자료구조
1.배열과 구조체

이 게시글은 원본 링크https://lsoovmee-rhino.tistory.com/27?category=847612에서 공부를 하며 주석을 달고 오류가 있는 부분을 수정한 게시글임을 미리 알립니다.C 프로그래밍 기초에서 배열과 포인터에 대해 공부하면서 배열에
2.연결리스트
이 글은 https://blog.encrypted.gg/932?category=773649를 원본으로 하며 공부한 내용을 필기한 것임을 미리 밝힙니다. (자료구조를 공부하는 데에 어느 정도의 시간이 필요할까 가늠하기 위해 연결리스트를 우선적으로 공부하기로 했다.)
3.유클리드 호제법의 pseudo code와 증명

유클리드 호제법의 pseudo code(출처 : kocw에 올라와있는 금오공대 자료구조 및 알고리즘 강의)강의를 들으며 이 pseudo code를 보았고 이를 증명해보고자 한다.유클리드 호제법의 증명 x = GCM p y = GCM q (p,q는 서로소, q > p
4.CH 01 자료구조 및 알고리즘의 이해
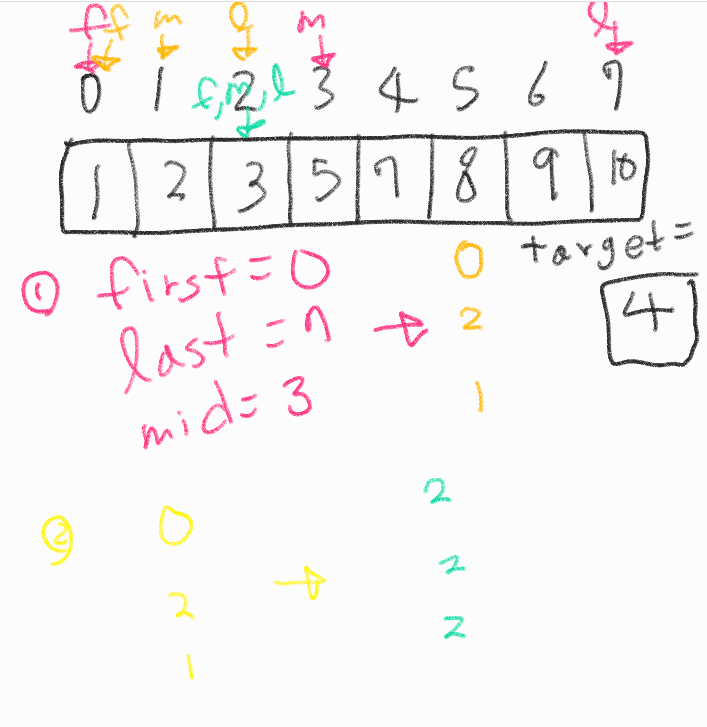
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다.스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다.1\. 자료구조란 무엇인가?프로그램이란 데이터를 표현하고 그렇게 표현
5.CH 02 재귀
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다. 스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다. 02 - 1 함수의 재귀적 호출의 이해 EX.1 피보나치 수열
