이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다.
스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다.
프롤로그
우선순위 큐는 힙이다. 힙은 우선순위 큐이다. 모두 X
우선순위 큐에 활용되는 도구가 힙인 것이다.
힙의 그 특성이 우선순위 큐를 구현하는 데에 딱이기 때문이다.
이제부터 힙이 어떻게 활용되기에 우선 순위 큐를 구현하는 데에 딱인지 알아보자.
(1) 힙에서의 데이터 저장 과정
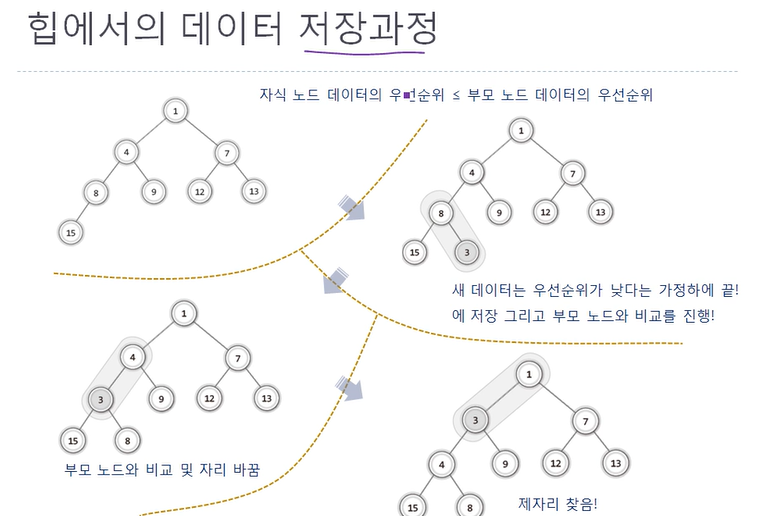
우선 순위는 값이 낮을수록 높다고 가정
부모 노드가 모두 자식 노드보다 우선 순위가 높거나 같고 완전 이진트리이므로 그림의 왼쪽 위의 이진트리는 힙이다.
데이터의 저장이 어려운 이유는 완전 이진트리 구조가 깨져서는 안되고 규칙도 깨져서는 안되기 때문이다.
따라서 데이터를 무작위로 받아서 완전 이진 트리의 다음 노드로 저장하는 것은 불가능하다.
따라서 그림과 같은 저장 과정을 거친다.
3이 들어온다고 가정해보자.
- 3을 완전이진트리의 마지막 노드 자리에 저장
- 부모 노드와 자식 노드의 대소를 비교
- 부모 노드가 자식 노드보다 크면 부모 노드와 자식 노드의 자리를 바꾼다.
- 부모 노드가 자식 노드보다 작을 때까지 2.와 3.을 반복
(2) 힙에서의 데이터 삭제 과정
우선 순위 큐 관점에서의 삭제라고 해야 맞다.
관점을 정하지 않고 단순히 힙에서의 데이터 삭제라면 맨 마지막 노드부터 역순으로 삭제하여
힙이라는 자료구조가 유지되기 때문이다.
따라서 우리의 우선 순위 큐를 구현해야 한다는 목적에서의 데이터 삭제과정을 알아보자.
- 일단 루트 노드의 데이터를 리턴하고 삭제
- 완전 이진 트리의 마지막 노드를 루트 노드로 두기
- 삽입과정처럼 루트 노드가 자기 자리 찾아가기
이 때 자리를 찾아가는 데 있어서는 두 자식 노드 즁 우선순위가 높은 데이터와만 비교하면 된다.
왜냐하면 둘 중 우선 순위가 낮은 데이터와 자리를 바꾸면 우선순위가 낮은 노드가 부모 노드가 될 수도 있기 때문이다.
(이 부분을 숙지하지 않고 구현했다가 큰 코 다쳤다 ㅎㅎ..)
이 때 루트 노드에 오는 것은 무조건 가장 우선순위가 큰 노드가 된다.
왜냐하면 힙의 규칙을 만족한다고 가정하면
루트 노드의 left노드는 왼쪽 서브트리에서 가장 우선 순위가 높은 노드이고
루트 노드의 right노드는 오른쪽 서브트리에서 가장 우선 순위가 높은 노드이므로
이 두개보다 우선 순위가 높으면 우선 순위가 가장 높음이 보장되기 때문이다.
(3) 삽입과 삭제의 과정에서 보인 성능의 평가
트리는 log_2 n 이라고 해도 통용이 될 정도로 log_2 n은 트리에 있어서 트리를 대표하는 성능이라 할 수 있고 log_2 n도 일반적으로 매우 만족스러운 성능이다.
