빅데이터 분석기사 D-7

작년 12월에서 코로나 때문에 취소되어 4월까지 밀린 유일한 시험(이지 않을까?)을 준비하며 공부하는 글이다. 이번 시험이 첫번째 시험이기 때문에 시중에 기출은 없고 문제집만 많이 나와있다. 나는 작년 11월에 구매한, 뒷부분이 깨끗한 문제집으로 벼락치기중이다. 작년엔 한 달 정도 공부하다가 날벼락 같은 취소 공지를 받고, 4개월이나 밀렸으니 공부는 충분하겠군이라고 생각했다. 그러나 이제야 시작하는 나같은 수험생들이 여러명이겠지 하는 위안을 얻으며.. 정리해본다..📝
다음은 언젠가 한번쯤은 공부하며 머리 한켠에 있는데 (면접 담당자를 앞에 두고) 설명 할 수 있나? 했는데 입이 안떨어져서 정리하는 개념들이다.
결정계수 R^2
- coefficient of Determination
- 말 그대로 결정해주는 상관계수
- 회귀식이 얼마나 정확한지 나타내주는 숫자
- 결정계수가 높을수록 회귀식의 예측을 믿을 수 있고, 낮을수록 믿을 수 없다.
- 0 <= R^2 <= 1
- (1이면 완전 정확하게 예측했다, 오차 0) - 회귀식의 정확도 = 실제값과 예측값의 오차가 적다
- 만일 실제 값들의 밀도가 높은 경우 (모여있는 경우) 회귀식 간의 오차가 적을 수 있다. 반면에 밀도가 낮은 경우 같은 회귀분석이더라도 오차가 클 수 있다.
- 결정계수는 보통 분산 분석의 데이터를 사용해서 구한다.(SSR / SST)
- 결정계수 값이 애매할 경우, 이 회귀식을 믿어도 되는지/안되는지에 대한 판단은 가설 검정을 통해 진행한다. 귀무가설 기각..0.05.. p-value..
회귀와 분류 Regression and Classification
-
지도 학습에는 2가지 방식이 있습니다. 분류와 회귀
-
output, 학습의 목적, 평가 방법(evaluation)에 따라 둘은 다른데
-
예측하고 싶은 종속 변수가 숫자일 때 회귀를 사용합니다.
- 회귀 분석의 목적은 가장 데이터를 잘 표현하는 회귀식(the best line)을 찾는 것- 회귀식의 정확도는 sum of squared error / 결정계수로 계산합니다.
-
예측하고 싶은 종속 변수가 범주형/이산형일때 (discrete) 분류를 사용합니다.
- 분류 분석의 목적은 데이터의 결정 경계decision boundary를 찾는 것, 즉 데이터가 나뉘는 지점을 찾는 것- 분류의 정확도는 accuracy(얼마나 맞게 분류했는지)를 통해 알 수 있습니다.
-
근데 로지스틱 회귀 분석은 선형 회귀와 달리 종속변수가 서열형, 범주형, 이산형일때 사용됨 (분류기법임)
자율학습 인공신경망? 자기조직화지도
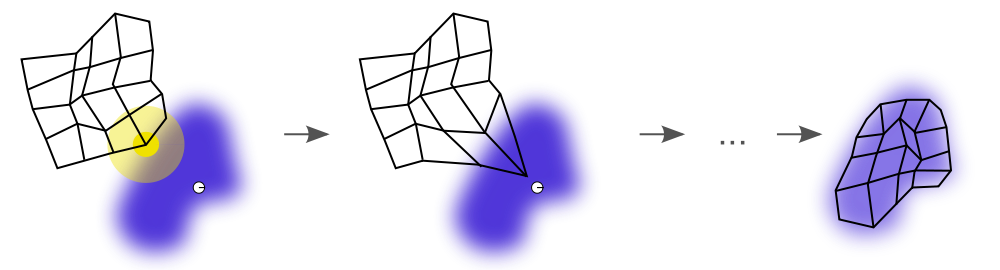
파란 부분이 Train data, 흰색 격자가 학습을 거치며 (맞닿는 부분을 이용해서) train data를 설명할 수 있을 모양을 갖추게됨.. (이론적으로..)

데이터들이 차원 축소되면서 동시에 클러스터링 되고 있다..
- 책에서 처음 본 개념 (비지도학습의 예로)
- SOM - Self-Organizing Map
- 차원 축소와 군집화를 동시에 수행하며, 고차원으로 표현된 데이터를 저차원으로 변환하여 보는
- 비지도학습 기반 클러스터링 기법