6.CH 03 - 1 추상 자료형
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다.스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다.추상자료형이란?구체적인 기능의 완성 과정을 언급하지 않고 순수하게 기
7.CH 03 - 2 배열을 이용한 리스트의 구현
1\. 리스트의 특징과 ADT우선 순차리스트와 연결리스트는 구현 방법을 기준으로 한 구분이므로 ADT가 동일하다고 해서 문제가 되지는 않는다.<리스트의 특징>1\. 데이터의 저장 형태 - 데이터를 나란히 저장2\. 저장 특성 - 중복이 되는 데이터의 저장을 허용&
8.CH 04 - 1 연결리스트의 개념
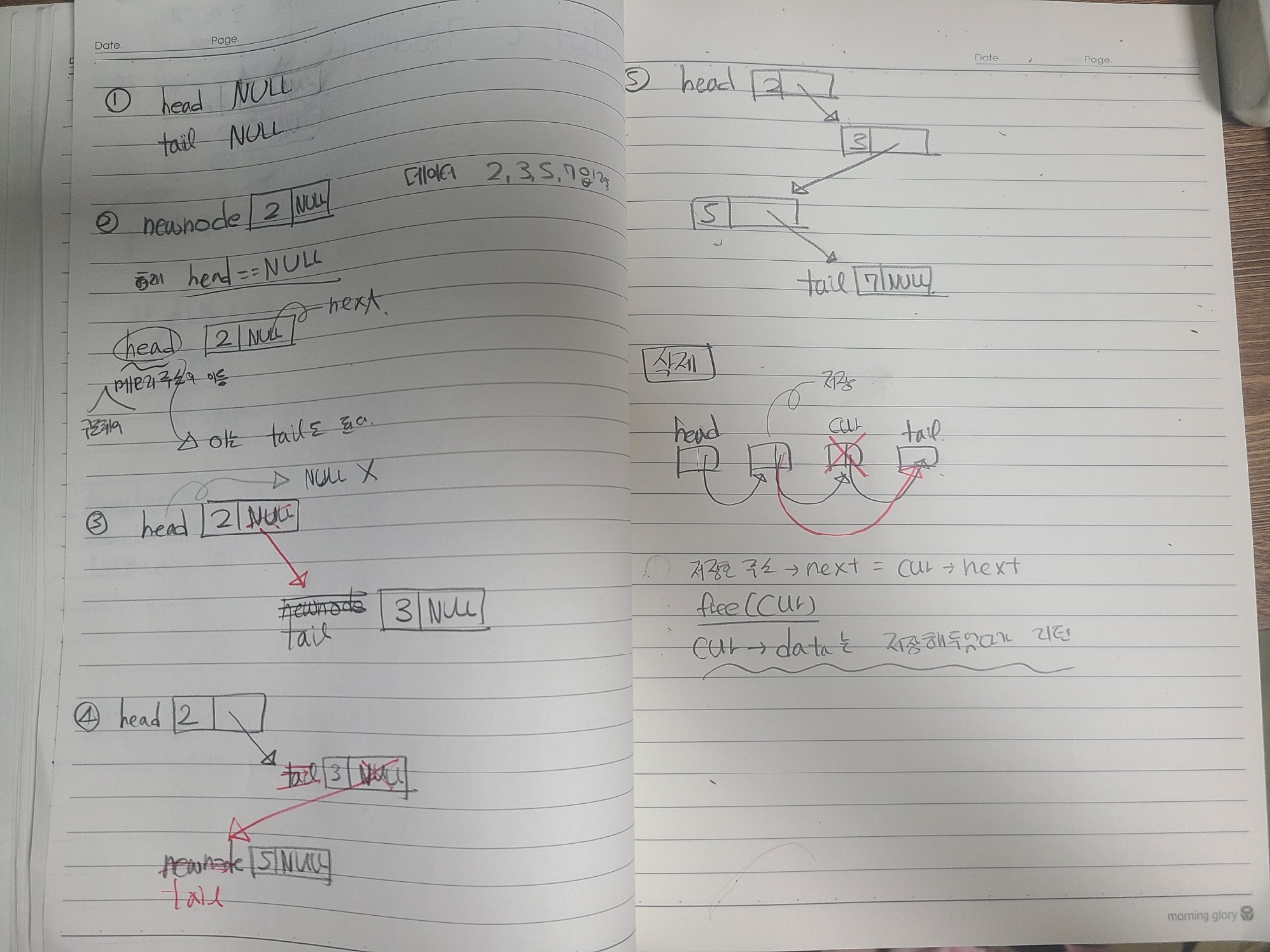
사실 연결리스트는 이전에 공부한 적이 있어서 더 배울건 없었고몇가지 얻은 것을 정리해보겠다.1.head == NULL, tail == NULL, cur == NULL로 정의함으로서 현재 데이터가 저장되어있는가 아닌가 등의 정보를 얻을 수 있다.예를 들어이 코드에서도 헤
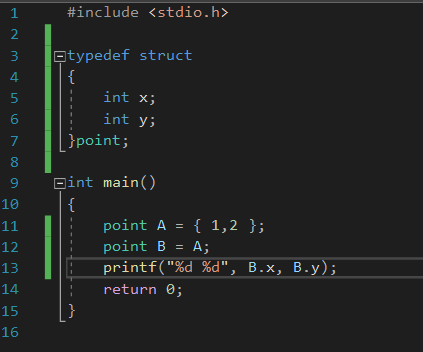
9.범용성있는 소스코드에 대한 이해
배열리스트에 저장할 자료형을 구조체 포인터로 두고 잘 짠 소스코드는 범용성있게 사용할 수 있음을 이해해보자.Point.htypedef struct \_point{ int xpos; int ypos;} Point; //구조체에 x좌표, y좌표, struct로 타입 디피니
10.CH 04 - 2,3 단순 연결 리스트의 구현
