(1) 힙 정렬
힙을 이용한 우선순위 큐를 우리는 이미 구현해보았고 이는 결국 정렬과 같다.
1. HeapSort함수 구현
힙 라이브러리를 이용하지 않고 직접 힙 정렬을 구현하여
https://www.acmicpc.net/problem/15688 를 푼 코드
#include <stdio.h>//힙 정렬
int array[1000000];// 처음에 데이터 받아오는 ㅐ열
int brray[1000001];// 힙
void Heap(int N)
{
int i, cur;
for (i = 0; i < N; i++)
{
brray[i + 1] = array[i];
cur = i + 1;
while (cur != 1)
{
if (brray[cur / 2] > brray[cur])
{
brray[cur] = brray[cur / 2];
brray[cur / 2] = array[i];
cur /= 2;
}
else break;
}
}
for (i = 0; i < N; i++)
{
array[i] = brray[1];
brray[1] = brray[N - i];
cur = 1;
while (2 * cur <= N - i - 1)
{
if (brray[2 * cur] <= brray[2 * cur + 1])
{
if (brray[2 * cur] < brray[cur])
{
brray[cur] = brray[2 * cur];
brray[2 * cur] = brray[N - i];
cur *= 2;
}
else break;
}
else
{
if (brray[2 * cur + 1] < brray[cur])
{
brray[cur] = brray[2 * cur + 1];
brray[2 * cur + 1] = brray[N - i];
cur = 2 * cur + 1;
}
else break;
}
}
}
}
int main()
{
int i, N;
scanf("%d", &N);
for (i = 0; i < N; i++) scanf("%d", &array[i]);
Heap(N);
for (i = 0; i < N; i++) printf("%d\n", array[i]);
return 0;
}2.시간 복잡도
힙의 데이터 하나의 저장 시간 복잡도, 삭제 시간 복잡도 모두 log_2 n
따라서 n개의 데이터를 저장하는 것의 시간 복잡도는
log_2 1 + log_2 2 +.....log_2 n = log_2 n!
그리고 n^n은 n!보다 크고 (n/2)^(n/2)은 (n/2)~n까지의 곱보다 작으므로 n!보다 작은데
이는 결국 nlogn급이므로 log(n!)역시 nlongn급이다.
(2) 병합 정렬
Divide And Conquer -> 아 분할 정복! -> 별찍기 10 등으로 분할 정복을 이미 공부해본 바가 있어서 재귀함수를 활용핧 것이라고 추측가능하다.
1. 알고리즘
1단계 분할 : 해결이 용이한 단계까지 문제를 분할해 나간다.
2단계 정복 : 해결이 용이한 수준까지 분할된 문제를 해결한다.
3단계 결합 : 분할해서 해결한 결과를 결합하여 마무리한다.
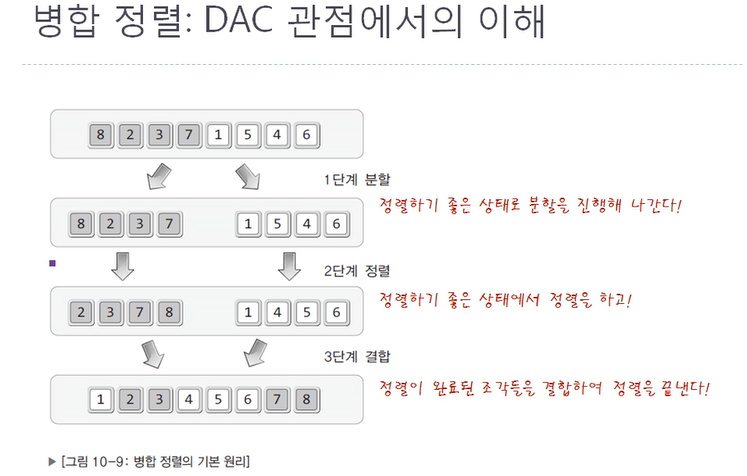
해결이 용이한 단계의 예시 -> 데이터 2개는 if문 하나면 정렬 가능
그러나 병합 정렬은 데이터를 정렬할 필요가 없는 1개까지 쪼갠다!
일단 여기서 나누는 것은 정렬을 위한 준비과정이다.
실재 정렬은 결합하는 과정에서 일어난다.
