[신경망] Attention and Transformer
자연어 처리에는
- 자연어 이해 (감성 분석, 문서 분류, 자연어 추론, 기계독해)
- 자연어 생성 (챗봇 등)
- 기계 번역 machine translation
- TTS, STT (text to speach, speach to text)
등의 분류가 있다고 할 수 있다.
그 중에서 오늘은 기계 번역에서 사용하는 모델에 대해 알아보겠슴.
keyword
- Attention mechanism
- (에서 발전한) Transformer 장점
- 의 주요 프로세스인 Self Attention 이해
- (에서 변형된) GPT, PERT 알아보기
가 오늘 배울 내용입니다.
RNN with Attention
-
RNN이 가진 가장 큰 단점 중 하나는 장기의존성(long-term dependency)
-
문장이 길어질 경우 앞 단어의 정보를 잃어버리게 됨 (그래서 짧은 시퀀스에서만 효과적)
-
이걸 해결하기 위해 나온 것이 셀 구조를 개선한 (input, output, forget 게이트를 추가한) LSTM, GRU 모델
-
기계 번역에서 RNN 기반 모델이 단어를 처리하는 방법은?
- 문장의 단어가 encoder unit에 input으로 들어가고 그 때마다 은닉 상태의 벡터가 갱신이 되어 들어가게 됨
- 마지막의 히든 스테이트 벡터가 decoder에 들어가게 되고 decoder - 출력층? 에서도 노드당 하나씩 문장 단어가 나오게 됨.
-
그래도 문장이 길어지면 모든 단어 정보를 고정 길이의 hidden state 벡터에 담기 어려운 단점이 있었음
-
처음 단어의 내용부터 다 담기는데 그걸 벡터 하나에 담기엔 부족함
-
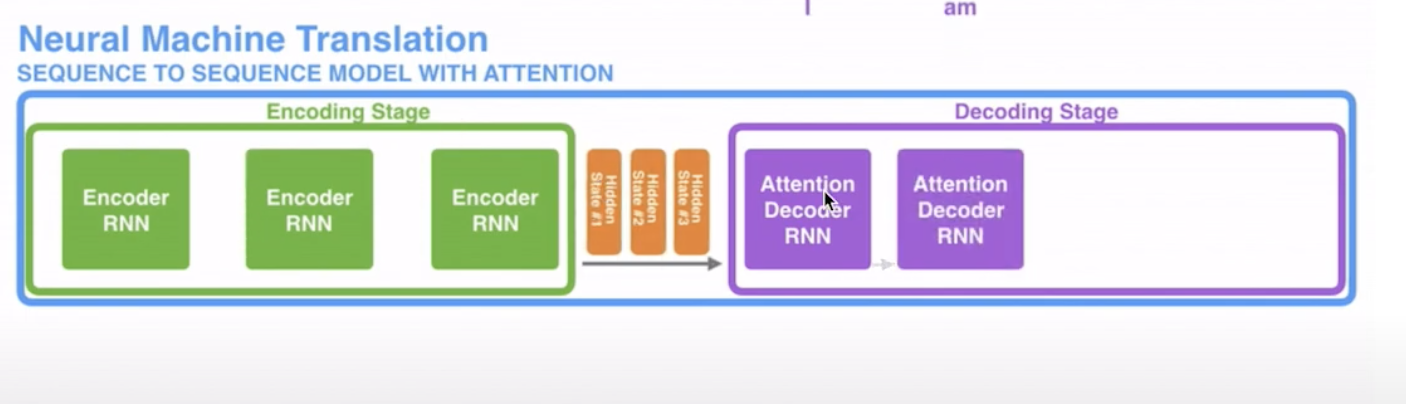
그래서 고안된 방법이 Attention
-
한 벡터에 담기는 게 아니라 노드를 지나며 갱신 된 각각의 단어 노드의 hidden state 벡터가 한번에 decoder로 넘어감
- 각 인코더의 time-step마다 생성되는 (입력 단어가 10개라면 10개) hidden state 벡터 간직
-
맨 마지막 히든 스테이트 벡터만 넘겨주고 있었는데, attention을 적용했을 때는 모든 히든 스테이트 벡터를 다 넘겨주게 됨
-
디코더에서는?