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다. 스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다. 목표 : 내가 헤더파일을 보고 구현해보고 구현한 함수들을 자료형
11.원형 연결 리스트와 양방향 연결 리스트
원형 연결 리스트는 메모리를 순환적으로 사용가능하게 해주는데단순 연결 리스트에서 마지막 노드가 처음 노드를 가리키게 하면 이것이 바로 원형 연결리스트이다.원형 연결리스트는 꼬리와 머리의 구분이 없으며, 따라서 단순 연결 리스트처럼 머리와 꼬리를 가리키는 포인터 변수를
12.Ch 6 - 1 스택의 개념과 배열 기반 스택 구현
1\. 스택의 개념먼저 들어간 것이 나중에 나오는 구조가 스택스택의 기본 연산1.push - 넣고2.pop - 꺼내기 -> 데이터 꺼내기 + 삭제3.peek - 데이터 추출 가능, 삭제X2\. 내가 구현한 배열기반 스택의 헤더 파일과 소스 파일1.헤더2.소스파일3.강의
13.Ch 6 - 2 연결리스트 기반 스택 구현
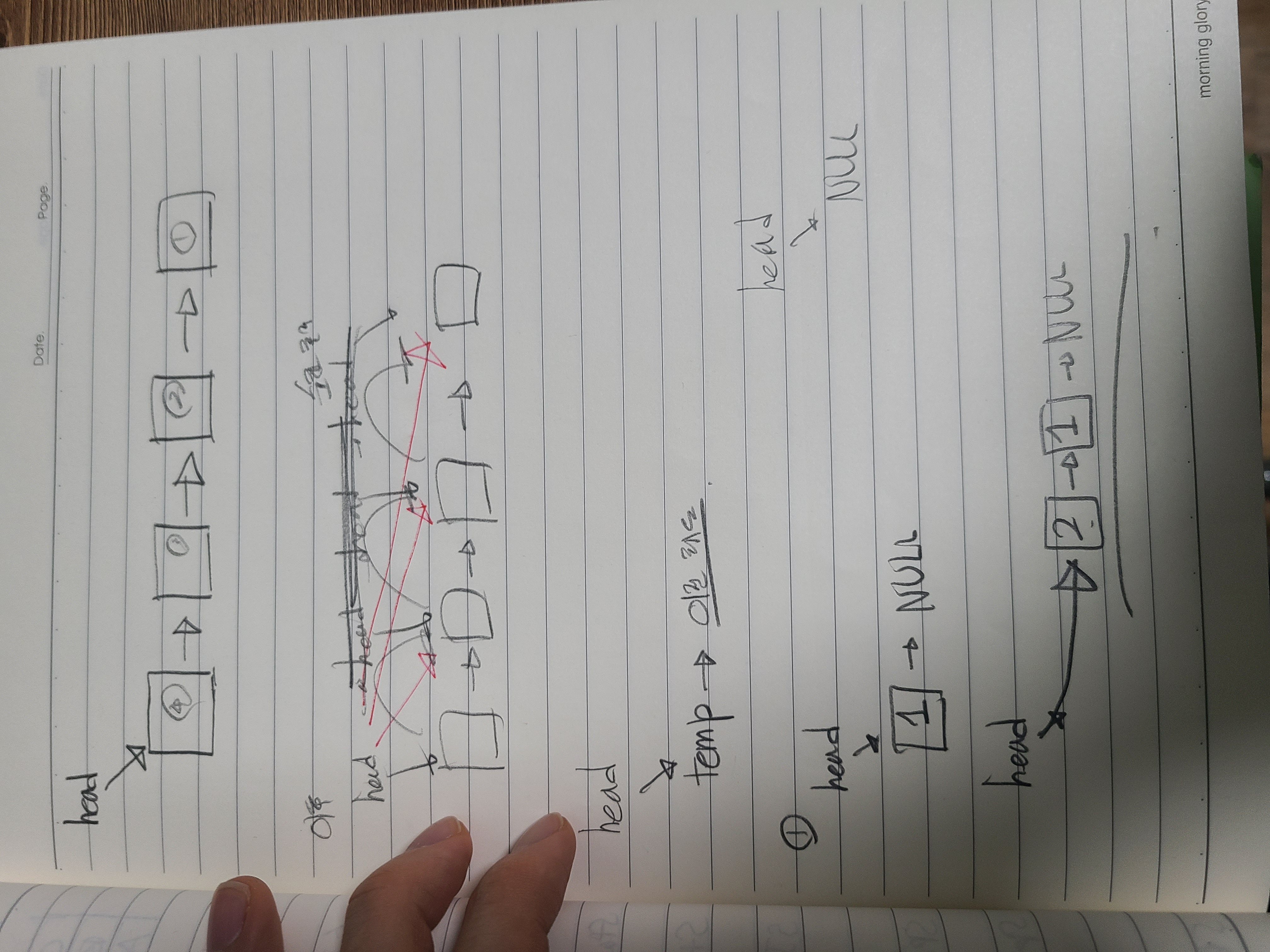
1\. 헤더파일 코드2\. 내가 구현한 소스 파일강의에서 구현한 소스 파일//거의 코드가 내거랑 유사하다. 실력이 늘어가고 있는걸까? 뿌듯함이 느껴진다.
14.중위표기식을 후위표기식으로 바꾸는 법
중위 표기식은 연산의 순서에 대한 정보가 없고 대신 연산의 우선순위가 정의되어 있다. 이를 소괄호를 파악하여 그 부분을 먼저 연산, 연산자의 우선순위를 근거로 연산의 순위를 결정하여 컴퓨터가 계산하기 쉬운 후위 표기식으로 변환하는 것이 계산기 프로그램 구현의 첫 걸음
15.계산기 구현
