부캠 과제 중에 spaCy 무료 강의를 듣는게 있어서, 들으며 정리한 내용이다.
Advanced NLP with spaCy의 online free course 중 chapter1 : Finding words, phrases, names and concepts의 1-5까지 들은 내용을 정리했다.
spaCy란, NLP(자연어 처리)를 위한 파이썬 라이브러리임
The nlp object
- spaCy 라이브러리를 통해 nlp 객체를 생성할 수 있다
- nlp 객체는 processing pipeline을 갖고 있음
- 이런 변수를 op라고 함 (object pipeline?) - language 별로 토큰화 룰이 있음 (근데 한국어는 없음😢)
from spacy.lang.en import English
# nlp object - 영어 - 생성
nlp = English()
# op에 텍스트를 넣으면 doc 객체를 생성
doc = nlp("Hello world!")
for token in doc:
print(token.text)
- doc은 일반 python sequence 처럼 동작한다
- iterate 하며 text 속성으로 출력 가능
- doc 객체 안에는 텍스트가 Token object들로 있다
- 인덱싱으로 접근 가능 ex)
token = doc[1]
The Span object
- span은 a slice from the Doc임 (인덱스로 슬라이싱 가능)
- span is one or more tokens
span = doc[1:3]print(span.text)가능
Token attributes
token.i: 인덱스token.text: 텍스트token.is_alpha,.is_punct,.like_num: 각각 알파벳인지, 문장 부호인지, 숫자인지 Boolean 값으로 리턴.like_num은 numeric 아니어도 됨. ex) 10 아니고 ten 이어도 true값임
Statistical models
- spacy가 context에서 linguistic 속성을 예측할 수 있다 (동사인지, 사람 이름인지..)
- part-of-speech tags
- syntactic dependencies
- named entities
- 레이블이 있는 데이터로 학습된 것
- 모델 패키지
python -m spacy download en_core_web_sm
for token in doc:
print(token.text, token.pos_, token.dep_, token.head.text)- 토큰의 품사 (동사,대명사, 형용사..), 토큰의 dependency label (어떤 단어가 어떤 단어에 의존하는지), parent token - 어떤 token에 attached 되어있는지?
- dependency label scheme
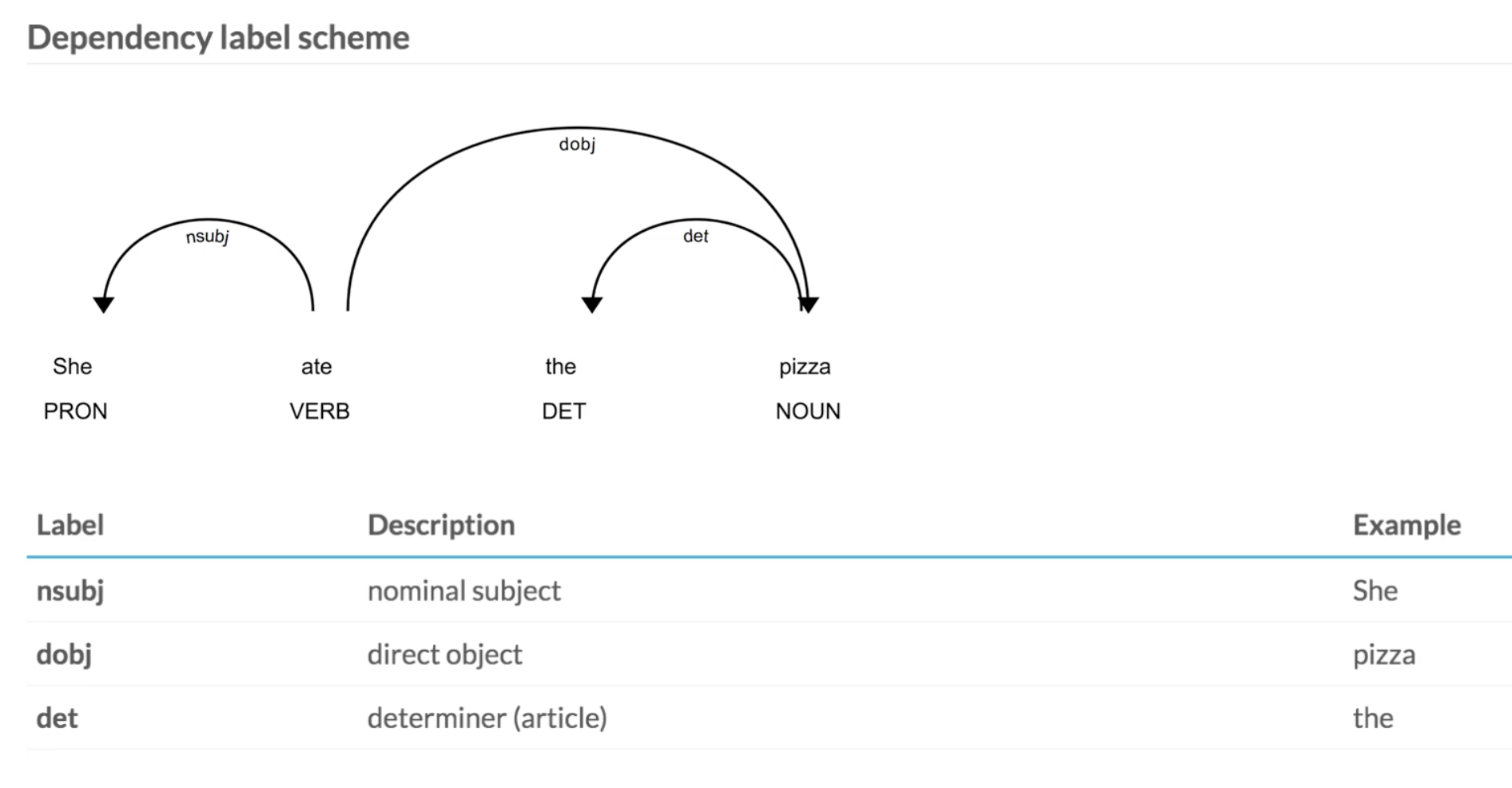
- nominal subject =
nsubj - direct object =
dobj - determiner(관사) =
det
- nominal subject =
for ent in doc.ents:
print(ent.text, ent.label_)- named entities 개체명 예측하기
- ORG, GPE, MONEY 등 대명사 예측
- 이런 tag와 label이 뭔지 알고 싶다면
spacy.explain("개체명")하면 된다

그게 쉬운 일이었다면, 아무런 즐거움도 얻을 수 없었을 것이다.