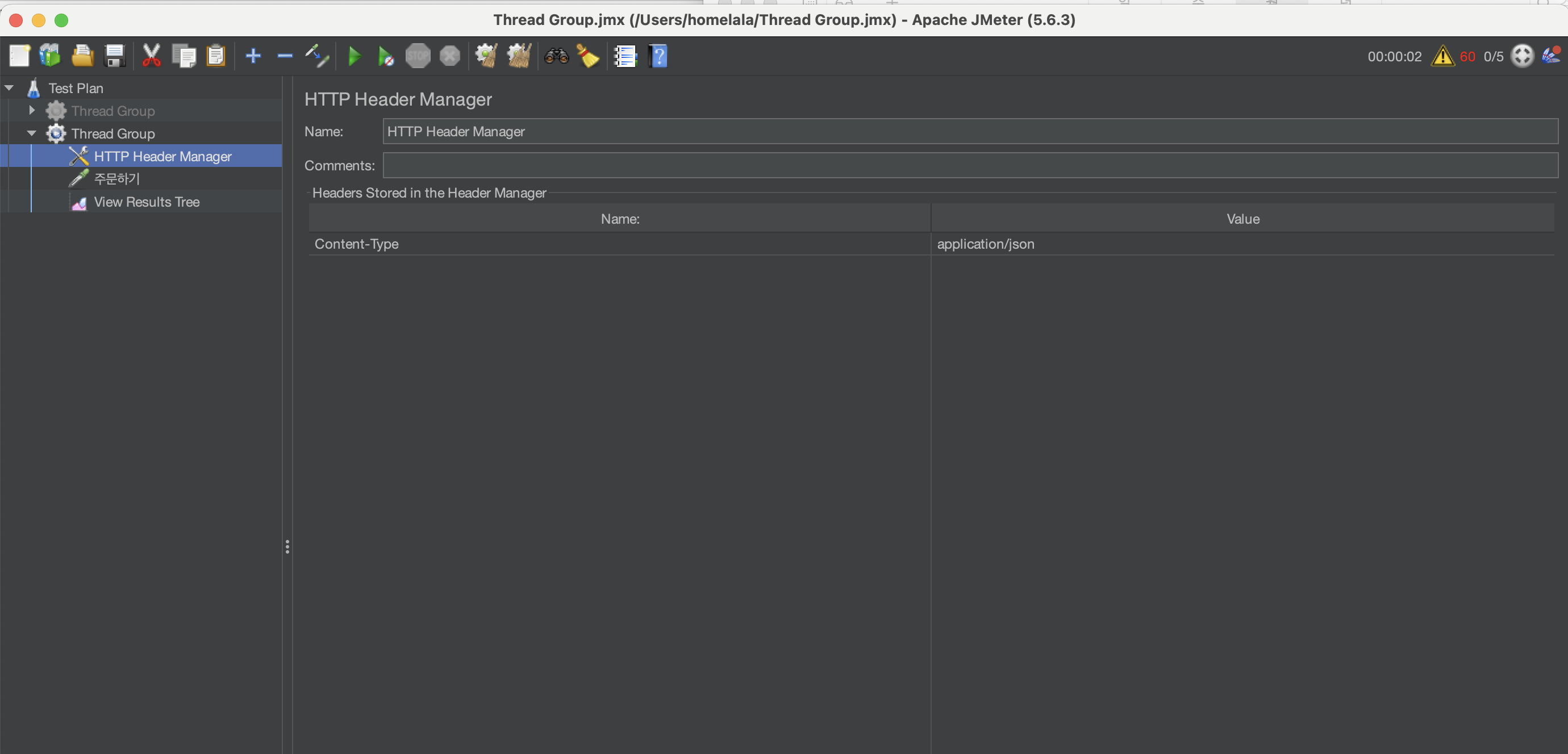
이렇게 하면 실행 준비는 끝이구요 마지막으로 각 쓰레드의 결과를 모니터링할 수 있게 View results Tree를 넣어주시면 됩니다~!
참고로 이번 테스트에서 필요하지는 않지만 만일 각 요청마다 값을 다르게 넣고 싶을 경우!