한자리수만 계산할 수 있고 중간까지의 계산값도 0이상의 정수여야만 하는 조잡한 계산기 ㅋㅋ... 스택 공부를 했다는데 의의를 두고자 한다.. 내 코드 강의의 코드
16.Ch 7 - 1 큐(Queue)
1.큐의 이해와 ADT먼저 들어간 것이 먼저 나온다.즉, First in - FIrst out의 구조줄서기를 예시로 생각하면 편할 것이다.ADT1.초기화 2.큐가 비었는지 여부 검사 3.데이터 저장 4.데이터 삭제5.저장순서가 가장 앞선 데이터를 반환하되 삭제하지X큐는
17.Ch 7 - 2 덱
(1) 덱의 이해Deque(덱)을 디큐라고 읽지 않는 이유 : 큐의 기초연산 디큐와 햇갈릴 수 있기 때문스텍 : 입구와 출구가 같다.큐 : 입구와 출구가 양쪽 끝이다.덱 : Double(Double ended queue)양쪽으로 넣을 수 있고 양쪽 방향으로 꺼낼 수 있
18.CH 8 - 1 트리의 개요
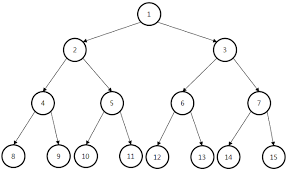
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다.스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다.Prologue자료구조는 데이터를 표현하는 학문이다.표현은 저장을 포
19.CH 8 - 2 이진 트리의 구현
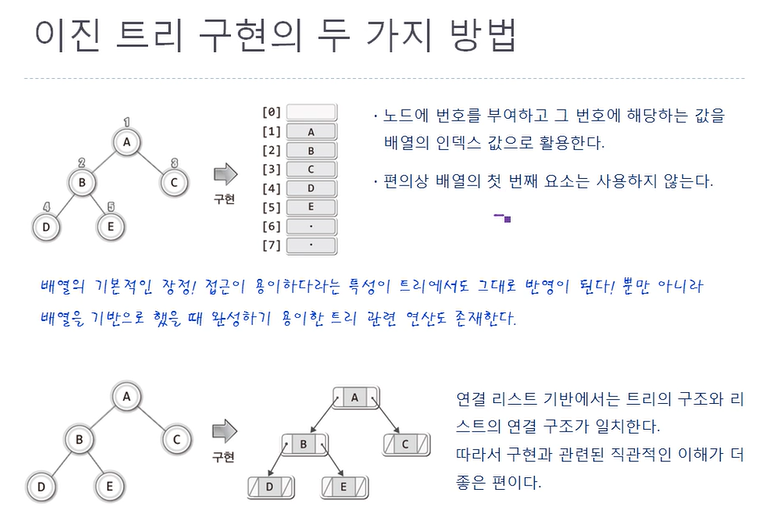
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다.스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다.Prologue이진트리의 구현은 이진트리를 만드는 도구의 구현이다.(