이제 다른 자료 구조와 한번 비교해보자.
배열 기반 데이터 삽입의 시간복잡도는 O(n)이다. 왜냐하면 n개의 데이터를 비교 또는 이동시켜야 하기 때문이다.
연결 리스트 기반 데이터 삽입의 시간 복잡도 역시 O(n)이다. 워스트의 경우 n개를 비교해야 하기 때문이다.
그럼 힙 기반 데이터 삽입의 시간 복잡도는?
2의 n제곱 - 1 이 데이터의 총 개수일 때 level은 n
따라서 워스트 케이스 일때 데이터 삽입의 시간복잡도는 log_2 n에 비례한다.
(상수 부분은 삭제)
//좀 더 정확하게 보자면 데이터의 개수가 2의 (n-1)제곱 이상 2의 n제곱 - 1 이하일 때 연산 횟수가 최대 n이므로 log_2 (n + 1) 의 '올림'이 최대 연산 횟수이고 이는 빅-O가 log_2 n이라고 말할 수 있다.
그리고 배열,리스트 의 데이터 삭제는 각각 맨앞의 것을 삭제하면 되므로 O(1)인데
힙 기반은 데이터를 삭제하고 나서도 다시 힙의 조건에 맞게 완전이진트리를 만들어야 하므로
삭제하는데도 시간복잡도가 O(log_2 n)이다.
그러나 데이터개수의 증가에 따른 연산횟수의 증가 정도를 생각했을 때 2 * log_2 n 이 당연히 n보다 훨씬 낫다.
(4) 배열을 기반으로 힙을 구현하는데 필요한 지식들
일반적으로 힙을 구현할 때, 즉, 이진트리를 구현할 때 연결리스트를 사용하는 경우가 많다.
직관적으로 훨씬 와닿기 때문이다.
하지만 배열을 이용해서 구현하는 것도 그렇게 어렵지 않다.
사실 힙은 대부분 배열을 이용하여 구현한다.
왜냐하면 연결리스트 기반으로 힙을 구현할 시 새로운 노드를 힙의 마지막 위치에 추가하여야 하는데 이 마지막 위치를 아는 것이 힘들기 때문이다.
(나라면 데이터의 개수를 생각한 휴 데이터의 개수를 이진수로 바꾸어서 처음의 1만 루트노드에 진입이라고 생각하고 나머지 자릿수들은 1이면 left 0이면 right로 이동이라 생각할 것이다.)
부모 노드의 인덱스값을 k라 할 때
자식 노드의 인덱스값을 각각 2k , 2k + 1
//level n의 가장 왼쪽 인덱스의 값을 x라 하자.
level n + 1의 가장 왼쪽 인덱스의 값이 2x이면
x+1의 왼쪽 자식 노드의 인덱스는 당연히 2x + 2이고 그럼 당연히 2(x + 1)
x+k의 왼쪽 자식 노드의 인덱스는 당연히 2x + 2k이다.
그리고 이진트리이므로 level 0 의 원소개수는 1
그다음은 2....
등비급수의 합에 의해 총개수는 2의 (n + 1)제곱 - 1
따라서 level n의 다음 레벨 즉, level(n + 1)의 첫인덱스들은 2의 (n + 1)제곱 - 1 + 1 이므로 2의 (n+1)제곱
따라서 level n + 1의 가장 왼쪽 인덱스의 값은 level n의 가장 왼쪽 인덱스값 * 2라는 가정도 성립한다.
예외일 수 있는 것은 맨처음인데 맨첫줄의 첫 인덱스는 1
다음줄 첫인덱스는 2이므로 이 역시 성립한다.
따라서 위처럼 설정하면 이진트리를 배열에서 구현할 수 있다.
또한 이 원리에 의해
자식 노드의 인덱스값을 k라 할 때
부모 노드의 인덱스값을 k/2 로 두기만 하면 된다. (나눗셈은 정수형 나눗셈)
(5) 힙 구현 헤더 파일
#ifndef SIMPLE_HEAP_H
#define SIMPLE_HEAP_H
#define TRUE 1
#define FALSE 0
#define HEAP_LEN 128
typedef char HData;
typedef int Priority;
typedef struct _heapElem
{
Priority pr; // 값이 작을수록 높은 우선순위, 일반적으로 힙은 min Heap으로 구현되어 있다.