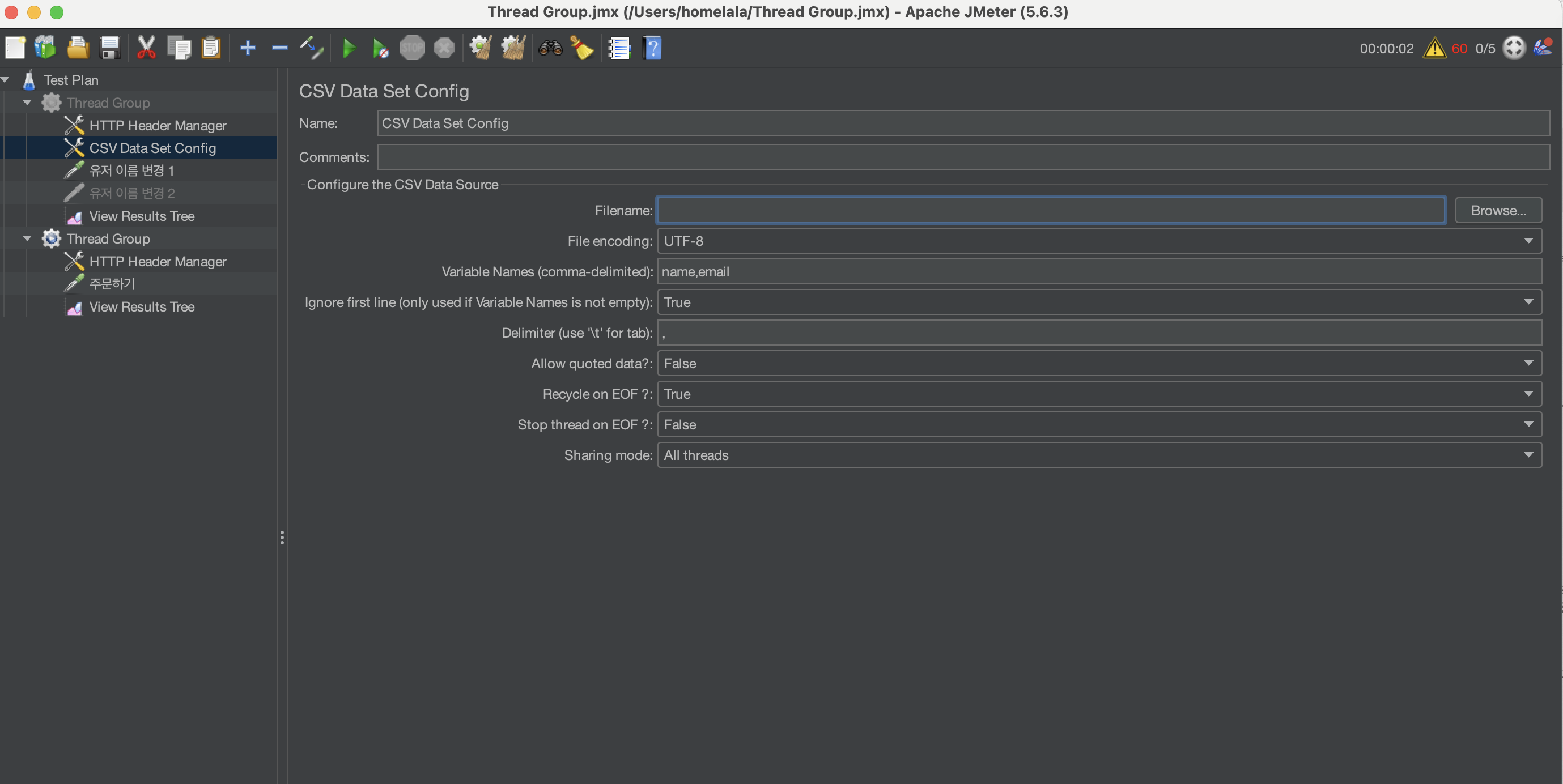
위와 같이 csv에 값들을 넣어주고 path 설정, split 단위 등 설정을 해주면 각 요청마다 순서대로 값이 입력됩니다!
📌 4. 동시성 TEST - 1
자 그럼 저 부분을 실행해볼건데요! 우선 동시성이 보장 안되어있은 아래의 코드로 먼저 서버를 실행해보겠습니다!