20.CH 08 - 3 이진 트리의 순회
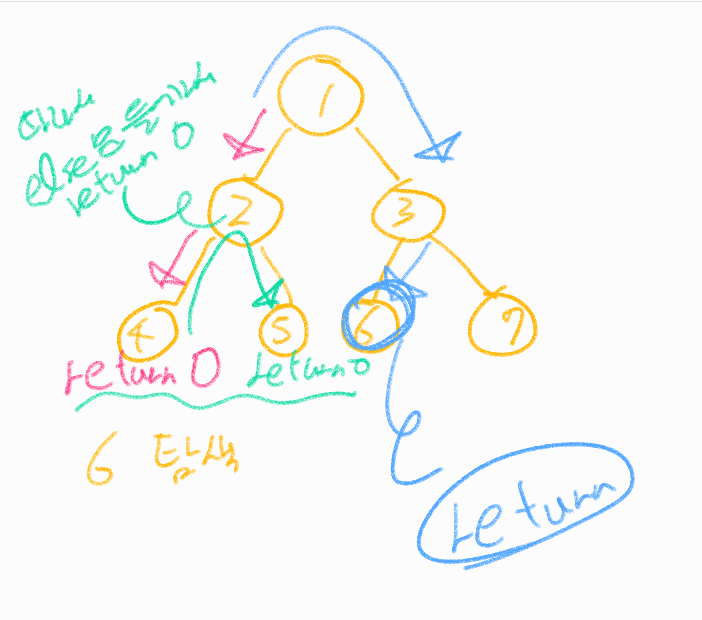
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다. 스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다. (1) 이진 트리의 순회에 대한 강의를 듣기 전 고민 이진트리
21.CH 8 - 4 수식 트리의 구현
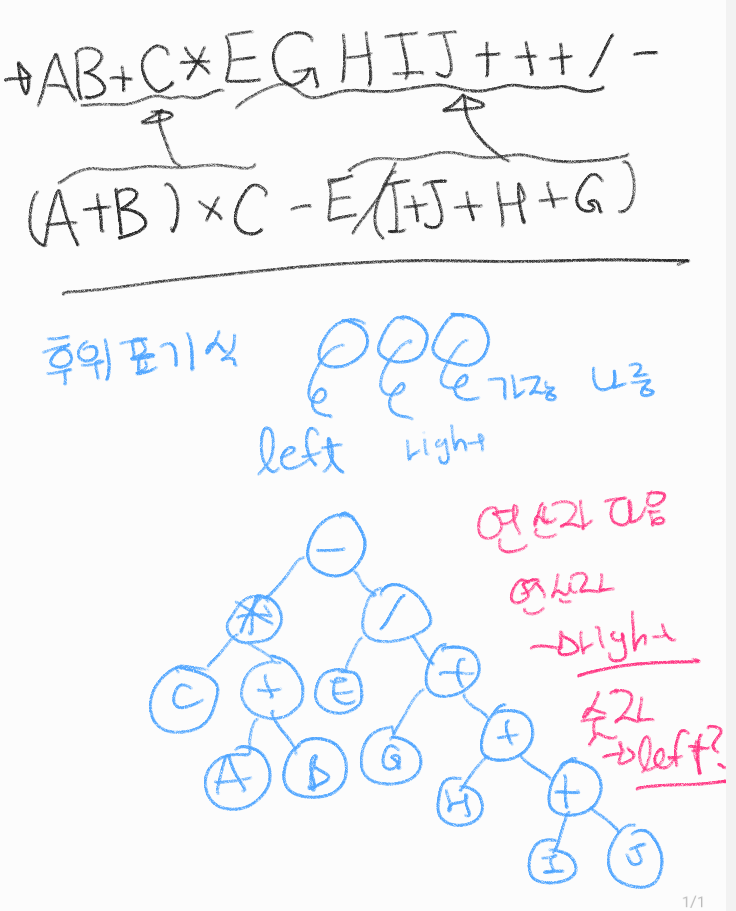
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다. 스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다. (1) 수식 트리의 이해 지금까지 본 수식을 표기하는 법 -
22.CH 9 - 1 우선순위 큐의 이해
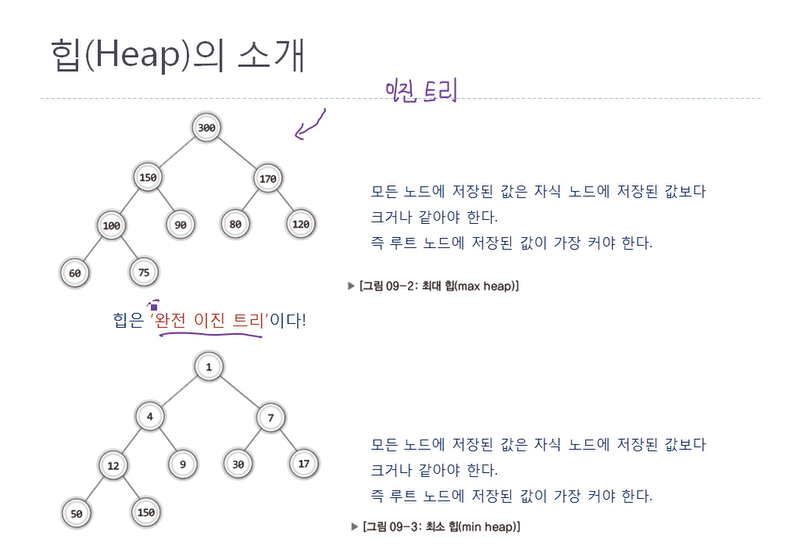
(1) 프롤로그큐는 먼저 들어간 것이 먼저 나오는 자료구조임을 우리는 이미 알고 있고보통 우선 순위 큐를 공부할 때 이와 연결하려는 경향이 있으나사실은 큐 보다는 트리의 연장선상에 있는 것이 우선 순위 큐이다.(2) 우선순위 큐란?들어가는 순서대로 나가는 것이 큐라면,
23.구현 연습 - 트리
입력으로 정수가 들어오면 1~정수까지 완전 이진 트리 구현하기
24.CH 9 - 2 힙의 구현과 우선순위 큐의 완성
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다. 스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다. 프롤로그 우선순위 큐는 힙이다. 힙은 우선순위 큐이다. 모두