(1.5). 내 생각
시간복잡도가 nlogn이려면 각 층이 log n이므로 각 줄의 시간복잡도가 n이면 될 것
각 줄에서 내려오는 두 배열은 이미 정렬된 것
2 3 7 8 / 1 4 5 6 을 예시로 들자
2와 1을 비교, 1이 더 작다 -> 1
2와 4를 비교, 2가 더 작다 -> 1 2
3과 4를 비교, 3이 더 작다 -> 1 2 3
7과 4를 비교, 4가 더 작다 -> 1 2 3 4
7과 5를 비교, 5가 더 작다 -> 1 2 3 4 5
7과 6을 비교, 6이 더 작다 -> 1 2 3 4 5 6
1 4 5 6은 끝, 나머지 7,8을 배열에 순서대로 넣기 -> 1 2 3 4 5 6 7 8
이려면 된다.
2. 내 생각으로 구현
https://www.acmicpc.net/status?user_id=honeyricecake&problem_id=15688&from_mine=1
을 병합 정렬을 이용하여 해결한 코드
분할 정복은 재귀로 해야될 거라는 힌트는 얻고 나머지는 직접 구현하였다.
#include<stdio.h>
int array[1000000];
int brray[500000];
int crray[500000];
void Merge(int k, int n)//나누고 정렬해서 합치는 함수
{
int i, cur, p, q;
if (n == 1) return;
else
{
Merge(k, n / 2);//배열의 시작 인덱스, 배열의 성분 개수
Merge(k + n / 2, n - n / 2);
}//정렬된 배열 두 개를 불러와야 한다. 이 때 정렬은 Merge함수 안에서 해결
cur = 0;
for (i = k; i < k + n / 2; i++)
{
brray[cur++] = array[i];
}
cur = 0;
for (i = k + n / 2; i < k + n; i++)
{
crray[cur++] = array[i];
}
p = 0; q = 0;
for (i = k; i < k + n; i++)
{
if (brray[p] < crray[q] && p < n/2) array[i] = brray[p++];
else
{
if (q >= n - n / 2) array[i] = brray[p++];
else array[i] = crray[q++];
}
}
} //마지막 for문의 if문이 좀 마음에 걸린다. 저것 때문에 연산시간이 많이 늘었을 것이다.
int main()
{
int i, N;
scanf("%d", &N);
for (i = 0; i < N; i++)
{
scanf("%d", &array[i]);
}
Merge(0, N);
for (i = 0; i < N; i++)
{
printf("%d\n", array[i]);
}
}내가 구현한 병합정렬로 푼 백준 2108번 통계학
https://www.acmicpc.net/problem/2108
#include<stdio.h>
int array[500000];
int brray[250000];
int crray[250000];
int drray[8001];
void Merge(int k, int n)//나누고 정렬해서 합치는 함수
{
int i, cur, p, q;
if (n == 1) return;
else
{
Merge(k, n / 2);//배열의 시작 인덱스, 배열의 성분 개수
Merge(k + n / 2, n - n / 2);
}//정렬된 배열 두 개를 불러와야 한다. 이 때 정렬은 Merge함수 안에서 해결
cur = 0;
for (i = k; i < k + n / 2; i++)
{
brray[cur++] = array[i];
}
cur = 0;
for (i = k + n / 2; i < k + n; i++)
{
crray[cur++] = array[i];
}
p = 0; q = 0;
for (i = k; i < k + n; i++)
{
if (brray[p] < crray[q] && p < n/2) array[i] = brray[p++];
else
{
if (q >= n - n / 2) array[i] = brray[p++];
else array[i] = crray[q++];
}
}
}
int main()
{
int i, N;
int total = 0;
int max = 0;
int maxnumber;
int cur = 1;
scanf("%d", &N);
for (i = 0; i < N; i++)
{
scanf("%d", &array[i]);
total += array[i];
drray[array[i] + 4000]++;
}
Merge(0, N);
printf("%.f\n", (double)total / (double)N);
printf("%d\n", array[N / 2]);
for (i = 0; i <= 8000 ; i++)
{
if (max < drray[i])
{
cur = 1;
maxnumber = i - 4000;
max = drray[i];
}
else if (max == drray[i] && cur == 1)
{
maxnumber = i - 4000;
cur++;
}
}
printf("%d\n", maxnumber);
printf("%d", array[N - 1] - array[0]);
}보너스
카운팅 정렬로 푼 통계학 코드
#include<stdio.h>
int array[500000];
int drray[8001];
int main()
{
int i, j, N, x;
int total = 0;
int max = 0;
int maxnumber;
int cur = 1;
int k;
int count = 0;
scanf("%d", &N);
for (i = 0; i < N; i++)
{
scanf("%d", &x);
total += x;
drray[x + 4000]++;
}
printf("%.f\n", (double)total / (double)N);
for (i = 0; i < 8001; i++)
{
for (j = 0; j < drray[i]; j++)
{
array[count++] = i - 4000;
}
}
printf("%d\n", array[N/2]);
for (i = 0; i <= 8000 ; i++)
{
if (max < drray[i])
{
cur = 1;
maxnumber = i - 4000;
max = drray[i];
}
else if (max == drray[i] && cur == 1)
{
maxnumber = i - 4000;
cur++;
}
}
printf("%d\n", maxnumber);
printf("%d", array[N - 1] - array[0]);
}카운팅 정렬은 자료구조를 공부하면서는 공부한 적이 없지만 내가 처음 생각해낸 알고리즘인데
데이터의 범위가 좁은 대신 수가 많을 때, 정렬하기 굉장히 좋은 알고리즘이라서
(시간복잡도가 O(n)이다.)