# OrderService.py
class OrderService:
@classmethod
def order_product(cls, user_id, address, order_list):
order = Order(user_id=user_id, address=address)
db.session.add(order)
db.session.flush()
product_ids = [order["product_id"] for order in order_list]
products = Product.query.filter(Product.id.in_(product_ids)).all()
indexed_product = indexing(products, key=lambda x: x.id)
order_details = OrderDetailService.create_order_detail(
order_list, indexed_product, order
)
db.session.add_all(order_details)
db.session.commit()
class OrderDetailService:
@classmethod
def create_order_detail(cls, order_list, indexed_product, order):
order_details = []
for order_detail in order_list:
order_product = indexed_product[order_detail["product_id"]]
if order_product.stock < order_detail["count"]:
raise Exception("재고가 부족합니다.")
order_details.append(
OrderDetail(
order_id=order.id,
product_id=order_detail["product_id"],
count=order_detail["count"],
price=order_detail["price"],
)
)
order_product.decrease_stock(order_detail["count"])
db.session.add(order_product)
return order_details위의 두 메서드는 재고가 부족하다는 예외처리는 되어있지만 동시에 들어오는 요청에 대해서는 막지 못하게 되어있습니다! 이 경우 Jmeter로 테스트해보겠습니다!

우선 위와 같이 product의 재고는 1로 설정이 되어있고 실행을 한다면!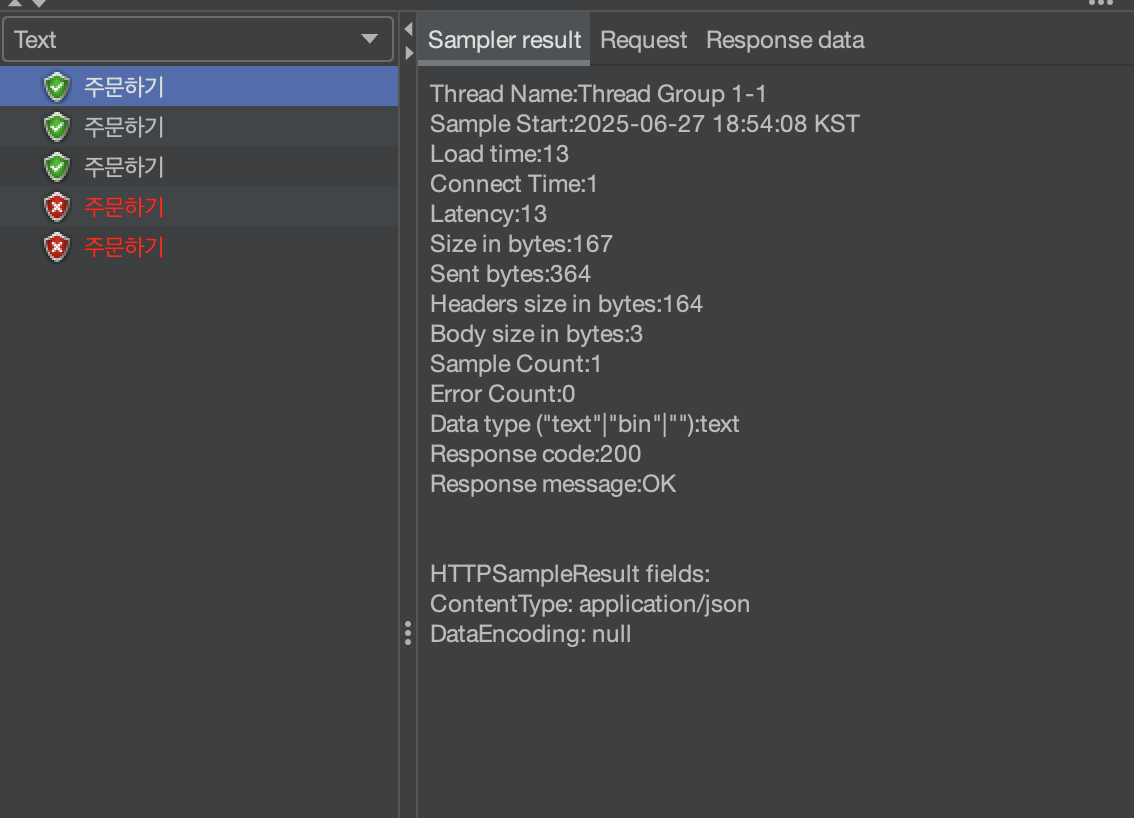
위의 화면과 같이 3개의 요청이 성공한 것을 볼 수 있고 2개의 요청은 실패가 뜬 것을 볼 수 있습니다.