25.Ch 10 - 1 단순한 정렬 알고리즘
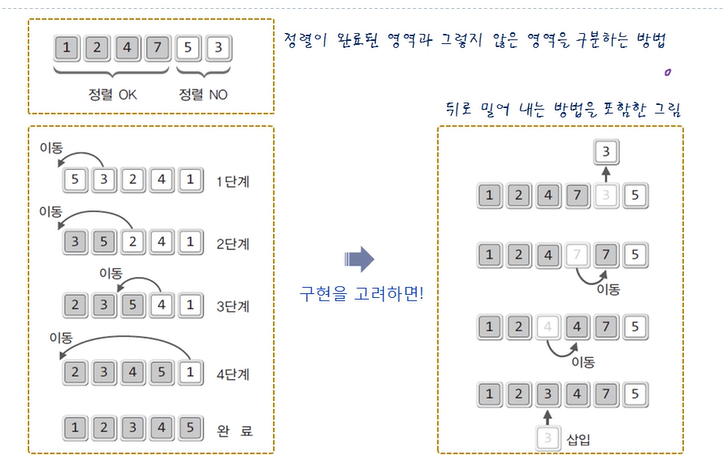
프롤로그 자료구조에서 정렬을 이야기하는 이유는 탐색을 설명하기 위해서이다. 자료구조의 3대 연산 (1)삽입 (2)삭제 (3)탐색 이 때 탐색의 성능은 뺄래야 뺼 수 없는 주제이다. 따라서 탐색 이전에 선행되어야 하는 정렬은 자료구조와 뗄레야 뗄 수 없는 알고리즘
26.CH 10 - 2 복잡하지만 효율적인 정렬 알고리즘 (1)
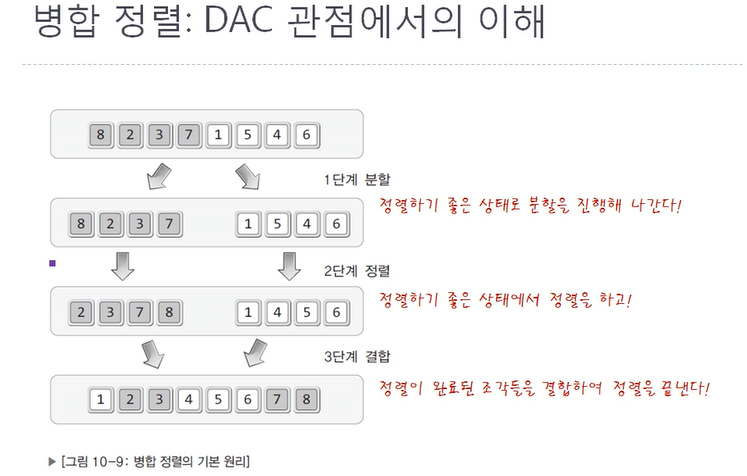
(1) 힙 정렬힙을 이용한 우선순위 큐를 우리는 이미 구현해보았고 이는 결국 정렬과 같다.1\. HeapSort함수 구현힙 라이브러리를 이용하지 않고 직접 힙 정렬을 구현하여https://www.acmicpc.net/problem/15688 를 푼 코드2.시간
27.CH 10 - 2 복잡하지만 효율적인 정렬 알고리즘
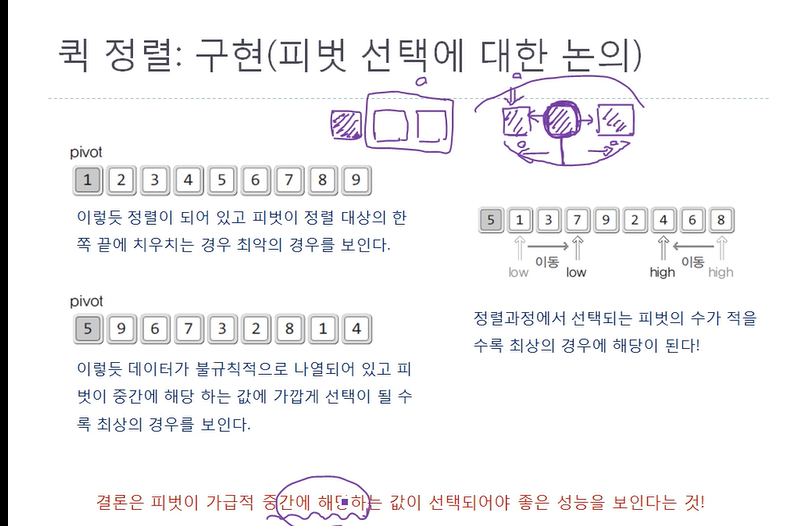
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다. 스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다. 1. 퀵 정렬 (1) 이론 (2) 이론 공부 후 구현해본 코
28.우리가 알던 quick sort는 잘못되었다(?)
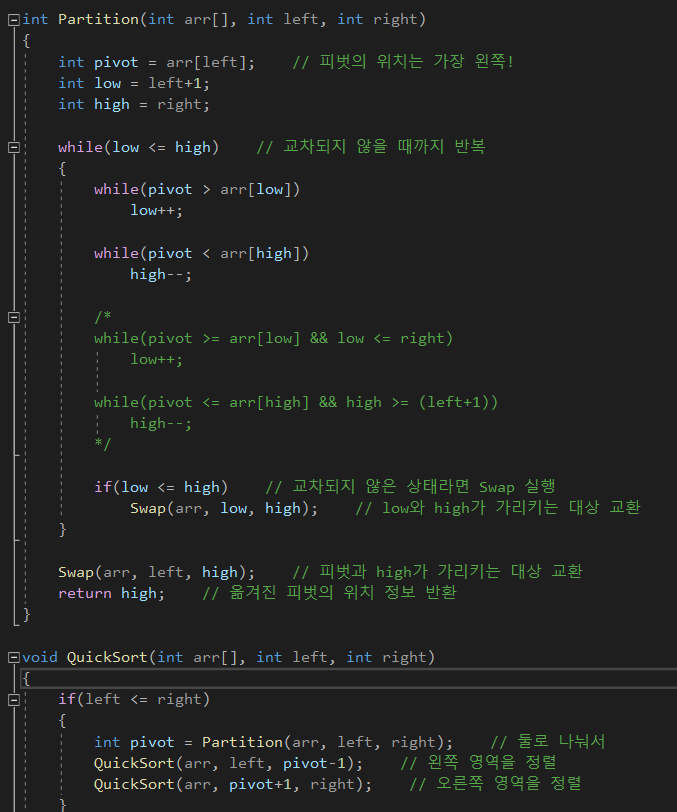