이 문제에 활용하기 좋아보여서 활용해보았다.
3. 강의에서의 구현
#include <stdio.h>
#include <stdlib.h>
void MergeTwoArray(int arr, int left, int mid, int right);//함수의 전방 선언
void MergeSort(int arr[], int left, int right)//ex. 8개짜리, 0, 7
{
int mid;
if (left < right) // left == right 이면 배열이 한 칸짜리, 즉 더 쪼갤 수 없음
{
//중간 지점을 계산한다.
mid = (left + right) / 2;
//둘로 나눠서 각각을 정렬한다.
MergeSort(arr, left, mid);
MergeSort(arr, mid, right);
//정렬된 두 배열을 병합한다.
MergeTwoArray(arr, left, mid, right);
//병합하는 동안은 정렬해야 하므로 함수에 정렬의 과정이 있어야 할 것.
}
else return;
}
void MergeTwoArray(int arr[], int left, int mid, int right)
{
int fIdx = left; int rIdx = mid + 1; ; int i; //오른쪽 데이터의 첫번째 요소가 rIdx = mid + 1
int* sortArr = (int*)malloc(sizeof(int) * (right + 1));//병합 결과를 담을 메모리 공간 할당
int sIdx = left;
while (fIdx <= mid && rIdx <= right)
{
if (arr[fIdx] < arr[rIdx])
{
sortArr[sIdx] = arr[fIdx++];
}
else
{
sortArr[sIdx] = arr[rIdx++];
}
sIdx++;
}//병합할 두 영역의 데이터를 비교하여 배열 sortArr에 담는다.
if (fIdx > mid)
{
for (i = rIdx; i <= right; i++, sIdx++)
{
sortArr[sIdx] = arr[i];
}
}//배열의 앞부분이 sortArr로 모두 이동되어서 배열, 뒷부분에 남은 데이터를 모두 sortArr로 이동
else
{
for (i = fIdx; i <= mid; i++, sIdx++)
{
sortArr[sIdx] = arr[i];
}
}
for (i = left; i <= right; i++)
{
arr[i] = sortArr[i];
}
//배열의 뒷부분이 sortArr로 모두 이동되어서 배열
free(sortArr);
}4. 병합 정렬의 성능 평가
(1)
병합 정렬의 연산은 대부분 분할과 병합 중 병합에서 이루어진다.
병합은 총 데이터 개수가 n개일 때 총 log_2 n단계를 거친다. (정확히는 log_2 n의 올림)
그리고 각 단계에서 비교 연산은 최대 n회 이루어진다.
즉 병합 정렬의 시간복잡도는 비교연산을 생각했을 때는 nlogn이다.
(2)
이동연산을 중심으로 생각했을 때는?
단계는 똑같이 log_2 n이고 이동연산은 각각의 단계에서 임시 배열에 데이터를 정렬해서 갖다놓는 데에 n회, 정렬된 데이터를 원본 배열에 복사라는데 n회
즉, 무조건 2*nlog_2(n)회의 이동연산이 이루어진다.
그래서 시간복잡도는 O(n log n)이다.