그리고 상품의 재고는 아래와 같이 0으로 변경된 것을 볼 수 있습니다.

결과를 분석해본다면 우선 동시성 처리가 이루이지 않으니까 3개의 요청에 대해서 동시에 같은 DB에 접근이 이루어지면서 데이터 정합성 이슈가 발생한 것을 볼 수 있습니다!
그렇다면 2개의 에러는 무슨 에러냐! 아래와 같은 에러가 뜨는데요
pymysql.err.OperationalError: (1213, 'Deadlock found when trying to get lock; try restarting transaction')
위 에러는 동시에 스레드들이 하나의 DB에 대해서 트랜잭션을 획득하려고 하면 발생하는 문제입니다!
이제 이럴 경우에는 락을 걸어서 하나의 요청에 대해서만 트랜잭션을 획득하도록 구현해야 하는데요!
우리는 이 동시성 이슈를 2가지 방식으로 해결해볼 것입니다! 우선 첫 번째로 DB의 락을 사용하기!
📌 4. 동시성 TEST - 비관적 락 적용
우선 Mysql에서는 비관적 락을 지원하게 되는데요! 상품 데이터를 가져올 때 해당 스레드 말고 다른 스레드들은 접근하지 못하도록 락을 거는 것을 말합니다.
class OrderService:
@classmethod
def order_product_with_pessimistic_lock(cls, user_id, address, order_list):
try:
with db.session.begin():
order = Order(user_id=user_id, address=address)
db.session.add(order)
db.session.flush()
product_ids = [order["product_id"] for order in order_list]
products = (
Product.query.filter(Product.id.in_(product_ids))
.with_for_update()
.all()
)
indexed_product = indexing(products, key=lambda x: x.id)
order_details = OrderDetailService.create_order_detail(
order_list, indexed_product, order
)
db.session.add_all(order_details)
db.session.commit()
except:
db.session.rollback()
raise위의 코드처럼 db.session.begin()을 넣어 트랜잭션 시작점을 명시해주고 with_for_update() 메서드를 통해 데이터를 가져오게 되면 해당 데이터에 한해서는 락이 생기게 됩니다!
그렇다면 하나의 의문이 생기게 되는데요! 저렇게 데이터를 가져오면 테이블 전체에 락이 생기는 것인가? 아니면 해당 데이터만 락이 생기는 것인가? 그리고 읽기에도 성능제한이 생기는 것인가?
답을 우선 말씀드리자면 저렇게 데이터를 가져오게되면 가져온 데이터에 한해서만 락이 발생합니다! 그리고 조회는 따로 막지 않고 쓰기/삭제에 관해서만 락이 발생한다! 라고 알고 계시면 될것 같습니다~! 만일 테이블 전체에 락이 발생하고 읽기에도 제한이 된다면 성능적인 부분에서 이슈가 많이 발생하겠죠?
자! 그래서 저렇게 메서드를 고치고 실행을 하게 된다면~!