한 강의에서 퀵 정렬을 공부하던 중while문 아래의 두 while문을 보면5 4 3 2 1이나 1 2 3 4 5같이 pivot보다 나머지가 모두 우선순위가 pivot보다 낲거나 높으면 low 나 high가 끊임없이 증가 또는 감소하지 않을까 하는 의문이 들었다.그래서
29.CH 11 - 1 탐색의 이해와 보간 탐색(Interpolation Search)
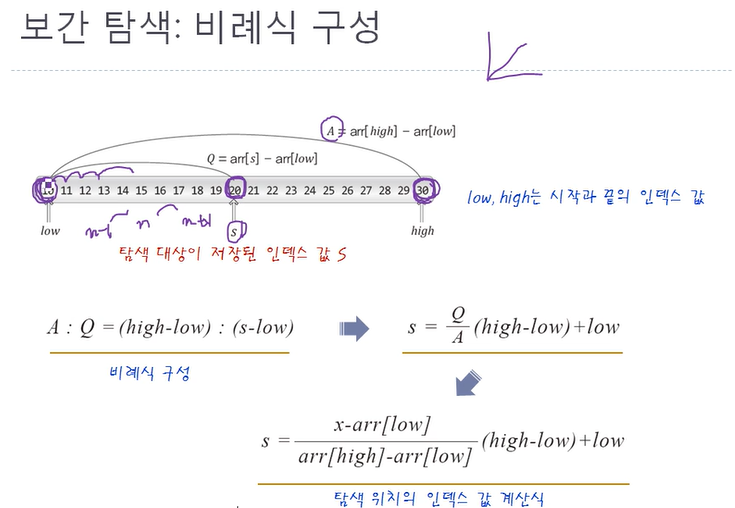
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다.스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다.Prologue(1) 효율적인 탐색을 위해서는 어떻게 찾을까 만을 고
30.쌩으로 혼자 구현해본 이진 탐색 트리
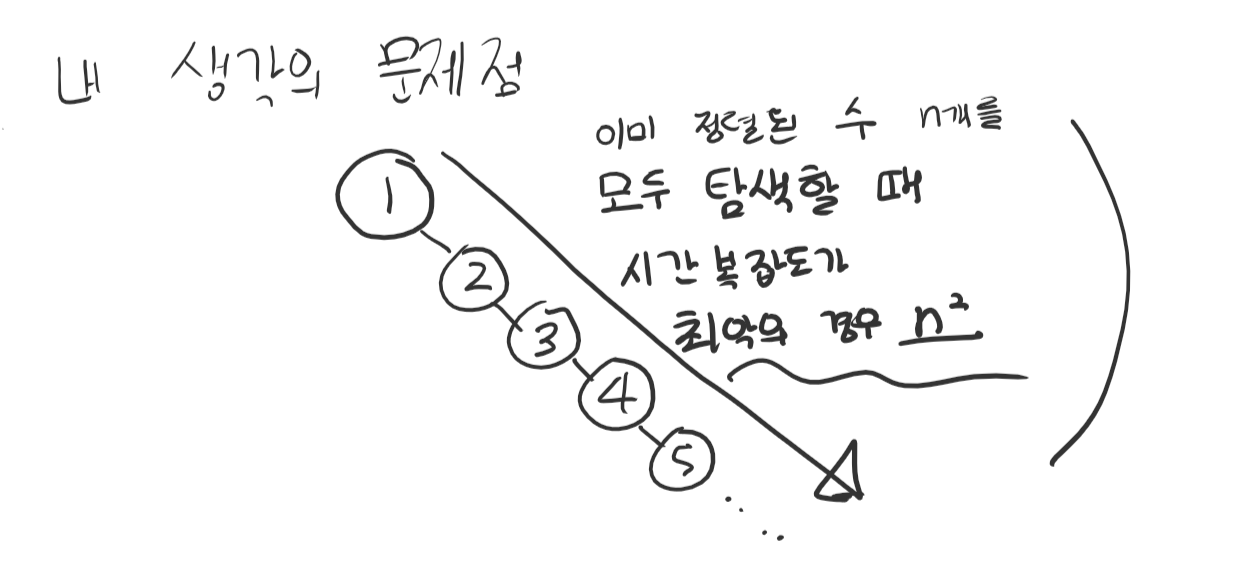
1\. 프롤로그Ch 11 개념을 강의로 들으면서 비교 기준이 되는 노드보다 더 큰 수는 오른쪽 서브트리, 더 작은 수는 왼쪽 서브트리에 저장한다는 것을 알았다.그러나 나머지 개념을 가르쳐주지 않고 강의에서 바로 코드로 들어가서 설명을 하는데 이가 마음에 들지 않아 쌩으
31.이진 탐색 트리 코드 분석
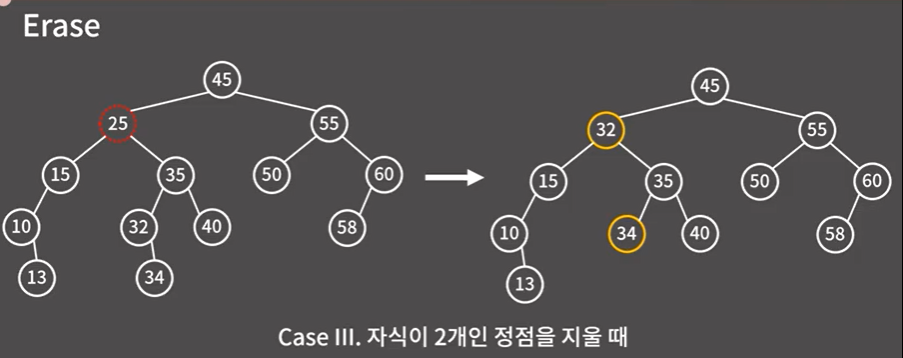
혼자 썡으로 구현해보았으므로 다른 사람의 코드를 한번 보기로 했다. 다른 사람의 코드
32.CH 13 - 1 빠른 탐색을 보이는 해쉬 테이블

1. 빠른 탐색을 보이는 해쉬 테이블 (1) 테이블 자료구조의 이해 테이블 - 데이터가 key와 value로 한 쌍을 이루며, key가 데이터의 저장 및 탐색의 도구가 된다. 즉, 테이블 자료구조에서는 원하는 데이터를 단번에 찾을 수 있다. (이 때 value는
33.CH 13 - 2 충돌 문제의 해결책