- 단어가 생성 (출력?)될 때마다 모든 hidden state 벡터와 얼마나 관련이 있는지 가중치를 구함
- 이 때 디코더의 hidden state 벡터와 인코더의 각 hidden state 벡터 내적 (n개면 1XN인가..?) 해서 가중치 구함
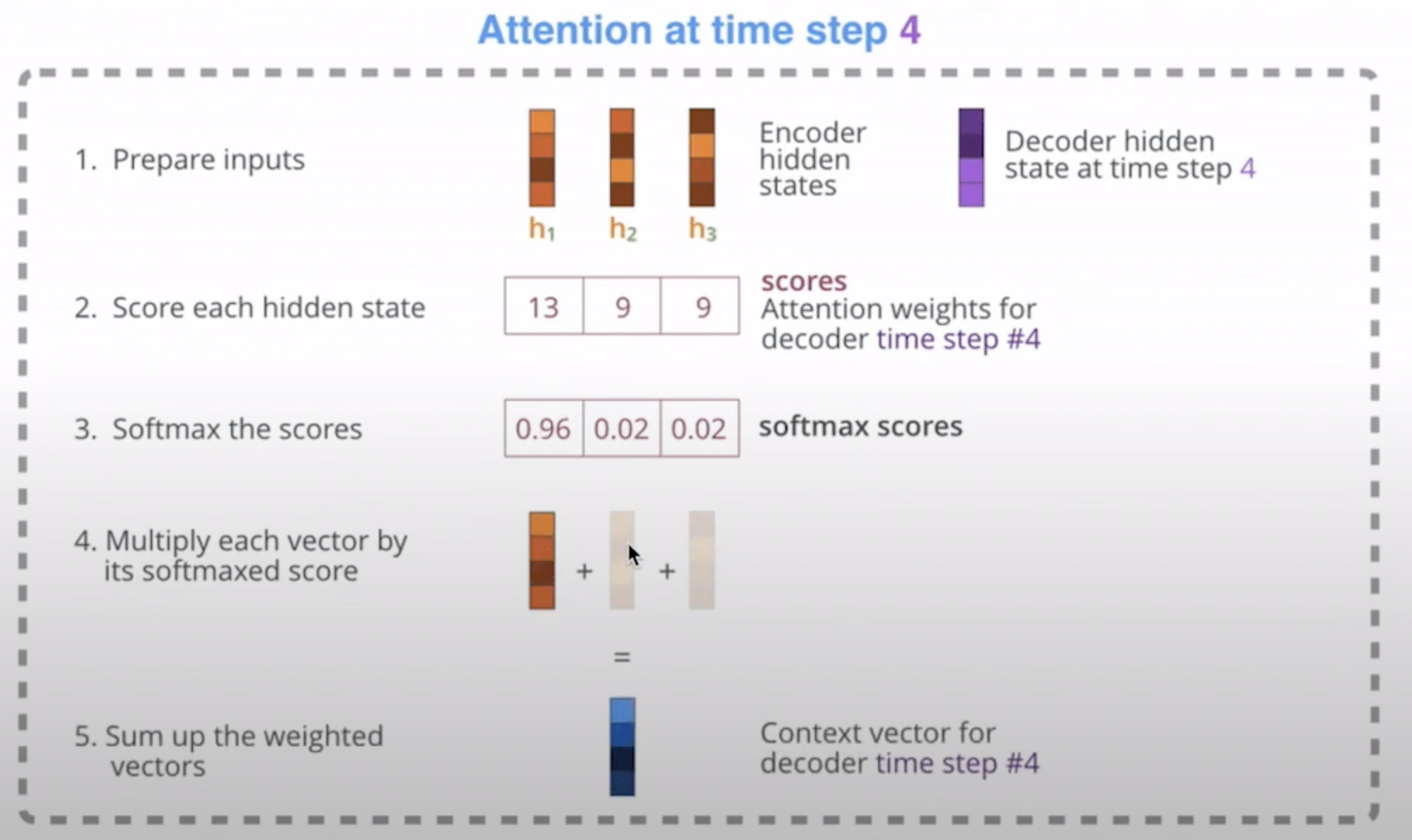
- h1, h2, h3 인풋에 각각 decoder hidden state 벡터를 곱해줌
- 각 hidden state vector의 가중치 (13, 9, 9)
- softmax로 스코어를 확률로 바꿈
- h1 0.96, h2 0.02, h3 * 0.02 하면 h1는 많이 남게 되고 h2, h3 정보는 거의 사라지게 됨
- 그렇게 모든 히든 state vector을 다 더 해서 context vector을 만들게 됨 (output)
- time step 마다 출력할 단어가 어떤 단어에 집중해야 할지 알 수 있음 (attention)
- 이런 과정을 거쳐 단어를 생성하면 인코더에 입력되는 모든 단어의 정보를 활용할 수 있다. => 장기 의존성 문제 해결
(tbc)
- 단어가 생성 (출력?)될 때마다 모든 hidden state 벡터와 얼마나 관련이 있는지 가중치를 구함

그게 쉬운 일이었다면, 아무런 즐거움도 얻을 수 없었을 것이다.