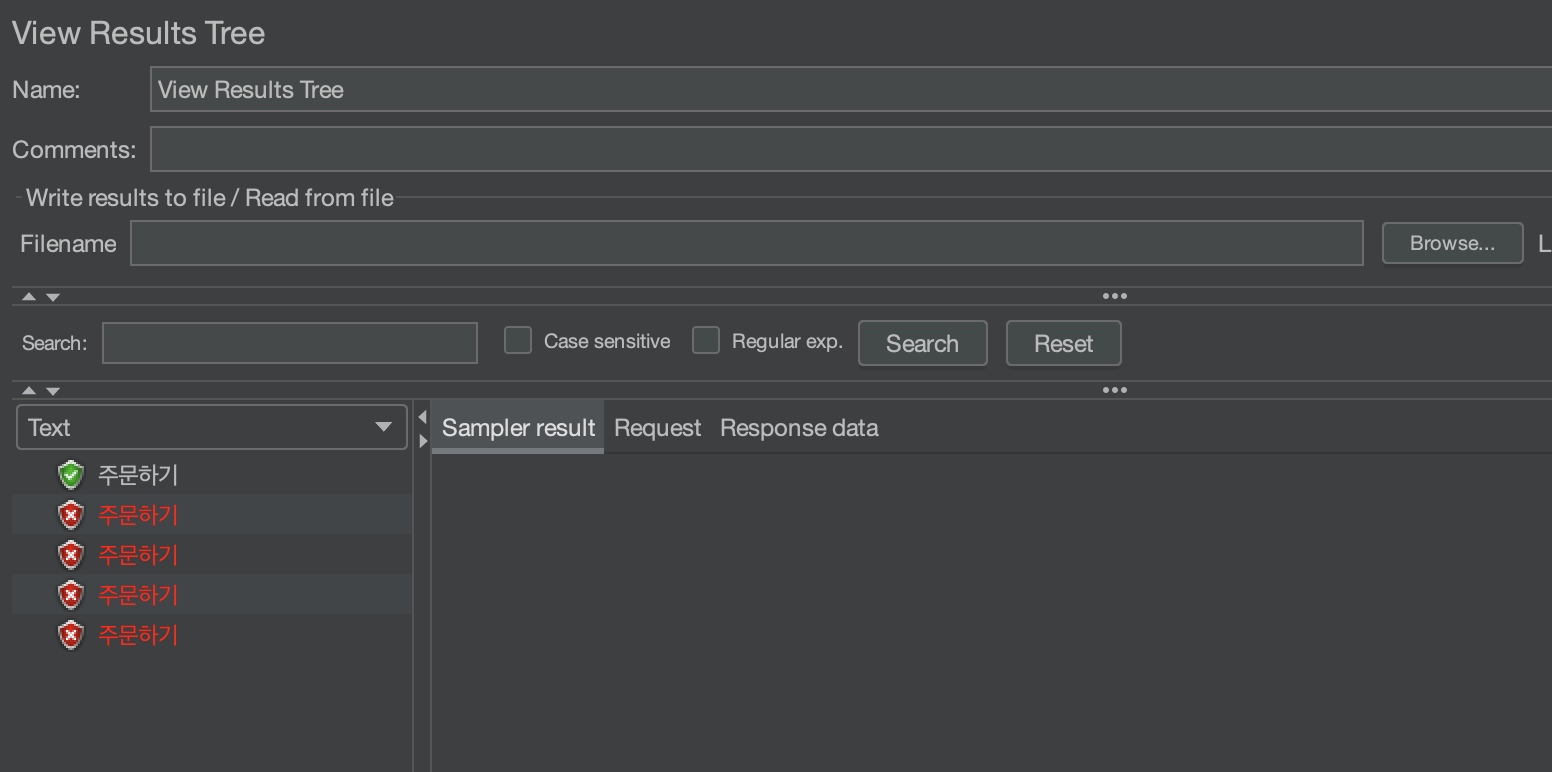
하나의 요청만 성공한 것을 볼 수 있습니다~! 
그리고 나머지 요청에 대해서는 "재고가 부족합니다~!"라는 예외 처리가 되는 것을 볼 수 있습니다~!
📌 4. 동시성 TEST - RedLock 적용
자 이번에는 DB의 락이 아니라 요청에 대해서 락을 걸게 할건데요! DB 락은 하나의 자원에 하나의 요청만 접근하게끔하는 것이지만 분산락이라는 것은 하나의 로직에 대해 하나의 요청만 실행하게 한다! 라는 차이가 있습니다!
분산락이 무엇인지도 설명하고 싶지만 그렇게 되면 이번 포스팅이 너무 길어져 다음 포스팅에 따로 시간이 된다면 올려보도록 하겠습니다~!
궁금하신 분들은 해당 설명을 참고하시면 좋을 것 같습니다!
자 이제 저희는 분산락의 대표적인 Redlock을 사용할 것인데요! 해당 락을 사용하기 위해 필요한 것이 있습니다! 바로 redis 설치와 docker 설치입니다.
우선 Docker Desktop을 다운받아야 합니다~! 사실 필요하지는 않는데 우리의 Redis가 잘 띄워졌나 확인하기 위해 ㅎㅎ
그 다음 mac 환경에 있는 사람들은 brew install docker, brew install redis를 통해 두 라이브러리를 실행시켜줍니다.