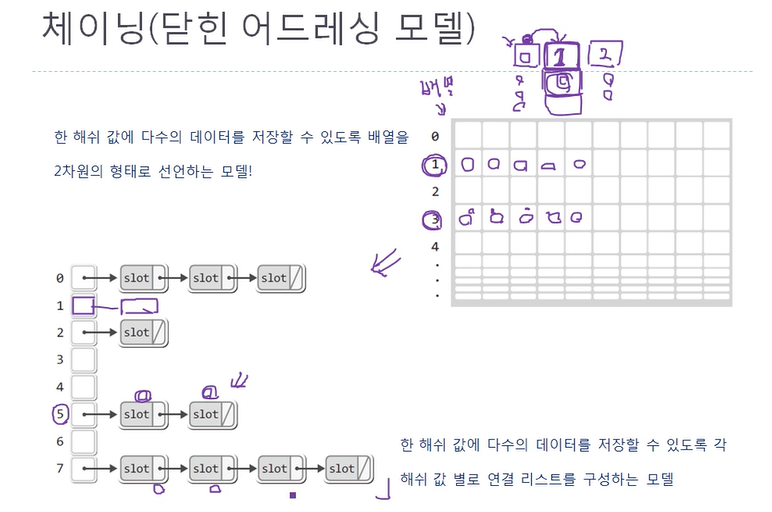
1. 선형 조사법 해쉬함수가 %7이면 9와 2는 충돌이 일어난다. 이 때, 충돌이 일어난 데이터는 그 옆칸의 저장을 한다는 것이 바로 선형 조사법이다. 이는 교과서적인 방법이고 특정 영역에 데이터가 몰리는 클러스터 현상이 발생하여 사용하지 않는다. 즉, 이는 클러스
34.CH 14 - 1 그래프의 이해와 종류 및 구현
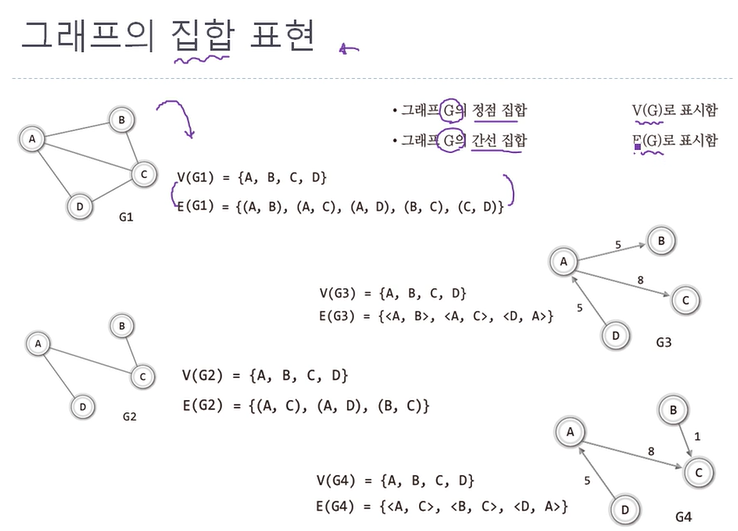
1. 그래프의 역사와 이야깃거리 -> 직관적으로는 모든 정점에 입구와 출구가 있어야 하기 때문 그래프는 정점(노드)과 간선을 하나로 모아 놓은 자료구조인데 그래프는 하나의 표현 방법이고 그와 관련된 알고리즘이 매우 많다. 그래프는 저장보다 표현의 특색이 훨씬 짙다
35.CH 14 - 2 그래프의 탐색
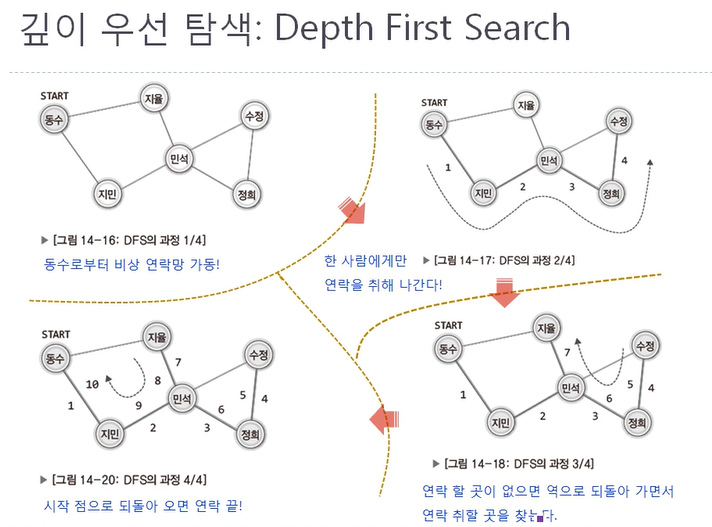
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다.스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다.Prologue탐색에는 깊이 우선 탐색, 너비 우선 탐색이 있다.그래
36.14 - 3 최소 비용 신장 트리
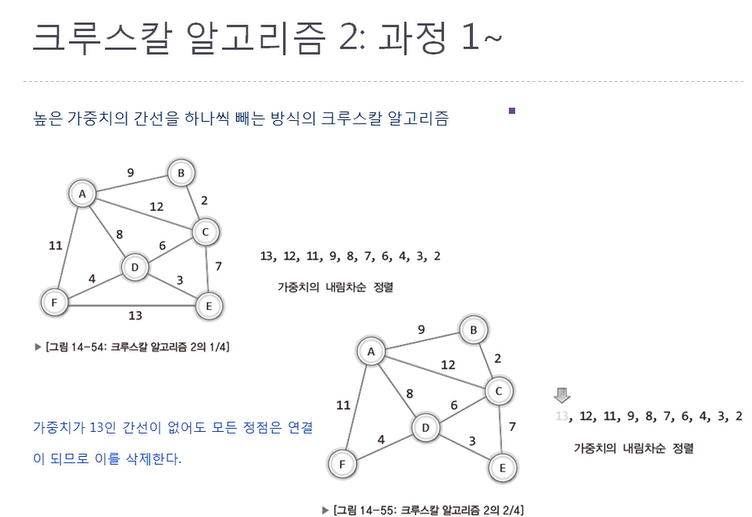
이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다. 스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다. 1. 사이클의 이해 단순 경로란 간선을 중복 포함하지 않는 경