HData data;
} HeapElem; //데이터와 우선 순위 정보를 각각 구분하였음 -> 이것만이 옳은 것은 아니다.
typedef struct _heap
{
int numOfData;//데이터의 개수
HeapElem heapArr[HEAP_LEN];//배열 기반으로 구현할 것
} Heap;
/* Heap 관련 연산들 **/
void HeapInit(Heap ph);//힙 초기화
int HIsEmpty(Heap ph);
void HInsert(Heap ph, HData data, Priority pr);//힙에 데이터 삽입
HData HDelete(Heap ph);//힙에서 데이터 삭제, 우선순위가 가장 높은 데이터가 삭제되도록 정의할 것
#endif
//제목은 힙의 구현이지만 목적을 우선 순위 큐의 완성에 둔 것이므로 힙의 구현이라기 보다는 힙을 활용한 우선 순위 큐의 구현이다.
(6) 힙 구현 숙지할 내용
- 힙은 완전 이진 트리이다.
- 힙의 구현은 배열을 기반으로 하여 인덱스가 0인 요소는 비워둔다.(편의를 위하여)
- 노드의 고유번호가 노드가 저장되는 배열의 인덱스 값이 된다.
- 힙에 저장된 노드의 개수와 마지막 노드의 고유 번호는 일치한다.
- 우선 순위를 나타내는 정수 값이 작을수록 높은 우선순위를 나타낸다고 가정한다.
(의무는 아니다.)
(7) 내가 구현해본 힙
#include <stdio.h>
#include "SimpleHeap.h"
void HeapInit(Heap* ph)
{
ph->numOfData = 0;
}
int HIsEmpty(Heap* ph)
{
if (ph->numOfData == 0) return TRUE;
else return FALSE;
}
void HInsert(Heap* ph, HData data, Priority pr)
{
HeapElem new;
HeapElem temp;
int cur;
new.data = data;
new.pr = pr;
ph->numOfData++;
ph->heapArr[ph->numOfData] = new;
cur = ph->numOfData;
while (cur != 1)
{
if (ph->heapArr[cur / 2].pr <= pr) break;
else
{
temp = ph->heapArr[cur / 2];
ph->heapArr[cur / 2] = new;
ph->heapArr[cur] = temp;
cur /= 2;
}
}
}
HData HDelete(Heap* ph)//중요한건 자식노드 중 우선순위가 높은 노드와 우선순위를 비교해서 자리바꿈해야한다는 것이다. 안 그러면 우선 순위가 낮은 노드가 부모 노드가 될 수 있기 때문.
{
if (ph->numOfData == 0)
{
return -1;
}
HData DData;
int cur = 1;
HeapElem temp;
DData = ph->heapArr[1].data;
ph->heapArr[1] = ph->heapArr[ph->numOfData];
int pr = ph->heapArr[1].pr;
ph->numOfData--;
while (2 * cur <= ph->numOfData)// 이 부분을 잘못 건드려 디버깅을 수없이 했다.
//numOfData가 2*cur이하이면 heapArray[2*cur]에 비교가능한 데이터가 있다는 것이므로 반복문에 진입하여야 한다. 2*cur + 1이 numOfData에 포함되지 않으므로 어차피 비교대상 자기자신이므로 2*num에 저장된 데이터보다 우선순위가 높으면 자기자신과 자리를 바꾸므로 변경되지 않을거고 낮으면 어차피 비교대상이 되지 않는다.
{
if (ph->heapArr[2 * cur].pr <= ph->heapArr[2 * cur + 1].pr)
{
if (pr > ph->heapArr[2 * cur].pr)
{
temp = ph->heapArr[2 * cur];
ph->heapArr[2 * cur] = ph->heapArr[cur];
ph->heapArr[cur] = temp;
cur = 2 * cur;
}
else break;
}
else
{
if (pr > ph->heapArr[2 * cur + 1].pr)
{
temp = ph->heapArr[2 * cur + 1];
ph->heapArr[2 * cur + 1] = ph->heapArr[cur];
ph->heapArr[cur] = temp;
cur = 2 * cur + 1;
}
else break;
}
}
return DData;
}원래 중간에 HDelete함수에서 heapArray[numOfData]의 우선도를 INT_MAX로 바꿔서 위의 데이터와 바뀌지 않게 하는 작업을 했는데
어차피 비교대상이 자기자신이라 넣지 않아도 괜찮았다.
또다른 교훈-> 살펴보기 쉬운 테스트 케이스를 하나 만들어 디버깅하는 걸 버릇들이면 좋다.