그리고 아래의 명령어를 실행해 redis 노드들을 띄워야되는데요! 분산락이라는 특성으로 인해 노드가 한개보다는 많아야 하기에 3개의 노드를 우리는 총 띄울 것입니다~!
docker run -d --name redis1 --net redlock-net -p 6379:6379 redis
docker run -d --name redis1 --net redlock-net -p 6380:6380 redis
docker run -d --name redis1 --net redlock-net -p 6381:6381 redis
해당 명령어를 실행하면 아래의 사진 처럼 우리의 redis 노드들이 띄워져 있는 것을 볼 수 있습니다.

자 이러면 준비는 끝입니다~! 이제 코드를 살펴보시면
import logging
from contextlib import contextmanager
from redlock import RedLockFactory
factory = RedLockFactory(
connection_details=[
{"host": "localhost", "port": 6379, "db": 0},
{"host": "localhost", "port": 6380, "db": 0},
{"host": "localhost", "port": 6381, "db": 0},
]
)
@contextmanager
def create_lock(resource_key, ttl=5000):
"""
분산 락 생성 및 해제
:param resource_key: 락을 걸 Redis 키
:param ttl: 락 유지 시간 (ms 단위)
"""
lock = factory.create_lock(
resource_key,
ttl=ttl,
retry_times=2, # 락 재시도 횟수
retry_delay=200,
)
if not lock.acquire():
raise Exception(f"[LOCK] Unable to acquire lock for key: {resource_key}")
try:
print(f"🔒 락 획득 성공: {resource_key}")
yield
finally:
lock.release()
print(f"🔓 락 해제 완료: {resource_key}")
def create_order_redlock(product_id):
return create_lock(RedLockKey.get_order_key(product_id))
class RedLockKey:
@classmethod
def get_order_key(cls, product_id):
return f"Order:{product_id}"
- RedLockFactory를 통해 Lock을 만드는 factory를 만듭니다.
- create_lock 메서드는 특정 id값을 가져와 lock을 생성하고 로직이 완료될 경우에는 락을 해제합니다.
- create_order_redlock 메서드는 order_id를 가져와서 각 order에 대해 고유한 락을 만드는 메서드입니다~!
이 다음에는 해당 락을 서비스 코드에 적용해볼 것인데요~!
class OrderService:
@classmethod
def order_product_with_redis_lock(cls, user_id, address, order_list):
order = Order(user_id=user_id, address=address)
db.session.add(order)
db.session.flush()
product_ids = [order["product_id"] for order in order_list]
products = Product.query.filter(Product.id.in_(product_ids)).all()
indexed_product = indexing(products, key=lambda x: x.id)
order_details = OrderDetailService.create_order_detail_with_redis_lock(
order_list, indexed_product, order
)
db.session.add_all(order_details)
db.session.commit()
@classmethod
def create_order_detail_with_redis_lock(cls, order_list, indexed_product, order):
order_details = []
for order_detail in order_list:
order_product = indexed_product[order_detail["product_id"]]
from infra.redis import create_order_redlock
from time import sleep
with create_order_redlock(order_product.id):
if order_product.stock < order_detail["count"]:
raise Exception("재고가 부족합니다.")
order_details.append(
OrderDetail(
order_id=order.id,
product_id=order_detail["product_id"],
count=order_detail["count"],
price=order_detail["price"],
)
)
order_product.decrease_stock(order_detail["count"])
db.session.add(order_product)
sleep(1) # 커밋되는 시간에 다른 쓰레드가 접근하여 DB접근이 성공되어버림
return order_details위와 같이 with문으로 락을 생성해서 적용해주게 되면 해당 로직 부터는 하나의 요청만 접근할 수 있습니다.
그리고 sleep(1)이 있는 이유는 해당 코드가 단순한 누적 코드여서 커밋되는 시간에 다른 쓰레드가 접근하여 그 사이에 락이 풀려 그 사이에 다른 스레드가 접근하는 것을 방지하기 위해 잠시 시간 값을 넣어 두게 되었습니다!
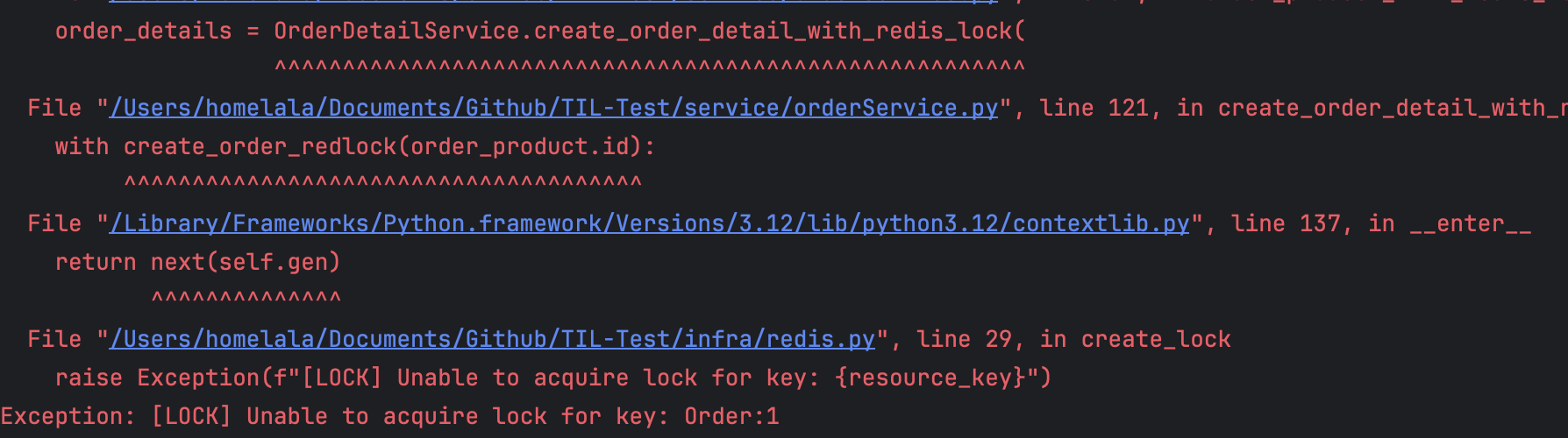
자 이제 해당 코드를 Jmeter로 테스트 해보면 아래의 결과 같이 나오게 됩니다~!
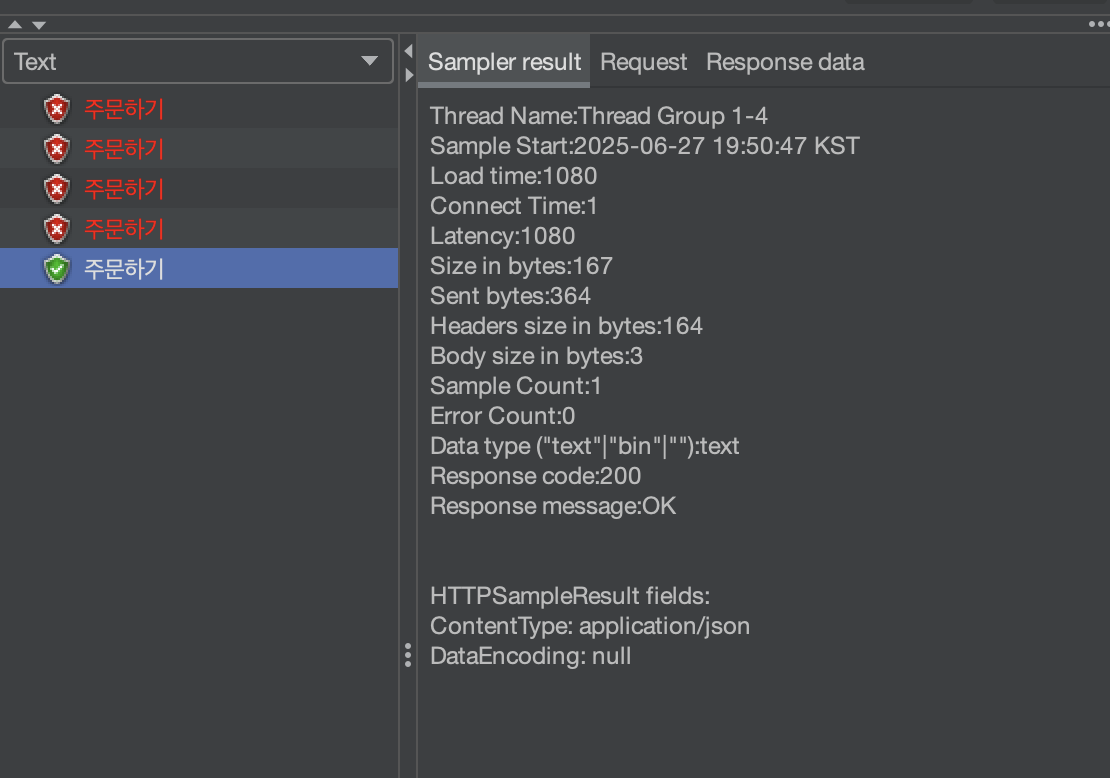
하나의 요청만이 성공하는 것을 볼 수 있고 나머지 요청들은 아래의 에러처럼 락 획득에 실패한 것을 볼 수 있습니다~!
5. 📌 DB 락 vs 분산락
자 그럼 하나의 의문이 우리에게 생길 수도 있는데요! 왜 DB락만 사용해도 충분할 거 같은데 왜 분산락까지 사용해야 할까?
사실 이론상으로만 보면 DB락만 사용해도 크게 문제가 없는게 맞습니다! 하지만 현실적으로 생각하면 많은 문제가 있는데요.
1. DB의 문제
우선 서비스 규모가 커져서 DB를 샤딩하거나 복제본을 만들게 되는 경우에는 여러 요청이 각 DB에 분산되기 시작합니다, 그렇게 된다면 DB락은 서로 다른 인스턴스 DB에는 락이 걸리지 않으므로 동시성을 보장해주지 못하게 됩니다!
2. 성능 이슈
수정되는 쿼리마다 DB락이 생긴다면 트랜잭션이 오래 대기하게 되고 대기 중 트랜잭션이 많아지면 DB 커넥션 풀이 금방 소진되버립니다. 이는 전체 서비스의 성능 부하 DB 커넥션 풀 부족으로 장애가지 야기할 수 있습니다!
분산락을 사용한다면!
우선 DB보다 앞단인 애플리케이션 단위에서 락이 발생하기 때문에 API의 요청들을 직렬화할 수가 있습니다! 그렇게 된다면 락 획득한 한 요청만 DB 처리로 넘어갈 수 있으니 결제 등 장시간 로직을 처리해도 다른 요청이 DB에 들어와 race condition이 생기지도 않고 특히! 여러 WAS 인스턴스가 락 정보를 공유할 수 있어, 여러 서버 간 동시성을 보장되는 것이 장점입니다.
그렇지만 분산락만 사용한다면 애플리케이션 레벨에서 동시성 이슈를 방지해도 트랜잭션이 DB에 도착하는 순간 여러 요청이 발생해 여기서 경쟁 상태가 발생할 수 있기 때문에 분산락만 사용해도 문제가 될 수 있습니다
결론적으로!
그래서 보통은 둘다 사용합니다.
우선 분산락을 통해 다중 워커 환경에서 하나의 상품에 대해 동시에 접근하는 여러 요청들을 어플리케이션 단위에서 직렬화하고
DB 레벨의 락을 통해 마지막 트랜잭션 내에서 경쟁상태를 방지한다!
라는 시나리오를 통해 우리는 동시성을 주로 해결합니다!
💀 락을 과도하게 사용할 경우
그러면 락을 API 요청 시에 마다 걸게되면 될까? 라는 의문이 드는데요!
만일 락을 과도하게 걸 경우 데이터의 정합성은 확보가 됩니다! 그렇지만 자원의 접근에 대해 한계가 생기기 때문에 성능 이슈, 그리고 락을 획득하는 과정에서 경쟁이 발생하는 등 많은 병목 현상이 발생할 수 있다는 점을 알아두어야 합니다!
그래서 주로 수정이 되는 부분, 트래픽이 과도하게 몰릴 API, 데이터의 정합성이 보장되어야 할 API에 대해 주로 락을 사용하는 편입니다!
6. 마치며
자 오늘은 Jmeter를 통해 동시성을 테스트해보고 이 동시성을 어떻게 방지할 수 있는지를 알아보았습니다. 간단한 프로젝트를 개발 할 때에는 이런 동시성 테스트, 트래픽에 대해 테스트를 못해봐서 성능 적인 부분을 간과할 수 있었는데 이런 프로그램이 있다면 이러한 부분을 해결할 수 있을 것 같습니다!
그러면 이번 포스팅도 여러분께 유용한 포스팅이 되길 바라며 마치겠습니다~!🙌
